

Факторная модельная структура
Существует множество исследовательских отчетов по многофакторной модели фондового рынка с богатой теорией и практикой. Рынок цифровых валют достаточен для факторного исследования с точки зрения количества валют, общей рыночной стоимости, объема транзакций и рынка деривативов. Эта статья в основном предназначена для новичков в количественных стратегиях и не будет включать сложные математические принципы и статистический анализ. Принимая во внимание Используя фьючерсный рынок в качестве источника данных, создается простая структура факторного исследования, облегчающая оценку факторных показателей.
Фактор можно рассматривать как индикатор и можно записать как выражение. Факторы постоянно меняются и отражают будущую информацию о доходности. Обычно факторы представляют собой инвестиционную логику.
Например, фактор цены закрытия основан на предположении, что цены акций могут предсказывать будущие доходы. Чем выше цена акций, тем выше будущие доходы (или ниже доходы). Формирование портфеля на основе этого фактора фактически является инвестицией модель/стратегия регулярной ротации позиций для покупки дорогостоящих акций. Вообще говоря, факторы, которые могут стабильно генерировать избыточную доходность, часто называют Альфа. Например, академические круги и инвестиционное сообщество подтвердили эффективность факторов рыночной капитализации и факторов импульса.
Будь то фондовый рынок или рынок цифровой валюты, это сложная система. Ни один фактор не может полностью предсказать будущую доходность, но он все равно имеет определенную степень предсказуемости. Эффективная альфа (инвестиционная модель) постепенно становится неэффективной по мере инвестирования большего количества средств. Но этот процесс приведет к появлению на рынке других моделей, что приведет к появлению новых альфа-версий. Фактор рыночной капитализации когда-то был очень эффективной стратегией на рынке акций класса А. Просто купите 10 акций с самой низкой рыночной капитализацией и корректируйте их раз в день. Десятилетний бэктест с 2007 года принесет более чем 400-кратную прибыль, намного превышающий общий рынок. Однако рынок акций «голубых фишек» в 2017 году отразил неэффективность фактора малой рыночной капитализации, в то время как вместо него стал популярен фактор стоимости. Поэтому необходимо постоянно балансировать и экспериментировать между проверкой и использованием альфы.
Факторы, которые мы ищем, являются основой для разработки стратегий. Лучшие стратегии могут быть созданы путем объединения нескольких не связанных между собой эффективных факторов.
python
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
Источник данных
На данный момент почасовые данные K-line бессрочных фьючерсов Binance USDT с начала 2022 года по настоящее время превысили 150 валют. Как упоминалось ранее, факторная модель — это модель выбора валют, которая ориентирована на все валюты, а не только на определенную валюту. Данные K-line включают в себя такие данные, как высокие цены открытия и низкие цены закрытия, объем торгов, количество транзакций, объем активных покупок и т. д. Эти данные, безусловно, не являются источником всех факторов, таких как индекс акций США, ожидания повышения процентных ставок. , прибыльность, данные о блокчейне, внимание социальных сетей и т. д. Менее популярные источники данных также могут раскрыть эффективный показатель альфа, однако базовых данных по объему и ценам также достаточно.
python
## 当前交易对
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
Out:
python
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
python
print(len(symbols))
Out:
153
python
#获取任意周期K线的函数
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
python
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
python
symbols = list(df_dict.keys())
print(df_s.columns)
Out:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
Сначала мы извлекаем интересующие нас данные из данных K-line: цену закрытия, цену открытия, объем торгов, количество транзакций и коэффициент активных покупок, а затем используем эти данные в качестве основы для обработки требуемых факторов.
