Comparação de 8 algoritmos de aprendizado de máquina
 0
6946
0
6946
Comparação de 8 algoritmos de aprendizado de máquina
Este artigo relembra principalmente os seguintes cenários de adaptação de algoritmos comuns e suas vantagens e desvantagens!
Há muitos algoritmos de aprendizado de máquina, como classificação, regressão, agregação, recomendação, reconhecimento de imagens e muito mais, e não é fácil encontrar um algoritmo adequado, por isso, na prática, geralmente usamos o aprendizado inspirado para experimentar.
Normalmente, no começo, nós escolhemos o algoritmo que todos reconhecemos, como SVM, GBDT, Adaboost, mas agora o aprendizado profundo está em alta, e as redes neurais também são uma boa opção.
Se você se preocupa com a precisão, a melhor maneira é testar cada algoritmo um a um por meio de uma verificação cruzada, comparando, ajustando os parâmetros para garantir que cada algoritmo atinja a solução ideal e, finalmente, escolhendo o melhor.
Mas se você está apenas procurando um algoritmo que seja bom o suficiente para resolver o seu problema, ou aqui estão algumas dicas para se referir, analise abaixo os pontos positivos e negativos de cada algoritmo, com base nos pontos positivos e negativos do algoritmo, para que seja mais fácil para nós escolhê-lo.
- ## Divergências e diferenças
Na estatística, um modelo é bem ou mal, e é medida em termos de variância e diferença, então vamos fazer uma generalização sobre variância e diferença:
Desvio: descreve a diferença entre o valor esperado de E e o valor real de Y para o valor de previsão (valor estimado). Quanto maior o desvio, mais desviado dos dados reais.
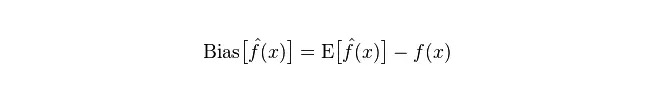
Diferença: descreve a variação do intervalo de variação do valor de previsão P, o grau de dispersão, é a diferença do valor de previsão, ou seja, a distância de seu valor esperado E. Quanto maior a diferença, mais dispersa a distribuição dos dados.
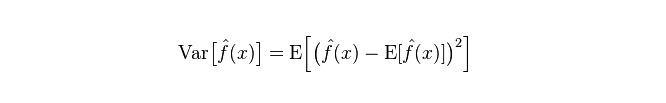
O erro real do modelo é a soma dos dois, como mostra o gráfico a seguir:
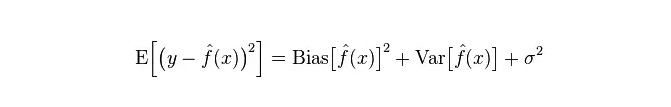
Se for um conjunto de treinamento pequeno, o classificador de alto desvio/baixa diferença (por exemplo, o simplório Bayesian NB) terá uma vantagem maior do que o classificador de baixo desvio/alto desvio grande (por exemplo, o KNN), pois o último será superadaptado.
No entanto, à medida que o conjunto de treinamento cresce, o modelo é mais capaz de prever os dados originais, e o desvio diminui, e os classificadores de desvio baixo / desvio alto gradualmente mostram sua vantagem (porque eles têm um menor erro de aproximação), e os classificadores de desvio alto não são suficientes para fornecer modelos precisos.
Claro, você também pode pensar que isso é uma diferença entre o modelo de geração (NB) e o modelo de determinação (KNN).
- ## Por que o simplório Bayes é um alto e um baixo?
O que é que isso quer dizer?
Em primeiro lugar, suponha que você conhece a relação entre o conjunto de treinamento e o conjunto de testes. Em outras palavras, vamos aprender um modelo no conjunto de treinamento e, em seguida, usar o conjunto de testes.
Mas muitas vezes, só podemos assumir que o conjunto de testes e o conjunto de treinamento estão na mesma distribuição de dados, mas não temos os dados de teste reais. Então, como medir a taxa de erro de teste com apenas a taxa de erro de treinamento?
Como as amostras de treinamento são poucas (ou pelo menos não o suficiente), o modelo obtido através do conjunto de treinamento nem sempre é verdadeiramente correto. Mesmo com uma taxa de correção de 100% no conjunto de treinamento, não significa que ele desenha uma distribuição de dados real. O nosso objetivo é desenhar uma distribuição de dados real, e não apenas desenhar os pontos de dados limitados do conjunto de treinamento.
