Три картинки для понимания машинного обучения: основные концепции, пять основных школ и девять распространенных алгоритмов
 0
2546
0
2546
Три картинки для понимания машинного обучения: основные концепции, пять основных школ и девять распространенных алгоритмов
- #### Обзор машинного обучения

Что такое машинное обучение?
Машины учатся, анализируя большие объемы данных. Например, их не нужно программировать, чтобы распознавать кошки или человеческие лица. Они могут быть обучены использованию изображений, чтобы резюмировать и распознавать конкретные цели.
Машинное обучение и искусственный интеллект
Машинное обучение - это разновидность исследований и алгоритмов, в которых мы ищем модели в данных и используем эти модели для прогнозирования. Машинное обучение является частью области искусственного интеллекта и пересекается с открытием знаний и добычей данных.
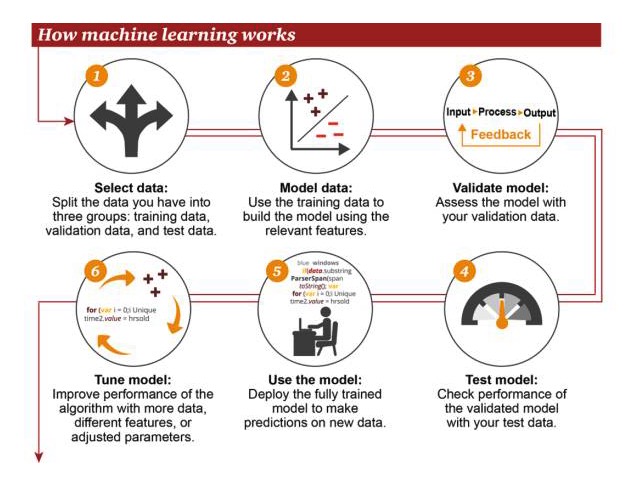
Как работает машинное обучение
1 Выбор данных: разделите ваши данные на три группы: обучающие данные, проверяющие данные и тестирующие данные 2 Модельные данные: использование тренировочных данных для построения моделей с использованием соответствующих характеристик 3 Проверка модели: используйте ваши данные для проверки доступа к вашей модели 4 Тестирование моделей: использование ваших тестовых данных для проверки эффективности проверенных моделей 5 Использование моделей: использование полностью обученных моделей для прогнозирования новых данных 6 Оптимизирующая модель: использование большего количества данных, различных признаков или отрегулированных параметров для повышения производительности алгоритма
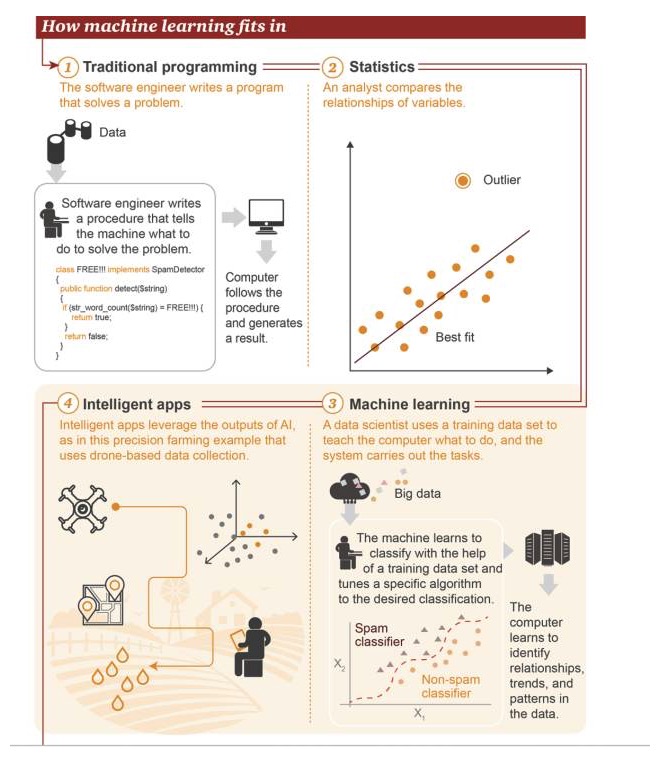
Где находится машинное обучение
1 Традиционное программирование: инженер-программист пишет программу для решения задачи. Сначала существуют данные→ Для решения задачи инженер-программист пишет процесс, чтобы сказать машине, что она должна делать→ Компьютер выполняет этот процесс, а затем получает результат 2 Статистика: аналитик сравнивает отношения между переменными 3 Машинное обучение: учёный использует обученный набор данных, чтобы научить компьютер тому, что он должен делать, а затем система выполняет эту задачу. Сначала существуют большие данные→ машина учится использовать обученный набор данных для классификации, регулируя определенные алгоритмы для достижения целевой классификации→ компьютер учится распознавать отношения, тенденции и модели в данных 4 Умные приложения: умные приложения Результаты, полученные с использованием искусственного интеллекта, показанные на рисунке, являются примером применения в точном сельском хозяйстве, которое основано на данных, собранных беспилотниками

Практическое применение машинного обучения
Есть множество сценариев применения машинного обучения, и вот несколько примеров, как вы можете использовать его.