python
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
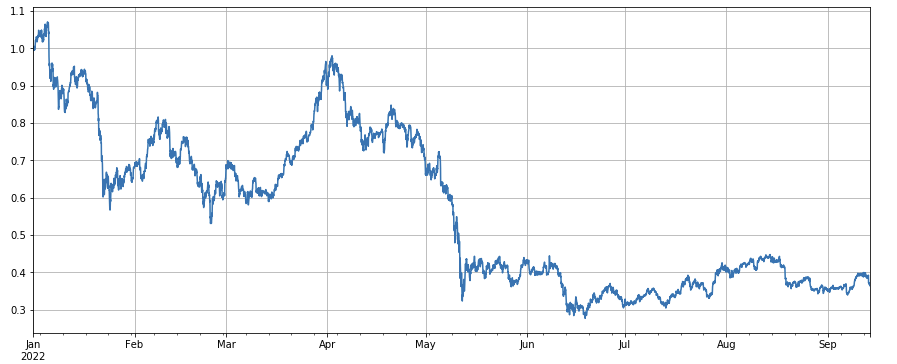
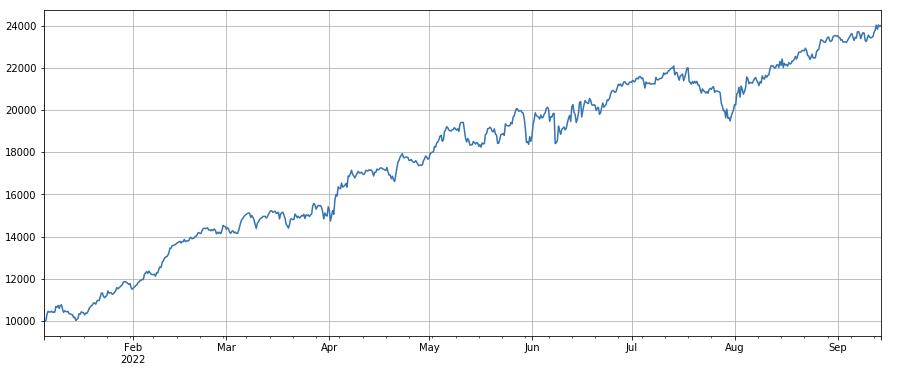
Если взглянуть на динамику рыночного индекса, то можно сказать, что она весьма неутешительна: с начала года падение составило 60%.
python
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #归一化
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#最终指数收益图
Определение валидности фактора
-
Метод регрессии
В качестве зависимой переменной берется норма доходности следующего периода, в качестве независимой переменной берется проверяемый фактор, а коэффициент, полученный в результате регрессии, является нормой доходности фактора. После построения уравнения регрессии мы обычно ссылаемся на абсолютное среднее значение коэффициента t, долю последовательности абсолютных значений коэффициента t, большую 2, годовую доходность фактора, волатильность годовой доходности фактора, коэффициент Шарпа доходность фактора и другие параметры. Эффективность фактора и волатильность. Вы можете регрессировать несколько факторов одновременно, подробности см. в документации barra. -
IC, IR и другие индикаторы
Так называемый IC — это коэффициент корреляции между фактором и доходностью следующего периода. Сейчас обычно используется RANK_IC, который представляет собой коэффициент корреляции между рейтингом фактора и доходностью акций следующего периода. IR обычно представляет собой среднее значение последовательности IC/стандартное отклонение последовательности IC. -
Иерархическая регрессия
В этой статье будет использоваться этот метод, который заключается в сортировке факторов для тестирования, разделении валют на N групп для группового бэктестинга и использовании фиксированного периода для корректировки позиций. Если ситуация идеальна, то доходности N групп валют будут демонстрировать хорошую монотонность, монотонно увеличиваясь или уменьшаясь, а разрыв в доходности между каждой группой будет большим. Такие факторы отражаются в лучшей дискриминации. Если у первой группы самая высокая доходность, а у последней группы самая низкая, то открывайте длинную позицию по первой группе и короткую по последней. Окончательная норма доходности является справочным показателем коэффициента Шарпа.
Фактическая операция обратного тестирования
По факторам выбранные валюты делятся на 3 группы по сортировке от меньшего к большему. Каждая группа валют составляет около 1/3. Если фактор эффективен, то чем меньше доля каждой группы, тем выше доходность, но это также означает, что средства, выделенные для каждой валюты, относительно велики. Если длинные и короткие позиции имеют кредитное плечо 1x, а первая и последняя группы состоят из 10 валют соответственно, то каждая составляет 10%. Если валюта, которая короткие продажи растут, если объем инвестиций увеличивается в 2 раза, откат составит 20%; соответственно, если количество групп равно 50, откат составит 4%. Диверсификация валют может снизить риск возникновения «черных лебедей». Открывайте длинную позицию по первой группе (с наименьшим значением фактора) и короткую — по третьей группе. Если чем больше фактор, тем выше доходность, вы можете поменять местами длинные и короткие позиции или просто сделать фактор отрицательным или обратным.
