Машинное обучение для развлечения: простейшее руководство для начинающих
 3
3605
3
3605
Машинное обучение для развлечения: простейшее руководство для начинающих
Когда вы слышите, что люди говорят о машинном обучении, у вас есть лишь несколько мнимых представлений о том, что это означает? Или вы устали от того, что вы можете только кивать головой в разговоре с коллегами? Давайте изменим это!
Цель этого руководства - помочь всем, кто интересуется машинным обучением, но не знает, с чего начать. Я думаю, что многие из вас, прочитав статью в Википедии о машинном обучении, расстроены тем, что никто не может дать высокоуровневого объяснения.
Целью статьи является доступность, а это означает, что в статье присутствует множество обобщений. Но кого это волнует? Задача выполнена, если мы сможем заинтересовать читателей ML.
- ### Зачем машинное обучение?
Концепция машинного обучения предполагает, что для решения задачи вам не нужно писать никаких специальных программных кодов, генетические алгоритмы (генерические алгоритмы) могут получить интересные ответы для вас на наборе данных. Для генетических алгоритмов не нужно кодировать, а вводить данные, они будут строить свою собственную логику на данных.
Например, существует алгоритм, называемый классификационным алгоритмом, который может разделить данные на различные группы. Классификационный алгоритм, используемый для распознавания рукописных цифр, может быть использован для разделения электронной почты на спам и обычную почту без изменения одного строка кода.
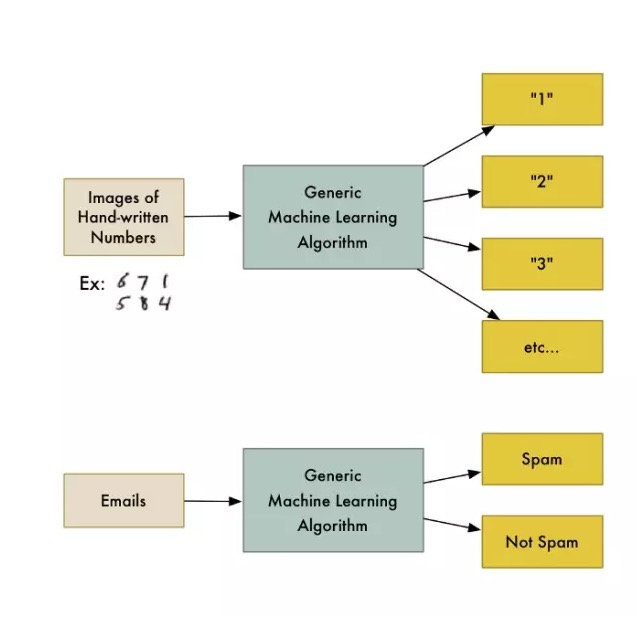
Алгоритмы машинного обучения - это черный ящик, который может быть использован повторно для решения множества различных классификационных задач.
“Машинное обучение” - это широкий термин, охватывающий множество аналогичных генетических алгоритмов.
- ### Два типа алгоритмов машинного обучения
Вы можете разделить алгоритмы машинного обучения на две основные категории: контролируемое обучение и неконтролируемое обучение. Различия между ними просты, но очень важны.
-
Наблюдаемое обучение
Предположим, что вы агент по недвижимости, и ваш бизнес становится все больше и больше, поэтому вы нанимаете группу стажеров, чтобы помочь вам. Но проблема в том, что вы можете увидеть дом и узнать, сколько он стоит, а стажеры не имеют опыта и не знают, как его оценить.
Для того, чтобы помочь вашим стажерам (и, возможно, для того, чтобы освободить себя от необходимости отправиться в отпуск), вы решили написать небольшое программное обеспечение, которое позволит вам оценить стоимость жилья в вашем районе на основе таких факторов, как размер дома, площадь и цена покупки аналогичного жилья.
Вы записываете каждую сделку на жилье в городе за три месяца, и в каждой из них вы записываете длинный список деталей: количество спален, размер дома, участок и т.д. Но, что самое важное, вы записываете конечную цену сделки:
Это наша тренировочная база данных.
