الفاگو کا ہتھیار: مونٹی کارلو الگورتھم، آپ اسے پڑھنے کے بعد سمجھ جائیں گے! (کوڈ مثال کے ساتھ) - دوبارہ پرنٹ کریں۔
 0
23883
0
23883
الفا ڈاگ کی ہوشیاری: مونٹی کارلو الگورتھم ، ایک بار پڑھ کر سمجھ جائیں!
اس سال 9 سے 15 مارچ تک ، گوکی کی دنیا میں ایک اہم واقعہ ہوا ، جس میں جنوبی کوریا کے شہر سیئول میں پانچ راؤنڈ کی انسانی اور مشین جنگ کا انعقاد کیا گیا۔ اس میچ کے نتیجے میں انسانوں کو شکست ہوئی۔ عالمی گو چیمپئن لی شی شی نے گوگل کمپنی کے مصنوعی ذہانت پروگرام الفا گو کو 1-4 سے شکست دی۔ تو ، الفاگو کیا ہے اور اس میں جیت کی کلید کیا ہے؟ یہاں ہم ایک الگورتھم کے بارے میں بات کرنے جارہے ہیں: مونٹی کارلو الگورتھم
- ### AlphaGo اور مونٹی کارلو الگورتھم
چین کے ایک اخبار کے مطابق ، “الفا گو” ایک ایسا گوو پروگرام ہے جو گوو کے لئے تیار کیا گیا ہے اور اسے چینی شائقین نے “الفا کتے” کے نام سے پکارا ہے۔
پچھلے مضمون میں ہم نے Google کے نیورل نیٹ ورک کے بارے میں بات کی تھی جو خود کار طریقے سے سیکھنے والی مشینوں کے لئے تیار کیا جا رہا ہے، اور AlphaGo بھی اسی طرح کی ایک مصنوعات ہے.
چائنا آٹومیشن ایسوسی ایشن کے ڈپٹی چیئرمین اور سیکرٹری جنرل وانگ فائی یو نے کہا کہ پروگرامرز کو گو کی مہارت حاصل کرنے کی ضرورت نہیں ہے ، صرف گو کے بنیادی اصولوں کو جاننے کی ضرورت ہے۔ الفاگو کے پیچھے ایک ممتاز کمپیوٹر سائنسدانوں کا ایک گروپ ہے ، جو مشین لرننگ کے شعبے میں ماہر ہیں۔ سائنسدانوں نے نیورل نیٹ ورک کے الگورتھم کا استعمال کرتے ہوئے ، شطرنج کے ماہرین کے میچ ریکارڈ کو کمپیوٹر میں داخل کیا ، اور کمپیوٹر کو خود سے مقابلہ کرنے دیا ، اس عمل میں مسلسل سیکھنے کی تربیت کی۔ ایک طرح سے یہ کہا جاسکتا ہے کہ الفاگو کی شطرنج کی مہارت اسے ڈویلپر نے نہیں سکھائی ، بلکہ خود سیکھنے والی مہارت ہے۔
تو ، اس کے لئے کون سی کلید ہے کہ الفاگو خود سیکھنے کے لئے تیار ہے؟ یہ مونٹی کارلو الگورتھم ہے۔
مونٹی کارلو الگورتھم کیا ہے؟ مونٹی کارلو الگورتھم کی وضاحت کے لیے ہم عام طور پر استعمال کرتے ہیں: اگر ایک ٹوکری میں ایک ہزار سیب ہوں اور آپ اپنی آنکھیں بند کر کے ہر بار سب سے بڑا سیب تلاش کریں تو آپ کو اس بات کی کوئی پابندی نہیں ہوگی کہ آپ کتنی بار منتخب کرسکتے ہیں۔ اس طرح آپ آنکھیں بند کر کے ایک کو بے ترتیب طور پر لے سکتے ہیں اور پھر ایک کو بے ترتیب طور پر پہلے والے کے ساتھ موازنہ کرسکتے ہیں اور پھر ایک بڑا اور پھر ایک اور بے ترتیب طور پر لے سکتے ہیں اور پھر پچھلے والے کے ساتھ موازنہ کرسکتے ہیں اور پھر ایک بڑا۔ یہ سائیکل بار بار چلتا رہتا ہے، اور جتنی بار آپ سب سے بڑا سیب چنتے ہیں اس کا امکان اتنا ہی زیادہ ہوتا ہے، لیکن جب تک آپ ایک ہزار سیبوں میں سے ہر ایک کو منتخب نہیں کرتے، آپ اس بات کا یقین نہیں کر سکتے کہ آخر میں سب سے بڑا کون سا ہے۔
