
مشین لرننگ کے تین بڑے زمروں اور چھ بڑے الگورتھم کے فوائد اور نقصانات کی مکمل وضاحت
مشین لرننگ میں ، ہدف یا تو پیش گوئی (پریڈکشن) یا کلسٹرنگ (کلسٹرنگ) ہے۔ اس مضمون کی توجہ پیش گوئی پر مرکوز ہے۔ پیش گوئی اس عمل کی ہے جس میں ہم ان پٹ متغیرات کے ایک سیٹ سے آؤٹ پٹ متغیرات کی قدر کی پیش گوئی کرتے ہیں۔ مثال کے طور پر ، گھر کے بارے میں خصوصیات کا ایک سیٹ ملنے پر ، ہم اس کی فروخت کی قیمت کی پیش گوئی کرسکتے ہیں۔ پیش گوئی کے سوالات کو دو بڑی اقسام میں تقسیم کیا جاسکتا ہے: 1 ، رجعت کے سوالات: جن میں متغیرات کی پیش گوئی کی جائے گی وہ عددی ہیں (جیسے مکان کی قیمت) ؛ 2 ، درجہ بندی کے سوالات: جن میں متغیرات کی پیش گوئی کی جائے گی وہ ہاں / نہیں کے جوابات ہیں (جیسے یہ پیش گوئی کی جائے گی کہ آیا کوئی آلہ خراب ہوجائے گا)
اس کے بعد ، آئیے مشین لرننگ میں سب سے نمایاں اور سب سے زیادہ استعمال ہونے والے الگورتھم پر ایک نظر ڈالیں۔ ہم ان الگورتھم کو تین اقسام میں تقسیم کرتے ہیں: لکیری ماڈل ، درخت پر مبنی ماڈل ، اور نیورل نیٹ ورکس۔
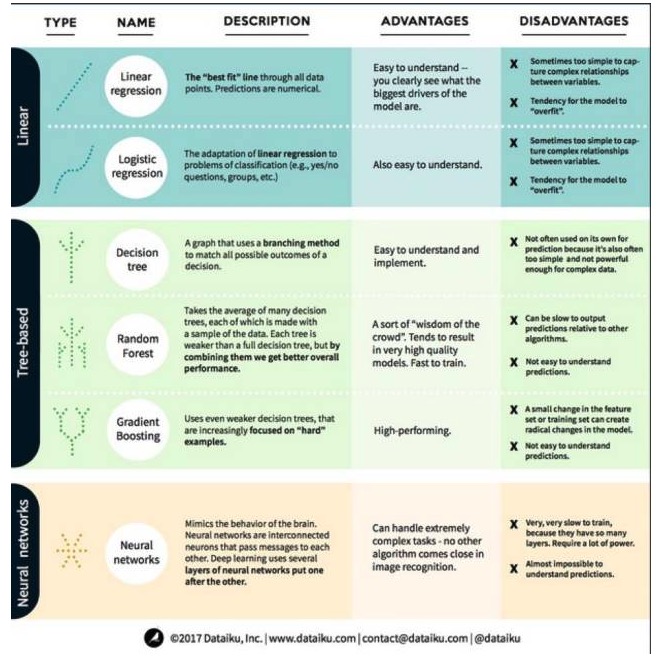
ایک ، لکیری ماڈل الگورتھم: لکیری ماڈل ایک سادہ فارمولے کا استعمال کرتے ہوئے اعداد و شمار کے ایک سیٹ کے ذریعے بہترین فٹ فٹ لائنوں کو تلاش کرتا ہے۔ یہ طریقہ 200 سال سے زیادہ پرانا ہے اور اعدادوشمار اور مشین لرننگ کے شعبوں میں وسیع پیمانے پر استعمال کیا جاتا ہے۔ اس کی سادگی کی وجہ سے ، یہ اعدادوشمار کے لئے مفید ہے۔ متغیر جو آپ پیش گوئی کرنا چاہتے ہیں ((متغیر کی وجہ سے) آپ کو پہلے سے معلوم متغیر کے مساوات کے طور پر ظاہر کیا گیا ہے (متغیر سے) ، لہذا پیش گوئی کرنا صرف متغیر سے ان پٹ کی بات ہے ، اور پھر اس مساوات کے جوابات کا حساب کتاب کریں۔
-
1. لکیری رجعت
لکیری رجعت ، یا اس سے زیادہ درست طور پر کہا جاتا ہے کہ کم سے کم دوگنا رجعت ، لکیری ماڈل کی سب سے معیاری شکل ہے۔ رجعت کے مسئلے کے لئے ، لکیری رجعت سب سے آسان لکیری ماڈل ہے۔ اس کا نقصان یہ ہے کہ ماڈل آسانی سے زیادہ فٹ بیٹھتا ہے ، یعنی ، ماڈل نئے اعداد و شمار کو فروغ دینے کی صلاحیت کی قربانی میں تربیت یافتہ اعداد و شمار کو مکمل طور پر اپناتا ہے۔ لہذا ، مشین لرننگ میں لکیری رجعت (اور اس کے ساتھ ساتھ ہم اس کے بارے میں بات کریں گے) عام طور پر مثالی ہے ، جس کا مطلب یہ ہے کہ ماڈل کو حد سے زیادہ فٹ ہونے سے روکنے کے لئے کچھ سزا دی جاتی ہے۔
