

페어 트레이딩은 수학적 분석에 기반한 트레이딩 전략을 개발하는 좋은 예입니다. 이 글에서는 데이터를 활용하여 페어 트레이딩 전략을 만들고 자동화하는 방법을 보여드리겠습니다.
기본 원칙
펩시와 코카콜라처럼 두 회사가 모두 같은 제품을 생산하는 것처럼 서로 상관관계가 있는 두 투자 X와 Y가 있다고 가정해 보겠습니다. 두 가지 가격 비율 또는 기준(스프레드라고도 함)은 시간이 지나도 일정하게 유지되기를 원합니다. 그러나 두 통화쌍 간의 스프레드는 대량의 매수/매도 주문, 한 투자 대상에 대한 중요 뉴스에 대한 반응 등 일시적인 공급과 수요 변화로 인해 수시로 달라질 수 있습니다. 이 경우, 한 투자는 상대적으로 상승하고 다른 투자는 하락합니다. 시간이 지남에 따라 이러한 차이가 정상화될 것으로 예상되면 거래 기회(또는 차익 거래 기회)를 발견할 수 있습니다. 이런 차익거래 기회는 디지털 화폐 시장이나 국내 상품 선물 시장에 어디에나 존재합니다. 여기에는 BTC와 안전 자산의 관계, 선물 시장에서의 대두박, 대두유, 대두 품종의 관계가 포함됩니다.
일시적인 가격 차이가 있을 때, 거래는 성과가 좋은 투자(상승한 투자)를 매도하고 성과가 나쁜 투자(하락한 투자)를 매수합니다. 두 투자 사이에 차이가 있다는 것을 확신할 수 있습니다. 스프레드는 결국 실적이 좋은 투자가 하락하거나 실적이 나쁜 투자가 다시 상승하거나, 둘 다에 의해 반영될 것입니다. 귀하의 거래는 이 모든 시나리오에서 수익을 낼 것입니다. 투자 금액 간의 차이가 변하지 않고 투자 금액이 함께 상승하거나 하락한다면, 돈을 벌거나 잃을 일이 없습니다.
따라서 페어 트레이딩은 트레이더가 상승세, 하락세 또는 횡보세 등 거의 모든 시장 상황에서 수익을 낼 수 있는 시장 중립적 트레이딩 전략입니다.
개념 설명: 두 가지 가상 투자 대상
- Inventor Quantitative Platform에서 연구 환경 구축
우선, 원활하게 작업하기 위해서는 연구 환경을 구축해야 합니다. 이 글에서는 Inventor Quantitative Platform(FMZ.COM)을 사용하여 연구 환경을 구축합니다. 주로 편리하고 빠른 API를 사용할 수 있도록 하기 위해서입니다. 나중에 이 플랫폼의 인터페이스와 캡슐화. 완전한 Docker 시스템.
Inventor Quantitative Platform의 공식 명칭에서는 이 Docker 시스템을 호스트 시스템이라고 합니다.
호스트와 로봇을 배치하는 방법에 대한 자세한 내용은 이전 기사를 참조하세요: https://www.fmz.com/bbs-topic/4140
자체 클라우드 컴퓨팅 서버 배포 호스트를 구매하려는 독자는 이 기사를 참조하세요: https://www.fmz.com/bbs-topic/2848
클라우드 컴퓨팅 서비스와 호스트 시스템을 성공적으로 배포한 후 가장 강력한 Python 도구인 Anaconda를 설치합니다.
이 문서에 필요한 모든 관련 프로그램 환경(종속 라이브러리, 버전 관리 등)을 구현하기 위한 가장 쉬운 방법은 Anaconda를 사용하는 것입니다. 이는 패키지된 Python 데이터 과학 생태계 및 종속성 관리자입니다.
Anaconda 설치 방법은 Anaconda 공식 가이드를 참조하세요: https://www.anaconda.com/distribution/
이 글에서는 Python 과학 컴퓨팅에서 매우 인기 있고 중요한 라이브러리인 numpy와 pandas를 사용할 것입니다.
