

Pairs trading é um ótimo exemplo de desenvolvimento de uma estratégia de trading baseada em análise matemática. Neste artigo, demonstraremos como alavancar dados para criar e automatizar uma estratégia de pairs trading.
Princípios básicos
Suponha que você tenha um par de investimentos X e Y que tenham alguma correlação subjacente, como ambas as empresas produzindo o mesmo produto, como Pepsi e Coca-Cola. Você quer que a relação de preço ou base (também chamada de spread) entre os dois permaneça constante ao longo do tempo. No entanto, o spread entre os dois pares pode divergir de tempos em tempos devido a mudanças temporárias de oferta e demanda, como grandes ordens de compra/venda para um alvo de investimento, reação a notícias importantes sobre uma das empresas, etc. Nesse caso, um investimento sobe e o outro desce em relação ao outro. Se você espera que essa divergência se normalize ao longo do tempo, poderá identificar uma oportunidade de negociação (ou oportunidade de arbitragem). Essas oportunidades de arbitragem estão por toda parte no mercado de moeda digital ou no mercado futuro de commodities domésticas, como a relação entre BTC e ativos de refúgio; a relação entre farelo de soja, óleo de soja e variedades de soja em futuros.
Quando há uma diferença temporária de preço, a negociação venderá o investimento de desempenho superior (o investimento que subiu) e comprará o investimento de desempenho inferior (o investimento que caiu). Você pode ter certeza de que há uma diferença entre os dois investimentos. o spread acabará sendo refletido pelo investimento de desempenho superior caindo para trás ou pelo investimento de desempenho inferior subindo novamente, ou ambos. Sua negociação renderá dinheiro em todos esses cenários. Se os investimentos subirem ou descerem juntos sem alterar a diferença entre eles, você não ganhará nem perderá dinheiro.
Portanto, a negociação de pares é uma estratégia de negociação neutra em relação ao mercado que permite aos traders lucrar com quase qualquer condição de mercado: tendência de alta, tendência de baixa ou lateral.
Explique o conceito: dois alvos de investimento hipotéticos
- Construindo nosso ambiente de pesquisa na Plataforma Quantitativa Inventor
Primeiro de tudo, para trabalhar sem problemas, precisamos construir nosso ambiente de pesquisa. Neste artigo, usamos a Inventor Quantitative Platform (FMZ.COM) para construir o ambiente de pesquisa, principalmente para que possamos usar a API conveniente e rápida interface e encapsulamento desta plataforma posteriormente. Sistema Docker completo.
No nome oficial da Inventor Quantitative Platform, esse sistema Docker é chamado de sistema host.
Para obter mais informações sobre como implantar hosts e robôs, consulte meu artigo anterior: https://www.fmz.com/bbs-topic/4140
Os leitores que desejam adquirir seu próprio host de implantação de servidor de computação em nuvem podem consultar este artigo: https://www.fmz.com/bbs-topic/2848
Após a implantação bem-sucedida do serviço de computação em nuvem e do sistema host, instalaremos a ferramenta Python mais poderosa: Anaconda
Para obter todos os ambientes de programa relevantes necessários para este artigo (bibliotecas dependentes, gerenciamento de versões, etc.), a maneira mais fácil é usar o Anaconda. É um ecossistema de ciência de dados Python empacotado e um gerenciador de dependências.
Para o método de instalação do Anaconda, consulte o guia oficial do Anaconda: https://www.anaconda.com/distribution/
Este artigo também usará numpy e pandas, duas bibliotecas muito populares e importantes na computação científica Python.
Para o trabalho básico acima, você também pode consultar meu artigo anterior, que apresenta como configurar o ambiente Anaconda e as duas bibliotecas numpy e pandas. Para detalhes, consulte: https://www.fmz.com/digest- tópico/4169
Em seguida, vamos usar o código para implementar "duas metas de investimento hipotéticas"
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
Sim, também usaremos o matplotlib, uma biblioteca de gráficos muito famosa em Python.
