

시계열 데이터
시계열은 연속된 균등한 시간 간격에서 얻은 일련의 데이터입니다. 양적 투자에서 이러한 데이터는 주로 가격 움직임과 추적되는 투자 대상의 데이터 포인트로 나타납니다. 예를 들어, 특정 기간 동안 정기적으로 기록된 주가, 시계열 데이터는 다음 그림에서 볼 수 있으며, 이를 통해 독자는 더 명확하게 이해할 수 있습니다.
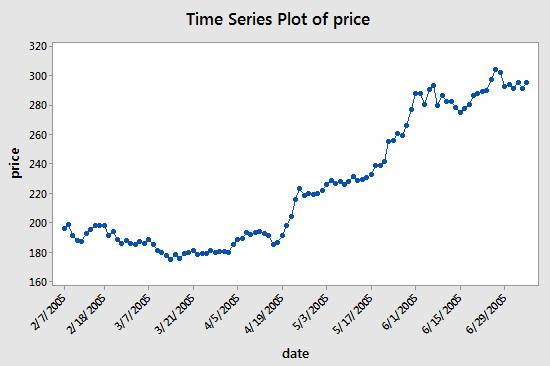
보시다시피, 날짜는 x축에 있고, 가격은 y축에 있습니다. 이 경우 "연속 간격"은 x축의 날짜가 14일 간격이라는 것을 의미합니다. 2005년 3월 7일과 그 다음 지점인 2005년 3월 31일 및 2005년 4월의 차이에 주목하세요. 2005년 4월 5일과 19일입니다.
하지만 시계열 데이터를 다루다 보면 날짜와 가격 열만 보는 것 이상의 내용을 접하게 되는 경우가 많습니다. 대부분의 경우 데이터 기간, 시가, 고가, 저가, 종가라는 5개 열이 포함된 데이터를 다루게 됩니다. 즉, 데이터 기간을 일일 수준으로 설정하면 해당 날짜의 최고가, 시가, 최저가, 종가 변동 사항이 이 시계열 데이터에 반영됩니다.
틱 데이터란?
틱 데이터는 거래소에서 가장 세부적인 거래 데이터 구조입니다. 이는 위에서 언급한 시계열 데이터의 확장된 형태이기도 하며 여기에는 시가, 최고가, 최저가, 최신가, 거래량, 거래금액이 포함됩니다. 거래 데이터를 강에 비유한다면, 틱 데이터는 특정 횡단면에 있는 강의 데이터입니다.
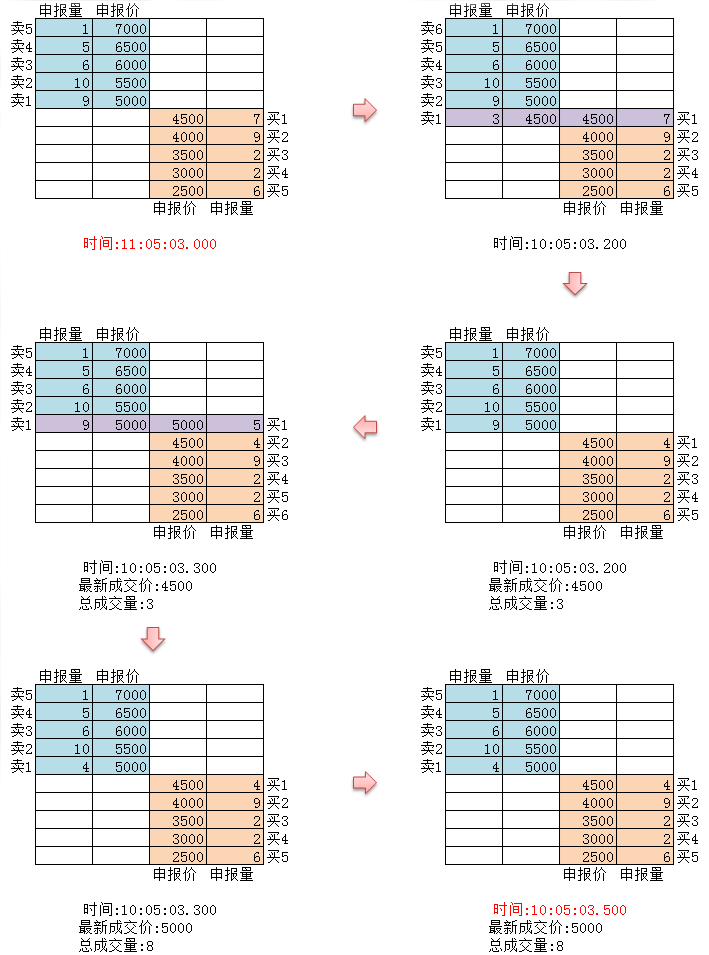
위 그림에서 보듯이, 외환의 모든 움직임은 실시간으로 시장에 반영됩니다. 국내 거래소는 1초에 두 번 확인합니다. 이 기간 동안 어떤 동작이 있으면 스냅샷이 생성되어 푸시됩니다. 비교해 보면, 데이터 푸시는 기껏해야 OnTime으로만 간주될 수 있으며 OnTick이라고 부를 수 없습니다.