위의 기본 작업에 대해서는 Anaconda 환경과 numpy, pandas 두 라이브러리를 설정하는 방법을 소개하는 이전 기사를 참조할 수도 있습니다. 자세한 내용은 https://www.fmz.com/digest-를 참조하세요. 주제/4169
다음으로, 코드를 사용하여 "두 개의 가상 투자 대상"을 구현해 보겠습니다.
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
네, Python의 매우 유명한 차트 라이브러리인 matplotlib도 사용할 것입니다.
가상의 투자 자산 X를 생성하고 정규 분포를 사용하여 일일 수익률을 표시하는 것을 시뮬레이션해 보겠습니다. 그런 다음 누적 합계를 계산하여 일일 X 값을 구합니다.
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
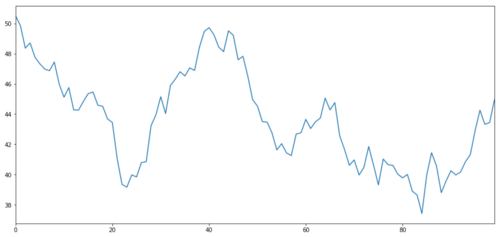
투자 목표 X를 시뮬레이션하고 정규 분포를 통해 일일 수익률을 도출합니다.
이제 X와 강력하게 상관관계가 있는 Y를 생성합니다. 즉, Y의 가격은 X의 변화와 매우 유사하게 움직여야 합니다. 우리는 X를 취하고 이를 위로 이동한 다음 정규 분포에서 추출한 무작위 노이즈를 추가하여 이를 모델링합니다.
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
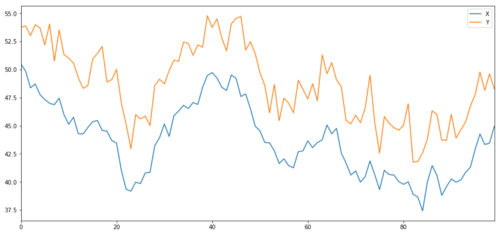
투자 대상 X와 Y를 공적분화
공적분
공적분은 상관관계와 매우 유사합니다. 즉, 두 데이터 시리즈 간의 비율이 평균을 중심으로 변합니다. 두 시리즈 Y와 X는 다음을 따릅니다.
Y = ⍺ X + e
여기서 ⍺는 상수 비율이고 e는 잡음입니다.
두 시계열 간의 거래 쌍의 경우, 시간 경과에 따른 비율의 기대값은 평균으로 수렴해야 합니다. 즉, 공적분되어야 합니다. 위에서 구성한 시계열은 공적분입니다. 이제 두 가지 사이의 척도를 그려서 어떻게 보일지 확인해 보겠습니다.
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
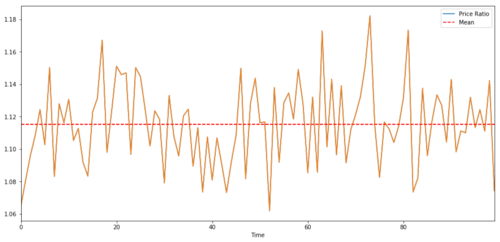
두 공적분 투자의 가격 비율과 평균
공적분 검정
이를 테스트하는 편리한 방법은 statsmodels.tsa.stattools를 사용하는 것입니다. 우리는 가능한 한 공적분된 두 데이터 시리즈를 인위적으로 생성했기 때문에 매우 낮은 p-값을 볼 수 있습니다.
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
결과는: 1.81864477307e-17
참고사항: 상관관계와 공적분
상관관계와 공적분은 이론적으로는 유사하지만 동일하지는 않습니다. 상관관계는 있지만 공적분은 아닌 데이터 시리즈의 예를 살펴보겠습니다. 그리고 그 반대의 경우도 마찬가지입니다. 먼저 방금 생성한 급수의 상관관계를 확인해 보겠습니다.