Além disso, na prática, as amostras de treinamento tendem a ter um certo grau de erro de ruído, então se você for muito exigente com a perfeição dos conjuntos de treinamento e usar um modelo muito complexo, o modelo pode considerar todos os erros dentro dos conjuntos de treinamento como características de distribuição de dados reais, resultando em estimativas de distribuição de dados erradas.
Nesse caso, o erro é muito grande no conjunto de testes reais (esse fenômeno é chamado de adequação). Mas também não se pode usar modelos muito simples, caso contrário, quando a distribuição de dados é mais complexa, o modelo não é suficiente para desenhar a distribuição de dados (representando uma alta taxa de erro mesmo no conjunto de treinamento, esse fenômeno é pouco adequado).
O excesso de adequação indica que o modelo adotado é mais complexo do que a verdadeira distribuição de dados, enquanto a falta de adequação indica que o modelo adotado é mais simples do que a verdadeira distribuição de dados.
Na estrutura de aprendizagem estatística, quando se descreve a complexidade do modelo, há uma opinião de que o erro = Bias + Variance. O erro aqui pode ser entendido como a taxa de erro de previsão do modelo, e é composto de duas partes, uma parte é a estimativa imprecisa causada pela simplicidade do modelo (Bias), e a outra parte é o espaço de variação maior e a incerteza causada pela complexidade do modelo (Variance).
Assim, é fácil de analisar o Bayesianismo Simples. O seu simples pressuposto de que os dados não estão relacionados é um modelo muito simplificado. Assim, para um modelo tão simples, a maior parte das vezes a parte de Bias é maior do que a parte de Variance, ou seja, um alto desvio e um baixo diferencial.
Na prática, para minimizar o erro, precisamos equilibrar a proporção de Bias e Variance na escolha do modelo, ou seja, equilibrar o over-fitting e o under-fitting.
A relação entre o desvio e a diferença quadrada e a complexidade do modelo é mais clara no gráfico a seguir:
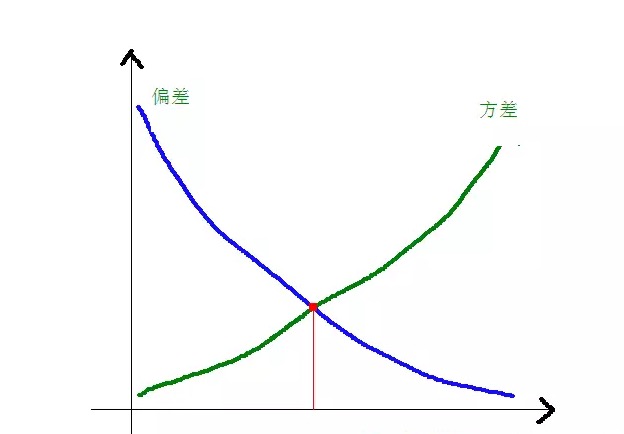
Quando a complexidade do modelo aumenta, o desvio se torna menor e a diferença se torna maior.
-
Vantagens e desvantagens de algoritmos comuns
- ### 1. Simples Bayes
O Bayesianismo simplório pertence ao modelo gerador (sobre o modelo gerador e o modelo discriminador, principalmente sobre se a distribuição conjunta é necessária ou não), é muito simples, você só faz um monte de cálculos.
Se for dada a independência condicional (uma condição mais rigorosa), o classificador Bayesian simplório converge mais rapidamente do que um modelo de discernimento, como a regressão lógica, então você só precisa de menos dados de treinamento. Mesmo que a independência condicional da NB não seja assumida, o classificador NB ainda funciona muito bem na prática.
A principal desvantagem é que não consegue aprender a interagir entre os personagens, o que é um excesso de personagens em mRMR. Para citar um exemplo mais clássico, por exemplo, embora você goste de filmes de Brad Pitt e Tom Cruise, não consegue aprender que você não gosta de filmes em que eles estão juntos.
Vantagens:
O modelo simplório de Bayes tem origem na teoria matemática clássica, tem uma base matemática sólida e uma eficiência de classificação estável. A performance é boa em dados de pequena escala, com capacidade para executar tarefas de múltiplas classes individualmente, e é adequada para treinamento incremental; O algoritmo é menos sensível aos dados perdidos e é mais simples, sendo usado frequentemente para classificação de texto. Desvantagens:
O que é necessário é calcular a probabilidade de antecedência. A taxa de erro nas decisões de classificação; A expressão de dados de entrada é sensível.
- ### 2. Regressão lógica
Há muitas maneiras de regular um modelo que pertence a um modelo discriminativo (L0, L1, L2, etc.), e você não precisa se preocupar se sua característica é relevante, como acontece com um simples Bayesian.