Быстрое трехмерное картографирование и моделирование: для строительства железнодорожного моста, ученые-данные и эксперты в области PwC применяют машинное обучение к данным, собранным беспилотниками. Эта комбинация обеспечивает точный мониторинг и быструю обратную связь в успехе работы.
Усиление аналитики для снижения риска: для обнаружения внутренних сделок, PwC объединяет машинное обучение и другие аналитические технологии, чтобы разработать более полную профиль пользователя и получить более глубокое понимание сложного подозрительного поведения.
Прогнозирование лучших результатов: PwC использует машинное обучение и другие аналитические методы для оценки потенциала различных лошадей на стадионах Melbourne Cup.
- #### Эволюция машинного обучения

Различные “племена” исследователей искусственного интеллекта на протяжении десятилетий боролись друг с другом за господство. Не пора ли им объединиться? Возможно, им придется это сделать, потому что сотрудничество и слияние алгоритмов - это единственный способ достичь истинного общего искусственного интеллекта (AGI).
Пятерка
1 Символизм: использование символов, правил и логики для обозначения знаний и логического рассуждения, любимые алгоритмы: правила и деревья решений 2Бейсизм: получение вероятности происшествия для вероятностного рассуждения, предпочтительный алгоритм: наивный Бейс или Марков 3 Коннективизм: использование вероятностных матриц и весовых нейронов для динамического распознавания и индукции моделей, любимый алгоритм: нейронные сети 4 Эволюционизм: создание изменений, а затем извлечение наилучших из них для конкретных целей, любимый алгоритм: генетический алгоритм 5 Analogizer: оптимизировать функции в зависимости от ограничительных условий ((поднимайтесь как можно выше, но в то же время не уходите с дороги), самый любимый алгоритм: поддержка векторных машин
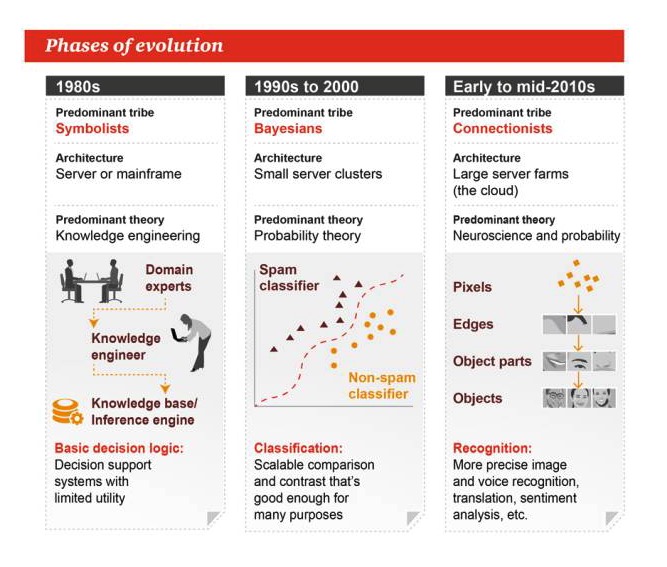
Этапы эволюции
1980-е годы
Главный жанр: символизм Архитектура: сервер или крупный компьютер Основная теория: инженерия знаний Основная логика принятия решений: системы поддержки принятия решений, ограниченная практичность
1990-е - 2000-е годы
Основные жанры: Бейес Архитектура: небольшие кластеры серверов Доминирующая теория: теория вероятности Классификация: расширяемая сравнительная или противопоставляющая, достаточно хорошая для многих задач
Начало и середина 2010-х
Основная группа: конъюнктура Архитектура: серверная ферма Доминирующие теории: нейробиология и вероятность Идентификация: более точная идентификация изображений и звуков, перевод, эмоциональный анализ и т.д.