X.corr(Y)
결과는 0.951입니다.
예상대로 이는 매우 높습니다. 하지만 상관관계는 있지만 공적분은 아닌 두 시계열은 어떨까요? 간단한 예로는 두 개의 데이터 시리즈가 발산하는 경우가 있습니다.
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
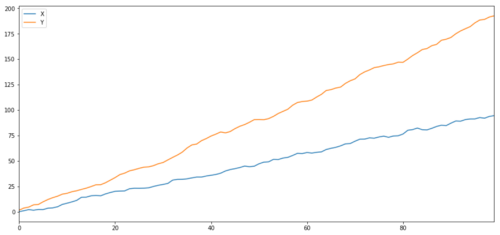
두 개의 관련 시리즈(공적분되지 않음)
상관 계수 : 0.998
공적분 검정 p-값: 0.258
상관관계가 없는 공적분의 간단한 예로는 정규 분포된 급수와 사각파가 있습니다.
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
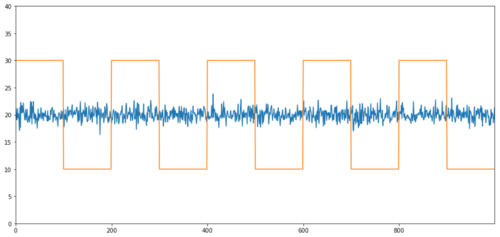
상관관계: 0.007546
공적분 검정 p-값: 0.0
상관관계는 매우 낮지만 p값은 완벽한 공적분을 보여줍니다!
페어 트레이딩은 어떻게 하나요?
두 개의 공적분 시계열(위의 X와 Y 등)이 서로 가까워지기도 하고 멀어지기도 하므로, 높은 기저와 낮은 기저가 존재할 때가 있습니다. 우리는 한 투자를 매수하고 다른 투자를 매도하여 페어 트레이딩을 수행합니다. 이런 방식으로 두 투자 대상이 동시에 하락하거나 상승하더라도 우리는 돈을 벌지도 잃지도 않습니다. 즉, 우리는 시장 중립적입니다.
위의 Y = ⍺ X + e에서 X와 Y로 돌아가서, 우리는 비율(Y/X)을 평균 ⍺ 주위로 이동시켜 돈을 벌 수 있습니다. 이를 위해, 우리는 X가 ⍺의 값이 너무 클 때를 주목합니다. 높거나 너무 낮음, ⍺ 값이 너무 높거나 너무 낮습니다.
-
롱 비율: 비율 ⍺가 작고 앞으로 커질 것으로 예상되는 경우입니다. 위의 예에서 우리는 Y를 롱 포지션, X를 숏 포지션으로 포지션을 시작합니다.
-
단기 비율: 이는 비율 ⍺가 크고 이 비율이 더 작아질 것으로 예상되는 경우입니다. 위의 예에서 우리는 Y를 단기로 매수하고 X를 장기로 매수하여 포지션을 시작합니다.
우리는 항상 "헤지 포지션"을 갖고 있다는 점에 유의하세요. 기초 자산인 롱 포지션이 가치를 잃으면 숏 포지션이 수익을 내고, 그 반대의 경우도 마찬가지이므로 전반적인 시장 움직임에 영향을 받지 않습니다.
자산 X와 Y가 상대적으로 움직임에 따라, 우리는 돈을 벌거나 잃습니다.
데이터를 사용하여 유사한 행동을 보이는 거래를 찾으세요
이를 수행하는 가장 좋은 방법은 공적분일 가능성이 있는 거래부터 시작하여 통계적 검정을 수행하는 것입니다. 모든 거래 쌍에 대해 통계 테스트를 수행하면다중 비교 편향피해자.
다중 비교 편향많은 수의 검정을 실행해야 하기 때문에, 많은 수의 검정을 실행할 때 유의미한 p-값을 잘못 생성할 가능성이 커지는 상황을 말합니다. 만약 우리가 무작위 데이터에 대해 이 테스트를 100번 실행한다면, 0.05보다 낮은 p-값이 5개 나올 것입니다. 공적분에 대해 n개의 도구를 비교하는 경우, n(n-1)/2개의 비교를 수행하게 되고, 많은 잘못된 p-값이 나타나며, 이는 테스트 샘플 크기가 증가함에 따라 증가합니다. 그리고 증가합니다. 이를 피하려면 공적분될 가능성이 있다고 생각되는 거래 쌍 몇 개를 선택한 다음 개별적으로 테스트하세요. 이렇게 하면 크게 줄어들 것입니다다중 비교 편향。
따라서 공적분을 보이는 몇 가지 도구를 찾아보도록 합시다. S&P 500의 미국 대형 기술 주식 바구니를 살펴보겠습니다. 이러한 도구는 유사한 시장 세그먼트에서 운영되고 공적분을 보입니다. 가격. 우리는 거래 도구 목록을 검토하고 모든 쌍 사이의 공적분을 테스트합니다.
반환된 공적분 검정 점수 행렬, p-값 행렬 및 p-값이 0.05 미만인 모든 쌍별 일치가 포함됩니다.이 방법은 다중 비교 편향이 발생하기 쉽기 때문에 실제로는 2차 검증을 수행해야 합니다. 이 글에서는 설명의 편의를 위해 예에서 이 부분을 무시하기로 했습니다.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
참고: 우리는 데이터에 시장 벤치마크(SPX)를 포함했습니다. 시장은 많은 악기의 흐름을 주도하며 종종 공적분된 것처럼 보이는 두 악기를 발견할 수 있습니다. 그러나 실제로는 서로 공적분되지 않습니다. 시장. 이를 교란 변수라고 합니다. 찾은 모든 관계에서 시장 참여를 조사하는 것이 중요합니다.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

이제 우리의 방법을 사용하여 공적분 거래 쌍을 찾아보겠습니다.
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
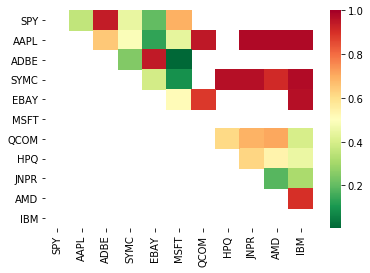
'ADBE'와 'MSFT'는 공적분인 것 같습니다. 가격이 실제로 합리적인지 살펴보겠습니다.
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
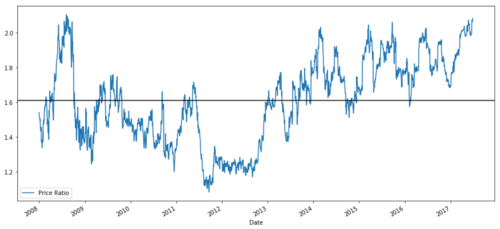
2008년부터 2017년까지 MSFT와 ADBE의 가격 비율 차트
이 비율은 안정적인 평균처럼 보입니다. 절대비율은 통계적으로 그다지 유용하지 않습니다. 신호를 z-점수로 보고 정규화하는 것이 더 도움이 됩니다. Z 점수는 다음과 같이 정의됩니다.
Z Score (Value) = (Value — Mean) / Standard Deviation
경고하다
실제로 우리는 일반적으로 데이터에 어느 정도의 확장을 적용하려고 하지만, 이는 데이터가 정규 분포를 따르는 경우에만 해당합니다. 그러나 많은 금융 데이터는 정규적으로 분포되지 않기 때문에 통계를 생성할 때 단순히 정규성이나 어떤 특정 분포를 가정하지 않도록 매우 주의해야 합니다. 비율의 실제 분포는 꼬리가 굵을 수 있으며, 극단적인 경향을 보이는 데이터는 모델을 혼란스럽게 만들어 막대한 손실로 이어질 수 있습니다.