Прогностическую силу фактора обычно можно приблизительно оценить на основе окончательной доходности бэктеста и коэффициента Шарпа. Кроме того, необходимо также указать, является ли выражение фактора простым, нечувствительным к размеру группировки, нечувствительным к интервалу корректировки позиции, нечувствительным к начальному времени бэк-теста и т. д.
Что касается частоты корректировки позиций, то на фондовом рынке чаще всего наблюдается цикл в 5 дней, 10 дней и один месяц, однако для рынка цифровых валют такой цикл, несомненно, слишком длинный, а рыночные условия на реальном рынке отслеживаются в в реальном времени, поэтому сложно придерживаться определенного цикла. Нет необходимости снова корректировать позиции, поэтому в реальной торговле мы корректируем позиции в реальном времени или в короткие периоды времени.
Что касается способа закрытия позиции, то согласно традиционному методу, вы можете закрыть позицию, если она не находится в группе при следующей сортировке. Однако в случае корректировки позиций в реальном времени некоторые валюты могут находиться на разделительной линии, и позиции могут закрываться туда и обратно. Поэтому эта стратегия принимает подход ожидания групповых изменений и закрытия позиций, когда необходимо открыть позиции в противоположном направлении. Например, если вы идете в лонг в первой группе, когда валюта в длинной позиции делится на третья группа, вы можете закрыть позицию и открыть короткую позицию. Если вы закрываете позиции через фиксированный период времени, например, каждый день или каждые 8 часов, вы также можете закрывать позиции, не вступая в группу. Вы можете попробовать еще.
python
#回测引擎
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #初始的资产
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #扣除手续费
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #先平仓
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #利润
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #对资产进行更新
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#测试因子的函数
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
Простой факторный тест
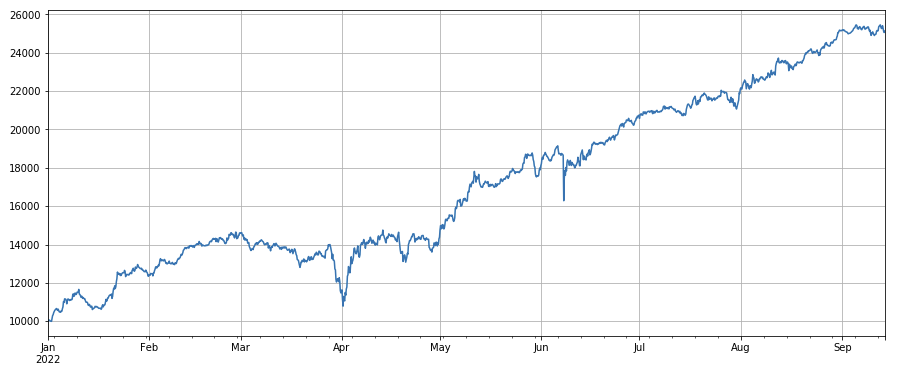
Фактор объема: простая длинная позиция по монетам с низким объемом и короткая позиция по монетам с высоким объемом дает очень хорошие результаты, что показывает, что популярные монеты с большей вероятностью упадут.
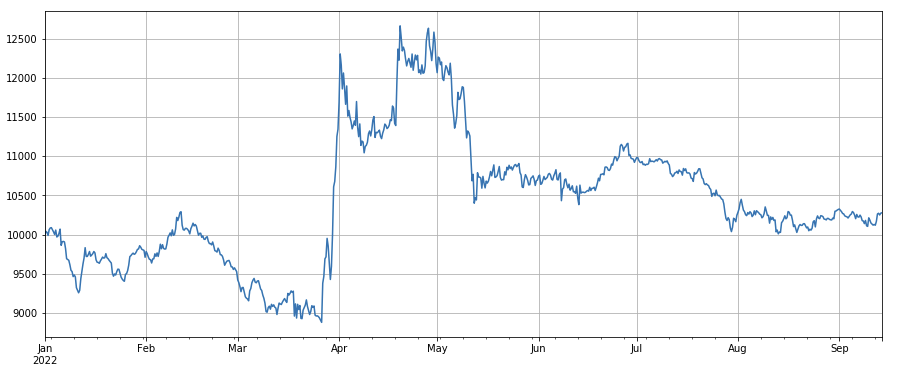
Фактор цены транзакции: длинные позиции по дешевым валютам, короткие позиции по дорогим валютам, эффект средний.