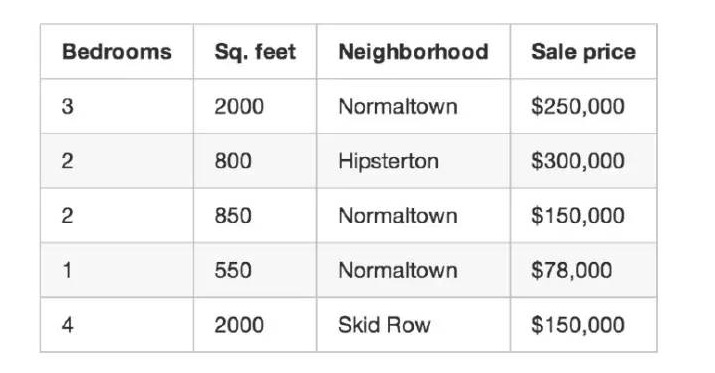
Мы собираемся использовать данные, полученные в ходе обучения, чтобы создать программу оценки стоимости других домов в этом районе:

Это называется “наблюдаемое обучение”. Вы уже знаете цену продажи каждого дома, то есть вы знаете ответ на вопрос, и вы можете перевернуть логику решения на обратную сторону.
Чтобы написать программное обеспечение, вы вводите в свой алгоритм машинного обучения данные обучения, содержащие каждый набор недвижимости. Алгоритм пытается выяснить, какие операции следует использовать для получения цифр цен.
Это как упражнение по математике, в котором все знаки оператора были стерты:
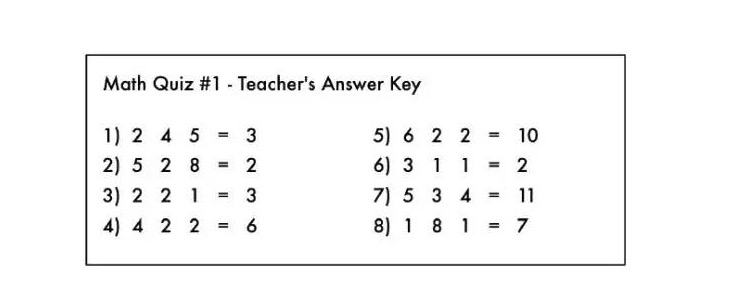
Боже мой! Один хитроумный студент стер все символы математики с ответов учителя.
Если вы посмотрите на эти задачи, вы поймете, что это за математические задачи? Вы знаете, что вы должны сделать с числовыми столбцами слева, чтобы получить ответ на числовые столбцы справа.
В контролируемом обучении вы позволяете компьютеру рассчитывать взаимосвязи между числами за вас. И как только вы знаете математические методы, необходимые для решения этих конкретных задач, вы можете решать другие подобные задачи.
-
Ненаблюдаемое обучение
Возвращаясь к примеру с риэлтором, с которого мы начали, если вы не знаете, сколько стоит продажа каждого дома, вы можете создать классный дизайн, даже если вы знаете только его размер, расположение и т. д. Это называется неконтролируемым обучением.
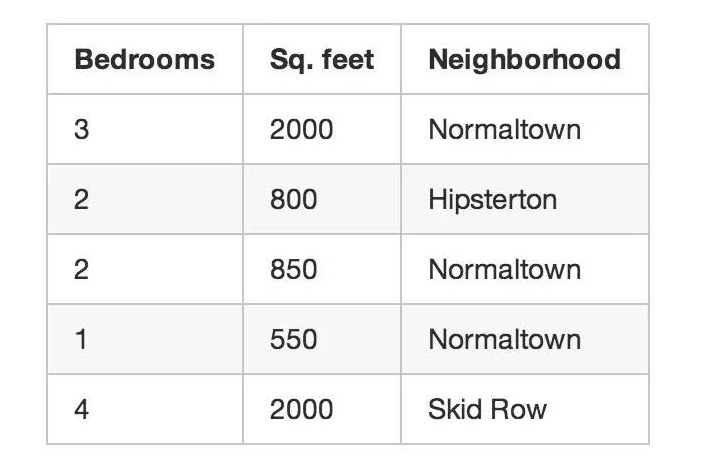
Даже если вы не хотите предсказывать неизвестные данные (например, цены), вы можете использовать машинное обучение, чтобы сделать что-то интересное.