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
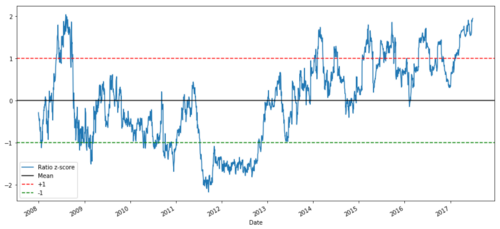
2008년부터 2017년까지 MSFT와 ADBE 간의 Z-Price 비율
이제 비율이 평균 주위에서 어떻게 움직이는지 더 쉽게 볼 수 있지만 때로는 평균으로부터 크게 벗어나는 경우가 있는데, 이를 이용할 수 있습니다.
이제 우리는 페어 트레이딩 전략의 기본을 논의하고 가격 이력을 기반으로 공적분 목표를 식별했으므로 트레이딩 신호를 개발해 보겠습니다. 먼저 데이터 기술을 사용하여 거래 신호를 개발하는 단계를 살펴보겠습니다.
-
신뢰할 수 있는 데이터 수집 및 데이터 정리
-
데이터에서 거래 신호/논리를 식별하기 위한 함수 생성
-
특징은 이동 평균 또는 가격 데이터, 보다 복잡한 신호의 상관 관계 또는 비율이 될 수 있습니다. 이를 결합하여 새로운 특징을 만듭니다.
-
이러한 기능을 사용하여 거래 신호(예: 매수, 매도 또는 단기 포지션)를 생성합니다.
다행히도, 우리는 위의 네 가지 측면을 완성해 줄 Inventor Quantitative Platform(fmz.com)을 가지고 있습니다. 이것은 전략 개발자에게 큰 축복입니다. 우리는 우리의 에너지와 시간을 전략 논리, 디자인 및 기능 확장에 사용할 수 있습니다.
Inventor Quantitative Platform에는 다양한 주류 거래소의 패키지 인터페이스가 있습니다. 우리가 해야 할 일은 이러한 API 인터페이스를 호출하는 것뿐입니다. 나머지 기본 구현 로직은 전문가 팀에 의해 다듬어졌습니다.
논리적인 완전성과 원리에 대한 설명을 위해 이러한 기본 논리를 자세히 제시하겠지만, 실제 운영에서는 독자가 Inventor Quant의 API 인터페이스를 직접 호출하여 위의 네 가지 측면을 완료할 수 있습니다.
시작해 봅시다:
1단계: 문제 설정
여기서 우리는 다음 순간에 비율이 매수가 될지 매도가 될지 알려주는 신호, 즉 예측 변수 Y를 생성하려고 합니다.
Y = Ratio is buy (1) or sell (-1)
Y(t)= Sign(Ratio(t+1) — Ratio(t))
기초 자산의 실제 가격이나 비율의 실제 가치를 예측할 필요는 없습니다(물론 예측할 수는 있지만). 그 다음에는 비율의 방향만 예측하면 됩니다.
2단계: 신뢰할 수 있고 정확한 데이터 수집
발명가 퀀트가 당신의 친구입니다! 거래하고 싶은 상품과 사용하고 싶은 데이터 소스를 지정하기만 하면, 필요한 데이터를 추출하여 배당금과 상품 분할에 맞춰 정리해줍니다. 그러니 여기 있는 우리의 데이터는 이미 매우 깨끗합니다.
우리는 지난 10년간의 거래일을 위해 Yahoo Finance에서 다음 데이터를 사용했습니다(약 2,500개 데이터 포인트): 시작가, 마감가, 최고가, 최저가, 거래량
3단계: 데이터 분할
모델의 정확도를 테스트하는 매우 중요한 단계를 잊지 마세요. 우리는 다음과 같은 데이터 훈련/검증/테스트 분할을 사용하고 있습니다.
-
Training 7 years ~ 70%
-
Test ~ 3 years 30%
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
이상적으로는 검증 세트도 만들었겠지만 지금은 그렇게 하지 않겠습니다.