Vamos gerar um ativo de investimento hipotético X e simular a plotagem de seus retornos diários usando uma distribuição normal. Em seguida, realizamos uma soma cumulativa para obter o valor diário de X.
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
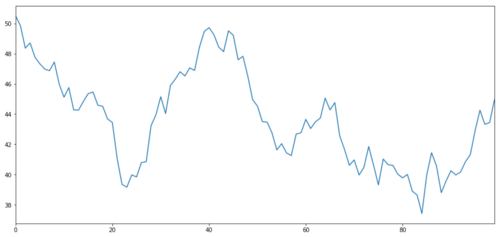
Meta de investimento X, simular e desenhar seu retorno diário através da distribuição normal
Agora geramos Y que está fortemente correlacionado com X, então o preço de Y deve se mover de forma muito semelhante às mudanças em X. Modelamos isso pegando X, deslocando-o para cima e adicionando algum ruído aleatório extraído de uma distribuição normal.
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
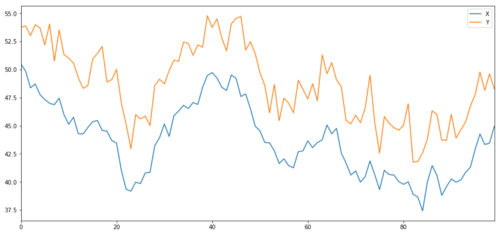
Cointegração dos alvos de investimento X e Y
Cointegração
A cointegração é muito semelhante à correlação, o que significa que a razão entre duas séries de dados variará em torno da média. As duas séries Y e X seguem o seguinte:
Y = ⍺ X + e
onde ⍺ é uma razão constante e e é o ruído.
Para um par de negociação entre duas séries temporais, o valor esperado da razão ao longo do tempo deve convergir para a média, ou seja, elas devem ser cointegradas. As séries temporais que construímos acima são cointegradas. Agora desenharemos a escala entre os dois para que possamos ver como ficará.
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
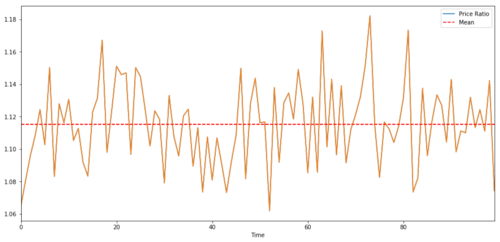
A razão e a média dos preços de dois investimentos cointegrados
Teste de Cointegração
Uma maneira conveniente de testar isso é usar statsmodels.tsa.stattools. Deveríamos ver um valor de p muito baixo porque criamos artificialmente duas séries de dados que são tão cointegradas quanto possível.
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
O resultado é: 1.81864477307e-17
Nota: Correlação e Cointegração
Embora correlação e cointegração sejam semelhantes na teoria, elas não são a mesma coisa. Vejamos exemplos de séries de dados que são correlacionadas, mas não cointegradas, e vice-versa. Primeiro, vamos verificar a correlação da série que acabamos de gerar.
X.corr(Y)
O resultado é: 0,951
Como esperávamos, isso é muito alto. Mas o que dizer de duas séries que são correlacionadas, mas não cointegradas? Um exemplo simples são duas séries de dados que divergem.
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
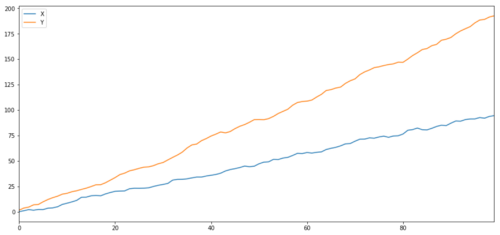
Duas séries relacionadas (não co-integradas)
Coeficiente de correlação: 0,998
Valor de p do teste de cointegração: 0,258
Exemplos simples de cointegração sem correlação são uma série distribuída normalmente e uma onda quadrada.
