Sokong mesin vektor dalam otak
 0
2106
0
2106
Sokong mesin vektor dalam otak
Pembantu Mesin Vektor (SVM) adalah pengelasan pembelajaran mesin yang penting, yang menggunakan transformasi bukan linear yang cerdik untuk memproyeksikan ciri dimensi rendah ke dimensi tinggi, yang dapat melakukan tugas pengelasan yang lebih kompleks. SWM seolah-olah menggunakan trik matematik, tetapi kebetulan sesuai dengan mekanisme pengekodan otak, yang dapat kita baca dari kertas Nature 2013 untuk memahami hubungan mendalam antara pembelajaran mesin dan prinsip kerja otak. Nama kertas kerja: The importance of mixed selectivity in complex cognitive tasks (by Omri Barak al. )
- #### SVM
Dari mana kita dapat melihat hubungan yang mengagumkan ini? Pertama, mari kita bercakap tentang sifat kod saraf: haiwan menerima isyarat tertentu dan bertindak mengikutnya, satu adalah mengubah isyarat luaran menjadi isyarat elektrikal saraf, dan yang lain adalah mengubah isyarat elektrikal saraf menjadi isyarat keputusan, proses pertama dipanggil pengekodan, proses kedua dipanggil penguraian. Dan tujuan sebenarnya dari kod saraf adalah untuk menguraikan dan kemudian membuat keputusan. Oleh itu, melihat kod dengan mata pembelajaran mesin, cara termudah untuk melakukannya adalah dengan melihat pembahagian, atau bahkan pembahagian linear model logistik, dan memasukkan isyarat masuk ke dalam pembahagian berdasarkan ciri-ciri tertentu.
Jadi mari kita lihat bagaimana pengekodan saraf dijalankan. Pertama, neuron boleh dilihat sebagai satu litar RC yang menyesuaikan rintangan dan kapasiti mengikut voltan luar. Apabila isyarat luaran cukup besar, ia akan disalurkan, jika tidak, ia akan ditutup, dengan frekuensi pelepasan elektrik dalam masa tertentu untuk menandakan isyarat.
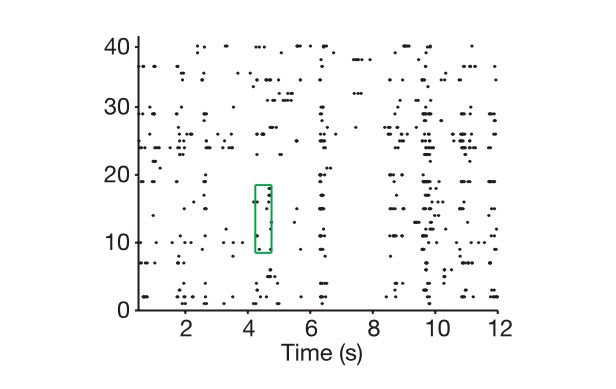
Rajah: Sel di garisan vertikal, masa di garisan lateral, menunjukkan bagaimana kita mengekstrak kod saraf
Pertama, kita masuk ke dalam ruang dimensi N yang dilambangkan oleh vektor dimensi N, dan kemudian kita memberikan semua kombinasi tugas yang mungkin, seperti menunjukkan kepada anda seribu gambar. Anggaplah gambar-gambar ini mewakili seluruh dunia, dan setiap kali kita mendapat kod saraf, kita akan menandakan satu titik di ruang ini.
Di samping dimensi sebenar kod, kita mempunyai konsep yang lain iaitu dimensi sebenar isyarat luaran, di mana isyarat merujuk kepada isyarat luaran yang diekspresikan oleh rangkaian saraf, tentu anda perlu mengulangi semua butiran isyarat luaran itu adalah masalah yang tidak terhingga, namun kita mengelas dan membuat keputusan berdasarkan yang selalu menjadi ciri-ciri utama, adalah proses pengurangan dimensi, ini juga adalah idea PCA. Di sini kita boleh melihat perubahan-perubahan utama dalam tugas sebenar sebagai dimensi sebenar tugas, contohnya anda perlu mengawal pergerakan lengan, anda biasanya hanya perlu mengawal sudut putaran sendi, jika anda menganggapnya sebagai satu masalah mekanika pepejal, dimensi mungkin tidak lebih daripada 10, kita panggil K.