4단계: 기능 엔지니어링
관련 기능은 무엇일까요? 우리는 비율 변화의 방향을 예측하고 싶습니다. 우리는 두 도구가 공적분되어 있음을 확인했으므로 이 비율은 이동하여 평균으로 회귀하는 경향이 있습니다. 우리의 특징은 비율의 평균을 측정하는 것 같고, 현재 값과 평균의 차이가 거래 신호를 생성할 수 있습니다.
우리는 다음과 같은 기능을 사용합니다:
-
60일 이동평균 비율: 이동평균의 측정
-
5일 이동평균 비율: 평균의 현재 가치를 측정하는 지표
-
60일 표준편차
-
z-점수: (5일 MA - 60일 MA) / 60일 SD
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
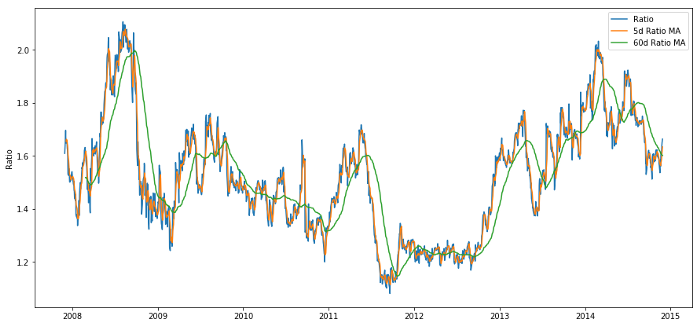
60d와 5d MA의 가격 비율
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
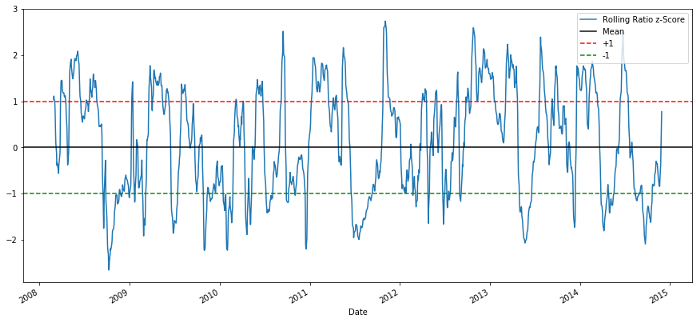
60-5 Z-점수 가격 비율
이동 평균의 Z-점수는 비율의 평균 회귀 특성을 잘 보여줍니다!
5단계: 모델 선택
매우 간단한 모델부터 시작해 보겠습니다. z-점수 그래프를 살펴보면 z-점수가 너무 높거나 낮을 때마다 회귀하는 것을 볼 수 있습니다. +1/-1을 임계값으로 사용하여 너무 높거나 너무 낮음을 정의한 다음 다음 모델을 사용하여 거래 신호를 생성할 수 있습니다.
-
z가 -1.0보다 낮을 경우, 우리는 z가 0으로 돌아올 것으로 예상하기 때문에 비율이 매수(1)가 되므로 비율이 증가합니다.
-
z가 1.0보다 높으면 z가 0으로 돌아갈 것으로 예상되므로 비율이 매도(-1)가 됩니다.
6단계: 훈련, 검증 및 최적화
마지막으로, 우리 모델이 실제 데이터에 미치는 실제적인 영향을 살펴보겠습니다. 이 신호가 실제 비율에서 어떻게 동작하는지 살펴보겠습니다.
