Três imagens para entender o aprendizado de máquina: conceitos básicos, cinco escolas principais e nove algoritmos comuns
 0
2546
0
2546
Três imagens para entender o aprendizado de máquina: conceitos básicos, cinco escolas principais e nove algoritmos comuns
- #### Um resumo do aprendizado de máquina

O que é aprendizado de máquina?
As máquinas aprendem analisando grandes quantidades de dados. Por exemplo, não precisam ser programadas para reconhecer gatos ou faces humanas, elas podem ser treinadas usando imagens para que possam resumir e reconhecer objetivos específicos.
A relação entre aprendizagem de máquina e inteligência artificial
O aprendizado de máquina é uma disciplina de pesquisa e algoritmos que se dedica a encontrar padrões em dados e usá-los para fazer previsões. O aprendizado de máquina é parte do campo da inteligência artificial e interage com a descoberta do conhecimento e a mineração de dados.
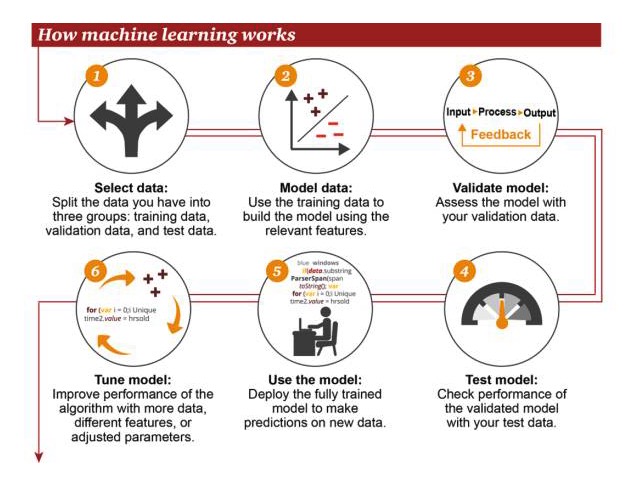
Como funciona a aprendizagem de máquina
1 Selecionar dados: divida os seus dados em três grupos: dados de treino, dados de verificação e dados de teste 2 Dados do modelo: usar dados de treinamento para construir modelos que usam características relevantes 3 Modelos de verificação: use os seus dados de verificação para acessar o seu modelo 4 Modelos de teste: use seus dados de teste para verificar o desempenho dos modelos validados 5 Usar modelos: usar modelos totalmente treinados para fazer previsões sobre novos dados 6 Modelo de ajuste: usa mais dados, características diferentes ou parâmetros ajustados para melhorar o desempenho do algoritmo
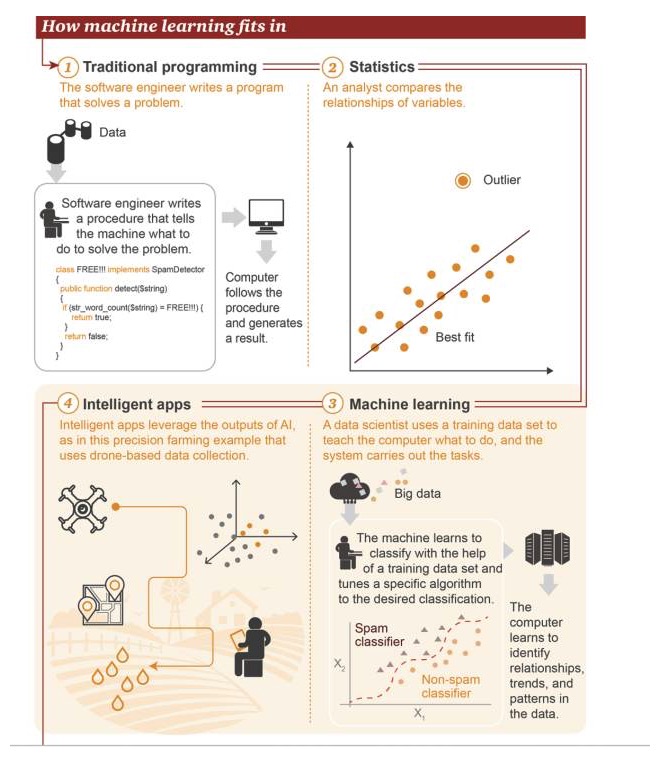
Onde está a aprendizagem de máquina?
