

В предыдущей статье было дано предварительное введение в методы расчета различных средних цен и дан пересмотр средней цены. В этой статье мы продолжаем углубляться в эту тему.
Требуемые данные
Данные о потоке ордеров и данные десяти уровней глубины собираются в ходе реальной торговли, а частота обновления составляет 100 мс. Реальный рынок содержит только данные о покупке и продаже, которые обновляются в режиме реального времени. Для простоты он пока не используется. Учитывая, что объем данных слишком велик, сохраняется только 100 000 строк подробных данных, а рыночные условия для каждого уровня также разделяются на отдельные столбцы.
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
python
tick_size = 0.0001
python
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
python
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
python
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
python
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
python
depths = depths.iloc[:100000]
python
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
python
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# 应用到每一行,得到新的df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# 在原有df上进行扩展
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
python
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
python
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
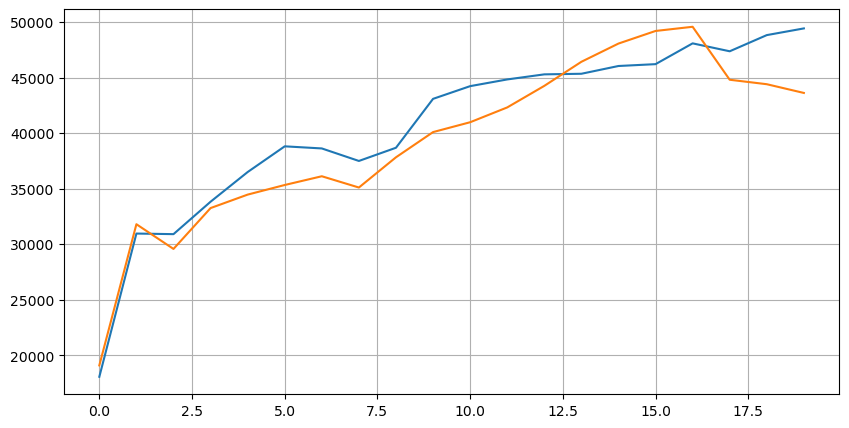
Давайте сначала посмотрим на распределение этих 20 рыночных условий. Оно соответствует ожиданиям. Чем дальше от открытия рынка, тем больше отложенных ордеров, а ордера на покупку и ордера на продажу примерно симметричны.
python
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Объедините данные о глубине и данные о транзакциях для облегчения оценки точности прогноза. Здесь мы гарантируем, что данные о транзакции будут позже, чем данные о глубине. Не принимая во внимание задержку, мы напрямую вычисляем среднеквадратичную ошибку между прогнозируемым значением и фактической ценой транзакции. Используется для измерения точности прогнозов.
Судя по результатам, ошибка mid_price, среднего значения пары покупка-продажа, самая большая. После изменения на weight_mid_price ошибка сразу становится намного меньше, и она еще больше улучшается путем корректировки взвешенной средней цены. После того, как вчерашняя статья была опубликована, некоторые люди сообщили, что они использовали только I^3/2. Я проверил это здесь и обнаружил, что результат был лучше. После размышлений о причине, это должно быть различие в частоте событий. Когда I близко к -1 и 1, это событие с низкой вероятностью. Для того, чтобы исправить эти низкие вероятности, прогнозирование событий с высокой частотой не так точен. Поэтому, чтобы более точно учесть высокочастотные события, я внес некоторые корректировки (это чисто экспериментальные параметры, и они не очень полезны для реальной торговли):
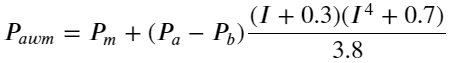
Результат оказался немного лучше. Как упоминалось в предыдущей статье, стратегии должны прогнозироваться с большим количеством данных. С большей глубиной и данными о выполнении заказов улучшение, которое может быть получено за счет запутывания с рыночной ценой, уже очень слабое.
python
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
python
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
python
print('平均值 mid_price的误差:', ((df['price']-df['mid_price'])**2).sum())
print('挂单量加权 mid_price的误差:', ((df['price']-df['weight_mid_price'])**2).sum())
print('调整后的 mid_price的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的 mid_price_2的误差:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('调整后的 mid_price_3的误差:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
平均值 mid_price的误差: 0.0048751924999999845
挂单量加权 mid_price的误差: 0.0048373440193987035
调整后的 mid_price的误差: 0.004803654771638586
调整后的 mid_price_2的误差: 0.004808216498329721
调整后的 mid_price_3的误差: 0.004794984755260528
调整后的 mid_price_4的误差: 0.0047909595497071375
Рассмотрим глубину второй передачи.
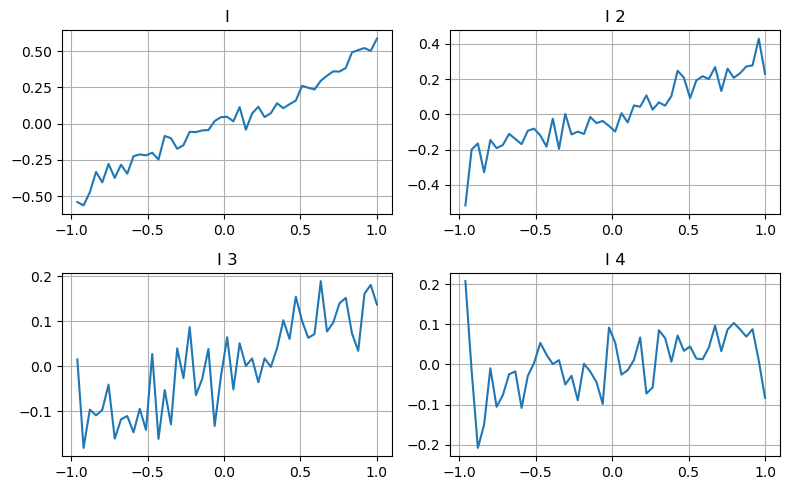
Здесь мы используем идею предыдущей статьи, чтобы изучить различные диапазоны значений определенного влияющего параметра и изменения цены сделки, чтобы измерить вклад этого параметра в среднюю цену. Как показано на графике глубины первого уровня, по мере увеличения I цена следующей транзакции с большей вероятностью изменится в положительную сторону, что означает, что I вносит положительный вклад.
