
Um tour pelos algoritmos de aprendizado de máquina
Depois de entender os problemas de aprendizagem de máquina que precisamos resolver, podemos pensar em quais dados precisamos coletar e quais algoritmos podemos usar. Neste artigo, vamos passar pelos algoritmos de aprendizagem de máquina mais populares para entender quais métodos podem ser usados.
Há muitos algoritmos no campo do aprendizado de máquina, e cada um deles tem muitas extensões, então é muito difícil determinar o algoritmo certo para um problema específico. Neste artigo, eu gostaria de te dar duas maneiras de resumir os algoritmos que você encontrará na realidade.
-
Método de aprendizagem
Algoritmos são divididos em diferentes tipos de algoritmos, dependendo de como eles processam experiências, ambientes ou qualquer outro tipo de dados que chamamos de "input". Os livros de aprendizagem de máquina e inteligência artificial geralmente consideram os métodos de aprendizagem que os algoritmos podem adaptar.
Aqui são discutidos apenas alguns dos principais estilos de aprendizagem ou modelos de aprendizagem, e alguns exemplos básicos. Esta maneira de classificar ou organizar é boa, pois obriga você a pensar sobre o papel dos dados de entrada e o processo de preparação do modelo, e depois escolher um algoritmo que melhor se adapte ao seu problema para obter os melhores resultados.
Aprendizagem supervisionada: os dados de entrada são chamados de dados de treinamento, e os resultados são conhecidos ou marcados. Por exemplo, dizer se um e-mail é um spam ou dizer o preço de uma ação por um período de tempo. O modelo faz uma previsão e se estiver errado, será corrigido.
Aprendizagem não supervisionada: os dados de entrada não são marcados e não há resultados definidos. Os modelos induzem a estrutura e os valores dos dados. Exemplos de problemas incluem aprendizagem de regras de associação e problemas de agregação. Exemplos de algoritmos incluem o algoritmo Apriori e o algoritmo K-means.
Aprendizagem semi-supervisionada: os dados de entrada são uma mistura de dados marcados e não marcados, com alguns problemas de previsão, mas o modelo também deve aprender a estrutura e a composição dos dados. Exemplos de problemas incluem classificação e problemas de regressão, e os exemplos de algoritmos são basicamente extensões de algoritmos de aprendizado não supervisionados.
Aprendizagem aumentada: os dados de entrada podem estimular o modelo e fazer com que o modelo reaja. O feedback não é obtido apenas do processo de aprendizagem supervisionado, mas também de recompensas ou punições no ambiente. Exemplos de problemas são o controle de robôs, e exemplos de algoritmos incluem o Q-learning e o aprendizado de diferença temporal.Quando se integra a simulação de dados em decisões de negócios, a maioria usa métodos de aprendizagem supervisionada e não supervisionada. O próximo tópico em voga é o aprendizado semi-supervisionado, como o problema de classificação de imagens, no qual há um grande banco de dados de problemas, mas apenas uma pequena parte das imagens é marcada. O aprendizado aumentado é usado principalmente no desenvolvimento de controles de robôs e outros sistemas de controle.
-
Algoritmos semelhantes
Algoritmos são basicamente classificados em função ou forma. Por exemplo, algoritmos baseados em árvores, algoritmos de redes neurais. Esta é uma forma útil de classificação, mas não é perfeita.
Nesta seção, eu listarei os algoritmos de classificação que eu considero os mais intuitivos. Eu não estou falando de todos os algoritmos ou métodos de classificação, mas eu acho que é muito útil para que os leitores tenham uma visão geral. Se você sabe que eu não listei, por favor, deixe um comentário.