1 Programação tradicional: engenheiros de software escrevem programas para resolver problemas. Primeiro há alguns dados→ Para resolver um problema, engenheiros de software escrevem um processo para dizer à máquina o que ela deve fazer→ O computador segue esse processo e produz resultados 2 Estatística: analistas comparam as relações entre as variáveis 3 Aprendizagem automática: os cientistas de dados usam o conjunto de dados de treinamento para ensinar o computador o que deve fazer, e depois o sistema executa a tarefa. Primeiro, há um grande conjunto de dados→ a máquina aprende a usar o conjunto de dados de treinamento para classificar e ajustar algoritmos específicos para realizar a classificação de objetivos→ o computador aprende a identificar relações, tendências e padrões nos dados 4 Aplicações inteligentes: Aplicações inteligentes Resultados obtidos com o uso de inteligência artificial, como mostrado na figura acima, é um exemplo de aplicação de agricultura de precisão, baseado em dados coletados por drones

Aplicações práticas da aprendizagem de máquina
A aprendizagem de máquina tem muitos cenários de aplicação, aqui estão alguns exemplos, como você pode usá-la?
Mapeamento e modelagem tridimensional rápida: para a construção de uma ponte ferroviária, os cientistas de dados e especialistas em campo da PwC aplicam aprendizado de máquina aos dados coletados pelos drones. Esta combinação permite um monitoramento preciso e um feedback rápido sobre o sucesso do trabalho.
Aumentar a análise para reduzir o risco: para detectar transações internas, o PwC combina aprendizado de máquina com outras técnicas de análise, desenvolvendo um perfil de usuário mais abrangente e obtendo uma visão mais profunda de comportamentos suspeitos complexos.
Objetivos de melhor desempenho: A PwC usa aprendizado de máquina e outros métodos analíticos para avaliar o potencial de diferentes cavalos na Melbourne Cup.
- #### A evolução da aprendizagem de máquina

Há décadas que os “tribos” de pesquisadores de inteligência artificial estão lutando entre si pela supremacia. Será que chegou a hora de se unirem? Eles podem ter que fazê-lo, porque a colaboração e a fusão de algoritmos é a única maneira de alcançar uma verdadeira inteligência artificial universal (AGI).
Cinco grandes gêneros
1 Simbolismo: o uso de símbolos, regras e lógica para representar conhecimento e raciocínio lógico, o algoritmo favorito é: regras e árvores de decisão 2 Bayesianismo: obtenção da probabilidade de ocorrência para a inferência de probabilidade, o algoritmo favorito é: simplório Bayesianismo ou Markovismo 3 Conectivismo: usando matrizes de probabilidade e neurônios ponderados para identificar e induzir padrões de forma dinâmica, o algoritmo favorito é: rede neural 4 Evolucionismo: gerar mudanças e, em seguida, obter o melhor para um determinado objetivo, o algoritmo favorito é: algoritmo genético 5 Analogizer: para otimizar a função de acordo com as condições de restrição ((Vai o mais alto possível, mas não saia do caminho), o algoritmo favorito é:
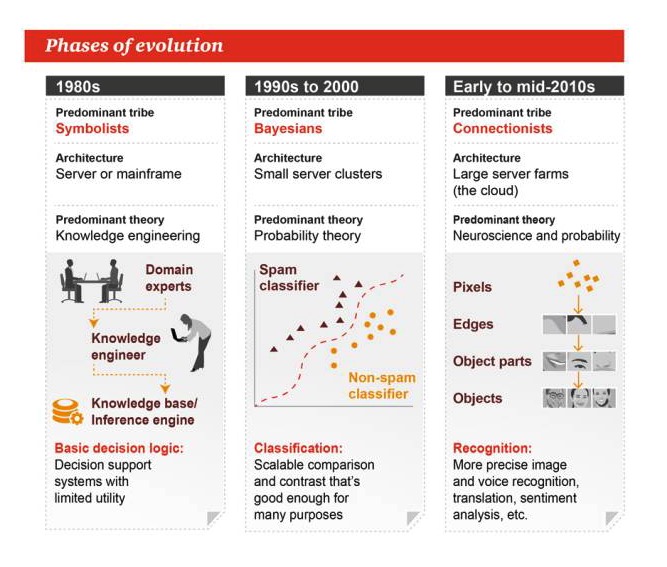
Etapas da evolução
Anos 80
Gênero dominante: Simbolismo Arquitetura: servidor ou computador Teoria dominante: engenharia do conhecimento Lógica básica de decisão: Sistemas de apoio à decisão, de utilidade limitada
Década de 1990 até 2000
Gênero dominante: Bayes Arquitetura: cluster de pequenos servidores A teoria dominante: a teoria da probabilidade. Classificação: comparação ou contraste extensivo, bom para muitas tarefas
Início e meados dos anos 2010
Gênero dominante: Ligacionismo Arquitetura: uma grande fazenda de servidores Teoria dominante: a neurociência e a probabilidade Identificação: reconhecimento de imagens e sons mais precisos, tradução, análise de emoções, etc.