Comparando a árvore de decisão com a máquina SVM, você também obtém uma boa interpretação de probabilidade, e você pode até mesmo facilmente usar novos dados para atualizar o modelo (usando o algoritmo de descida de gradiente online).
Se você precisa de uma estrutura de probabilidade (por exemplo, simplesmente para ajustar os limites de classificação, indicar incertezas ou obter intervalos de confiança), ou se você deseja integrar mais dados de treinamento rapidamente no modelo mais tarde, use-o.
Função sigmoide:
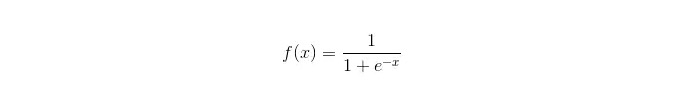
Vantagens: A simplicidade e a ampla aplicação em questões industriais; A classificação é feita com muito pouco volume, velocidade e pouca capacidade de armazenamento. A probabilidade de pontuação de uma amostra de observação facilitada; Para a regressão lógica, a multicomlinaridade não é um problema, que pode ser resolvido em combinação com a regularização L2; Desvantagens: Quando o espaço de características é grande, a regressão lógica não funciona muito bem; Falta de adequação, geralmente com pouca precisão Não consegue lidar bem com uma grande variedade de características ou variáveis; Só pode lidar com duas questões de classificação (o softmax derivado dessa base pode ser usado para multiclassificação) e deve ser linearmente divisível; Para caracteres não-lineares, a conversão é necessária.
- ### Regressão linear 3.
A regressão linear é usada para regressão, ao contrário da regressão logística, que é usada para classificação. A regressão linear é usada para otimizar a função de erro em forma de minúscula binomial com o método de gradiente decrescente. A regressão linear também pode ser usada para obter diretamente a solução de um parâmetro da equação normal, resultando em:
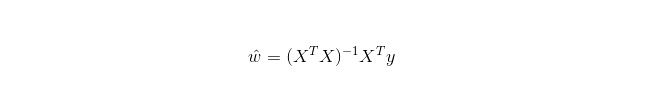
Em LWLR, a expressão de cálculo do parâmetro é:
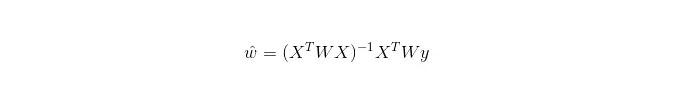
A diferença entre o LWLR e o LR é que o LWLR é um modelo não paramétrico, pois cada cálculo de regressão deve percorrer a amostra de treinamento pelo menos uma vez.
Os benefícios: Simplicidade de implementação e de cálculo.
Desvantagens: Não pode ser aplicado a dados não lineares.
- ### 4. Algoritmo de vizinhança mais próxima KNN
O KNN é o algoritmo de proximidade, cujo principal processo é:
Calcular a distância de cada ponto de amostragem na amostra de treino e na amostra de teste (metrômetros de distância comuns são distância em euros, distância em mares, etc.);
Sequenciar todos os valores de distância acima;
Escolha a distância mínima entre k amostras;
A classificação final é obtida através da votação de um total de k amostras de etiquetas;
Como escolher um valor de K ideal depende dos dados. Em geral, um valor de K maior na classificação pode reduzir o impacto do ruído, mas pode tornar os limites entre as categorias mais obscuros.
Um melhor valor de K pode ser obtido por meio de várias técnicas de iluminação, como, por exemplo, a validação cruzada. Além disso, a presença de vectores de características de ruído e não correlação reduz a precisão do algoritmo de vizinhança de K.
Os algoritmos de proximidade têm resultados de consistência mais fortes. Como os dados tendem para o infinito, o algoritmo garante que a taxa de erro não exceda o dobro da taxa de erro do algoritmo de Bayes. Para alguns bons valores de K, o algoritmo de proximidade garante que a taxa de erro não exceda a taxa de erro da teoria de Bayes.
Vantagens do algoritmo KNN
A teoria é madura, o pensamento é simples, e pode ser usado tanto para classificação como para regressão; Pode ser usado para classificação não-linear; A complexidade do tempo de treino é O (n); Não há hipóteses sobre os dados, a precisão é alta e não é sensível a outliers. deficiência
A quantidade de cálculo é grande. O problema do desequilíbrio de amostras (ou seja, há muitas amostras de algumas categorias e poucas de outras); O que é que isso quer dizer?
