
Uma explicação completa das vantagens e desvantagens das três principais categorias e seis principais algoritmos de aprendizado de máquina
No aprendizado de máquina, o objetivo é tanto a previsão quanto o agrupamento. Neste artigo, o foco é na previsão. A previsão é o processo de estimar o valor de uma variável de saída a partir de um conjunto de variáveis de entrada. Por exemplo, dado um conjunto de características sobre uma casa, podemos prever seu preço de venda.
Com isso em mente, vejamos os algoritmos mais destacados e mais usados em aprendizagem de máquina. Nós dividimos esses algoritmos em 3 categorias: modelos lineares, modelos baseados em árvores e redes neurais, com foco em 6 algoritmos mais usados:
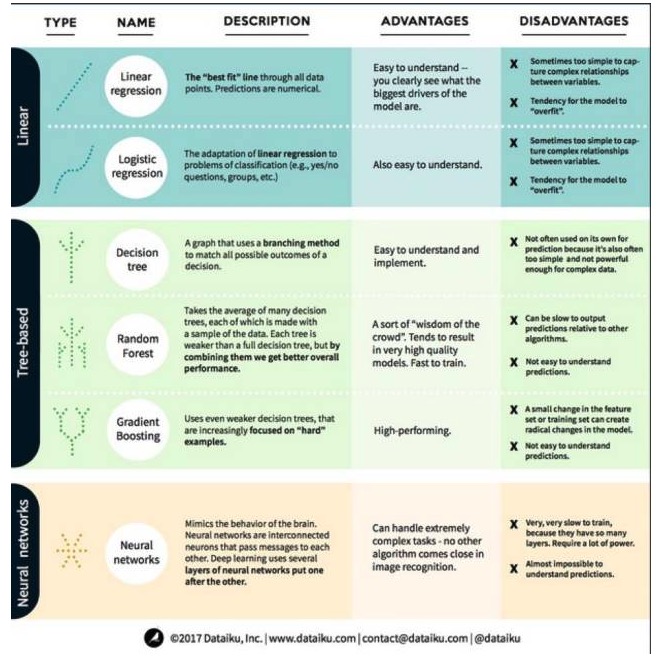
Um algoritmo de modelo linear: um modelo linear usa uma fórmula simples para encontrar a melhor combinação de linhas de um conjunto de pontos de dados. Este método, que remonta a mais de 200 anos, é amplamente utilizado em estatística e aprendizado de máquina. Por sua simplicidade, é útil para a estatística. A variável que você deseja prever é representada como uma equação de uma variável que você já conhece, portanto, a previsão é apenas uma questão de obter a resposta de uma variável e depois calcular a equação.
-
1. Regressão linear
A regressão linear, ou, mais precisamente, a regressão linear em minúsculas, é a forma mais padrão de um modelo linear. Para problemas de regressão, a regressão linear é o modelo linear mais simples. Sua desvantagem é que o modelo é facilmente superadaptável, ou seja, o modelo se adapta completamente aos dados que foram treinados, ao sacrifício da capacidade de divulgação para novos dados.
Outra desvantagem dos modelos lineares é que, por serem muito simples, não são fáceis de prever o comportamento de variáveis mais complexas quando as entradas não são independentes.
-
2. Regressão lógica
A regressão lógica é a adaptação da regressão linear para problemas de classificação. As desvantagens da regressão lógica são as mesmas que as da regressão linear. A função lógica é muito boa para problemas de classificação, pois introduz o efeito de barreira.
Algoritmos de modelagem de árvores
-
1 Árvore de decisão
Uma árvore de decisão é um gráfico que usa um método de ramificação para mostrar todos os resultados possíveis de uma decisão. Digamos que você decidiu pedir uma salada, e sua primeira decisão pode ser o tipo de legumes, depois o tipo de pratos, e depois o tipo de salada. Podemos representar todos os resultados possíveis em uma árvore de decisão.
Para treinar a árvore de decisão, precisamos usar o conjunto de dados de treinamento e descobrir qual atributo é mais útil para o alvo. Por exemplo, em um caso de uso de detecção de fraude, podemos descobrir que o atributo que tem maior impacto na previsão do risco de fraude é o país. Depois de ramificar com o primeiro atributo, obtemos dois subconjuntos, o que seria mais previsível se conhecêssemos apenas o primeiro atributo.
-
2 - Florestas aleatórias
A floresta aleatória é a média de muitas árvores de decisão, em que cada árvore de decisão é treinada com uma amostra aleatória de dados. Cada árvore na floresta aleatória é mais fraca do que uma árvore de decisão completa, mas colocando todas as árvores juntas, podemos obter um melhor desempenho geral devido à vantagem da diversidade.
A floresta aleatória é um algoritmo muito popular na aprendizagem de máquina atualmente. A floresta aleatória é fácil de treinar e tem um desempenho bastante bom. Sua desvantagem é que a previsão de saída da floresta aleatória pode ser lenta em relação a outros algoritmos, portanto, a floresta aleatória pode não ser escolhida quando uma previsão rápida é necessária.
-
3o - Aumento da escala
O GradientBoosting, como a Floresta Aleatória, também é composto por árvores de decisão fracas e fracas. A maior diferença entre o GradientBoosting e a Floresta Aleatória é que, no GradientBoosting, as árvores são treinadas uma após a outra.
O treinamento para elevação de escala também é rápido e o desempenho é excelente. No entanto, pequenas mudanças no conjunto de dados de treinamento podem causar mudanças fundamentais no modelo, portanto os resultados que ele produz podem não ser os mais viáveis.
Algoritmos de rede neural: uma rede neural é um fenômeno biológico composto por neurônios interligados que trocam informações entre si no cérebro. Esta ideia é agora aplicada ao campo da aprendizagem de máquinas, conhecida como ANN (Aneural Network Artificial). O aprendizado profundo é uma rede neural de várias camadas sobrepostas.
Traduzido de Big Data Land
- 1