Jadi, persoalan utama yang dihadapi para saintis ialah, mengapa kita perlu menyelesaikan masalah ini dengan dimensi kod dan bilangan neuron yang jauh lebih besar daripada masalah sebenar?
Neuroscience dan pembelajaran mesin bersama-sama memberitahu kita bahawa ciri-ciri tinggi neural manifestasi adalah asas untuk keupayaan pembelajaran yang kuat. Perhatikan bahawa kita tidak mulakan dengan rangkaian kedalaman.
Perhatikan bahawa pengekodan saraf yang dibincangkan di sini merujuk kepada pengekodan saraf pusat saraf yang lebih tinggi, seperti PFC yang dibincangkan dalam artikel ini, kerana undang-undang pengekodan pusat saraf yang lebih rendah tidak banyak melibatkan pengelompokan dan pengambilan keputusan.
Bahagian otak yang lebih tinggi yang diwakili oleh PFC
Pertama, kita menganggap bahawa kita tidak akan dapat menyelesaikan masalah pengelompokan yang tidak linear dengan menggunakan pengelompokan linear apabila dimensi pengekodan kita sama dengan dimensi pembolehubah penting dalam tugas sebenar (andaikan bahawa anda ingin memisahkan melon dari melon, anda tidak dapat mengasingkan melon dari melon dengan sempadan linear), dan ini adalah masalah biasa yang sukar untuk kita selesaikan ketika pembelajaran mendalam dan SVM tidak masuk ke dalam pembelajaran mesin.
SVM ((support vector machine):
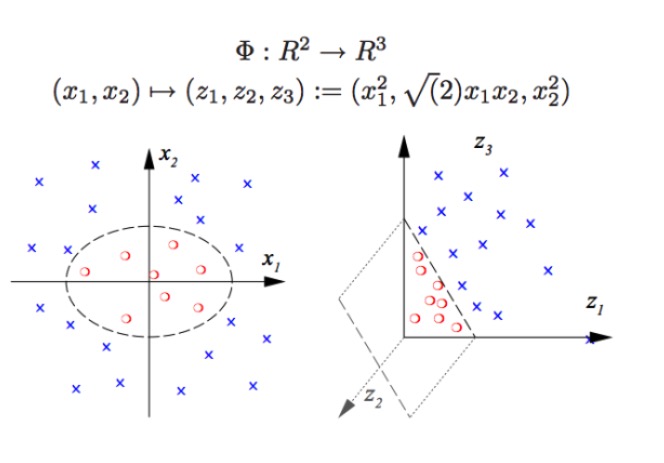
SVM boleh melakukan klasifikasi bukan linear, contohnya memisahkan titik merah dan titik biru dalam carta, dengan sempadan linear kita tidak dapat memisahkan titik merah dan titik biru (gambar kiri), oleh itu kaedah SVM adalah meningkatkan dimensi. Tetapi hanya menambah nombor pembolehubah tidak dapat dilakukan, seperti memetakan (x1, x2) ke (x1, x2, x1 + x2) sistem sebenarnya adalah ruang linear dua dimensi (gambar individu adalah titik merah dan titik biru berada di satu bidang), hanya menggunakan fungsi bukan linear (x1 ^ 2, x1)*x2, x2^2) kita akan mempunyai perpindahan dari dimensi rendah ke dimensi tinggi, dan anda akan melemparkan titik biru ke udara, dan anda akan melukis sebuah bidang di udara, dan anda akan memisahkan titik biru dari titik merah, seperti gambar di sebelah kanan.
Sebenarnya, apa yang dilakukan oleh rangkaian saraf sebenar adalah serupa. Jenis klasifikasi yang dapat dilakukan oleh pengelasa (decoder) linear seperti ini meningkat dengan ketara, yang bermaksud kita mendapat banyak keupayaan pengenalan corak yang lebih baik daripada sebelumnya. Di sini, dimensi tinggi adalah tenaga tinggi, dan pukulan dimensi tinggi adalah kebenaran.