- ### 5. Árvore de decisão
É fácil de interpretar. Ele pode lidar com relações entre as características sem estresse e é não-parametrizado, então você não precisa se preocupar se os valores de excepção ou os dados são linearmente separáveis (por exemplo, a árvore de decisão pode facilmente lidar com o caso de uma categoria A no final de uma determinada dimensão de característica x, uma categoria B no meio e, em seguida, uma categoria A no extremo anterior da dimensão de característica x).
Uma das suas desvantagens é que não suporta o aprendizado on-line, o que significa que a árvore de decisão precisa ser totalmente reconstruída quando novas amostras chegam.
Outra desvantagem é a facilidade de surgimento de overmatching, mas é o ponto de entrada para métodos de integração como o RF de floresta aleatória (ou o treeboosted tree).
Além disso, a floresta aleatória é frequentemente a vencedora de muitos problemas de classificação (muito menos do que as máquinas de suporte de vetores), é rápida de treinar e pode ser ajustada, e você não precisa se preocupar em ajustar um monte de parâmetros como as máquinas de suporte de vetores, por isso sempre foi muito popular.
Um ponto importante na árvore de decisão é a escolha de um atributo para ramificação, então preste atenção à fórmula de cálculo do acréscimo de informação e compreenda-a em profundidade.
A fórmula de cálculo da barra de informação é a seguinte:
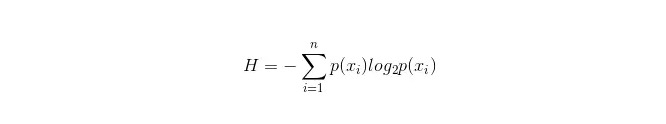
Em que n representa n categorias de classificação ((assumindo, por exemplo, que se trata de uma questão de classe 2, então n = 2) . Calcule a probabilidade de que essas duas categorias de amostras apareçam na amostra total, respectivamente, p1 e p2, para que possa ser calculada a quantidade de informações antes da ramificação das propriedades não selecionadas .
Agora selecione um atributo xixi para ramificação, e a regra de ramificação é: se xi = vxi = v, divida a amostra em um ramo da árvore; se não for igual, entre no outro ramo.
Obviamente, a amostra de ramificações é muito provável que inclua duas categorias, calcula-se H1 e H2 de cada ramificação, calcula-se o total de informações após a ramificação H = p1 H1 + p2 H2, então o ganho de informação ΔH = H - H. Com o ganho de informação como princípio, teste todas as propriedades de lado e escolha uma das propriedades com maior ganho como propriedade de ramificação.
As vantagens da árvore de decisão
O sistema de cálculo é simples, compreensível e interpretável. A comparação de amostras com propriedades ausentes é mais adequada; A capacidade de lidar com características irrelevantes; Capacidade de produzir resultados viáveis e eficazes em fontes de dados grandes em um período de tempo relativamente curto. deficiência
A sobre-adaptação é mais provável (a floresta aleatória pode reduzir significativamente a sobre-adaptação); A falta de correlação entre os dados; Para os dados em que o número de amostras de cada categoria é inconsistente, os resultados de aumento da informação na árvore de decisão são orientados para aqueles que possuem características com mais valores (a desvantagem existe sempre que o aumento da informação é usado, como o RF).
- ### 5.1 Adaboosting
Adaboost é um modelo de adição, cada modelo é construído com base na taxa de erro do modelo anterior, com foco excessivo em amostras com erros de classificação, e menos foco em amostras classificadas corretamente, após a repetição, pode ser obtido um modelo relativamente melhor. É um algoritmo de boosting típico.
vantagem
Adaboost é um classificador de alta precisão. Os subclassificadores podem ser construídos usando vários métodos. O Adaboost fornece uma estrutura. Os resultados dos cálculos são compreensíveis quando os classificadores simples são usados, e a construção dos classificadores fracos é extremamente simples. Simples, sem filtragem de características. Não é propenso a overfitting. Sobre algoritmos de combinação como florestas aleatórias e GBDT, consulte este artigo: Machine Learning - Summary of Combinator Algorithms
Desvantagens: sensibilidade ao outlier
- ### 6. Máquinas vetoriais compatíveis com SVM
A alta precisão fornece uma boa garantia teórica para evitar a sobreadaptação, e mesmo que os dados sejam linearmente indivisíveis no espaço de características originais, basta dar uma função de núcleo apropriada para que ele funcione bem.