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
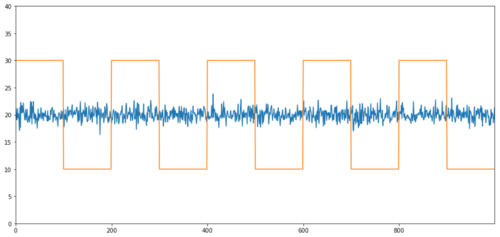
Correlação: 0,007546
Teste de cointegração valor p: 0,0
A correlação é muito baixa, mas o valor de p mostra cointegração perfeita!
Como fazer negociação de pares?
Como duas séries temporais cointegradas (como X e Y acima) se aproximam e se afastam uma da outra, há momentos em que há uma base alta e uma base baixa. Realizamos negociação de pares comprando um investimento e vendendo outro. Dessa forma, se os dois alvos de investimento caírem ou subirem juntos, não ganhamos nem perdemos dinheiro, ou seja, somos neutros em relação ao mercado.
Voltando para X e Y em Y = ⍺ X + e acima, ganhamos dinheiro fazendo a razão (Y/X) se mover em torno de sua média ⍺. Para fazer isso, notamos que quando X Quando o valor de ⍺ é muito alto ou muito baixo, o valor de ⍺ é muito alto ou muito baixo:
-
Proporção Longa: É quando a proporção ⍺ é pequena e esperamos que ela fique maior. No exemplo acima, abrimos uma posição comprando Y e vendendo X.
-
Razão curta: ocorre quando a razão ⍺ é grande e esperamos que ela se torne menor. No exemplo acima, abrimos uma posição vendendo Y e comprando X.
Observe que sempre temos uma “posição protegida”: se a posição longa subjacente perde valor, a posição curta ganha dinheiro, e vice-versa, então somos imunes aos movimentos gerais do mercado.
À medida que os ativos X e Y se movem em relação um ao outro, ganhamos ou perdemos dinheiro.
Use dados para encontrar transações com comportamento semelhante
A melhor maneira de fazer isso é começar com as negociações que você suspeita que podem ser cointegradas e realizar testes estatísticos. Se você realizar um teste estatístico em todos os pares de negociação, você seráViés de comparações múltiplasvítima de.
Viés de comparações múltiplasrefere-se à situação em que a chance de gerar falsamente um valor p significativo aumenta ao executar muitos testes, porque precisamos executar um grande número de testes. Se executarmos esse teste 100 vezes em dados aleatórios, veremos 5 valores de p abaixo de 0,05. Se você estiver comparando n instrumentos para cointegração, você estará realizando comparações n(n-1)/2 e verá muitos valores de p incorretos, que aumentarão conforme o tamanho da sua amostra de teste aumentar. E aumentar. Para evitar isso, selecione alguns pares de negociação que você tenha motivos para acreditar que provavelmente serão cointegrados e, em seguida, teste-os individualmente. Isso reduzirá bastanteViés de comparações múltiplas。
Então, vamos tentar encontrar alguns instrumentos que exibem cointegração. Vamos pegar uma cesta de ações de tecnologia de grande capitalização dos EUA no S&P 500. Esses instrumentos operam em segmentos de mercado semelhantes e exibem cointegração. preço. Analisamos a lista de instrumentos de negociação e testamos a cointegração entre todos os pares.
A matriz de pontuação do teste de cointegração retornada, a matriz de valor p e todas as correspondências em pares com um valor p menor que 0,05 estão incluídas.Esse método é propenso a viés de comparação múltipla, então, na prática, eles precisam realizar uma segunda validação. Neste artigo, para conveniência de nossa explicação, optamos por ignorar isso nos exemplos.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
Nota: Incluímos o benchmark de mercado (SPX) em nossos dados - o mercado impulsiona o fluxo de muitos instrumentos e, muitas vezes, você pode encontrar dois instrumentos que parecem ser cointegrados; mas, na verdade, eles não são cointegrados entre si, mas sim cointegrados com o mercado. Isso é chamado de variável de confusão. É importante examinar a participação de mercado em qualquer relacionamento que você encontrar.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

Agora vamos tentar encontrar pares de negociação cointegrados usando nosso método.
