Оружие AlphaGo: алгоритм Монте-Карло, вы поймете его, прочитав это! (с примером кода)--Перепечатать
 0
23883
0
23883
Альфа-собака: алгоритм Монте-Карло, посмотрите и поймете!
С 9 по 15 марта этого года в Сеуле, Южная Корея, состоялась грандиозная битва между человеком и машиной, которая длилась пять туров. В результате этого матча люди проиграли, а мировой чемпион по гоу Ли Ши Ши был побеждён программой AlphaGo, разработанной Google, со счетом 1:4. Итак, что такое AlphaGo и где ключ к победе?
- ### Алгоритмы AlphaGo и Монте-Карло
Согласно сообщению агентства Синьхуа, программа AlphaGo - это программа для игры в гоа, разработанная командой DeepMind, принадлежащей американской компании Google, и которая была названа китайскими фанатами как “Альфа-кук”.
В нашей предыдущей статье мы рассказывали о нейронной сети, которую Google разрабатывает для автономного обучения машин, и о том, что AlphaGo - это аналогичный продукт.
Заместитель председателя правления и генеральный секретарь Китайской ассоциации автоматизации Ван Файюй сказал, что программистам не нужно быть знатоками гоуч, а только знать основные правила гоуч. За AlphaGo стоит группа выдающихся компьютерных ученых, точнее, экспертов в области машинного обучения.
В этом случае, где ключ к самообучению AlphaGo? Это алгоритм Монте Карло.
Что такое алгоритм Монте-Карло? Давайте попробуем объяснить алгоритм Монте-Карло: Если бы в корзине было 1000 яблок, и каждый раз, когда вы закрывали глаза, вы искали бы самое большое, вы могли бы выбирать неограниченное количество раз. Таким образом, вы могли бы с закрытыми глазами выбирать один случайный, затем выбирать еще один случайный, сравнивать его с первым, оставляя большой, затем выбирать еще один случайный, сравнивать его с предыдущим, оставляя большой.
То есть, алгоритм Монте-Карло заключается в том, что чем больше образцов, тем лучшее решение, но это не гарантируется, потому что если бы было 10000 яблок, то, вероятно, можно было бы найти больше.
Его можно сравнить с алгоритмом из Лас-Вегаса: По общепринятому мнению, если есть замок, то есть 1000 ключей для выбора, но только один из них является правильным. Поэтому каждый раз, когда вы случайно берёте один ключ, чтобы попробовать его открыть, не получается, и вы меняете его. Чем больше попыток, тем больше шансов открыть наилучшее решение, но до открытия те ключи, которые были ошибочными, были бесполезны.
Таким образом, алгоритм Лас-Вегаса является наилучшим возможным решением, но не обязательно найденным. Предположим, что из 1000 ключей не может быть открыт ни один ключ, настоящий ключ - 1001-й ключ, но в образце нет 1001-го алгоритма, и алгоритм Лас-Вегаса не может найти ключ, открывающий замок.
Алгоритм Монте-Карло от AlphaGo Игры в гоу особенно сложны для искусственного интеллекта, потому что в игре есть так много разновидностей, что компьютерам трудно их различить. Во-первых, в гоу слишком много возможностей. На каждом шаге гоу очень много возможных вариантов, и у шахматиста есть 19 × 19 = 361 вариант падения. Во-вторых, в 150 раундах гоу может возникнуть до 10 170 ситуаций. Во-вторых, правила слишком тонкие, и в какой-то степени выбор падения зависит от интуиции, сформированной накопленным опытом.
AlphaGo - это не просто алгоритм Монте-Карло, а, скорее, его модернизация.
AlphaGo использует алгоритм поиска в деревьях Монте-Карло и две глубинные нейронные сети для создания шахматных игр. Перед тем, как столкнуться с Ли Ши Ши, Google сначала тренировал нейронную сеть AlphaGo с помощью почти 30 миллионов шагов человеческих пар, чтобы она могла предсказать, как проиграют профессиональные шахматисты.
Их задача состоит в том, чтобы совместно отбирать наиболее перспективные шаги и отбрасывать наиболее очевидные ошибки, таким образом, ограничивая вычисления в пределах, которые могут быть выполнены компьютером. По сути, это то же самое, что делают человеческие шахматисты.