Это как если бы кто-то дал вам лист бумаги, на котором написано множество цифр, и сказал бы вам: “Я не знаю, что эти цифры означают, но, может быть, вы сможете вычислить из них закономерности или классифицировать их, или что-то в этом роде - удачи вам!”
Что делать с этими данными? Во-первых, вы можете использовать алгоритм для автоматического выделения различных сегментов рынка из данных. Возможно, вы обнаружите, что покупатели домов вблизи университетов предпочитают дома с небольшими спальнями, в то время как покупатели домов в пригороде предпочитают дома с тремя спальнями.
Вы также можете сделать что-то крутое, автоматически выявить цены на недвижимость, которые отличаются от других данных. Эти недвижимости в скоплениях могут быть высотными зданиями, и вы можете сосредоточить лучших продавцов в этих районах, потому что они получают более высокие комиссии.
В дальнейшем мы будем в основном обсуждать НЛ, но это не значит, что НЛ не очень полезно или что оно не имеет никакого смысла. Фактически, НЛ становится все более важным с улучшением алгоритмов, поскольку данные не связаны с правильными ответами.
Есть много других видов алгоритмов машинного обучения, но это хорошо для начинающих.
Это круто, но можно ли оценивать цены на жилье как урок?
Как человек, ваш мозг способен справляться с большинством ситуаций и учиться справляться с ними без каких-либо четких указаний. Если вы работаете в сфере недвижимости долгое время, у вас есть инстинктивное чувство, что недвижимость имеет правильную цену, как ее лучше всего продавать, какие клиенты будут заинтересованы и т. Д.
Но современные алгоритмы машинного обучения не настолько хороши, чтобы сосредоточиться только на очень конкретных, ограниченных проблемах. Возможно, в этом случае более подходящим определением машинного обучения является поиск уравнения для решения конкретной проблемы на основе небольшого количества образцовых данных.
К сожалению, для решения конкретной задачи на основе небольшого количества образцовых данных уравнение, полученное с помощью машины, называется слишком плохим именем. Поэтому в конечном итоге мы заменили его на уравнение, полученное с помощью машины, обучающейся уравнению.
Конечно, если вы будете читать эту статью через 50 лет, тогда мы уже получим мощный алгоритм искусственного интеллекта, а этот текст будет выглядеть как старинный артефакт.
Давайте напишем код!
Как вы собираетесь написать программу оценки стоимости жилья, приведенную в предыдущем примере?
Если вы ничего не знаете о машинном обучении, скорее всего, вы попытаетесь написать несколько основных правил оценки цен на жилье, например:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # In my area, the average house costs $200 per sqft price_per_sqft = 200 if neighborhood == "hipsterton": # but some areas cost a bit more price_per_sqft = 400 elif neighborhood == "skid row": # and some areas cost less price_per_sqft = 100 # start with a base price estimate based on how big the place is price = price_per_sqft * sqft # now adjust our estimate based on the number of bedrooms if num_of_bedrooms == 0: # Studio apartments are cheap price = price — 20000 else: # places with more bedrooms are usually # more valuable price = price + (num_of_bedrooms * 1000) return priceЕсли вы будете так заняты по несколько часов, вы, возможно, немного преуспеете, но ваша программа никогда не будет идеальной, и ее сложно поддерживать, когда цены меняются.
Если бы мы могли дать компьютерам возможность выяснить, как выполнять эти функции, разве это не было бы лучше?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return priceОдин из способов рассмотреть эту проблему - рассматривать цены на жилье как чашу вкусного соуса, в которую входят количество спален, площадь и участок. Если вы сможете вычислить, насколько каждый компонент влияет на конечную цену, возможно, вы получите конкретную пропорцию, в которой различные ингредиенты смешиваются, чтобы сформировать конечную цену.
