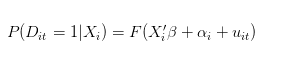Quando prevemos probabilidades, o que estamos prevendo?
Eu tive uma entrevista há muito tempo atrás, e o tema da entrevista me trouxe uma nova lembrança.
Entrevistador: Você conhece a regressão logística?
Eu: Claro que sei, é muito comum.
P: Então, como você acha que a probabilidade de uma previsão de regressão logística deve ser interpretada como a probabilidade de um indivíduo ter sucesso?
Eu: Claro que não. Se houver apenas uma observação, a probabilidade de um indivíduo não pode ser estimada. Deve ser interpretada como, dado N indivíduos com a mesma característica, a taxa de sucesso é igual à probabilidade estimada.
Bem, o entrevistador não estava disponível, mas claro que no final eu fui eliminado (talvez devido à minha formação em economia e não em estatística e informática).
Então, quando nós estimamos o retorno logístico, nós estimamos:
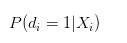
Não deveria ser interpretado como probabilidade de sucesso individual?
-
Eu acho que essa afirmação é um pouco problemática.
Quando falamos da probabilidade de um indivíduo sozinho ter sucesso, deve ser a média de sucesso de 100 repetições do mesmo indivíduo sob as mesmas condições. Se t for o número de tentativas de um indivíduo, então nosso modelo ideal (o processo de geração de dados) deve ser o seguinte:
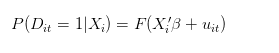
No entanto, alternativamente, o processo de geração de dados reais pode ser o seguinte: