

Artikel sebelum ini memberi pengenalan awal kepada kaedah pengiraan pelbagai harga pertengahan dan memberikan semakan harga pertengahan Artikel ini terus mendalami topik ini.
Data yang diperlukan
Data aliran pesanan dan sepuluh tahap data kedalaman dikumpul daripada dagangan sebenar, dan kekerapan kemas kini ialah 100ms. Pasaran sebenar hanya mengandungi data beli dan jual, yang dikemas kini dalam masa nyata Demi kesederhanaan, ia tidak digunakan buat masa ini. Memandangkan data terlalu besar, hanya 100,000 baris data mendalam dikekalkan dan keadaan pasaran untuk setiap peringkat juga dipisahkan ke dalam lajur yang berasingan.
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
python
tick_size = 0.0001
python
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
python
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
python
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
python
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
python
depths = depths.iloc[:100000]
python
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
python
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# 应用到每一行,得到新的df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# 在原有df上进行扩展
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
python
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
python
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
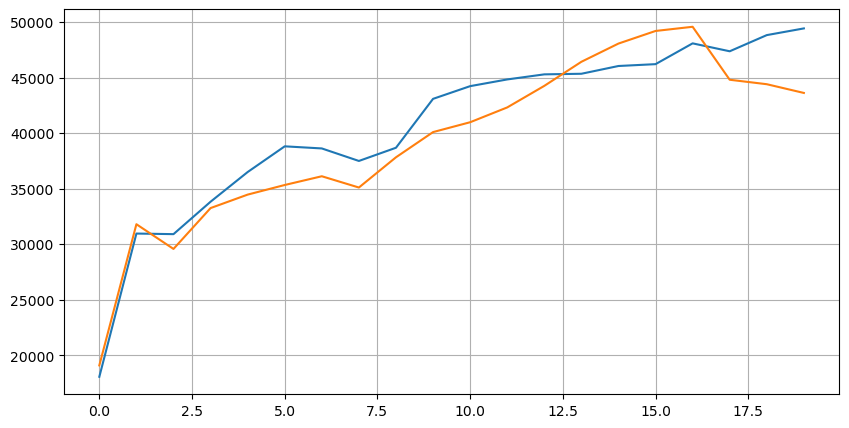
Mari kita lihat terlebih dahulu pengagihan 20 keadaan pasaran ini Ia adalah selaras dengan jangkaan Semakin jauh dari pembukaan pasaran, semakin banyak pesanan yang belum selesai, dan pesanan beli dan jualan secara kasarnya simetri.
python
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Menggabungkan data kedalaman dan data transaksi untuk memudahkan penilaian ketepatan ramalan. Di sini kami memastikan bahawa data urus niaga semuanya lewat daripada data kedalaman Tanpa mengambil kira kelewatan, kami terus mengira ralat min kuasa dua antara nilai yang diramalkan dan harga transaksi sebenar. Digunakan untuk mengukur ketepatan ramalan.
Berdasarkan keputusannya, ralat harga_tengah, purata pasangan beli-jual, adalah yang terbesar Selepas bertukar kepada harga_pertengahan_berat, ralat itu serta-merta menjadi lebih kecil, dan ia diperbaiki lagi dengan melaraskan harga pertengahan wajaran. Selepas artikel semalam diterbitkan, beberapa orang melaporkan bahawa mereka hanya menggunakan I^3/2 Saya menyemaknya di sini dan mendapati hasilnya lebih baik. Selepas memikirkan sebabnya, ia harus menjadi perbezaan dalam kekerapan peristiwa Apabila saya hampir dengan -1 dan 1, ia adalah peristiwa kebarangkalian rendah Untuk membetulkan kebarangkalian rendah ini, ramalan kejadian frekuensi tinggi Tidak begitu tepat, dalam lebih banyak lagi Untuk menjaga acara frekuensi tinggi, saya membuat beberapa pelarasan (ini adalah parameter percubaan semata-mata, dan tidak begitu berguna untuk perdagangan sebenar):
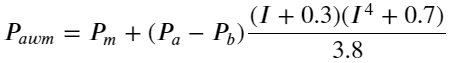
Hasilnya lebih baik sedikit. Seperti yang dinyatakan dalam artikel sebelum ini, strategi harus diramalkan dengan lebih banyak data Dengan lebih mendalam dan data pemenuhan pesanan, penambahbaikan yang boleh diperolehi dengan terjerat dengan harga pasaran sudah sangat lemah.
