
Penjelasan lengkap tentang kelebihan dan kekurangan tiga kategori utama dan enam algoritma utama pembelajaran mesin
Dalam pembelajaran mesin, matlamatnya adalah untuk meramalkan (prediction) atau untuk mengelompokkan (clustering). Di sini, fokusnya adalah pada ramalan. Ramalan adalah proses untuk meramalkan nilai variabel output dari sekumpulan pembolehubah input. Sebagai contoh, dengan sekumpulan ciri mengenai rumah, kita dapat meramalkan harga penjualannya. Soalan ramalan boleh dibahagikan kepada dua kategori besar: 1) Soalan regresi: di mana pembolehubah yang akan diramalkan adalah digital (seperti harga rumah); 2) Soalan klasifikasi: di mana pembolehubah yang akan diramalkan adalah jawapan kepada soalan ya / tidak (seperti meramalkan sama ada peranti akan rosak).
Dengan ini, mari kita lihat algoritma yang paling terkenal dan paling biasa digunakan dalam pembelajaran mesin. Kami membahagikan algoritma ini kepada 3 kategori: model linear, model berasaskan pokok, dan rangkaian saraf, dengan fokus pada 6 algoritma yang paling biasa digunakan:
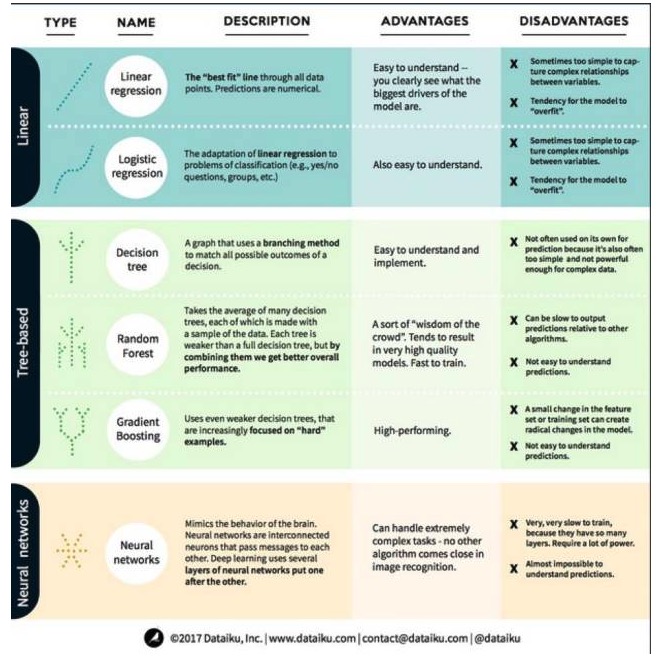
Algoritma model linear: Model linear menggunakan formula mudah untuk mencari baris yang paling sesuai dengan satu set titik data. Kaedah ini bermula lebih dari 200 tahun yang lalu dan telah digunakan secara meluas dalam bidang statistik dan pembelajaran mesin.
-
1. Regresen Linear
Regresen linear, atau lebih tepatnya regresen dua kali minimum, adalah bentuk model linear yang paling standard. Regresen linear adalah model linear yang paling mudah untuk masalah regresi. Kekurangannya adalah model mudah beradaptasi, iaitu, model menyesuaikan sepenuhnya dengan data yang telah dilatih, dengan mengorbankan keupayaan untuk menyebarkan kepada data baru.
Kelemahan lain kepada model linear adalah bahawa kerana mereka sangat mudah, mereka tidak dapat meramalkan tingkah laku yang lebih rumit apabila pembolehubah input tidak bebas.
-
2. Kembali logik
Regresen logik adalah penyesuaian regresen linear kepada masalah klasifikasi. Kelemahan regresen logik adalah sama dengan regresen linear. Fungsi logik sangat baik untuk masalah klasifikasi kerana ia memperkenalkan kesan nilai tebing.
Kedua, algoritma model pokok
-
1. Pokok keputusan
Pokok keputusan adalah grafik yang menggunakan kaedah percabangan untuk memaparkan setiap keputusan yang mungkin. Sebagai contoh, anda memutuskan untuk memesan salad, keputusan pertama anda mungkin adalah jenis sayur-sayuran, kemudian hidangan, dan kemudian salad. Kita boleh menyatakan semua keputusan yang mungkin dalam pokok keputusan.
Untuk melatih pokok keputusan, kita perlu menggunakan set data latihan dan mencari sifat mana yang paling berguna untuk sasaran. Sebagai contoh, dalam contoh penggunaan pengesanan penipuan, kita mungkin mendapati bahawa sifat yang paling memberi kesan kepada ramalan risiko penipuan adalah negara. Setelah bercabang dengan sifat pertama, kita mendapat dua subset, yang paling dapat diramalkan dengan tepat jika kita hanya tahu sifat pertama.
-
Hutan rawak
Hutan rawak adalah purata banyak pokok keputusan, di mana setiap pokok keputusan dilatih dengan sampel data rawak. Setiap pokok dalam hutan rawak lebih lemah daripada pokok keputusan yang lengkap, tetapi meletakkan semua pokok bersama-sama, kita dapat memperoleh prestasi keseluruhan yang lebih baik kerana kelebihan kepelbagaian.
Hutan rawak adalah algoritma yang sangat popular dalam pembelajaran mesin hari ini. Hutan rawak mudah dilatih dan berkinerja cukup baik. Kekurangannya adalah bahawa perkiraan output hutan rawak mungkin lambat berbanding dengan algoritma lain, jadi hutan rawak mungkin tidak dipilih apabila ramalan cepat diperlukan.
-
3 Tingkatkan
GradientBoosting, seperti hutan rawak, juga terdiri daripada pokok keputusan yang lemah dan lemah. Perbezaan terbesar antara gradientBoosting dan hutan rawak adalah bahawa dalam gradientBoosting, pokok dilatih satu demi satu.
Latihan untuk menaikkan pangkat juga cepat dan berkinerja sangat baik. Namun, perubahan kecil dalam set data latihan boleh menyebabkan model berubah secara fundamental, jadi hasilnya mungkin bukan yang paling berkesan.
3. Algoritma Jaringan Neural: Jaringan saraf adalah fenomena biologi yang terdiri daripada neuron yang saling berhubung dalam otak untuk bertukar maklumat antara satu sama lain. Gagasan ini kini digunakan dalam bidang pembelajaran mesin, yang dikenali sebagai ANN (jaringan saraf buatan). Pembelajaran mendalam adalah rangkaian saraf berlapis.
Disalin dari Big Data Land
- 1