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
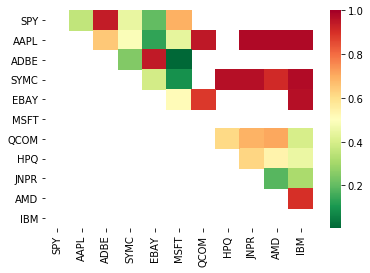
Parece que 'ADBE' e 'MSFT' são cointegrados. Vamos dar uma olhada no preço para ter certeza de que realmente faz sentido.
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
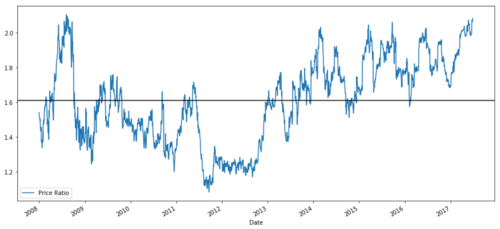
Gráfico da relação de preços entre MSFT e ADBE de 2008 a 2017
Essa proporção parece uma média estável. Proporções absolutas não são muito úteis estatisticamente. É mais útil normalizar nosso sinal visualizando-o como um z-score. O escore Z é definido como:
Z Score (Value) = (Value — Mean) / Standard Deviation
avisar
Na prática, geralmente tentamos aplicar alguma expansão aos dados, mas somente se os dados forem distribuídos normalmente. No entanto, muitos dados financeiros não são distribuídos normalmente, então devemos ter muito cuidado para não simplesmente presumir normalidade ou qualquer distribuição específica ao gerar estatísticas. A distribuição real das proporções pode ter caudas grossas, e dados que tendem aos extremos podem confundir nosso modelo e levar a grandes perdas.
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
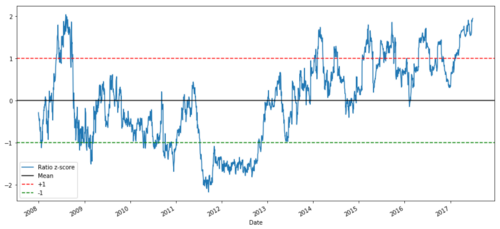
Razão Z-Preço entre MSFT e ADBE de 2008 a 2017
Agora é mais fácil ver como a proporção se move em torno da média, mas às vezes ela tende a ter grandes desvios da média, o que podemos explorar.
Agora que discutimos os fundamentos de uma estratégia de negociação de pares e identificamos alvos de cointegração com base no histórico de preços, vamos tentar desenvolver um sinal de negociação. Primeiro, vamos rever as etapas para desenvolver sinais de negociação usando técnicas de dados:
-
Coletando dados confiáveis e limpando dados
-
Crie funções a partir de dados para identificar sinais/lógica de negociação
-
Os recursos podem ser médias móveis ou dados de preços, correlações ou proporções de sinais mais complexos - combine-os para criar novos recursos
-
Use esses recursos para gerar sinais de negociação, ou seja, quais sinais são posições de compra, venda ou curta
Felizmente, temos a Inventor Quantitative Platform (fmz.com) para completar os quatro aspectos acima para nós. Esta é uma grande bênção para desenvolvedores de estratégia. Podemos gastar nossa energia e tempo em lógica de estratégia, design e expansão funcional.
Na Inventor Quantitative Platform, há interfaces empacotadas de várias bolsas tradicionais. Tudo o que precisamos fazer é chamar essas interfaces de API. O restante da lógica de implementação subjacente foi polida por uma equipe profissional.
Para fins de completude lógica e explicação dos princípios, apresentaremos essas lógicas subjacentes de maneira detalhada, mas na operação real, os leitores podem chamar diretamente a interface da API do Inventor Quant para concluir os quatro aspectos acima.