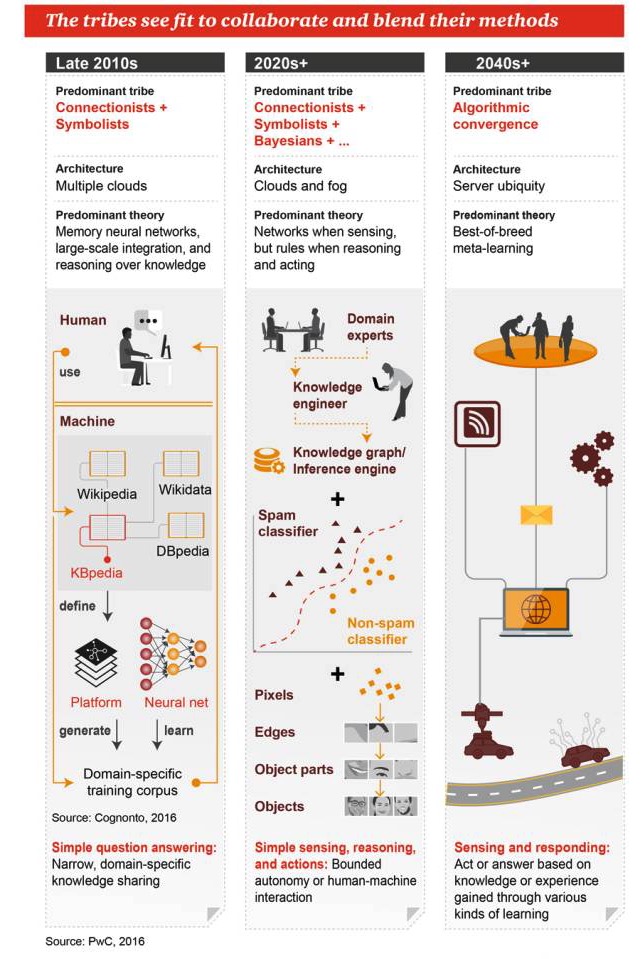
Os grupos esperam trabalhar juntos e combinar seus métodos.
Fim da década de 2010
Gênero dominante: Ligalismo + simbolismo Arquitetura: muitas nuvens Teorias dominantes: redes neurais de memória, integração em massa, raciocínio baseado no conhecimento Perguntas e respostas simples: partilha de conhecimentos de âmbito restrito e específico
Década de 2020+
Os principais gêneros: sindicalismo + simbolismo + Bayesianismo + … Arquitetura: computação em nuvem e computação em neblina Teoria dominante: quando há percepção, há rede; quando há raciocínio, há regras. Percepção, raciocínio e ação simples: limitações de automação ou interação entre humanos e máquinas
2040s+
Gêneros dominantes: fusão de algoritmos Arquitetura: servidores em todos os lugares Teoria dominante: a melhor combinação de aprendizagem meta Percepção e resposta: agir ou responder com base no conhecimento ou experiência adquiridos através de várias formas de aprendizagem
- #### Três, algoritmos de aprendizagem de máquina

Que tipo de algoritmo de aprendizado de máquina você deve usar? Isso depende muito da natureza e quantidade de dados disponíveis e de seus objetivos de treinamento em cada caso de uso específico. Não use os algoritmos mais complexos, a menos que o resultado valha a pena os gastos e recursos caros.
Árvore de decisão: Durante o processo de resposta gradual, a análise típica da árvore de decisão usa variáveis de esterilização ou nós de decisão, por exemplo, para classificar um determinado usuário como confiável ou não confiável.
