
Обзор алгоритмов машинного обучения
После понимания проблем машинного обучения, которые нам нужно решить, мы можем подумать о том, какие данные нам нужно собирать и какие алгоритмы мы можем использовать. В этой статье мы пройдемся по самым популярным алгоритмам машинного обучения, чтобы получить представление о том, какие методы могут быть полезны.
В области машинного обучения существует множество алгоритмов, и каждый из них имеет множество расширений, поэтому очень сложно определить, какой из них является правильным для конкретной проблемы. В этой статье я хочу показать вам два способа, как можно объединить алгоритмы, встречающиеся в реальности.
-
Метод обучения
Алгоритмы делятся на различные типы в зависимости от того, как они обрабатывают опыт, окружение или что мы называем входом. Учебники машинного обучения и искусственного интеллекта обычно рассматривают методы обучения, к которым могут приспособиться алгоритмы.
Здесь обсуждаются лишь несколько основных стилей обучения или моделей обучения, и есть несколько основных примеров. Такой подход к классификации или организации хорош, потому что он заставляет вас думать о ролях ввода данных и процессе подготовки модели, а затем выбрать алгоритм, который наиболее подходит для вашей проблемы, чтобы получить наилучшие результаты.
Наблюдаемое обучение: вводные данные называются обучающими данными, и имеют известный результат или маркируются. Например, сообщается, является ли письмо спамом, или что цены на акции в течение определенного периода времени. Модель делает прогнозы, которые исправляются, если они ошибаются, и этот процесс продолжается до тех пор, пока она не достигнет определенного правильного стандарта для обучающих данных.
Ненаблюдаемое обучение: входные данные не маркируются и не имеют определенного результата. Модели индукционируют структуру и числовые значения данных. Примеры проблем включают в себя обучение правилам ассоциации и проблемы кластеризации, примеры алгоритмов включают в себя алгоритмы Apriori и алгоритмы K-среднего значения.
Полунаблюдаемое обучение: входные данные представляют собой смесь маркированных и немаркированных данных, есть некоторые проблемы с прогнозированием, но модели также должны изучать структуру и состав данных. Примеры проблем включают в себя классификационные и регрессивные проблемы, алгоритмические примеры - это в основном расширение алгоритмов неконтролируемого обучения.
Усиленное обучение: вводные данные могут стимулировать модель и заставлять модель реагировать. Отзывы получаются не только от процесса обучения, который контролируется, но и от вознаграждения или наказания в окружающей среде. Примеры проблем - это роботоконтроль, примеры алгоритмов включают Q-learning и Temporal difference learning.При интеграции в бизнес-решения по моделированию данных большинство использует методы контролируемого и неконтролируемого обучения. Следующая горячая тема - полунаблюдаемое обучение, например, классификация изображений, в которой есть большая база данных, но только небольшая часть изображений маркирована.
-
Сходство алгоритмов
Алгоритмы в основном классифицируются по функционалу или форме. Например, алгоритмы, основанные на деревьях, алгоритмы нейронных сетей. Это очень полезный способ классификации, но не идеальный.
В этом разделе я перечислил алгоритмы классификации, которые я считаю наиболее интуитивными. Я не исчерпываю алгоритмов или методов классификации, но я думаю, что это поможет читателям получить общую информацию. Если вы знаете что-то, что я не перечислил, пожалуйста, оставьте комментарий.