لکیری ماڈل کا ایک اور نقصان یہ ہے کہ چونکہ وہ بہت آسان ہیں ، لہذا جب ان پٹ متغیرات آزاد نہیں ہوتے ہیں تو وہ زیادہ پیچیدہ طرز عمل کی آسانی سے پیش گوئی نہیں کرسکتے ہیں۔
-
منطقی رجعت 2.
منطقی رجعت لکیری رجعت کا درجہ بندی کے مسئلے کے لئے ایک موافقت ہے۔ منطقی رجعت کے نقصانات لکیری رجعت کے ساتھ ملتے ہیں۔ منطقی افعال درجہ بندی کے مسئلے کے لئے بہت اچھے ہیں کیونکہ اس نے ایک حد کا اثر متعارف کرایا ہے۔
2، درخت ماڈل الگورتھم
-
1، فیصلہ درخت
فیصلہ درخت ایک ایسا گراف ہے جو فیصلہ کے ہر ممکنہ نتائج کو ظاہر کرتا ہے۔ مثال کے طور پر ، اگر آپ نے سلاد کا آرڈر دینے کا فیصلہ کیا ہے تو ، آپ کا پہلا فیصلہ ممکنہ طور پر سبزیوں کی قسم ہے ، پھر اس کے بعد ، اور پھر سلاد کی قسم۔ ہم فیصلہ کے درخت میں تمام ممکنہ نتائج ظاہر کرسکتے ہیں۔
فیصلے کے درختوں کو تربیت دینے کے لئے ، ہمیں تربیت دینے والے ڈیٹا سیٹ کا استعمال کرنے کی ضرورت ہے اور یہ معلوم کرنے کی ضرورت ہے کہ ہدف کے لئے کون سی خاصیت سب سے زیادہ مفید ہے۔ مثال کے طور پر ، فراڈ کا پتہ لگانے کے استعمال کے معاملات میں ، ہم یہ معلوم کرسکتے ہیں کہ ملک کا سب سے زیادہ اثر انداز ہونے والے فراڈ کے خطرے کی پیشن گوئی ہے۔ پہلی خصوصیت کے ساتھ شاخوں کے بعد ، ہمیں دو ذیلی سیٹ ملتے ہیں ، جو اس بات کا یقین کرنے کے لئے کہ اگر ہم صرف پہلی خصوصیت کو جانتے تو سب سے زیادہ درست پیش گوئی کرسکتے ہیں۔ اس کے بعد ، ہم دوسری اچھی خصوصیت تلاش کرتے ہیں جو ان دونوں ذیلی سیٹوں کے ساتھ شاخوں کے لئے استعمال ہوسکتی ہے ، پھر دوبارہ تقسیم کریں ، اور اس طرح بار بار ، جب تک کہ کافی تعداد میں خصوصیات کا استعمال کرکے ہدف کی ضروریات کو پورا نہ کیا جاسکے۔
-
2، بے ترتیب جنگل