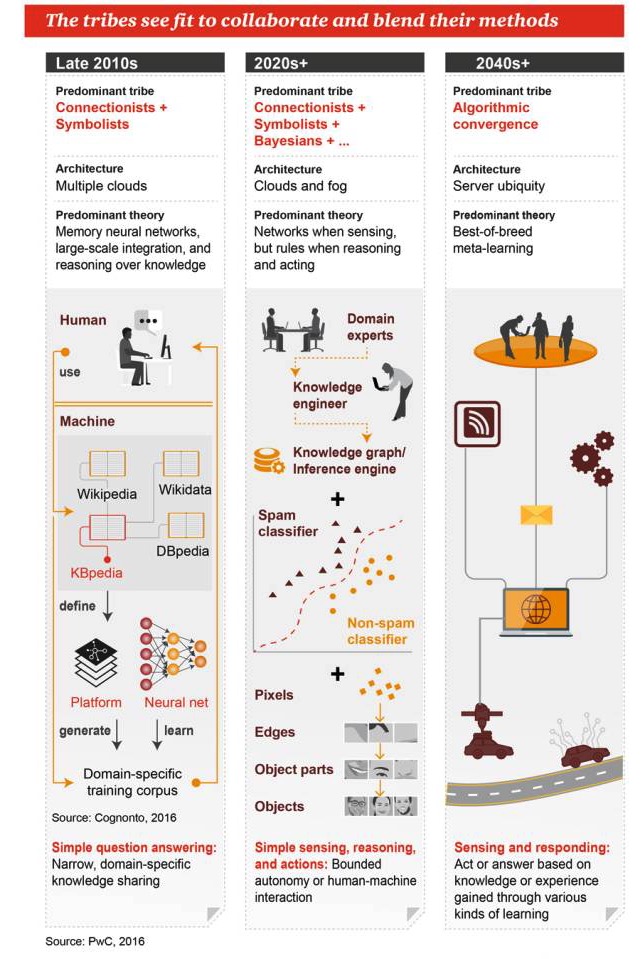
Эти группы надеются сотрудничать и объединить свои методы.
Конец 2010-х годов
Доминирующие жанры: коннективизм + символизм Архитектура: много облаков Доминирующие теории: нейронные сети памяти, массовая интеграция, основанные на знаниях рассуждения Простые вопросы и ответы: узкомасштабный обмен знаниями в определенных областях
2020-е +
Основные направления: коннективизм + символизм + Бейес + … Архитектура: облачные и туманные вычисления Доминирующая теория: есть сети, когда есть восприятие, есть правила, когда есть рассуждение и работа Простые восприятия, рассуждения и действия: ограниченная автоматизация или человеко-машинное взаимодействие
2040-е +
Главные жанры: слияние алгоритмов Архитектура: вездесущие серверы Доминирующая теория: оптимальное сочетание мета-обучения Ощущение и реакция: действие или ответ на знания или опыт, полученные с помощью различных методов обучения
- #### Третье: алгоритмы машинного обучения.

Какой алгоритм машинного обучения вам следует использовать? Это во многом зависит от характера и количества имеющихся данных, а также от ваших целей обучения в каждом конкретном случае. Не используйте самые сложные алгоритмы, если только их результат не стоит дорогостоящих затрат и ресурсов.
Дерево решений (Decision Tree): в процессе пошагового ответа типичный анализ дерева решений использует сложные переменные или узлы решений, например, можно классифицировать данного пользователя в качестве надежного или ненадежного.