이 튜토리얼의 모든 코드와 시계열 데이터는 Inventor Quantitative Platform에서 얻었습니다.
발명가 정량화된 틱 데이터
국내 틱 데이터가 진짜 틱은 아니지만, 이 데이터를 백테스팅에 사용하면 적어도 현실에 무한히 가깝게 접근하여 복원할 수 있습니다. 각 틱은 당시 시장의 상품의 주요 매개변수를 표시하며, 실제 시장에서는 초당 2회의 이론적인 틱 속도에 따라 코드가 계산됩니다.
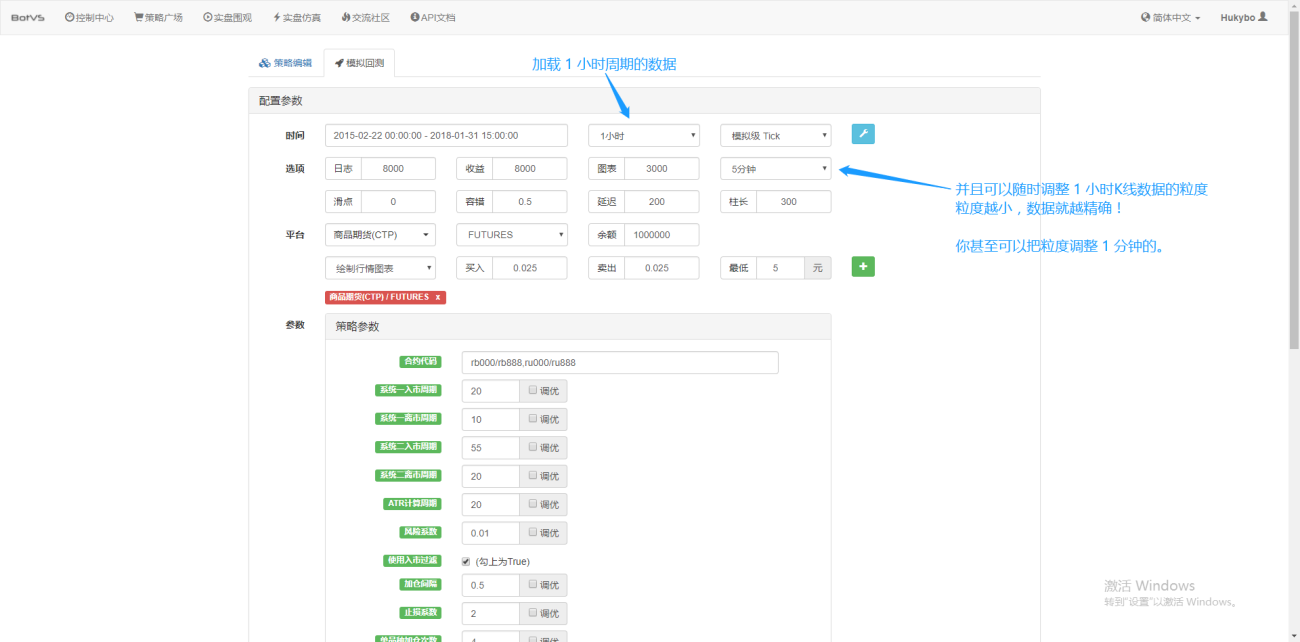
뿐만 아니라 Inventor Quantification에서는 1시간 분량의 데이터를 로드하더라도 데이터 세분성을 1분 단위로 조정하는 등 데이터 세분성을 조정할 수 있습니다. 현재 1시간 K-라인은 1분 데이터로 구성되어 있습니다. 물론, 입자 크기가 작을수록 정확도는 높아집니다. 더욱 강력한 점은 데이터를 실시간 틱으로 전환하면 원활하게 실시간 환경을 복원할 수 있다는 것입니다. 즉, 거래소의 실제 데이터는 초당 두 번씩 표시됩니다.