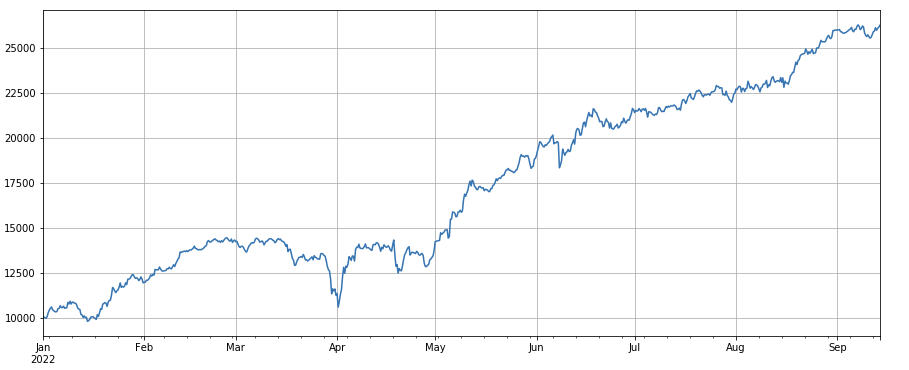
Фактор количества транзакций: производительность очень похожа на объем. Очевидно, что корреляция между фактором объема и фактором количества транзакций очень высока. Фактически, средняя корреляция между различными валютами составляет 0,97, что показывает, что эти два фактора очень похожи. Этот фактор необходимо учитывать .
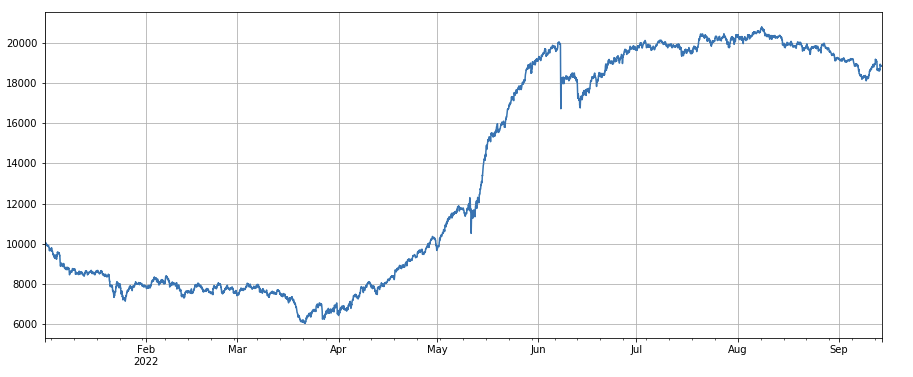
Фактор импульса 3h: (df_close - df_close.shift(3))/df_close.shift(3). То есть, 3-часовой рост фактора. Результаты бэктеста показывают, что 3-часовой рост имеет очевидную регрессионную характеристику, то есть, рост с большей вероятностью снизится в следующем периоде. Общая динамика хорошая, но наблюдаются также более длительные периоды отката и колебаний.
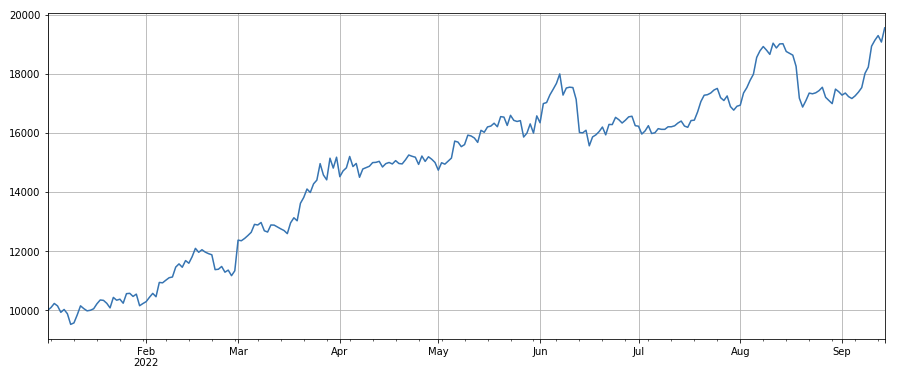
Фактор 24-часового импульса: результаты 24-часового цикла ребалансировки довольно хороши, доходность аналогична 3-часовому импульсу, а просадка меньше.