Это может упростить вашу первоначальную программу (все сумасшедшие “если еще”) примерно так:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return priceОбратите внимание на магические цифры, обозначенные как 841231951398213, 1231.1231231, 2.3242341421, и 201.23432095. Они называются весами. Если бы мы могли найти идеальный вес, применимый к каждому дому, наша функция могла бы предсказать цены на все дома!
Один из способов определить оптимальный вес:
Шаг первый:
Во-первых, наложите вес на каждую цифру в размере 1.0:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return priceШаг второй:
Введите каждую недвижимость в свою функцию, чтобы проверить, насколько оценка отклонена от правильной цены:
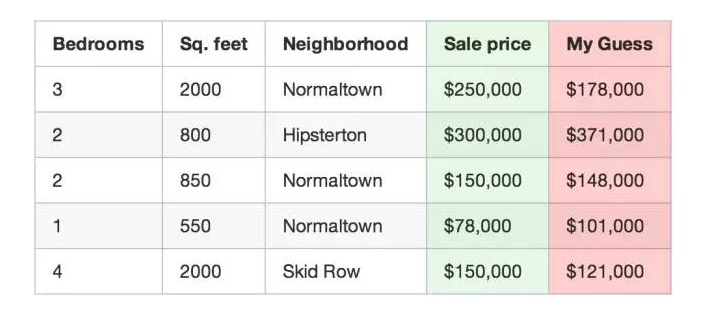
Используйте свою программу для прогнозирования цен на жилье.
Например, если цена первой недвижимости в таблице составляет \(250,000, а ваша функция оценивает ее в \)178,000, то вы потеряли $72,000 от этой недвижимости.
Затем вы суммируете оценку каждой недвижимости в вашем наборе данных квадратом отклонения от стоимости. Предположим, что в наборе данных есть 500 сделок с недвижимостью, сумма оценок квадрата отклонения от стоимости составляет 86 123 373 долларов США. Это отражает то, насколько правильно ваша функция теперь работает.
Теперь делим сумму на 500 и получаем оценку отклонения от среднего значения для каждого дома. Назовем это среднее значение отклонения стоимостью вашей функции.
Если вы можете изменить вес, чтобы цена была равна нулю, то ваша функция идеальна. Это означает, что ваша программа оценивает каждую сделку недвижимости точно так же, как и вводимые данные. И это наша цель - попытаться использовать разные веса, чтобы цена была как можно ниже.
Шаг третий:
Повторяйте шаг 2 снова и снова, пробуйте все возможные комбинации весовых значений. Какая комбинация приближает стоимость к нулю, это то, что вам нужно использовать, и как только вы найдете такую комбинацию, проблема будет решена!
Мысли, отвлекающие время
Подумайте о том, что вы только что сделали. Вы получили данные, ввели их в три простых общепринятых шага, и в итоге получили функцию, которая позволяет оценивать дома в вашем районе. Но следующие факты могут запутать вас:
-
- За последние 40 лет исследования в различных областях (например, лингвистика/транслятология) показали, что алгоритмы обучения, подобные общепринятому динамическому алгоритму данных (слово, которое я создал), превосходят методы, требующие использования четких правил, сделанных реальными людьми.
-
- Функция, которую вы написали в конце, была очень странной, она даже не знала, что такое квадратный квадрат и квадратный квадратный квадрат. Она знала только, как пошевелить и поменять цифры, чтобы получить правильный ответ.
-
- Скорее всего, вы не знаете, почему конкретный набор весов работает. Поэтому вы просто написали функцию, которую вы не понимаете, но можете доказать.
-
- Представьте, что вместо параметров, таких как квадрат площади лимона и квадрат номера спальни лимона, в вашей программе принимается набор цифр. Предположим, что каждая цифра представляет собой пиксель из изображения, захваченного камерой, установленной на крыше вашей машины, а затем прогнозируемый выход называется не квадрат цены лимона, а квадрат оборота лимона, и таким образом вы получаете программу, которая может автоматически манипулировать вашей машиной!
Это безумие, не так ли?
Что происходит, когда курицы в шаге 3 пробуют каждую цифру?