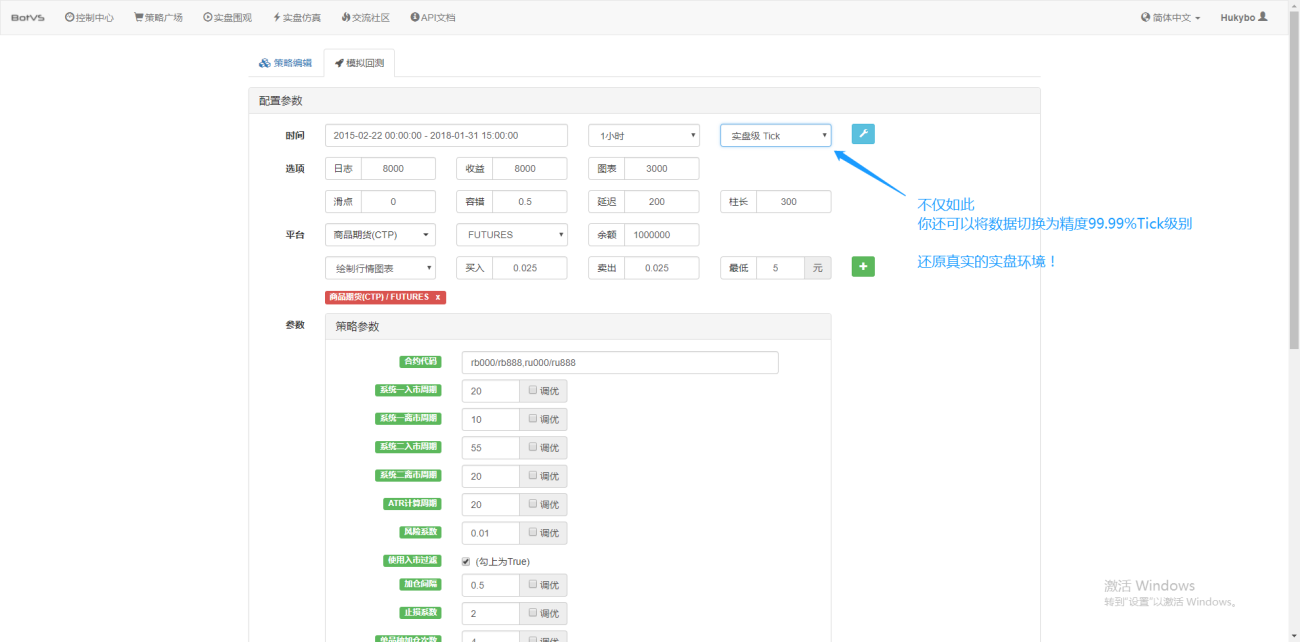
이제 이 튜토리얼을 완료하는 데 알아야 할 기본 개념을 이해하게 되었습니다. 이러한 개념에 대해서는 곧 다시 살펴보겠습니다. 이 튜토리얼의 뒷부분에서 이에 대해 더 자세히 알아보게 될 것입니다.
이 부분에 대한 자세한 내용은 https://www.fmz.com/bbs-topic/1651에서 확인하세요.