Преимущества: умение оценивать различные характеристики, качества и свойства людей, мест и вещей Примеры сценариев: кредитная оценка на основе правил, прогнозирование результатов гонок
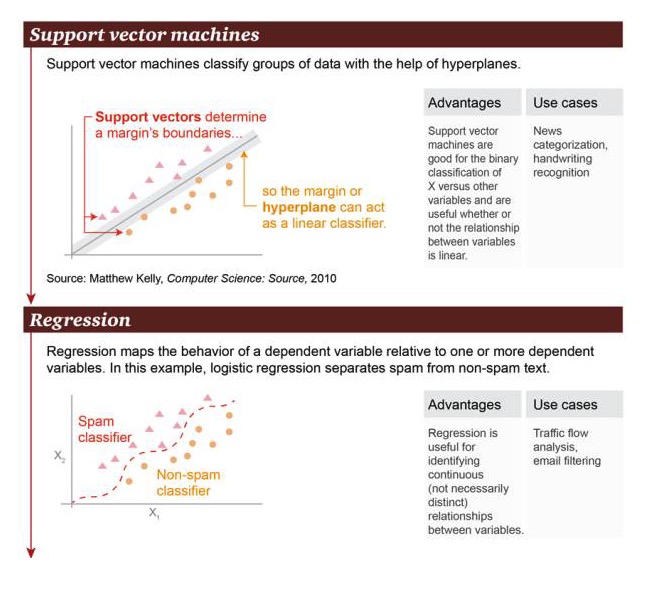
Поддерживающая векторная машина (Support Vector Machine): основанная на гиперплане (hyperplane), поддерживающая векторная машина позволяет классифицировать группы данных.
Преимущества: поддерживает векторные машины, умеющие выполнять двоичные классификационные операции между переменной X и другими переменными, независимо от того, является ли их связь линейной Примеры сценариев: классификация новостей, распознавание почерка.
Regression: Regression может выявить соотношение состояния между конечным переменным и одним или несколькими конечными переменными. В этом примере различают спам и неспам.
Преимущества: регрессия может быть использована для определения непрерывной связи между переменными, даже если эта связь не очень очевидна Примеры: анализ дорожного движения, фильтрация почты
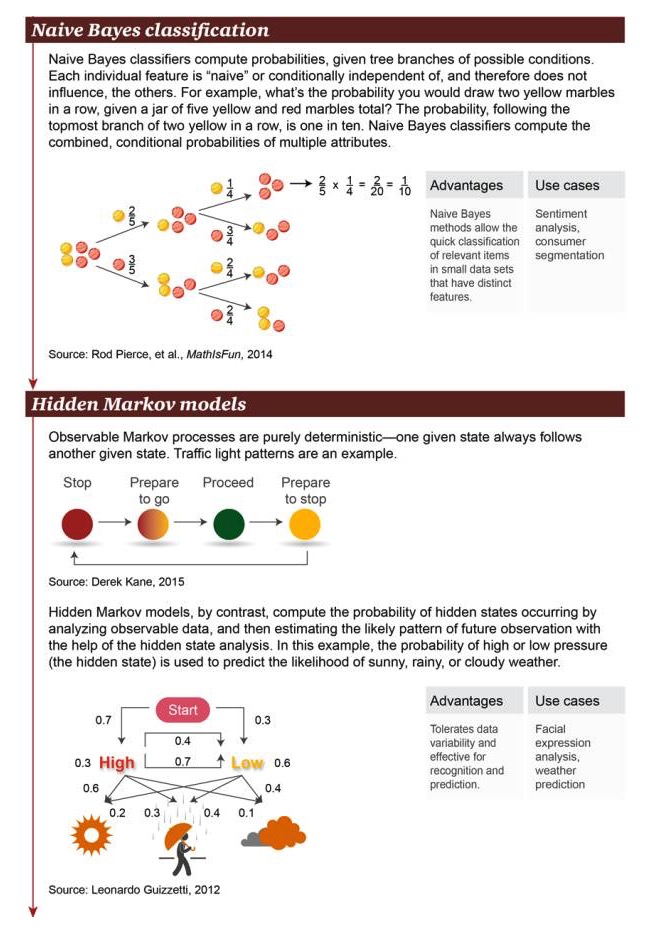
Наивная классификация Байеса: Наивная классификация Байеса используется для вычисления вероятности разделения возможных условий. Каждый отдельный признак является “наивным” или условно-независимым, поэтому они не влияют на другие объекты. Например, какова вероятность того, что в ящике, содержащем в общей сложности 5 желтых и красных шаров, будут пойманы два желтых шара подряд?
Преимущества: Простой бейесовский метод позволяет быстро классифицировать связанные объекты с заметными особенностями в небольших наборах данных Примеры: анализ эмоций, классификация потребителей
Скрытая марковская модель: явный марковский процесс - это абсолютная определенность того, что одно данное состояние часто сопровождается другим. Например, светофоры. Напротив, скрытая марковская модель рассчитывает возникновение скрытых состояний, анализируя видимые данные.