Исследователь Института автоматизации Китайской академии наук И Цзянян говорит, что традиционное программное обеспечение для игры в шахматы обычно использует насильственный поиск, включая глубокий синий компьютер, который создает поисковое дерево для всех возможных результатов (каждый результат - это плод на дереве), а по мере необходимости выполняет обходный поиск. Этот метод также имеет определенную реализацию в шахматах, шашках и т. Д., но не для гоу-гоу, потому что гоу-гоу проходит по 19 линиям, а вероятность падения настолько велика, что компьютер не может построить это дерево (сли плодов слишком много), чтобы осуществить обходный поиск.
Далее, как объясняет Вангач, одна из основных единиц глубинной нейронной сети похожа на нейрон в нашем человеческом мозге, и многие слои связаны друг с другом, как будто это нейронная сеть в человеческом мозге. Две нейронные сети в AlphaGo - это стратегическая сеть и оценочная сеть.
В процессе игры в шахматы он не думает о том, как он должен проиграть, а думает о том, как проиграет лучший человек. То есть, он будет прогнозировать, где будет следующий шаг человека, основываясь на текущем состоянии вводной доски, и предлагает несколько возможных вариантов, которые наиболее соответствуют человеческому мышлению.
Однако, стратегическая сеть не знает, будет ли ее шаг хорошим или плохим, она только знает, будет ли он таким же, как у человека, и тогда сеть оценивания будет работать.
По словам Пугачжи, “сеть оценок кристаллов оценивает ситуацию в целом по диапазону для всех возможных вариантов, а затем дает кристалл выигрыша”. Эти значения отражаются в алгоритме поиска дерева Монте-Карло, который вызывает наивысший кристалл выигрыша путем повторения этого процесса.
AlphaGo использует эти два инструмента для анализа ситуации, чтобы оценить преимущества и недостатки каждой из следующих стратегий, как человеческий шахматист будет оценивать текущую ситуацию и делать выводы о будущей ситуации. Используя алгоритм поиска в дереве Монте-Карло, чтобы проанализировать, например, следующие 20 шагов, можно будет определить, где вероятность выигрыша будет выше.
Несомненно, алгоритм Монте-Карло является одним из основных элементов AlphaGo.
Два небольших эксперимента Наконец, посмотрим на два небольших эксперимента с алгоритмом Монте-Карло.
- ### 1. Вычислить величину окружности pi.
Принцип: сначала нарисуй квадрат, нарисуй кружок внутри него, затем в этом квадрате рисуй случайную точку, которая входит в круг, примерно P, тогда P = площадь круга / площадь квадрата. P=(Pi*R*R)/(2R*2R) = Pi/4, то есть Pi=4P
Что делать? 1. Поставив центр круга в исходной точке, сделав круг с радиусом R, получим площадь 1⁄4 круга первого квадрата, равную площади Pi*R*R/4 2. Сделайте внешний квадрат этого 1⁄4 круга, координатами которого являются ((0,0) ((0,R) ((R,0) ((R,R), тогда площадь этого квадрата равна R*R 3. Возьмите точку ((X, Y), чтобы 0 <= X <= R и 0 <= Y <= R, то есть точка находится внутри квадрата 4. По формуле X*X+Y*Y*R находится в пределах 1⁄4 окружности. 5. Предположим, что число всех точек (то есть количество экспериментов) N, а число точек, находящихся в пределах 1⁄4 круга (точки, которые соответствуют шагу 4), M.
P=M/N, то есть Pi=4.*N/M
 Первый снимок.
Первый снимок.
M_C(10000) получит результат 3.1424
- ### 2. Модель Монте-Карло искала предельные значения функций, чтобы избежать локальных предельных значений
# В промежутках[-2,2] выводит число, вычисляет его y и находит наибольшую из них, считая, что функция[Максимальное значение на -2,2]
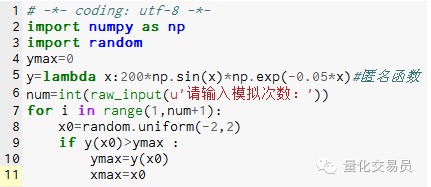 Рисунок 2
Рисунок 2
После 1000 имитаций обнаружено максимальное значение 185.12292832389875 (очень точно)
Это очень интересно, ведь код можно писать руками! Копировалось из WeChat Public