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
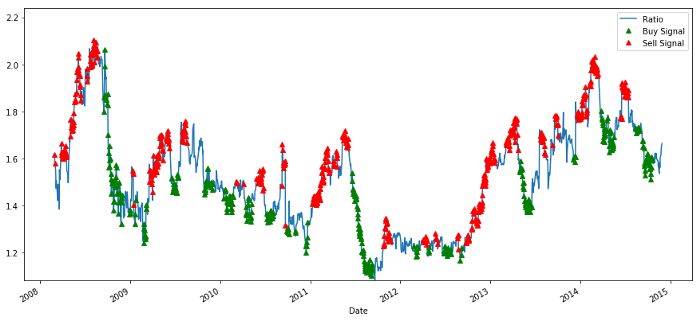
매수 및 매도 가격 비율 신호
이 신호는 타당한 것으로 보이며, 비율이 높거나 증가할 때(빨간색 점) 매도하고, 비율이 낮고(녹색 점) 감소할 때 매수하는 것이 좋습니다. 이는 실제 거래 주제와 관련하여 무엇을 의미합니까? 보자
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
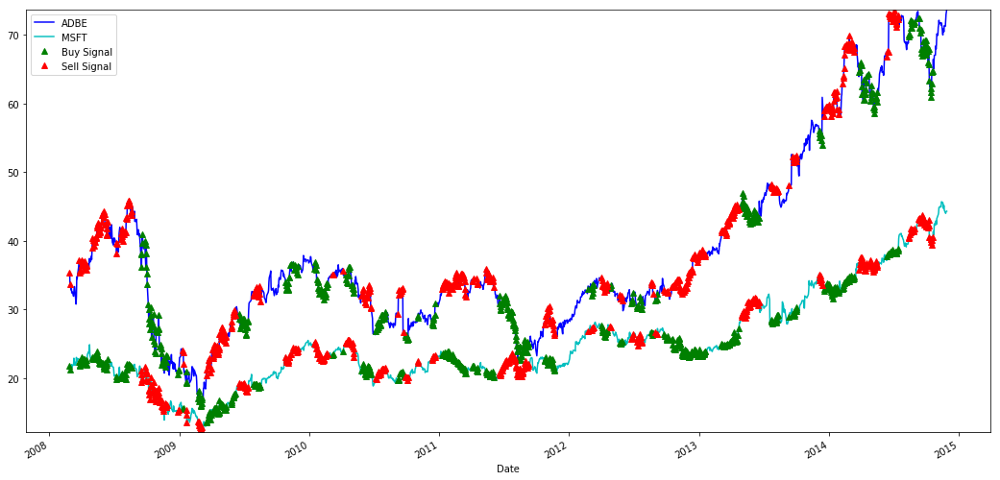
MSFT 및 ADBE 주식 매수 및 매도 신호
때로는 "단기"로 돈을 벌기도 하고, 때로는 "장기"로 돈을 벌기도 하고, 때로는 둘 다로 돈을 벌기도 한다는 점에 유의하세요.
우리는 훈련 데이터의 신호에 만족합니다. 이 신호가 어떤 종류의 이익을 낼 수 있는지 살펴보겠습니다. 비율이 낮을 때 1개의 ADBE 주식을 매수하고 비율 x MSFT 주식을 매도하는 간단한 백테스터를 만들고 1개의 ADBE 주식을 매도하고 비율 x MSFT 주식을 콜하는 비율 x MSFT 주식을 매도하여 이에 대한 PnL 거래를 계산할 수 있습니다. 비율.
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
결과는: 1783.375
그러니 이 전략은 수익성이 있는 것 같네요! 이제 이동 평균 시간 창을 변경하고 매수/매도 및 마감 포지션에 대한 임계값을 변경하는 등의 방법으로 추가로 최적화하고 검증 데이터의 성능 개선 사항을 확인할 수 있습니다.
1/-1 예측을 위해 로지스틱 회귀, SVM 등과 같은 보다 복잡한 모델을 시도할 수도 있습니다.
이제 이 모델을 발전시켜 보겠습니다.
7단계: 테스트 데이터 백테스트
여기서 저는 Inventor Quantitative Platform을 언급하고 싶습니다. 그것은 고성능 QPS/TPS 백테스팅 엔진을 사용하여 역사적 환경을 진정으로 재현하고, 일반적인 양적 백테스팅 함정을 제거하고, 전략의 단점을 신속하게 발견하여 실제를 더 잘 제공합니다. -시간 투자. 도움을 제공하세요.