Vantagens: Habilidade em avaliar uma série de características, qualidades e características diferentes de pessoas, lugares e coisas Exemplos de cenários: Avaliação de crédito baseada em regras, previsão de resultados de corridas
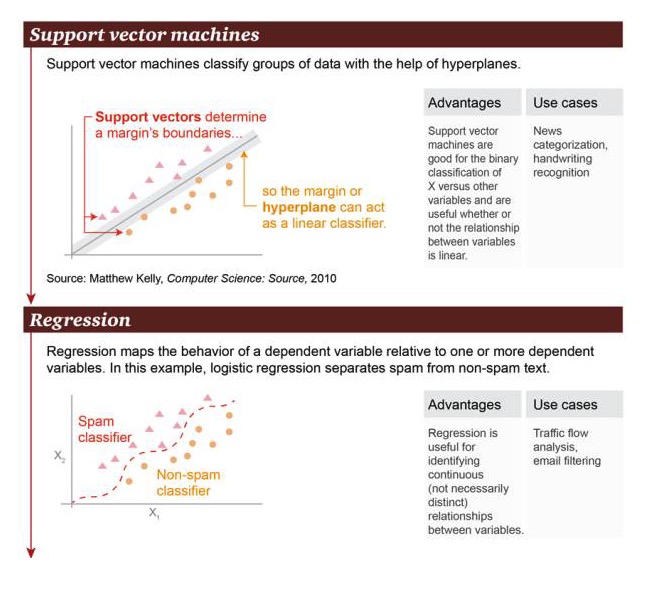
Máquina de suporte de vetores: baseada no hiperplano, a máquina de suporte de vetores pode classificar grupos de dados.
Vantagens: A máquina de suporte de vetores é boa para classificação binária entre a variável X e outras variáveis, independentemente de sua relação ser linear ou não Exemplos de cenários: classificação de notícias, identificação de manuscritos.
Regressão: regressão pode ser definida como uma relação de estado entre uma variável causal e uma ou mais variáveis causal. Neste exemplo, é feita uma distinção entre spam e não-spam.
Vantagens: A regressão pode ser usada para identificar uma relação contínua entre as variáveis, mesmo que essa relação não seja muito óbvia Scenários: análise de tráfego rodoviário, filtragem de e-mails
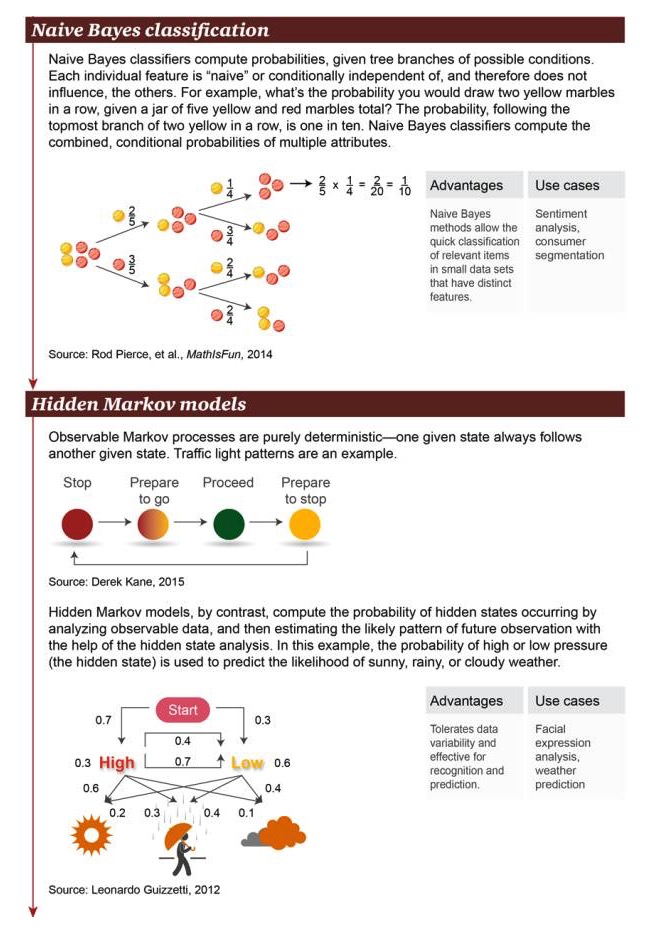
Classificação de Naive Bayes: Classificador de Naive Bayes é usado para calcular a probabilidade de subdivisão de possíveis condições. Cada característica independente é “natural” ou condicional, portanto, não afeta outros objetos. Por exemplo, qual é a probabilidade de obter duas bolas amarelas consecutivas em um pacote com um total de 5 bolas amarelas e vermelhas?
Prós: O método Bayesian simplório permite uma classificação rápida de objetos relevantes com características significativas em pequenos conjuntos de dados Exemplos de cenários: análise de sentimentos, classificação de consumidores
Modelo de Hidden Markov: Processo de Markov que demonstra que uma certa condição é frequentemente acompanhada de outra condição. Um exemplo é um semáforo. Em vez disso, o modelo de Markov calcula a ocorrência de uma condição oculta através da análise de dados visíveis.