Vamos começar:
Etapa 1: configure seu problema
Aqui estamos tentando criar um sinal que nos diz se a proporção será de compra ou venda no próximo momento, que é nossa variável preditora Y:
Y = Ratio is buy (1) or sell (-1)
Y(t)= Sign(Ratio(t+1) — Ratio(t))
Observe que não precisamos prever o preço real do ativo subjacente, ou mesmo o valor real da proporção (embora possamos), precisamos apenas prever a direção da proporção em seguida.
Etapa 2: coletar dados confiáveis e precisos
O Inventor Quant é seu amigo! Basta especificar os instrumentos que deseja negociar e a fonte de dados que deseja usar, e ele extrairá os dados necessários e os limpará para divisões de dividendos e instrumentos. Então nossos dados aqui já estão muito limpos.
Usamos os seguintes dados do Yahoo Finance para dias de negociação nos últimos 10 anos (aproximadamente 2.500 pontos de dados): abertura, fechamento, alta, baixa e volume
Etapa 3: Divida os dados
Não se esqueça desta etapa muito importante de testar a precisão do seu modelo. Estamos usando a seguinte divisão de treinamento/validação/teste dos dados
-
Training 7 years ~ 70%
-
Test ~ 3 years 30%
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
O ideal seria também criar um conjunto de validação, mas não faremos isso por enquanto.
Etapa 4: Engenharia de recursos
Quais poderiam ser as funções relacionadas? Queremos prever a direção da mudança de proporção. Vimos que nossos dois instrumentos são cointegrados, então essa proporção tenderá a mudar e retornar à média. Parece que nossa característica deve ser alguma medida da média da razão, e a diferença entre o valor atual e a média pode gerar nosso sinal de negociação.
Utilizamos as seguintes funções:
-
Razão da média móvel de 60 dias: uma medida da média móvel
-
Razão da média móvel de 5 dias: uma medida do valor atual da média
-
Desvio padrão de 60 dias
-
Pontuação z: (5d MA - 60d MA) / 60d DP
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
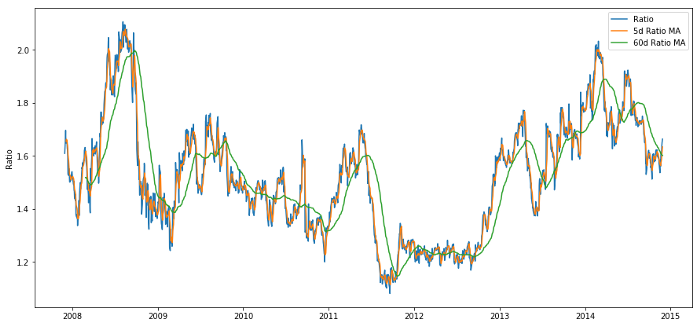
Relação de preço de 60d e 5d MA
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
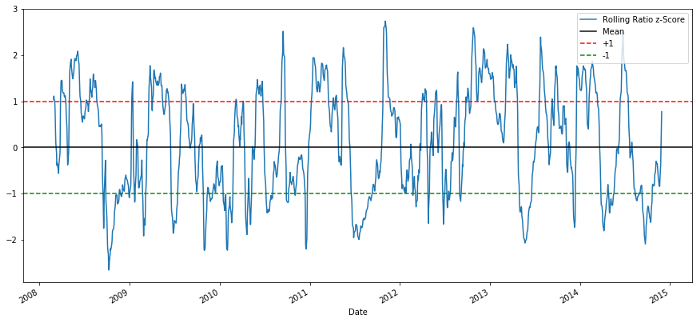
60-5 Índice de preço do Z-score
O Z-score da média móvel realmente destaca a natureza de reversão da média da proporção!