python
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
python
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
python
print('平均值 mid_price的误差:', ((df['price']-df['mid_price'])**2).sum())
print('挂单量加权 mid_price的误差:', ((df['price']-df['weight_mid_price'])**2).sum())
print('调整后的 mid_price的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的 mid_price_2的误差:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('调整后的 mid_price_3的误差:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
平均值 mid_price的误差: 0.0048751924999999845
挂单量加权 mid_price的误差: 0.0048373440193987035
调整后的 mid_price的误差: 0.004803654771638586
调整后的 mid_price_2的误差: 0.004808216498329721
调整后的 mid_price_3的误差: 0.004794984755260528
调整后的 mid_price_4的误差: 0.0047909595497071375
Pertimbangkan kedalaman gear kedua
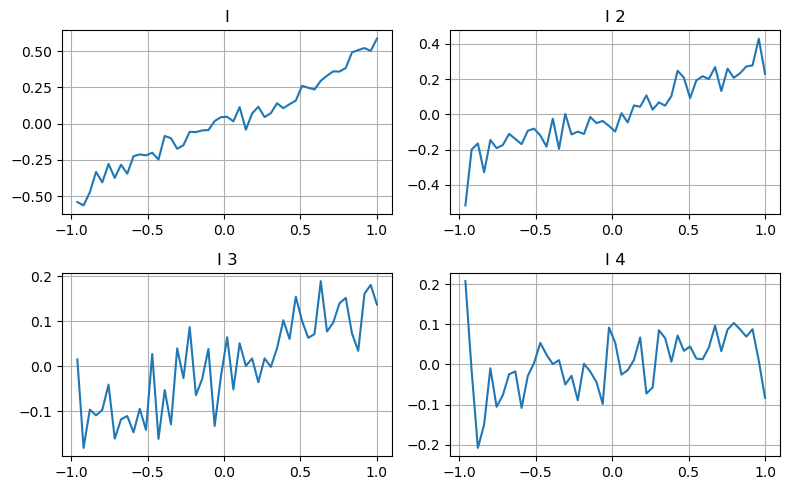
Di sini kami menggunakan idea artikel sebelumnya untuk mengkaji julat nilai yang berbeza bagi parameter yang mempengaruhi tertentu dan perubahan dalam harga transaksi untuk mengukur sumbangan parameter ini kepada harga pertengahan. Seperti yang ditunjukkan dalam graf kedalaman peringkat pertama, apabila saya meningkat, harga urus niaga seterusnya berkemungkinan besar akan berubah secara positif, yang bermaksud bahawa saya membuat sumbangan positif.
Kumpulan kedua telah diproses dengan cara yang sama, dan didapati bahawa walaupun kesannya lebih kecil sedikit daripada kumpulan pertama, ia masih tidak boleh diabaikan. Tahap kedalaman ketiga juga memberikan sedikit sumbangan, tetapi kebosanan adalah lebih teruk, dan kedalaman yang lebih dalam pada dasarnya tidak mempunyai nilai rujukan.
Mengikut tahap sumbangan yang berbeza, pemberat yang berbeza diberikan kepada parameter ketidakseimbangan bagi tiga tahap Pemeriksaan sebenar menunjukkan bahawa ralat ramalan dikurangkan lagi untuk kaedah pengiraan yang berbeza.
python
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
python
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
python
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('调整后的 mid_price_5的误差:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('调整后的 mid_price_6的误差:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('调整后的 mid_price_7的误差:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('调整后的 mid_price_8的误差:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
调整后的 mid_price_4的误差: 0.0047909595497071375
调整后的 mid_price_5的误差: 0.0047884350488318714
调整后的 mid_price_6的误差: 0.0047778319053133735
调整后的 mid_price_7的误差: 0.004773578540592192
调整后的 mid_price_8的误差: 0.004771415189297518
Pertimbangkan data transaksi
Data transaksi secara langsung mencerminkan tahap kedudukan panjang dan pendek Lagipun, ini adalah pilihan yang melibatkan wang sebenar, dan kos membuat pesanan jauh lebih rendah, malah terdapat kes penipuan penempatan pesanan yang disengajakan. Oleh itu, apabila meramalkan harga pertengahan, strategi harus menumpukan pada data transaksi.
