
Полное объяснение преимуществ и недостатков трех основных категорий и шести основных алгоритмов машинного обучения.
В машинном обучении целью является либо прогнозирование (prediction), либо кластеризация (clustering). В данной статье основное внимание уделяется прогнозированию. Прогнозирование - это процесс, при помощи которого мы оцениваем значение выходной переменной из набора входных переменных. Например, получив набор характеристик, касающихся дома, мы можем спрогнозировать его цену на продажу.
Теперь давайте рассмотрим наиболее известные и наиболее часто используемые алгоритмы в машинном обучении. Мы разделили их на три категории: линейные модели, деревообразующие модели и нейронные сети.
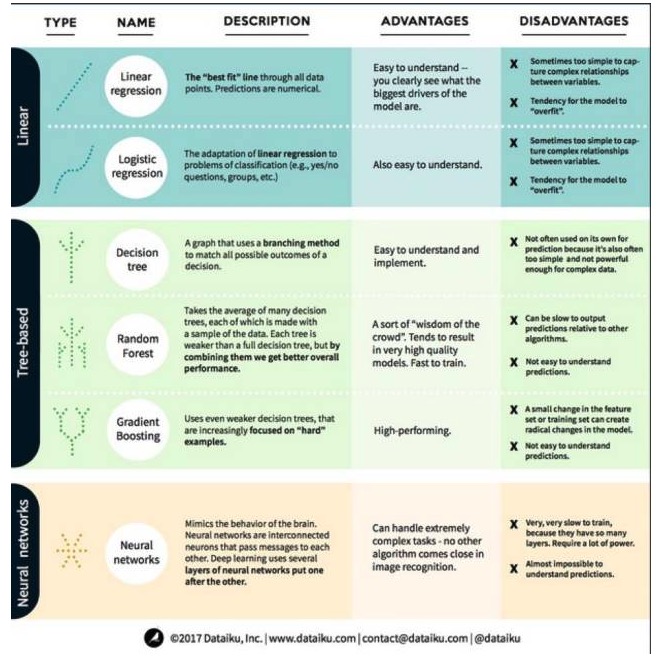
Линейный модельный алгоритм: линейный модель использует простые формулы для поиска наиболее подходящих линий из ряда из ряда с помощью набора точек данных. Этот метод, который датируется более 200 лет назад, широко используется в области статистики и машинного обучения. Из-за своей простоты он полезен для статистики.
-
1. Линейная регрессия
Линейная регрессия, или, точнее говоря, регрессия на малейшее двойное число, является самой стандартной формой линейных моделей. Линейная регрессия является самой простой линейной моделью для регрессионных задач. Ее недостатком является то, что модель легко перенастраивается, то есть модель полностью адаптируется к обученным данным, жертвуя способностью к распространению на новые данные.
Еще один недостаток линейных моделей заключается в том, что они очень просты, поэтому они не могут легко предсказать более сложное поведение, когда входные переменные не независимы.
-
2. Логическая регрессия
Логическая регрессия является адаптацией линейной регрессии к классификационным задачам. У нее те же недостатки, что и у линейной регрессии. Логическая функция очень хороша для классификационных задач, поскольку она вводит эффект трамплина.
Второе, алгоритмы древесных моделей
-
1. Дерево решений
Дерево решений - это диаграмма, которая показывает каждый возможный результат решения, используя разветвленный метод. Скажем, вы решили заказать салат, и ваше первое решение - это, возможно, сорт овощей, затем - сорта блюд, а затем - сорт салата.
Для обучения дерева принятия решений нам необходимо использовать набор обученных данных и определить, какой атрибут наиболее полезен для цели. Например, в примере использования для обнаружения мошенничества мы можем обнаружить, что атрибут, который оказывает наибольшее влияние на прогнозирование риска мошенничества, - это страна. После разделения на первый атрибут мы получаем два подсета, которые наиболее точно прогнозируются, если мы знаем только первый атрибут. Затем мы находим второй лучший атрибут, который можно разделить на эти два подсета, снова разделить, и так далее, до тех пор, пока не будет удовлетворены потребности цели, используя достаточное количество атрибутов.
-
Второе, случайные леса
Случайный лес - это среднее из множества деревьев для принятия решений, каждое дерево для принятия решений обучается с помощью случайных образцов данных. Каждое дерево в случайном лесу слабее, чем целое дерево для принятия решений, но если собрать все деревья вместе, мы получим лучшую общую производительность из-за преимущества разнообразия.
Случайный лес является очень популярным алгоритмом в современном машинном обучении. Случайный лес легко обучается и довольно хорошо работает. Его недостатком является то, что прогноз вывода из случайного леса может быть медленным по сравнению с другими алгоритмами, поэтому, когда требуется быстрое прогнозирование, случайный лес может не быть выбран.
-
Третье, повышение.
Градиентный подъем, как и случайные леса, состоит из слабых и слабых деревьев решения. Самым большим отличием градиентного подъема от случайных лесов является то, что в градиентном подъеме деревья обучаются один за другим. Каждое дерево позади обучается в основном ошибочным данным, идентифицированным деревом впереди.
Тренировки с повышением степени также быстрые и очень эффективные. Однако небольшие изменения в тренируемом наборе данных могут привести к фундаментальным изменениям в модели, поэтому результаты, которые она дает, могут быть не самыми практичными.
Нейронные сети - это биологические явления, состоящие из взаимосвязанных нейронов, обменивающихся информацией друг с другом в мозге. Эта идея теперь применяется в области машинного обучения, называемая ANN (Артифизическая нейронная сеть). Глубокое обучение представляет собой многослойную нейронную сеть, сложенную вместе.
Продолжение из Big Data
- 1