É especialmente popular em problemas de classificação de texto de alta dimensão. Infelizmente, consome muita memória, é difícil de interpretar, o funcionamento e a modelagem também são um pouco irritantes, e a floresta aleatória evita esses defeitos, sendo mais prática.
vantagem A solução para o problema de alta dimensão, ou seja, o espaço de características grandes; Ser capaz de lidar com interações de características não-lineares; Não é preciso depender de todos os dados. A capacidade de generalização pode ser aumentada.
deficiência A eficiência não é muito alta quando se observa muitas amostras. Não há soluções universais para problemas não-lineares e, por vezes, é difícil encontrar uma função nuclear adequada. Sensibilidade a dados em falta; A escolha do núcleo também é técnica (libsvm possui quatro funções de núcleo: núcleo linear, núcleo de múltiplos termos, RBF e núcleo sigmoide):
Em primeiro lugar, se o número de amostras é menor que o número de características, não há necessidade de escolher o núcleo não-linear, basta usar o núcleo linear.
Em segundo lugar, se o número de amostras for maior do que o número de características, então o núcleo não-linear pode ser usado para mapear as amostras em dimensões mais altas, geralmente com melhores resultados.
Em terceiro lugar, se o número de amostras e o número de características forem iguais, o núcleo não-linear pode ser usado, seguindo o mesmo princípio que o segundo tipo.
Para o primeiro caso, também é possível reduzir a dimensão dos dados e, em seguida, usar o núcleo não linear, que também é um método.
- ### 7. As vantagens e desvantagens de uma rede neural artificial
As vantagens das redes neurais: A classificação é muito precisa. A capacidade de processamento distribuído em paralelo, de armazenamento distribuído e de aprendizagem é forte. A robustez e a tolerância ao ruído dos neurônios permitem uma aproximação perfeita de relações não-lineares complexas. Tem função de memória associada.
As redes neurais artificiais têm os seus inconvenientes: As redes neurais requerem uma grande quantidade de parâmetros, como a estrutura topológica da rede, os valores iniciais de ponderação e de desvalorização; A falta de observação entre os processos de aprendizagem e a dificuldade de interpretação dos resultados de saída, que afetam a credibilidade e aceitabilidade dos resultados; O tempo de estudo é longo demais e pode até não atingir o objetivo do estudo.
- ### 8 K-Means agrupamento
O K-Means cluster é um algoritmo de aprendizagem de máquina que tem um forte pensamento em termos de inferência em relação ao K-Means.
vantagem Algoritmos simples e fáceis de implementar; Para processar grandes conjuntos de dados, o algoritmo é relativamente escalável e altamente eficiente, pois sua complexidade é de aproximadamente O{\displaystyle O} nkt, onde n é o número de todos os objetos, k é o número de colunas e t é o número de repetições. Normalmente k<
deficiência Requisitos mais elevados para tipos de dados, adequados para dados numéricos; Pode haver convergência em mínimos locais, mas é mais lenta em dados de grande escala. O valor de K é mais difícil de extrair; Sensível ao valor de concentração inicial, que pode levar a resultados de agregação diferentes para diferentes valores iniciais; Não é adequado para a descoberta de bolhas de forma não convexa, ou bolhas de tamanho muito variável. A pequena quantidade de dados desse tipo pode ter um grande impacto sobre a média.
Algorithm seleção de referência
Um artigo anterior, traduzido de outros países, oferece uma técnica simples de seleção de algoritmos:
A regressão lógica deve ser escolhida em primeiro lugar, e se não for muito eficaz, os resultados podem ser usados como referência e comparados com outros algoritmos;
Em seguida, experimente a árvore de decisão para ver se ela pode melhorar significativamente o desempenho do seu modelo. Mesmo que você não o considere o modelo final, você pode usar a floresta aleatória para remover variáveis de ruído e fazer escolhas de características.
Se o número de características e de amostras de observação é particularmente grande, o uso da SVM é uma opção quando os recursos e o tempo são suficientes (o que é importante).
Normalmente: GBDT>=SVM>=RF>=Adaboost>=Other… Bem, agora o aprendizado profundo é muito popular, é usado em muitos campos, é baseado em redes neurais, e eu também estou aprendendo, mas o conhecimento teórico não é muito sólido, não é profundo o suficiente para entender, não vou fazer uma introdução aqui.
Algoritmos são importantes, mas bons dados são melhores do que bons algoritmos, e o design de boas características é benéfico. Se você tiver um grande conjunto de dados, então qualquer algoritmo que você use pode não ter grande impacto na performance de classificação (então você pode fazer uma escolha com base na velocidade e facilidade de uso).
-
Referências