Вторая партия была обработана таким же образом, и было обнаружено, что хотя эффект был немного меньше, чем у первой партии, он все равно был существенным. Третий уровень глубины также вносит небольшой вклад, но монотонность гораздо хуже, а более глубокие значения по сути не имеют никакой референтной ценности.
В соответствии с различными уровнями вклада, различные веса присваиваются параметрам дисбаланса трех уровней. Фактическая проверка показывает, что ошибки прогнозирования еще больше уменьшаются для различных методов расчета.
python
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
python
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
python
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('调整后的 mid_price_5的误差:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('调整后的 mid_price_6的误差:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('调整后的 mid_price_7的误差:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('调整后的 mid_price_8的误差:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
调整后的 mid_price_4的误差: 0.0047909595497071375
调整后的 mid_price_5的误差: 0.0047884350488318714
调整后的 mid_price_6的误差: 0.0047778319053133735
调整后的 mid_price_7的误差: 0.004773578540592192
调整后的 mid_price_8的误差: 0.004771415189297518
Рассмотрите данные транзакций
Данные о транзакциях напрямую отражают степень длинных и коротких позиций. В конце концов, это опцион, который подразумевает реальные деньги, а стоимость размещения ордера значительно ниже, и даже есть случаи преднамеренного мошенничества при размещении ордеров. Поэтому при прогнозировании средней цены стратегия должна ориентироваться на данные о транзакциях.
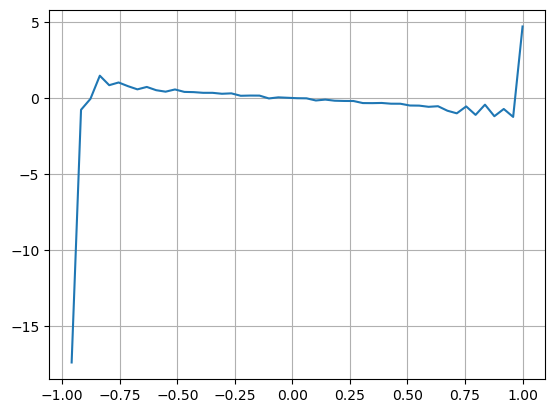
Учитывая форму, определите дисбаланс среднего количества поступивших заказов VI, Vb, Vs, представляющий среднее количество заказов на покупку и на продажу в рамках единичного события соответственно.
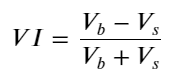
Результаты показывают, что количество прибывших товаров за короткий период времени является наиболее значимым для прогнозирования изменения цен. Когда VI находится в диапазоне (0,1-0,9), он отрицательно коррелирует с ценой, но за пределами диапазона он положительно коррелирует с цена. Это говорит о том, что когда рынок не экстремальный, он в основном характеризуется колебаниями, и цены вернутся к среднему значению. Когда возникают экстремальные рыночные условия, такие как большое количество ордеров на покупку, подавляющих ордера на продажу, тренд выйдет из тренда . Даже если мы проигнорируем эти маловероятные ситуации и просто предположим, что тренд и VI удовлетворяют отрицательной линейной зависимости, ошибка прогнозирования средней цены значительно уменьшится. Буква «а» в формуле представляет собой коэффициент.
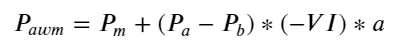
python
alpha=0.1
python
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
python
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
python
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
python
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
python
print('调整后的mid_price 的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的mid_price_9 的误差:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('调整后的mid_price_10的误差:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
调整后的mid_price 的误差: 0.0048373440193987035
调整后的mid_price_9 的误差: 0.004629586542840461
调整后的mid_price_10的误差: 0.004401790287167206
Полная медианная цена
Учитывая, что и отложенные ордера, и данные о транзакциях полезны для прогнозирования средней цены, эти два параметра можно объединить. Присвоение веса здесь произвольно и не учитывает граничные условия. В крайних случаях прогнозируемая средняя цена может быть Это не между покупкой и продажей, но если погрешность можно уменьшить, эти детали не имеют значения.
Наконец, ошибка прогноза снизилась с первоначальных 0,00487 до 0,0043. Мы не будем вдаваться в подробности. Еще многое предстоит изучить о средней цене. В конце концов, прогнозирование средней цены — это прогнозирование цены. Вы можете попробовать сами .
python
#注意VI需要延后一个使用
df['price_change'] = np.log(df['price']/df['price'].rolling(40).mean())
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3 + 150*df['price_change'].shift(1)
python
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('调整后的mid_price_11的误差:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
调整后的mid_price_11的误差: 0.00421125960463469
Подвести итог
В этой статье объединены данные глубины и данные транзакций для дальнейшего улучшения метода расчета средней цены. В этой статье представлен метод измерения точности и повышения точности прогнозов изменения цен. В целом, различные параметры не являются очень строгими и приведены только для справки. При более точной средней цене следующим шагом будет фактическое применение средней цены для бэктестинга. В этой части также много контента, поэтому мы на некоторое время прекратим обновления.