Ну, конечно, вы не можете попробовать все возможные значения весов, чтобы найти наилучшую комбинацию. Это займет много времени, потому что количество попыток может быть бесконечным. Чтобы избежать этого, математики нашли множество умных способов быстро найти хорошие значения веса без особых усилий. Вот один из них: Во-первых, напишите простое уравнение, которое обозначает эти два шага:
Это ваша стоимостная функция.
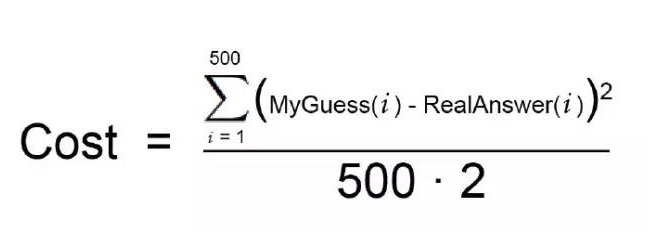
Теперь давайте перепишем эти же математические термины в машинном обучении (вы можете игнорировать их сейчас):
θ означает текущее значение весов. J ((θ) означает стоимость, соответствующую текущему значению весов.
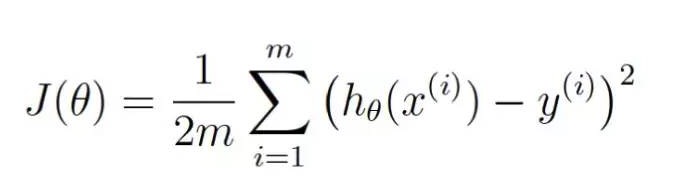
Это уравнение показывает, насколько наша оценка отклонена от текущего веса.
Если отобразить все возможные значения веса, присвоенных количеству и площади спален, в графическом виде, мы получим график, похожий на следующий:
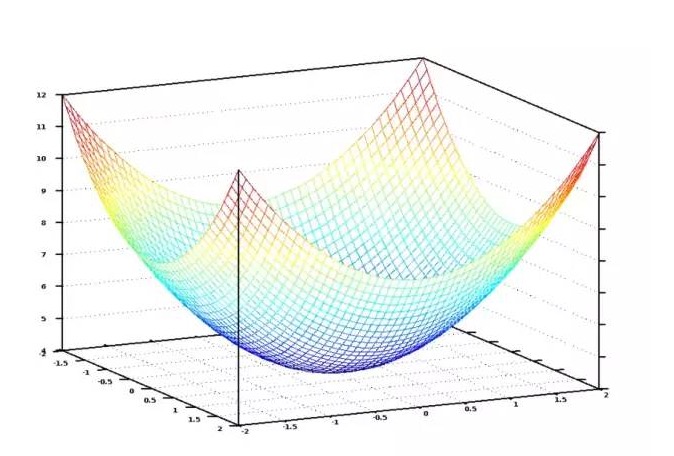
Графический изображение функции стоимости - чаша. Вертикальная ось показывает стоимость.
Синие точки на диаграмме - это наименьшие отклонения от цены, то есть наша программа отклонена наименее. Самые высокие точки - это наибольшие отклонения от цены.
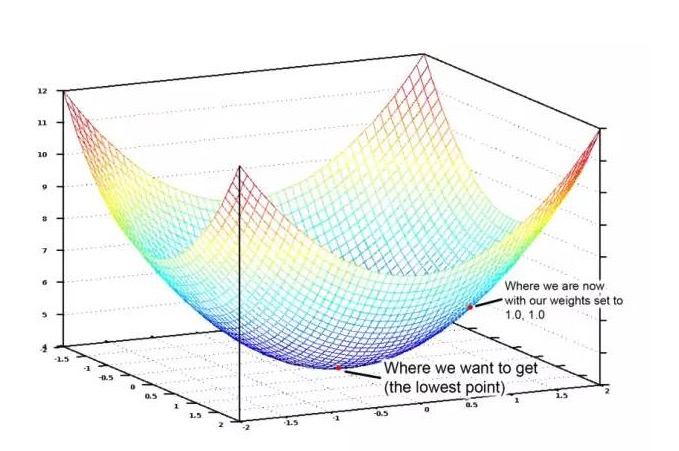
Таким образом, нам просто нужно настроить вес так, чтобы мы могли идти вниз по склону к самой низкой точке на графике. Если мелкие настройки веса позволяют нам двигаться вниз, то в конечном итоге мы сможем добраться туда, не пытаясь слишком много весов.