Etapa 5: Seleção do modelo
Vamos começar com um modelo muito simples. Observando o gráfico do escore z, podemos ver que sempre que o escore z é muito alto ou muito baixo, ele regride. Vamos usar +1/-1 como nossos limites para definir muito alto e muito baixo, então podemos usar o seguinte modelo para gerar sinais de negociação:
-
Quando z está abaixo de -1,0, a razão é comprar (1) porque esperamos que z retorne a 0, então a razão aumenta
-
Quando z está acima de 1,0, a razão é vendida (-1) porque esperamos que z retorne a 0, diminuindo assim a razão
Etapa 6: Treinamento, Validação e Otimização
Por fim, vamos ver o impacto real do nosso modelo em dados reais? Vamos ver como esse sinal se comporta em proporções reais
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
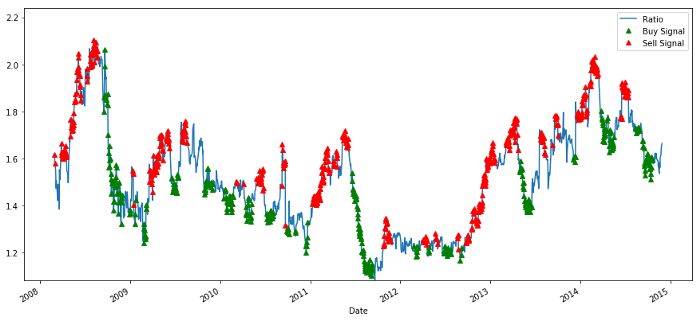
Sinais de relação de preço de compra e venda
Este sinal parece razoável, parece que vendemos a proporção quando ela está alta ou aumentando (pontos vermelhos) e a compramos de volta quando ela está baixa (pontos verdes) e diminuindo. O que isso significa para o objeto real de nossas transações? vamos ver
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
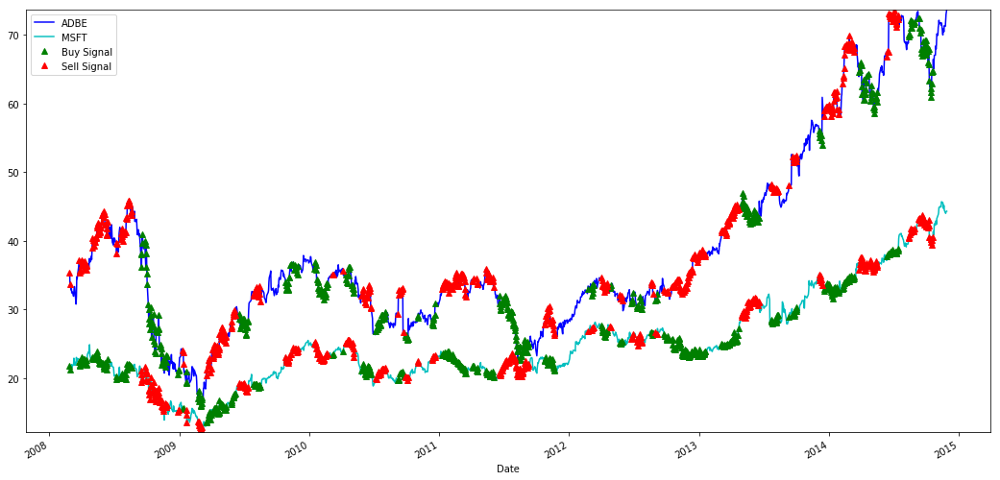
Sinais para comprar e vender ações da MSFT e ADBE
Observe como às vezes ganhamos dinheiro na "perna curta", às vezes na "perna longa" e às vezes em ambas.
Estamos felizes com o sinal dos dados de treinamento. Vamos ver que tipo de lucro esse sinal pode gerar. Podemos fazer um backtester simples que compra 1 proporção (compra 1 ação ADBE e vende proporção x ação MSFT) quando a proporção está baixa e vende 1 proporção (vende 1 ação ADBE e compra proporção x ação MSFT) e calcula o PnL das negociações para essas proporções.
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
O resultado é: 1783.375
Então essa estratégia parece ser lucrativa! Agora, podemos otimizar ainda mais alterando a janela de tempo da média móvel, alterando os limites para posições de compra/venda e fechamento, etc., e verificar as melhorias de desempenho nos dados de validação.