-
Regression
Регрессия (или регрессивный анализ) занимается отношениями между переменными. Она применяет статистические методы. Примеры нескольких алгоритмов включают:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
Instance based learning (обучение, основанное на примерах) моделирует задачу принятия решения, причем используемые примеры или примеры очень важны для модели. Этот метод создает базу данных с существующими данными, затем добавляет новые данные, а затем использует метод измерения сходства, чтобы найти наилучшее совпадение в базе данных и сделать прогноз. По этой причине этот метод также известен как метод победителя и метод, основанный на памяти.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
Это расширение на другие методы (обычно регрессивные), которые способствуют более простым моделям и лучше подходят для индукции. Я перечисляю их здесь, потому что они популярны и сильны.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Decision tree methods (методы дерева решений) создают модель решений, основанную на фактических значениях в данных. Деревья решений используются для решения индукционных и регрессионных задач.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
Bayesian method - метод применения теоремы Бейеса для решения классификационных и регрессионных задач.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
Наиболее известным из Kernel Method является Support Vector Machines. Этот метод отображает входные данные в более высоких измерениях, что облегчает моделирование некоторых классификационных и регрессионных задач.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
Кластеризация (англ. clustering, сгруппирование) - это сама по себе проблема и метод. Кластеризация обычно классифицируется методом моделирования. Все методы кластеризации организуют данные с помощью единой структуры данных, чтобы в каждой группе было как можно больше общего.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
Association rule learning - это метод, используемый для выявления закономерностей между данными, с помощью которых можно обнаружить связи между огромным количеством данных в многомерном пространстве, и эти важные связи могут быть использованы организацией.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
Искусственные нейронные сети (AI) вдохновлены структурой и функцией биологических нейронных сетей. Они относятся к классу моделирования, часто используемого для регрессионных и классификационных задач, но состоят из сотен алгоритмов и вариантов.
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
Метод Deep Learning является современным обновлением искусственных нейронных сетей. По сравнению с традиционными нейронными сетями, он имеет большее количество более сложных сетевых конструкций, многие методы имеют дело с полунаблюдаемым обучением, в котором есть большие данные, но мало что из них маркировано.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionality Reduction (уменьшение размера), как и метод кластеризации, преследует и использует единую структуру в данных, но использует меньше информации для редукции и описания данных. Это полезно для визуализации или упрощения данных.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Ensemble methods состоят из множества небольших моделей, которые обучаются самостоятельно, делают самостоятельные выводы и в конечном итоге составляют общий прогноз. Много исследований сосредоточено на том, какие модели использовать и как эти модели объединены. Это очень мощный и популярный метод.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
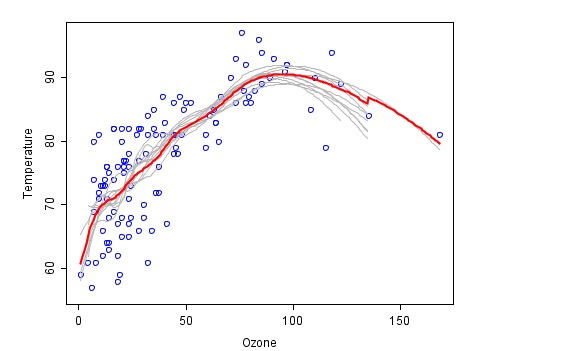
Это пример сопоставления с помощью комбинированного метода ((из Википедии), где каждый пожарный закон обозначен серым, а окончательный прогноз последнего синтеза - красным.
-
Другие ресурсы
Эта экскурсия по алгоритмам машинного обучения предназначена для того, чтобы дать вам общее представление о том, что такое алгоритмы, и некоторые инструменты, связанные с алгоритмами.
Ниже приведены некоторые другие ресурсы, не думайте, что это слишком много, чем больше вы узнаете об алгоритмах, тем лучше для вас, но глубокое знание некоторых алгоритмов также может быть полезным.
- Список алгоритмов машинного обучения (List of Machine Learning Algorithms): это ресурс на Википедии, хотя и очень полный, но я думаю, что классификация не очень хороша.
- Категория:Алгоритмы машинного обучения (Machine Learning Algorithms Category): Это также ресурс на Википедии, немного лучше, чем выше, в алфавитном порядке.
- CRAN Task View: Machine Learning & Statistical Learning: Расширенный набор алгоритмов машинного обучения на языке R, который поможет вам лучше понимать, что делают другие люди.
- Top 10 Algorithms in Data Mining: это опубликованная статья, а теперь и книга, включающая в себя наиболее популярные алгоритмы для добычи данных. Другой список базовых алгоритмов, в котором перечислено не так много алгоритмов, поможет вам углубиться в изучение.
Копировано из колонки Бэрла / разработчики Python
- 1