Преимущества: допускает изменчивость данных, применяется для распознавания и прогнозирования операций Примеры сценариев: анализ выражений лица, прогноз погоды
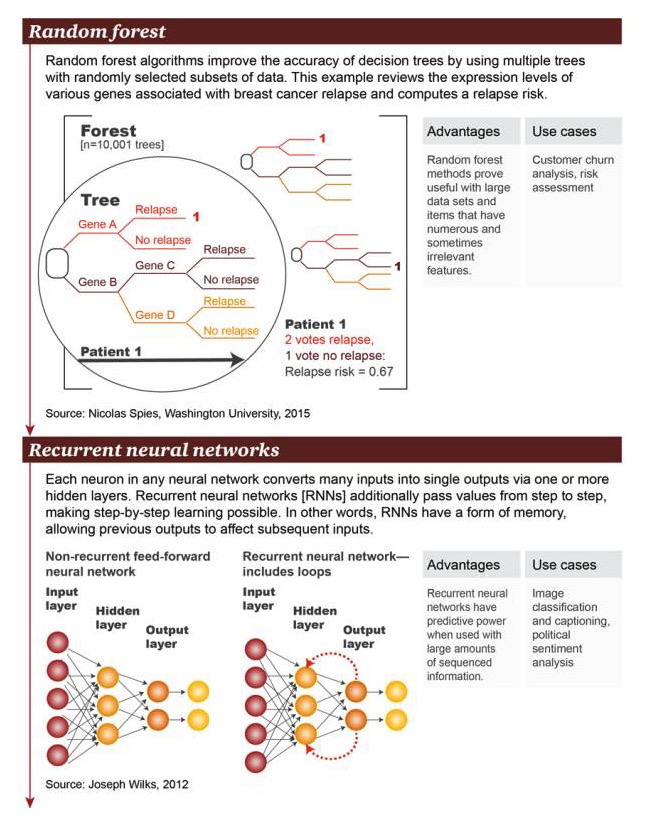
Случайный лес: алгоритм случайного леса улучшает точность дерева принятия решений с использованием нескольких деревьев с подмножеством случайных выбранных данных. В этом примере рассматривается большое количество генов, связанных с рецидивом рака молочной железы, на уровне генетического выражения и рассчитывается риск рецидива.
Преимущества: метод случайного леса доказал свою полезность для больших массивов данных и наличия большого количества иногда не связанных характеристик элементов Примеры сценариев: анализ потерь пользователей, оценка рисков
В произвольной нейронной сети каждый нейрон преобразует множество вводов в отдельные выводы через один или несколько скрытых слоев. Циркулирующая нейронная сеть (RNN) передает значения дальше по уровню, что позволяет изучать уровень по уровню. Другими словами, РНН имеют какую-то форму памяти, которая позволяет предыдущим вводам влиять на последующие.
Преимущества: циклическая нейронная сеть обладает предсказуемой способностью при наличии большого количества упорядоченной информации Примеры сценариев: классификация изображений с добавлением субтитров, анализ политических эмоций

Длительная кратковременная память (LSTM) и шлюзовые циклические нейронные сети (GRU): ранние формы RNN были потерянными. Хотя эти ранние шлюзовые нейронные сети позволяли хранить только небольшое количество ранней информации, более поздние LSTM и GRU имеют как долгосрочную, так и краткосрочную память. Другими словами, эти более поздние RNN обладают лучшей способностью контролировать память, позволяя сохранять более ранние значения или переставлять их, когда необходимо обрабатывать много последовательных шагов, что предотвращает окончательную деградацию значений, передаваемых по ступеньке “упадок” или поэтапной передаче.
Преимущества: долгосрочная краткосрочная память и нейронные сети с циркулирующими блоками управления дверью имеют те же преимущества, что и другие циркулирующие нейронные сети, но они используются чаще, потому что они обладают лучшей памятью Примеры сцен: обработка естественного языка, перевод
Конвульсионная нейронная сеть: конвульсия - это слияние весов из последующих слоев, которые могут быть использованы для маркировки выходной слоя.
Преимущества: Конвульсионные нейронные сети очень полезны при наличии очень больших наборов данных, большого количества характеристик и сложных классификационных задач Примеры: распознавание изображений, перевод текста, обнаружение лекарств.
- #### Ссылка на оригинальный текст:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Продолжение из Big Data