Jadi, bagaimana untuk mendapatkan satu dimensi yang tinggi dalam pengekodan neuron? Jumlah neuron cahaya yang lebih banyak tidak berguna. Kerana kita tahu dari aljabar linear, jika kita mempunyai sejumlah besar N neuron, dan kadar pelepasan setiap neuron hanya berkaitan secara linear dengan K ciri-ciri utama, maka dimensi yang kita akan mewakili akhirnya hanya akan sama dengan dimensi masalah itu sendiri, anda N neuron tidak berfungsi (sebelum neuron yang dihasilkan adalah kombinasi linear K neuron).
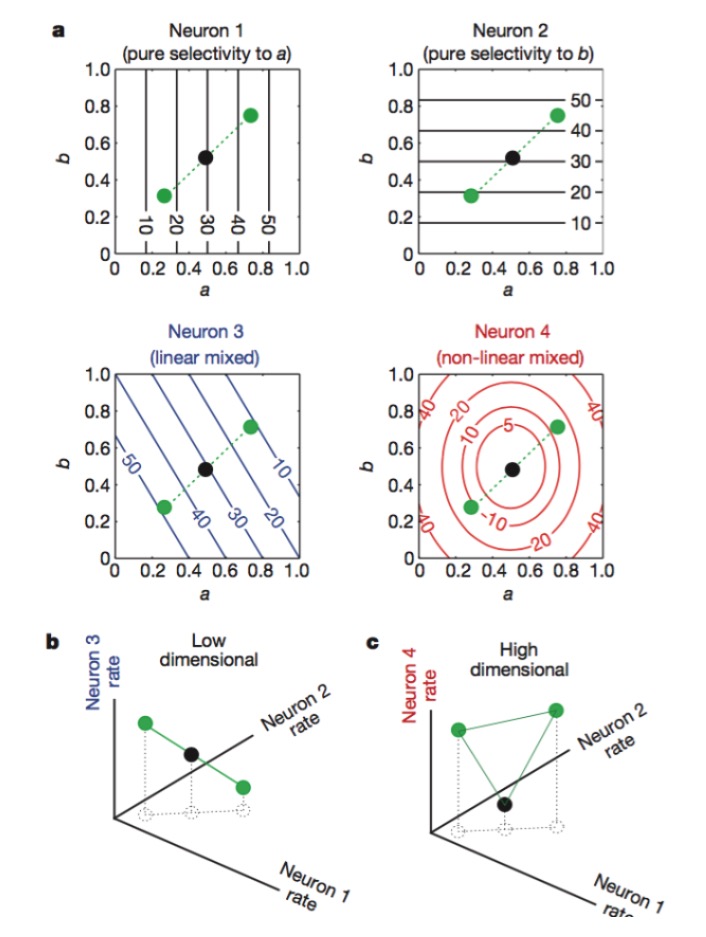
Rajah: Neuron 1 dan 2 hanya peka terhadap ciri-ciri a dan b, 3 peka terhadap campuran linier ciri-ciri a dan b, dan 4 peka terhadap campuran bukan linier ciri-ciri. Akhirnya, hanya kombinasi neuron 1, 2, 4 yang meningkatkan dimensi pengekodan saraf (gambar di bawah).
Di dalam sistem saraf sekitar, neuron berfungsi sebagai sensor untuk mengekstrak dan mengenali ciri-ciri yang berbeza dari isyarat. Fungsi setiap sel saraf adalah agak khusus, seperti rods dan cones pada retina yang bertanggungjawab untuk menerima foton, dan kemudian sel Gangelion terus mengkod, setiap neuron adalah seperti sentinel yang dilatih secara khusus. Di kawasan otak yang lebih tinggi, kerja yang jelas ini sukar untuk dilihat, dan kita mendapati bahawa neuron yang sama mungkin sensitif kepada pelbagai ciri, dan ini bukan kepekaan linear.