이 글에서는 원리를 설명하기 위해 기본 논리를 보여주기로 했습니다. 실제 적용에서는 독자들이 Inventor Quantitative Platform을 사용하는 것이 좋습니다. 시간을 절약하는 것 외에도 중요한 것은 결함 허용률을 개선하는 것입니다.
백테스팅은 간단합니다. 위의 함수를 사용하여 테스트 데이터의 PnL을 볼 수 있습니다.
trade(data[‘ADBE’].iloc[1762:], data[‘MSFT’].iloc[1762:], 60, 5)
결과는 5262.868입니다.
이 모델은 정말 잘 만들어졌어요! 이는 우리의 첫 번째 간단한 페어 트레이딩 모델이 되었습니다.
과잉 맞춤을 피하세요
마무리하기 전에 과잉적합에 대해 구체적으로 이야기하고 싶습니다. 과도한 적합은 거래 전략에서 가장 위험한 함정입니다. 과대적합 알고리즘은 백테스팅에서는 매우 좋은 성능을 보일 수 있지만, 새로운 보이지 않는 데이터에서는 실패할 수 있습니다. 즉, 데이터의 추세를 전혀 보여주지 않으며 실제 예측 능력이 없습니다. 간단한 예를 들어보겠습니다.
우리 모델에서는 롤링 매개변수 추정치를 사용하고 시간 창 길이를 최적화하고자 합니다. 우리는 모든 가능성과 합리적인 시간 창 길이를 반복하고, 모델이 가장 좋은 성과를 내는 데 기반한 시간 길이를 선택하기로 결정할 수도 있습니다. 아래에서는 훈련 데이터의 PNL을 기준으로 시간 창 길이를 평가하고 가장 좋은 루프를 찾는 간단한 루프를 작성합니다.
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
이제 테스트 데이터에서 모델의 성능을 확인해보니 이 시간 창 길이는 최적과는 거리가 멀다는 걸 알 수 있었습니다! 이는 우리가 원래 선택한 것이 샘플 데이터에 분명히 과적합되었기 때문입니다.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
명백히 우리의 샘플 데이터에 효과적인 방법이 항상 미래에도 좋은 결과를 가져오는 것은 아닙니다. 테스트를 위해 두 데이터세트에서 계산된 길이 점수를 그래프로 표시해 보겠습니다.
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
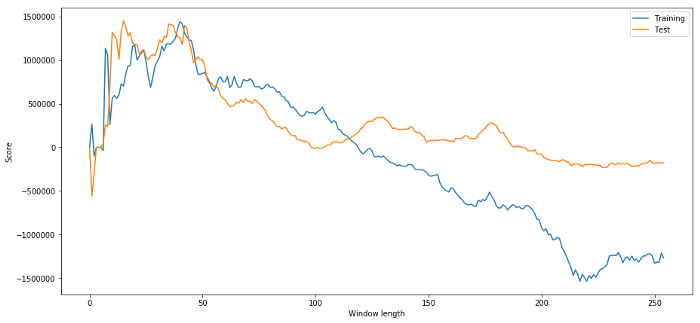
시간 범위로는 20~50 사이가 좋은 선택임을 알 수 있습니다.
과도한 적합을 피하기 위해 경제적 추론이나 알고리즘의 속성을 사용하여 시간 창 길이를 선택할 수 있습니다. 또한 길이를 지정할 필요가 없는 칼만 필터를 사용할 수도 있습니다. 이 방법은 나중에 다른 기사에서 다루겠습니다.
다음 단계
이 글에서는 거래 전략을 개발하는 과정을 보여주는 몇 가지 간단한 소개 방법을 제시합니다. 실제로는 더욱 정교한 통계를 사용해야 하며, 다음 옵션을 고려할 수 있습니다.
-
허스트 지수
-
Ornstein-Uhlenbeck 공정에서 추론된 평균 회귀의 반감기
-
칼만 필터