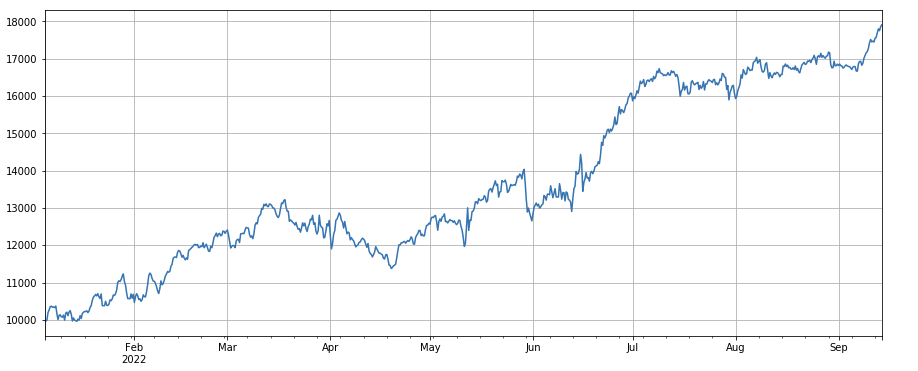
Фактор изменения оборота: df_volume.rolling(24).mean() / df_volume.rolling(96).mean(), который является отношением оборота последнего дня к обороту последних трех дней. Позиция корректируется каждые 8 часов. Результаты бэктестинга относительно неплохие, а откат относительно низкий, что показывает, что акции с активным объемом торговли с большей вероятностью упадут.
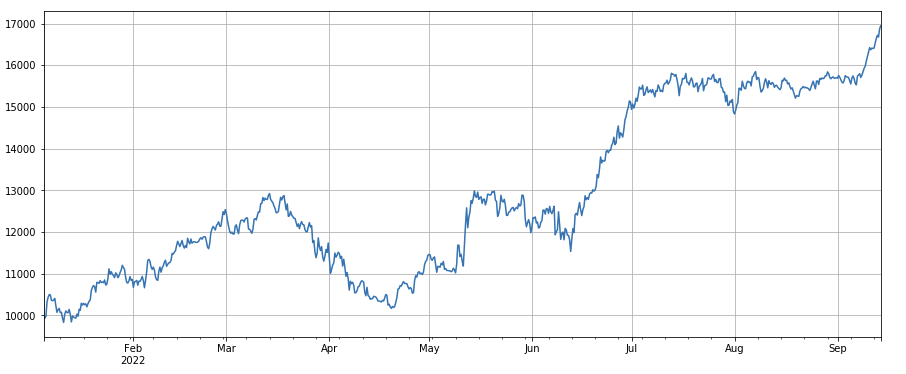
Коэффициент изменения количества транзакций: df_count.rolling(24).mean() / df_count.rolling(96).mean(), который представляет собой отношение количества транзакций за последний день к количеству транзакций за последние три дня. . Положение корректируется каждые 8 часов. Результаты бэктестинга относительно неплохие, а откат относительно низкий, что показывает, что по мере увеличения количества транзакций рынок имеет тенденцию к более активному падению.
Фактор изменения стоимости отдельной транзакции:
-(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
, представляющий собой отношение стоимости транзакции за последний день к стоимости транзакции за последние три дня, при этом позиция корректируется каждые 8 часов. Этот фактор также тесно связан с фактором объема.
Коэффициент изменения коэффициента активных транзакций: df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean(), то есть отношение активного объема покупки к общему объему транзакций за последний день до транзакции значение за последние три дня, корректируйте положение каждые 8 часов. Этот фактор работает хорошо и имеет слабую корреляцию с фактором объема.