Também podemos tentar modelos mais complexos como Regressão Logística, SVM, etc. para previsões 1/-1.
Agora, vamos avançar neste modelo, o que nos leva a
Etapa 7: Faça o backtest dos dados de teste
Aqui, gostaria de mencionar a Inventor Quantitative Platform. Ela usa um mecanismo de backtesting QPS/TPS de alto desempenho para reproduzir verdadeiramente o ambiente histórico, eliminar armadilhas comuns de backtesting quantitativo e descobrir prontamente as deficiências da estratégia, de modo a fornecer melhor - investimento de tempo. Ofereça ajuda.
Para explicar o princípio, este artigo escolhe mostrar a lógica subjacente. Na aplicação prática, é recomendado que os leitores usem a Inventor Quantitative Platform. Além de economizar tempo, o importante é melhorar a taxa de tolerância a falhas.
O backtesting é simples. Podemos usar a função acima para visualizar o PnL dos dados de teste.
trade(data[‘ADBE’].iloc[1762:], data[‘MSFT’].iloc[1762:], 60, 5)
O resultado é: 5262.868
Este modelo é muito bem feito! Tornou-se nosso primeiro modelo simples de negociação de pares.
Evite overfitting
Antes de encerrar, quero falar especificamente sobre overfitting. O overfitting é a armadilha mais perigosa nas estratégias de negociação. Um algoritmo de overfitting pode ter um desempenho extremamente bom em backtesting, mas falhar em dados novos e não vistos - o que significa que ele não revela nenhuma tendência nos dados e não tem poder preditivo real. Vamos dar um exemplo simples.
Em nosso modelo, usamos estimativas de parâmetros contínuos e esperamos otimizar a duração da janela de tempo. Podemos decidir simplesmente iterar sobre todas as possibilidades, durações de janela de tempo razoáveis e escolher a duração de tempo com base na qual nosso modelo tem melhor desempenho. Abaixo, escrevemos um loop simples para pontuar a duração da janela de tempo com base no PNL dos dados de treinamento e encontrar o melhor loop.
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
Agora verificamos o desempenho do modelo nos dados de teste e vemos que essa janela de tempo está longe de ser ideal! Isso ocorre porque nossa escolha original claramente superajusta os dados da amostra.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
Aparentemente, o que funciona bem para nossos dados de amostra nem sempre produz bons resultados no futuro. Apenas para teste, vamos plotar as pontuações de comprimento calculadas a partir dos dois conjuntos de dados
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
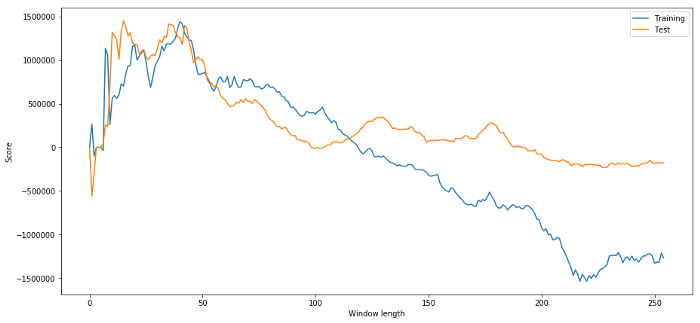
Podemos ver que qualquer valor entre 20 e 50 é uma boa escolha para a janela de tempo.
Para evitar overfitting, podemos usar o raciocínio econômico ou as propriedades do algoritmo para escolher a duração da janela de tempo. Também podemos usar um filtro de Kalman, que não exige que especifiquemos um comprimento; esse método será abordado mais adiante em outro artigo.
Próximo passo
Neste artigo, apresentamos alguns métodos introdutórios simples para demonstrar o processo de desenvolvimento de uma estratégia de negociação. Na prática, estatísticas mais sofisticadas devem ser usadas, e você pode considerar as seguintes opções:
-
Expoente de Hurst
-
A meia-vida da reversão média inferida do processo de Ornstein-Uhlenbeck
-
Filtro de Kalman