Vantagens: Permite variabilidade de dados e aplica-se a operações de reconhecimento e previsão Exemplos de cenários: análise de expressões faciais, previsões meteorológicas
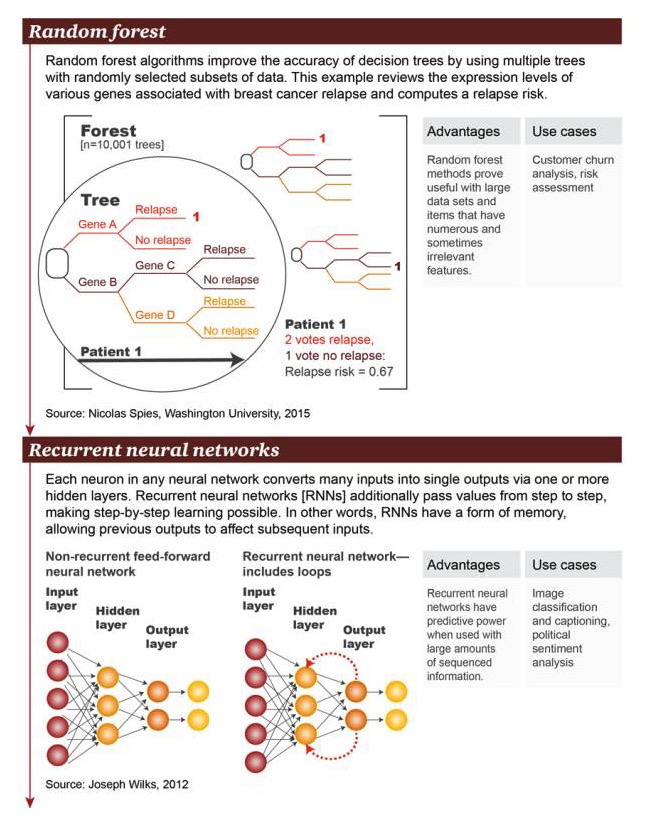
Floresta aleatória: O algoritmo de floresta aleatória melhora a precisão da árvore de decisão usando vários subconjuntos de dados aleatoriamente selecionados. Este exemplo examina um grande número de genes associados à reincidência do câncer de mama no nível de expressão genética e calcula o risco de reincidência.
Vantagens: O método da floresta aleatória tem se mostrado útil para grandes conjuntos de dados e a presença de itens com características numerosas e às vezes não relacionadas Exemplos de cenários: análise de perdas de usuários, avaliação de riscos
Rede neural recorrente: Em uma rede neural arbitrária, cada neurônio converte uma grande quantidade de entrada em uma única saída por meio de uma ou mais camadas ocultas. A rede neural recorrente transmite valores em camadas adicionais, permitindo a aprendizagem em camadas. Em outras palavras, a RNN possui uma forma de memória que permite que a saída anterior afete a entrada posterior.
Vantagens: A rede neural circular tem capacidade de previsão quando há uma grande quantidade de informação ordenada Exemplos de cenários: classificação de imagens com a adição de legendas, análise de sentimentos políticos

A memória de curto prazo (LSTM) e a rede neural de unidade recorrente de controle de portas (GRU) possuem memória de curto e longo prazo. Em outras palavras, essas RNNs possuem a capacidade de controlar melhor a memória, permitindo a retenção de valores anteriores ou a reposição desses valores quando for necessário processar uma série de passos, evitando a degradação final dos valores transmitidos em escala de “decaimento” ou “estratificação”. Com a rede GRU, podemos usar uma estrutura de memória ou módulo conhecido como “gate” para controlar a porta de memória, que pode ser reposta ou reposta quando for apropriado.
Vantagens: a memória de curto prazo e a rede de células circulares de controle de portas têm as mesmas vantagens que outras redes de células circulares, mas são mais usadas porque têm melhor capacidade de memória Exemplo de cenário: Processamento de linguagem natural, tradução
Rede neural convolutional: a convolução é a fusão de pesos de camadas subsequentes, que podem ser usadas para marcar as camadas de saída.
Prós: as redes neurais em espiral são muito úteis quando existem grandes conjuntos de dados, grandes quantidades de características e tarefas de classificação complexas Exemplos de cenários: reconhecimento de imagens, tradução de textos, detecção de drogas.
- #### O texto original em inglês:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Traduzido de Big Data Land