작업 환경 설정
일을 잘 하려면 먼저 도구를 날카롭게 다듬어야 합니다. Inventor Quantitative Platform에 관리자를 배치해야 합니다. 관리자 개념과 관련하여 프로그래밍 경험이 있는 독자는 공식적으로 패키징된 Docker 시스템이라고 생각할 수 있습니다. 이 시스템은 다양한 주요 거래소의 공개 API 인터페이스와 전략 작성 및 백테스팅에 대한 자세한 기술적 세부 정보를 캡슐화했습니다. 이 시스템을 구축한 원래 의도는 Inventor Quantitative Platform을 사용할 때 양적 거래자가 전략 작성 및 설계에 집중할 필요성을 덜어주는 것입니다. 이러한 기술적 세부 사항은 전략 작성자에게 패키지 형태로 제공되어 많은 번거로움을 덜어줍니다. 시간과 에너지.
- Inventor Quantitative Platform의 관리자 시스템 구축
호스트를 배포하는 방법은 두 가지가 있습니다.
방법 A: 사용자가 직접 서버를 임대하거나 구매하여 AWS, Alibaba Cloud, Digital Ocean, Google Cloud와 같은 주요 클라우드 컴퓨팅 플랫폼에 배포합니다. 장점은 전략적 보안과 시스템 보안이 모두 보장된다는 것입니다. Inventor Quantitative Platform의 경우 사용자는 이 방법을 사용하는 것이 좋습니다. 이러한 분산 배포는 서버 공격(고객이든 플랫폼 자체이든)의 위험을 제거합니다.
이 부분에 대해서는 독자들이 참조할 수 있습니다: https://www.fmz.com/bbs-topic/2848
방법 B: Inventor Quantitative Platform의 퍼블릭 서버 배포를 사용합니다. 이 플랫폼은 홍콩, 런던, 항저우에 배포를 제공합니다. 사용자는 거래하려는 거래소의 위치에 따라 근접성 원칙에 따라 배포할 수 있습니다. 이 측면의 장점은 간단하고 쉽고 클릭 한 번으로 완료할 수 있다는 것입니다. 특히 초보자에게 적합합니다. Linux 서버를 구매할 때 많은 문제를 이해할 필요가 없으며 시간과 에너지를 절약할 수도 있습니다. 리눅스 명령어를 배우는 데. 가격도 비교적 저렴해서 자금이 적은 사용자에게 적합합니다. 사용자, 플랫폼은 이 배포 방법을 사용하는 것을 권장합니다.
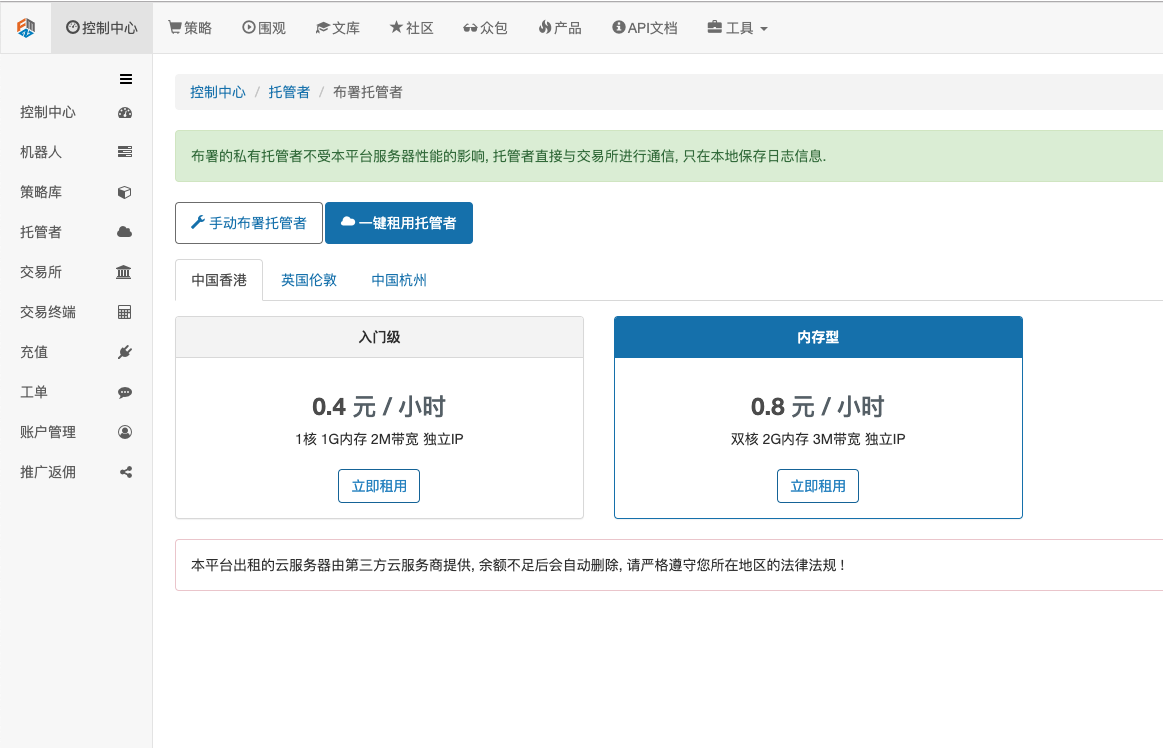
초보자의 이해를 돕기 위해 이 글에서는 방법 B를 채택하겠습니다.