Фактор волатильности: (df_close/df_open).rolling(24).std(), который оказывает определенное влияние при открытии длинных позиций по валютам с низкой волатильностью.
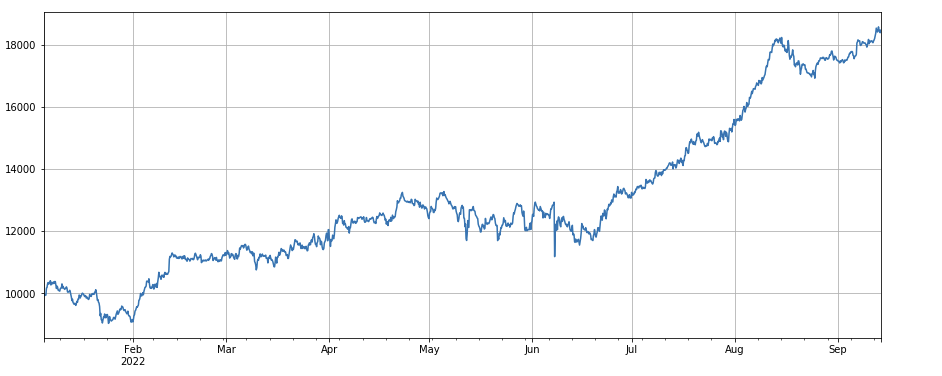
Коэффициент корреляции между объемом торгов и ценой закрытия: df_close.rolling(96).corr(df_volume), коэффициент корреляции между ценой закрытия и объемом торгов за последние 4 дня, общая эффективность хорошая.
Здесь перечислены лишь некоторые факторы, основанные на количестве и цене. На самом деле, комбинация формул факторов может быть очень сложной и не иметь очевидной логики. Вы можете обратиться к известному методу построения фактора ALPHA101: https://github.com/STHSF/alpha101.
python
#成交量
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
python
#成交价
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
python
#成交笔数
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
python
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
python
#3小时动量因子
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
python
#24小时动量因子
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
python
#成交量因子
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
python
#成交笔数因子
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
python
#因子相关性
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
python
#单笔成交价值因子
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
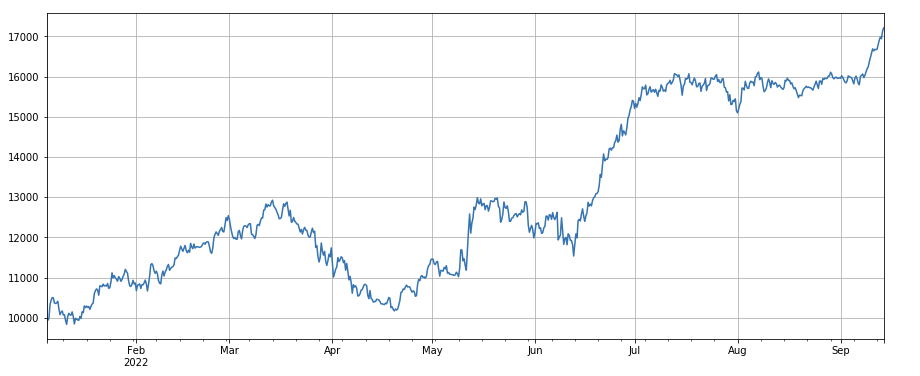
python
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
python
#主动成交比例因子
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
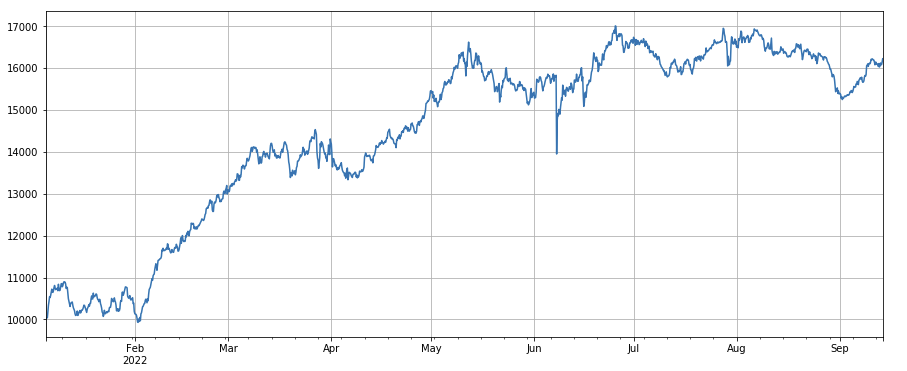
python
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
python
#波动率因子
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
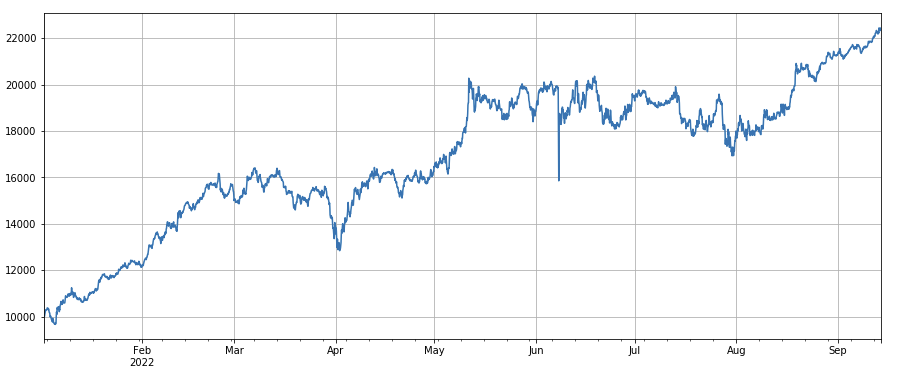
python
#成交量和收盘价相关性因子
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
Многофакторный синтез
Постоянное обнаружение новых эффективных факторов, безусловно, является важнейшей частью процесса построения стратегии, но без хорошего метода синтеза факторов отличный отдельный фактор Альфа не сможет сыграть свою максимальную роль. К распространенным методам многофакторного синтеза относятся:
Метод равного веса: все факторы, которые необходимо синтезировать, добавляются с равным весом для получения новых синтезированных факторов.