Setiap perincian alam semula jadi mempunyai latar belakang, banyak keterlaluan dan kod campuran yang kelihatan tidak profesional, kelihatan seperti isyarat yang berantakan, akhirnya mendapat keupayaan pengkomputeran yang lebih baik. Dengan prinsip ini, kita dapat dengan mudah menangani beberapa tugas seperti:
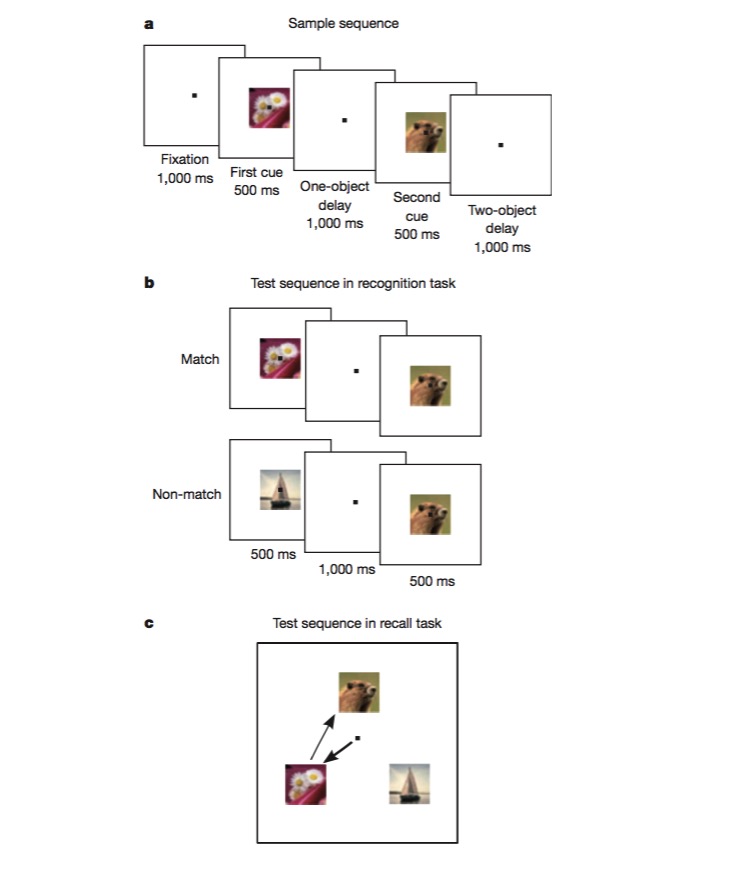
Dalam tugas ini, kelinci pertama kali dilatih untuk membezakan sama ada imej sama dengan yang sebelumnya (recognition), dan kemudian dilatih untuk menilai urutan munculnya dua imej yang berbeza (recall). Kelinci untuk menyelesaikan tugas seperti itu harus dapat mengkodkan pelbagai aspek tugas, seperti jenis tugas (recall or recognition), jenis gambar, dan lain-lain, dan ini adalah ujian yang sangat baik untuk menguji sama ada terdapat mekanisme pengekodan tidak linear campuran.
Dari artikel ini, kita tahu bahawa reka bentuk rangkaian saraf akan meningkatkan pengiktirafan corak jika kita memasukkan beberapa unit bukan linear, dan SVM telah menggunakan ini untuk menyelesaikan masalah pengelompokan bukan linear.
Kami mengkaji fungsi kawasan otak, mula dengan menggunakan kaedah pembelajaran mesin untuk memproses data, seperti mencari dimensi utama masalah dengan PCA, dan kemudian dengan memahami pengekodan saraf dan penguraian kod pemikiran yang diiktiraf oleh model pembelajaran mesin. Akhirnya, jika kita mendapat inspirasi baru, kita dapat memperbaiki kaedah pembelajaran mesin. Untuk otak atau algoritma pembelajaran mesin, yang paling penting adalah mendapatkan cara representasi yang paling tepat untuk maklumat, dan dengan representasi yang baik, semuanya mudah.
Dikutip dari Xinhua, teknologi kapal perang.