구체적인 작업은 다음과 같습니다: FMZ.COM에 로그인하고, 제어 센터, 호스트를 클릭하고, 호스트 페이지에서 호스트 원클릭 임대를 클릭합니다.
비밀번호를 입력하세요. 배포가 성공적으로 완료되면 다음 그림이 표시됩니다.
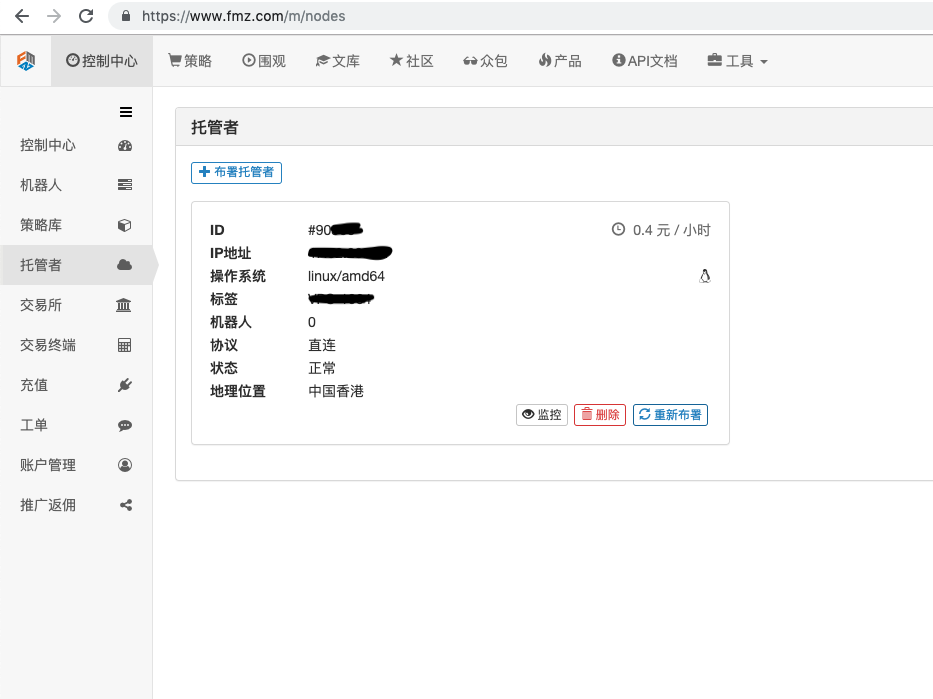
- 로봇 시스템의 개념과 호스트와의 관계
위에서 언급했듯이 호스트는 도커 시스템과 같고 도커 시스템은 표준 세트와 같습니다. 이 표준 세트를 배포한 후 이 표준에 대한 "인스턴스"를 생성해야 하며 이 "인스턴스"는 기계 인간.
로봇을 만드는 것은 매우 간단합니다. 호스트를 배포한 후 왼쪽의 로봇 열을 클릭하고 로봇 만들기를 클릭하고 레이블 이름에 이름을 입력하고 호스팅 호스트 중에서 방금 배포한 호스트를 선택합니다. 아래 대화 상자에서 매개변수 선택과 K-라인 기간은 특정 상황에 맞게 선택할 수 있으며, 주로 거래 전략 선택에 협조하기 위해 사용됩니다.