-
Regression
A regressão está preocupada com as relações entre as variáveis. Ela aplica métodos estatísticos. Alguns exemplos de algoritmos incluem:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
A aprendizagem baseada em instâncias simula uma questão de decisão, e os exemplos ou exemplos usados são muito importantes para o modelo. Esta abordagem cria um banco de dados de dados existentes e adiciona novos dados, em seguida, usa um método de medição de similaridade para encontrar o melhor jogo no banco de dados e fazer uma previsão. Por esta razão, a abordagem também é conhecida como o método do vencedor e o método baseado na memória.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
É uma extensão de outros métodos (geralmente o método de regressão), que favorece modelos mais simples e mais capazes de induzir. Eu a citei aqui por ser popular e poderosa.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Os métodos de árvore de decisão criam um modelo baseado em decisões baseadas em valores reais nos dados. As árvores de decisão são usadas para resolver problemas de integração e regressão.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
O método bayesiano é um método de aplicação do teorema de Bayes para a resolução de problemas de classificação e regressão.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
O mais conhecido dos Kernel Method é o Support Vector Machines. Este método mapeia os dados de entrada para uma dimensão mais alta, sendo que alguns problemas de classificação e regressão são mais fáceis de modelar.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
Clustering, em si, descreve problemas e métodos. Os métodos de agregação são geralmente classificados por métodos de modelagem. Todos os métodos de agregação são organizados com uma estrutura de dados unificada, de modo que cada grupo tenha o máximo de coisas em comum.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
O aprendizado de regras de associação é um método usado para extrair regras entre dados, através das quais as ligações entre enormes quantidades de dados em espaços multidimensionais podem ser encontradas, e essas ligações importantes podem ser usadas pela organização.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
As redes neurais artificiais são inspiradas na estrutura e função das redes neurais biológicas. Pertencem à classe de correspondência de padrões, frequentemente usadas para problemas de regressão e classificação, mas existem centenas de algoritmos e variantes. Alguns deles são algoritmos clássicos populares (eu coloco o aprendizado profundo separadamente):
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
O método de aprendizagem profunda é uma atualização moderna das redes neurais artificiais. Em comparação com as redes neurais tradicionais, tem uma composição de rede mais complexa. Muitos métodos são preocupados com aprendizagem semi-supervisionada, que inclui grandes quantidades de dados, mas pouca quantidade de dados marcados.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionality Reduction (Reduzir Dimensionalidade), como o método de agregação, busca e utiliza a estrutura de unificação nos dados, mas usa menos informações para resumir e descrever os dados. Isso é útil para visualizar ou simplificar os dados.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Ensemble methods (métodos de conjunto) consistem em muitos modelos pequenos, que são treinados independentemente, tiram conclusões independentes e, finalmente, formam uma previsão geral. Muita pesquisa se concentra em quais modelos são usados e como esses modelos são combinados.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
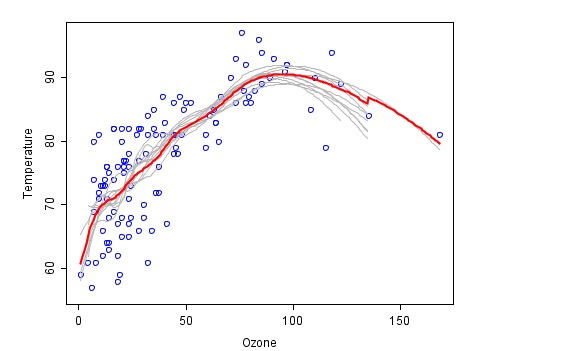
Este é um exemplo de combinação feita com o método de combinação ((traduzido do wiki)), em que cada lei de incêndio é representada em cinza e a previsão final da última combinação é em vermelho.
-
Outros recursos
Esta viagem de algoritmos de aprendizagem de máquina pretende dar-lhe uma visão geral do que é um algoritmo e de algumas ferramentas que o relacionam.
Aqui estão alguns outros recursos, não pense que são muitos, quanto mais você sabe sobre algoritmos, mais benefícios você terá, mas ter um conhecimento profundo de alguns algoritmos também pode ser útil.
- List of Machine Learning Algorithms: Este é um recurso da wiki, embora completo, mas não me parece que esteja bem classificado.
- Machine Learning Algorithms Category: Este também é um recurso no wiki, um pouco melhor do que o anterior, em ordem alfabética.
- CRAN Task View: Machine Learning & Statistical Learning: um pacote de extensão da linguagem R para algoritmos de aprendizagem de máquina, para comparar o que é melhor para você entender o que os outros estão usando.
- Top 10 Algorithms in Data Mining: Este é um artigo publicado, agora um livro, que inclui os mais populares algoritmos de mineração de dados. Outra lista de algoritmos básicos, que são poucos, pode ajudá-lo a aprofundar.
Reprodução de um artigo de Berle/Dafay Python
- 1