Mengambil kira bentuk, tentukan purata pesanan ketidakseimbangan kuantiti ketibaan VI, Vb, Vs mewakili kuantiti purata pesanan beli dan pesanan jual dalam acara unit masing-masing.
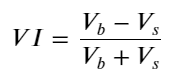
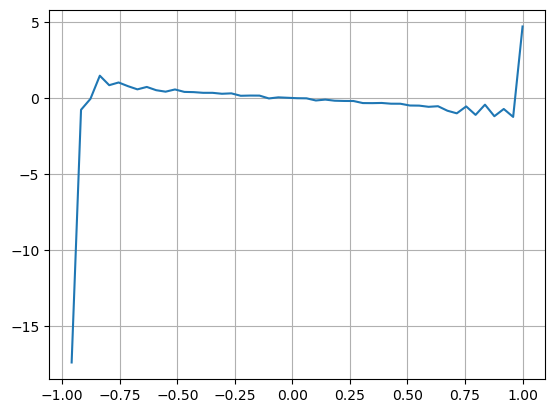
Keputusan menunjukkan bahawa kuantiti ketibaan dalam tempoh yang singkat adalah yang paling ketara dalam meramalkan perubahan harga Apabila VI berada di antara (0.1-0.9), ia berkorelasi negatif dengan harga, tetapi di luar julat ia berkorelasi positif dengan harga. harga. Ini menunjukkan bahawa apabila pasaran tidak melampau, ia dicirikan terutamanya oleh turun naik dan harga akan kembali kepada purata Apabila keadaan pasaran yang melampau berlaku, seperti sebilangan besar pesanan belian mengatasi pesanan jual, arah aliran akan keluar dari arah aliran. . Walaupun kita mengabaikan situasi kebarangkalian rendah ini dan hanya menganggap bahawa arah aliran dan VI memenuhi hubungan linear negatif, ralat ramalan harga pertengahan dikurangkan dengan banyaknya. A dalam formula mewakili pekali.
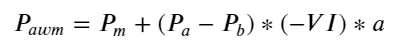
python
alpha=0.1
python
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
python
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
python
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
python
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
python
print('调整后的mid_price 的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的mid_price_9 的误差:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('调整后的mid_price_10的误差:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
调整后的mid_price 的误差: 0.0048373440193987035
调整后的mid_price_9 的误差: 0.004629586542840461
调整后的mid_price_10的误差: 0.004401790287167206
Harga median yang komprehensif
Memandangkan kedua-dua pesanan belum selesai dan data transaksi membantu untuk meramalkan harga pertengahan, kedua-dua parameter ini boleh digabungkan Penetapan berat di sini adalah sewenang-wenangnya dan tidak mengambil kira keadaan sempadan Dalam kes yang melampau, harga pertengahan yang diramalkan mungkin tidak antara beli satu dan jual satu, tetapi selagi ralat dapat dikurangkan, butiran ini tidak penting.
Akhirnya, ralat ramalan turun dari 0.00487 awal kepada 0.0043 Kami tidak akan pergi ke perincian di sini Masih banyak yang perlu diterokai .
python
#注意VI需要延后一个使用
df['price_change'] = np.log(df['price']/df['price'].rolling(40).mean())
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3 + 150*df['price_change'].shift(1)
python
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('调整后的mid_price_11的误差:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
调整后的mid_price_11的误差: 0.00421125960463469
ringkaskan
Kertas kerja ini menggabungkan data kedalaman dan data transaksi untuk menambah baik lagi kaedah pengiraan harga pertengahan Kertas ini menyediakan kaedah untuk mengukur ketepatan dan meningkatkan ketepatan meramalkan perubahan harga. Secara keseluruhannya, pelbagai parameter tidak begitu ketat dan hanya untuk rujukan sahaja. Dengan harga pertengahan yang lebih tepat, langkah seterusnya ialah menggunakan harga pertengahan untuk ujian belakang Bahagian ini juga mempunyai banyak kandungan, jadi kami akan berhenti mengemas kini buat seketika.