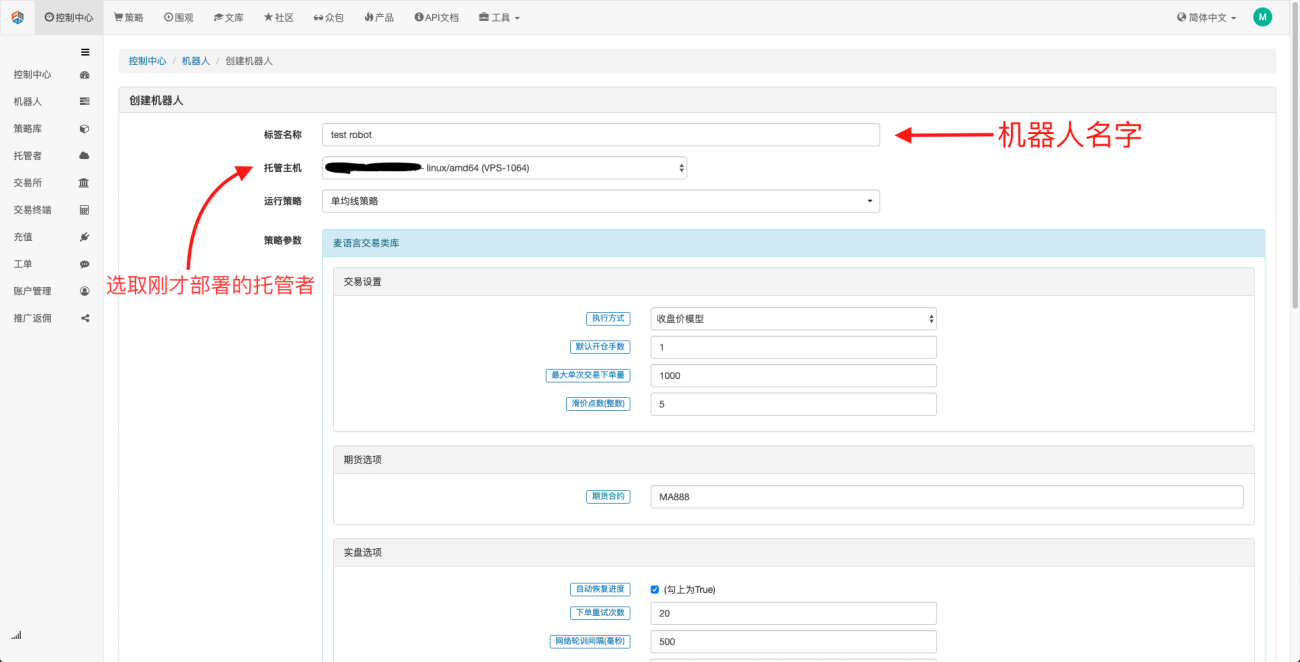
이 시점에서 우리의 작업 환경은 설정되었습니다. 보시다시피, 매우 간단하고 효과적이며, 각 기능은 자체 기능을 수행합니다. 다음으로, 양적 전략을 작성하는 것을 시작하겠습니다.
파이썬을 사용하여 간단한 이동 평균 전략 구현하기
위에서 우리는 시계열 데이터와 틱 데이터의 개념을 언급했습니다. 다음으로, 우리는 이 두 개념을 연결하기 위해 간단한 이동 평균 전략을 사용할 것입니다.
- 이동평균 전략의 기본 원리
7일 이동평균과 같은 느린 기간의 이동평균과 3일 이동평균과 같은 빠른 기간의 이동평균을 통해서입니다. 이를 같은 K-라인 차트에 적용하면, 빠르게 이동 평균선이 느리게 이동 평균선을 교차할 때를 골든 크로스라고 부르고, 느리게 이동 평균선이 빠르게 이동 평균선을 교차할 때를 데스 크로스라고 부릅니다.
포지션을 여는 기준은 골든 크로스가 나타나면 롱 주문을 열고 골든 크로스가 나타나면 숏 주문을 여는 것입니다. 포지션을 닫는 데도 같은 원칙이 적용됩니다.
FMZ.COM을 열고 계정, 제어 센터, 전략 라이브러리에 로그인하고 새로운 전략을 만들고 왼쪽 상단 모서리에 있는 전략 작성 언어에서 Python을 선택하세요. 다음은 이 전략에 대한 코드입니다. 각 줄에는 매우 자세한 주석이 있습니다. 시간을 내어 감상해 주세요. 이 전략은 라이브 전략이 아니므로 실제 돈으로 실험하지 마십시오. 주로 모든 사람에게 전략 쓰기에 대한 일반적인 아이디어와 학습 템플릿을 제공하기 위한 것입니다.
import types # 导入Types模块库,这是为了应对代码中将要用到的各种数据类型
def main(): # 主函数,策略逻辑从这里开始
STATE_IDLE = -1 # 标记持仓状态变量
state = STATE_IDLE # 标记当前持仓状态
initAccount = ext.GetAccount() #这里用到了现货数字货币交易类库(python版),编写策略时记得勾选上,作用是获得账户初始信息
while True: # 进入循环
if state == STATE_IDLE : # 这里开始开仓逻辑
n = ext.Cross(FastPeriod,SlowPeriod) # 这里用到了指标交叉函数,详情请查看https://www.fmz.com/strategy/21104
if abs(n) >= EnterPeriod : # 如果n大于等于入市观察期,这里的入市观察期是为了防止一开盘就胡乱开仓。
opAmount = _N(initAccount.Stocks * PositionRatio,3) # 开仓量,关于_N的用法,请查看官方API文档
Dict = ext.Buy(opAmount) if n > 0 else ext.Sell(opAmount) # 建立一个变量,用于存储开仓状态,并执行开仓操作
if Dict : # 查看dict变量的情况,为下面的日志输出做准备
opAmount = Dict['amount']
state = PD_LONG if n > 0 else PD_SHORT # PD_LONG和PD_SHORT均为全局常量,分别用来表示多头和空头仓位。
Log("开仓详情",Dict,"交叉周期",n) # 日志信息
else: # 这里开始平仓逻辑
n = ext.Cross(ExitFastPeriod,ExitSlowPeriod) # 指标交叉函数,
if abs(n) >= ExitPeriod and ((state == PD_LONG and n < 0) or (state == PD_SHORT and n > 0)) : # 如果经过了离市观察期且当前账户状态为持仓状态,进而判断金叉或者死叉
nowAccount = ext.GetAccount() # 再次刷新和获取账户信息
Dict2 = ext.Sell(nowAccount.Stocks - initAccount.Stocks) if state == PD_LONG else ext.Buy(initAccount.Stocks - nowAccount.Stocks) # 平仓逻辑,是多头就平多头,是空头就平空头。
state = STATE_IDLE # 标记平仓后持仓状态。
nowAccount = ext.GetAccount() # 再次刷新和获取账户信息
LogProfit(nowAccount.Balance - initAccount.Balance,'钱:',nowAccount.Balance,'币:',nowAccount.Stocks,'平仓详情:',Dict2,'交叉周期:',n) # 日志信息
Sleep(Interval * 1000) # 循环暂停一秒,防止API访问频率过快导致账户被限制。
- 이동 평균 전략의 백테스팅
전략 편집 페이지에서 전략 작성을 완료했습니다. 다음으로, 이 전략이 과거 시장 상황에서 어떤 성과를 보이는지 백테스트를 해야 합니다. 백테스트는 모든 정량적 전략의 개발에서 중요한 역할을 하지만, 또한 It 중요한 참고 자료가 될 수 있습니다. 백테스팅은 수익 보장을 의미하지 않습니다. 시장은 끊임없이 변화하기 때문입니다. 백테스팅은 단지 후견지식의 행위일 뿐이며 여전히 귀납의 범주에 속합니다. 시장은 연역적입니다.
시뮬레이션 백테스트를 클릭하면 조정 가능한 매개변수가 많이 있고, 이를 직접 수정할 수 있습니다. 전략이 점점 더 복잡해지고 매개변수 수가 증가함에 따라 이러한 수정 방법을 사용하면 사용자가 다음을 수행하지 않아도 됩니다. 코드에서 하나씩 수정하세요. 수정 과정은 번거롭지 않고 빠르고 쉽고 명확하게 정리되어 있습니다.
