A arma do AlphaGo: Algoritmo de Monte Carlo, você vai entender depois de ler isso! (com exemplo de código)--Reimprimir
 0
23882
0
23882
A sagacidade do cão alfa: o algoritmo Monte Carlo, só depois de ler!
Entre os dias 9 e 15 de março deste ano, um evento de grande importância para o mundo do Go ocorreu em Seul, na Coreia do Sul, em uma batalha de cinco voltas entre humanos e máquinas. O resultado foi uma derrota para os seres humanos, com o campeão mundial de Go, Li Shih-Shing, a ser derrotado por 1 a 4 pelo programa de inteligência artificial AlphaGo, da Google. Então, o que é o AlphaGo e onde está a chave para vencer?
- ### Algoritmos AlphaGo e Monte Carlo
De acordo com a agência de notícias Xinhua, o programa AlphaGo é um programa de jogo de Go para máquinas desenvolvido pela equipe DeepMind, da Google, que foi chamado de “Crazy Alpha” pelos fãs chineses.
Em nosso último post, falamos sobre a rede neural que o Google está desenvolvendo para a aprendizagem automática de máquinas, e AlphaGo é um produto parecido.
O vice-presidente e secretário-geral da Associação Chinesa de Automação, Wang Liyuan, disse que os programadores não precisam ser proficientes em jogo de Go, apenas precisam entender as regras básicas do jogo. Atrás do AlphaGo, há um grupo de cientistas de computador de destaque, exatamente especialistas no campo do aprendizado de máquina. Os cientistas usam algoritmos de redes neurais para inserir o registro de jogos de especialistas em xadrez no computador e deixam o computador jogar contra si mesmo, treinando-se continuamente no processo.
Então, qual é a chave para que o AlphaGo se torne um autodidata?
O que é o Algoritmo Monte Carlo? O algoritmo de Monte Carlo é um dos mais conhecidos e usados para explicar o que é o Monte Carlo: Se houver 1000 maçãs em uma cesta, para que você possa escolher a maior de cada vez que fechar os olhos, você não pode limitar o número de vezes que você pode escolher. Então, você pode escolher uma aleatoriamente com os olhos fechados, e depois compará-la com a primeira, deixando a maior, e outra aleatoriamente, comparando-a com a última, deixando a maior.
Ou seja, o algoritmo Monte Carlo é que, quanto mais amostras forem encontradas, melhor será a solução, mas não é garantido que seja a melhor, porque se houver 10.000 maçãs, provavelmente será possível encontrar uma solução maior.
O algoritmo de Las Vegas, em contraste com ele, diz: Diz-se popularmente que, se houver uma fechadura, há 1000 chaves para escolher, mas apenas uma delas é correta. Então, cada vez que você pega uma chave ao acaso e tenta abri-la, troca-a. Quanto mais tentativas, maior a chance de abrir a melhor solução, mas antes de abrir, as chaves erradas são inúteis.
Portanto, o algoritmo de Las Vegas é a melhor solução possível, mas não necessariamente encontrada. Suponha que não haja nenhuma chave aberta em 1000 chaves, a verdadeira chave é a 1001a, mas na amostra não há o algoritmo 1001, o algoritmo de Las Vegas não pode encontrar a chave para abrir a fechadura.
Algoritmo Monte Carlo do AlphaGo A dificuldade do Go é especialmente grande para a inteligência artificial, pois há muitas maneiras de jogar o Go que são difíceis de serem identificadas por um computador. Em primeiro lugar, o jogo de go é muito possível. Cada passo do jogo de go é muito possível, quando o jogador começa, há 19 × 19 = 361 opções de queda. Em uma partida de 150 rodadas, o jogo de go pode ter até 10.170 situações. Em segundo lugar, a lei é muito delicada e, de certa forma, a escolha de queda depende da intuição formada pela acumulação de experiência. Além disso, na partida de go, é difícil para o computador distinguir os pontos fortes e fracos da partida em questão.
O AlphaGo não é apenas um algoritmo Monte Carlo, mas uma versão melhorada do mesmo.
O AlphaGo trabalha com o algoritmo de busca de árvores Monte Carlo e duas redes neurais de profundidade para fazer o jogo de xadrez. Antes do confronto com Li Shizhi, o Google primeiro treinou a rede neural do filhote de Alpha para aprender a prever como os jogadores profissionais humanos falham usando quase 30 milhões de movimentos em pares humanos.
A tarefa deles é colaborar e selecionar as jogadas mais promissoras, descartando as que são mais evidentemente ruins, limitando assim o cálculo ao que o computador pode fazer. Essencialmente, isso é o mesmo que um jogador de xadrez humano faz.
O software de jogos de xadrez tradicional, o software de busca violenta, geralmente usado por pesquisadores do Instituto de Automação da Academia Chinesa de Ciências, incluindo o Deep Blue Computer, que cria uma árvore de busca para todos os resultados possíveis (cada resultado é um fruto da árvore), fazendo uma busca de percurso conforme a necessidade. Este método também tem uma certa viabilidade em xadrez, xadrez, etc., mas não é possível para o Go, porque o Go atravessa 19 linhas e a possibilidade de cair é tão grande que o computador não pode construir a árvore (há muitos frutos) para realizar a busca de percurso.
A rede de neurônios de profundidade tem uma unidade fundamental que se assemelha a um neurônio do nosso cérebro humano, com muitas camadas conectadas, como se fosse uma rede de neurônios do cérebro humano. As duas redes de neurônios da AlphaGo são a rede de estratégia e a rede de avaliação.
A rede de estratégias de jogo é usada principalmente para gerar estratégias de queda. No processo de jogar xadrez, ele não considera o que deveria ficar, mas sim o que o jogador superior do ser humano ficaria. Ou seja, ele prevê, com base no estado atual do tabuleiro de entrada, onde o próximo jogo do ser humano será jogado, e propõe várias soluções viáveis que melhor correspondem ao pensamento humano.
No entanto, a rede de estratégias não sabe se a jogada que está fazendo é boa ou ruim, apenas sabe se a jogada é a mesma que a jogada humana, e é aí que a rede de avaliação funciona.
A rede de avaliação de estratégias avalia a situação do disco inteiro para cada hipótese viável e, em seguida, fornece uma linha de probabilidade de vitória. Esses valores são transmitidos para o algoritmo de busca de árvores de Monte Carlo, que, por meio de um processo repetitivo, apresenta o caminho com a maior probabilidade de vitória. O algoritmo de busca de árvores de Monte Carlo decide que a rede de estratégias só continuará onde a probabilidade de vitória é maior, para que possa abandonar algumas linhas e não ter que calcular um caminho para o preto.
O AlphaGo usa essas duas ferramentas para analisar a situação e avaliar as vantagens e desvantagens de cada estratégia, assim como um jogador de xadrez humano avaliaria a situação atual e inferiria a situação futura. Usando o algoritmo de busca de árvores de Monte Carlo para analisar, por exemplo, os próximos 20 passos, pode-se determinar onde a probabilidade de vencer será maior.
Mas não há dúvida de que o algoritmo Monte Carlo é um dos pilares do AlphaGo.
Duas pequenas experiências. Por fim, vejamos duas pequenas experiências com o algoritmo Monte Carlo:
- ### 1. Calcule a circunferência pi.
Princípio: primeiro desenhe um quadrado, desenhe um círculo de corte interno, e então desenhe um ponto aleatório dentro do quadrado, definindo o ponto dentro do círculo como P, então P = área do círculo / área do quadrado. P=(Pi*R*R)/(2R*2R) = Pi/4, ou seja, Pi = 4P
Passos: 1. Coloque o centro do círculo no ponto de origem e faça um círculo com R como raio, então 1⁄4 da área do círculo no primeiro quadrante é Pi*R*R/4 2. Faça um quadrado exterior de 1⁄4 de círculo, com as coordenadas ((0,0) ((0,R) ((R,0) ((R,R), então a área do quadrado é R*R 3. Pegar o ponto ((X,Y)), de modo que 0<=X<=R e 0<=Y<=R, ou seja, o ponto está dentro do quadrado 4. através da fórmula X*X+Y*Y*O ponto de julgamento de R está dentro de 1⁄4 da circunferência. 5. Se N for o número de todos os pontos (ou seja, o número de experimentos) e M for o número de pontos dentro de um quarto do círculo (ou seja, o número de pontos que satisfazem o passo 4),
P = M/N então Pi = 4*N/M
 Imagem 1
Imagem 1
M_C(10000) com resultado de 3.1424
- ### 2. A simulação de Monte Carlo busca os extremos da função, evitando cair em extremos locais
# No espaço[-2,2] e, em seguida, gerar um número ao acaso, e encontrar o seu correspondente y, e encontrar o maior número que é considerado como função em[-2,2] é o valor máximo
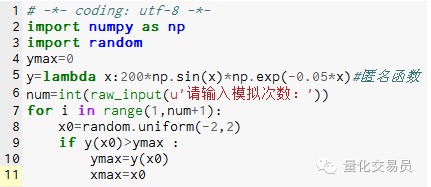 Imagem 2
Imagem 2
A simulação de 1000 vezes encontrou um valor máximo de 185.12292832389875 (muito preciso)
Vejam isto, vocês já perceberam. O código pode ser escrito manualmente, é muito divertido! Transcrição feita pelo WeChat Public