ایک بے ترتیب جنگل بہت سے فیصلے کے درختوں کا اوسط ہوتا ہے ، جس میں ہر فیصلے کا درخت بے ترتیب اعداد و شمار کے نمونے کے ساتھ تربیت یافتہ ہوتا ہے۔ بے ترتیب جنگل میں ہر درخت ایک مکمل فیصلے کے درخت سے کمزور ہوتا ہے ، لیکن تمام درختوں کو ایک ساتھ ڈال کر ، ہم تنوع کے فوائد کی وجہ سے مجموعی طور پر بہتر کارکردگی حاصل کرسکتے ہیں۔
بے ترتیب جنگل آج کل مشین لرننگ میں ایک بہت مقبول الگورتھم ہے۔ بے ترتیب جنگل کی تربیت کرنا آسان ہے اور اس کی کارکردگی کافی اچھی ہے۔ اس کا نقصان یہ ہے کہ دوسرے الگورتھم کے مقابلے میں ، بے ترتیب جنگل کی آؤٹ پٹ کی پیش گوئی سست ہوسکتی ہے ، لہذا جب فوری پیش گوئی کی ضرورت ہو تو ، بے ترتیب جنگل کا انتخاب نہیں کیا جاسکتا ہے۔
-
3، درجے میں اضافہ
gradientBoosting (GradientBoosting) ، رینڈم جنگلوں کی طرح ، بھی پُرجوش اور کمزور فیصلے کے درختوں پر مشتمل ہے۔ gradientBoosting اور رینڈم جنگلوں کے درمیان سب سے بڑا فرق یہ ہے کہ gradientBoosting میں ، درختوں کو ایک کے بعد ایک تربیت دی جاتی ہے۔ ہر پچھلے درخت کو بنیادی طور پر پچھلے درخت کے غلط اعداد و شمار کی نشاندہی کرنے کی تربیت دی جاتی ہے۔ اس سے gradientBoosting کو آسان پیش گوئی پر کم توجہ دی جاتی ہے ، اور مشکل حالات پر زیادہ۔
اس کے علاوہ، یہ بہت تیزی سے اور بہت اچھی کارکردگی کے ساتھ تربیت دی جاتی ہے. تاہم، تربیت کے اعداد و شمار میں چھوٹے تبدیلیوں کو بنیادی طور پر ماڈل کو تبدیل کر سکتا ہے، لہذا اس کے نتیجے میں ممکنہ طور پر سب سے زیادہ قابل عمل نہیں ہوسکتا.
نیورل نیٹ ورک الگورتھم: نیورل نیٹ ورک ایک حیاتیاتی رجحان ہے جس میں دماغ میں ایک دوسرے کے ساتھ معلومات کا تبادلہ کرنے والے ایک دوسرے کے ساتھ منسلک نیورونز پر مشتمل ہوتا ہے۔ اس خیال کو اب مشین لرننگ کے شعبے میں لاگو کیا گیا ہے ، جسے اے این این (مصنوعی نیورون نیٹ ورک) کہا جاتا ہے۔ گہری سیکھنے میں ایک دوسرے پر مشتمل ایک کثیر پرت نیورون نیٹ ورک ہوتا ہے۔ اے این این سیکھنے کے ذریعہ انسانی دماغ کی طرح کی علمی صلاحیتوں کو حاصل کرنے کا ایک سلسلہ ہے۔ ماڈل بہت پیچیدہ کاموں کو سنبھالنے میں بہت اچھا کارکردگی کا مظاہرہ کرتے ہیں ، جیسے امیج کی شناخت۔ لیکن ، جیسے ہی انسانی دماغ ، ماڈل کی تربیت بہت وقت طلب ہے اور بہت زیادہ توانائی کی ضرورت ہے۔
ٹویٹ ایمبیڈ کریں
- 1