Метод взвешенных исторических доходностей факторов: все факторы, которые необходимо синтезировать, складываются в соответствии со средним арифметическим исторических доходностей факторов за последний период в качестве весов для получения новых синтезированных факторов. Этот метод придает более высокий вес факторам, которые работают хорошо.
Метод взвешивания IC_IR: среднее значение IC составного фактора за определенный период времени используется в качестве оценки значения IC составного фактора в следующем периоде, а ковариационная матрица исторического значения IC используется в качестве оценки. волатильности составного фактора в следующем периоде. Он равен ожидаемому значению IC, деленному на стандартное отклонение IC, и можно получить оптимальное весовое решение для максимизации составного фактора IC_IR.
Метод анализа главных компонент (PCA): PCA — это широко используемый метод для снижения размерности данных. Корреляция между факторами может быть относительно высокой, и главные компоненты после снижения размерности используются в качестве синтезированных факторов.
В этой статье мы будем вручную ссылаться на весовые коэффициенты валидности факторов. Описанный выше метод может относиться к:ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
При тестировании одного фактора порядок фиксирован, но многофакторный синтез требует объединения совершенно разных данных, поэтому все факторы должны быть стандартизированы, а экстремальные значения и пропущенные значения, как правило, должны быть удалены. Здесь мы используем df_volume\factor_1\factor_7\factor_6\factor_8 для синтеза.
python
#标准化函数,去除缺失值和极值,并且进行标准化处理
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
python
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
Подвести итог
В этой статье представлен метод однофакторного теста и тестируются общие однофакторные факторы, а также предварительно представлен метод многофакторного синтеза. Однако содержание многофакторного исследования очень богато. Каждый пункт, упомянутый в статье, может быть расширен в глубину . Это осуществимый подход для преобразования такого стратегического исследования в открытие альфа-факторов. Использование факторной методологии может значительно ускорить проверку торговых идей, и для этого доступно много справочных материалов.
Настоящий адрес: https://www.fmz.com/robot/486605










- 1