Если вы хоть немного помните алгебры, то, возможно, помните, что если вы спросите о какой-то функции, то получите результат, который говорит вам, насколько она скользит в любой точке. Другими словами, для данной точки на графике, она говорит нам, что эта дорога идет вниз.
Итак, если мы искали искажение функции стоимости для каждого веса, то мы можем вычесть это значение из каждого веса. Это приближает нас к дну горы. Продолжайте делать это, и в конечном итоге мы достигнем дна и получим наилучшее значение веса.
Этот метод определения оптимального веса называется массовым gradient descent, о котором выше приведено высокое обобщение. Если вы хотите узнать подробности, не бойтесь, продолжайте углубляться (http://hbfs.wordpress.com/2012/04/24/introduction-to-gradient-descent/).
Когда вы используете библиотеку алгоритмов машинного обучения для решения реальных проблем, все это уже готово для вас. Но всегда полезно знать некоторые конкретные детали.
Что еще вы пропустили?
Трехступенчатый алгоритм, описанный мной выше, называется полилинейной регрессией. Вы используете уравнение, чтобы найти прямую линию, которая будет соответствовать всем точкам данных о ценах на жилье. Затем вы используете это уравнение, чтобы оценить цены на дома, которые вы никогда не видели, в зависимости от того, где они могут быть на вашей прямой.
Но этот метод, который я покажу вам, может работать в некоторых простых случаях, но не во всех. Одна из причин в том, что цены не всегда следуют простой прямой линии.
Но, к счастью, существует множество способов справиться с этой ситуацией. Для нелинейных данных можно использовать множество других типов алгоритмов машинного обучения (например, нейронные сети или ядерные векторные машины). Существует множество способов использовать линейную регрессию более гибко, чтобы подобрать более сложные линии.
Кроме того, я упустил понятие совпадения. Очень легко столкнуться с таким набором значений, которые прекрасно прогнозируют цены на жилье в вашем исходном наборе данных, но не точно прогнозируют любые новые дома за пределами исходного набора данных.
Другими словами, основная концепция очень проста, и для получения полезных результатов в машинном обучении требуются некоторые навыки и опыт. Но это навыки, которые может выучить каждый разработчик.
-
-
Является ли машинное обучение безграничным?
Как только вы начинаете понимать, что технологии машинного обучения легко применимы к решению сложных задач (например, распознавание почерка), у вас появляется ощущение, что, если у вас достаточно данных, вы можете решить любую проблему с помощью машинного обучения. Просто введите данные, и вы увидите, как компьютерный фокус вычисляет уравнения, соответствующие данным.
Но важно помнить, что машинное обучение может применяться только к проблемам, которые можно решить с помощью данных, которые у вас есть.
Например, если вы построите модель, которая будет прогнозировать стоимость жилья на основе количества бонанов в каждом доме, она никогда не будет успешной. Нет никакой связи между количеством бонанов в доме и ценой жилья. Поэтому, как бы он ни пытался, компьютер не сможет вывести связь между ними.
Вы сможете моделировать только те отношения, которые есть на самом деле.
-
Как углубиться в машинное обучение
Я считаю, что самая большая проблема с машинным обучением в настоящее время заключается в том, что оно активно используется в академических и коммерческих исследовательских организациях. Для тех, кто хочет иметь общие знания, а не быть экспертами, не так много простых и понятных учебных материалов. Но это становится лучше с каждым днем.
Профессор Чон Да (Andrew Ng) Бесплатные курсы по машинному обучению на Coursera очень хороши. Я настоятельно рекомендую начать здесь.
Кроме того, вы можете загрузить и установить SciKit-Learn и использовать его для тестирования тысяч алгоритмов машинного обучения.
Копировано разработчиками Python