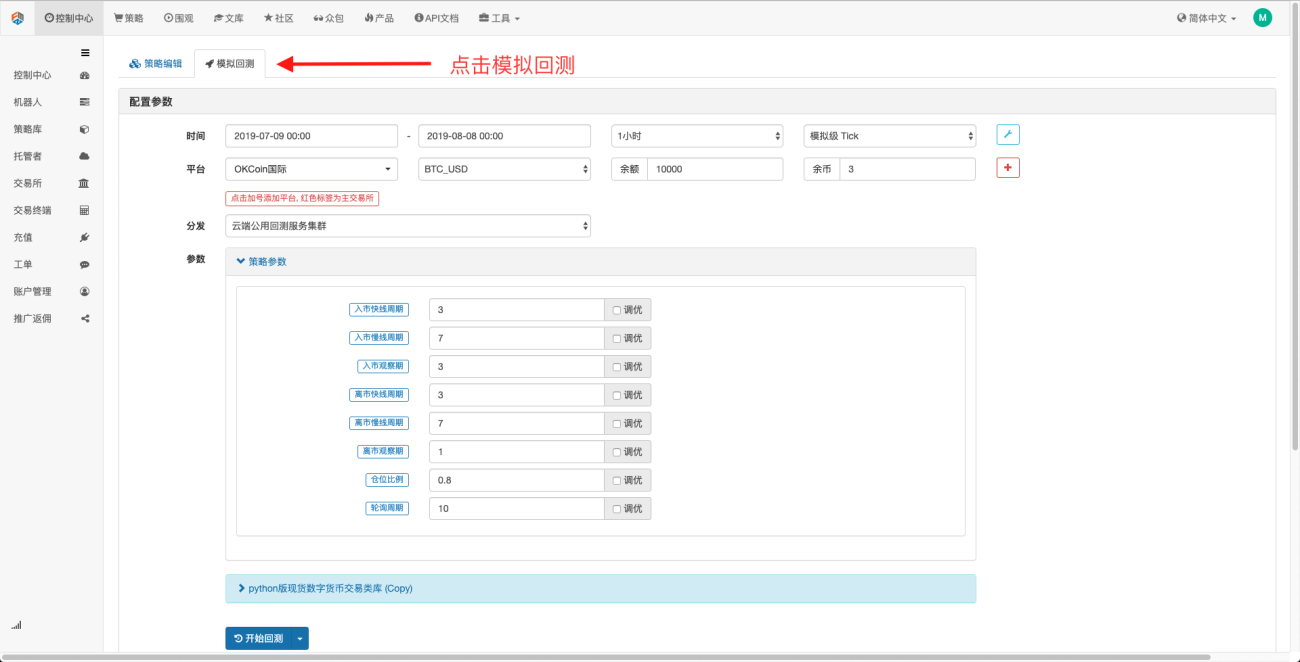
이후의 튜닝 옵션은 설정된 매개변수를 자동으로 최적화할 수 있습니다. 시스템은 다양한 최적 매개변수를 시도하여 전략 개발자가 최상의 선택을 찾을 수 있도록 돕습니다.
위의 예에서 우리는 양적 거래의 기초가 시계열 데이터 분석과 틱 데이터 백테스팅 간의 상호작용이라는 것을 알 수 있습니다. 논리가 아무리 복잡하더라도 이 두 가지 기본 요소와 분리할 수 없습니다. 차이점은 바로 차원입니다. 예를 들어, 고빈도 거래에는 더 자세한 데이터 섹션과 더 풍부한 시계열 데이터가 필요합니다. 예를 들어, 차익거래는 백테스트 샘플에 비교적 많은 양의 데이터가 필요합니다. 두 거래 대상에 대한 10년 이상의 지속적인 심층 데이터가 필요할 수 있으며, 금리 스프레드의 확장과 수축에 대한 통계적 결과를 찾아야 할 수도 있습니다. 향후 기사에서는 고빈도 트레이딩과 차익거래 전략을 소개할 예정이니 기대해주시기 바랍니다.
- 1