اس کا مطلب یہ ہے کہ مونٹی کارلو الگورتھم یہ ہے کہ جتنے زیادہ نمونے ہوں گے ، اتنا ہی بہتر حل مل جائے گا ، لیکن اس بات کی ضمانت نہیں ہے کہ یہ سب سے بہتر ہے ، کیونکہ اگر 10,000،XNUMX سیب ہوں تو ، اس سے کہیں زیادہ تلاش کیا جاسکتا ہے۔
اس کے برعکس لاس ویگاس کے الگورتھم: عام طور پر کہا جاتا ہے کہ اگر ایک تالے میں ایک ہزار چابیاں ہیں، لیکن ان میں سے صرف ایک ہی صحیح ہے۔ اس لیے ہر بار جب ایک چابی کو بے ترتیب طور پر لے کر کوشش کی جائے اور اسے کھولنے میں ناکامی ہو تو اسے تبدیل کیا جائے۔ جتنی بار کوشش کی جائے گی، بہترین حل کھولنے کا امکان اتنا ہی زیادہ ہو گا، لیکن کھولنے سے پہلے، وہ غلط چابیاں بے کار ہیں۔
لہذا لاس ویگاس کا الگورتھم بہترین حل ہے ، لیکن ضروری نہیں کہ اسے تلاش کیا جاسکے۔ فرض کریں کہ 1000 چابیاں میں سے کوئی بھی تالا کھولنے والا نہیں ہے ، اصل کلید 1001 واں ہے ، لیکن نمونہ میں 1001 واں الگورتھم نہیں ہے ، لاس ویگاس الگورتھم کو تالا کھولنے والی کلید نہیں مل سکتی ہے۔
AlphaGo کا مونٹی کارلو الگورتھم گو کی مشکل خاص طور پر مصنوعی ذہانت کے لیے بہت بڑی ہے، کیونکہ گو کی بہت سی شکلیں ہیں جن کو کمپیوٹرز کے لیے الگ کرنا مشکل ہے۔ وانگ لیپ نے کہا: اوہو ، سب سے پہلے ، گو کی بہت زیادہ امکانات ہیں۔ گو کے ہر قدم میں بہت زیادہ ممکنہ فیصلے ، جب شطرنج شروع ہوتا ہے تو اس میں 19 × 19 = 361 ڈراپ کا انتخاب ہوتا ہے۔ ایک کھیل میں 150 راؤنڈ میں گو کی ممکنہ صورتحال 10170 تک ہوسکتی ہے۔ دوسرا ، یہ ہے کہ قواعد بہت نازک ہیں ، کسی حد تک ڈراپ کا انتخاب تجربہ جمع کرنے سے پیدا ہونے والی انٹرو پر منحصر ہے۔ اس کے علاوہ ، گو کے شیشے میں ، کمپیوٹر کے لئے موجودہ شیشے کی طاقت اور کمزوری کو الگ کرنا مشکل ہے۔ لہذا ، گو چیلنج کو مصنوعی ذہانت کا چیلنج کہا جاتا ہے۔
اور AlphaGo صرف مونٹی کارلو الگورتھم نہیں ہے، بلکہ یہ مونٹی کارلو الگورتھم کا ایک اپ گریڈ ہے.
AlphaGo نے مونٹی کارلو ٹری سرچ الگورتھم اور دو گہرائی نیورل نیٹ ورکس کے ساتھ مل کر شطرنج کو مکمل کیا۔ لی شیشے سے مقابلہ کرنے سے پہلے ، گوگل نے سب سے پہلے انسانی جوڑے کے تقریبا 30 ملین چلنے کے طریقوں کا استعمال کرتے ہوئے AlphaGo کتے کے نیورل نیٹ ورک کو تربیت دی ، تاکہ یہ سیکھ سکے کہ انسانی پیشہ ور شطرنج کھلاڑی کس طرح گرتا ہے۔ اس کے بعد ، اس سے بھی آگے ، AlphaGo کو خود اپنے ساتھ شطرنج کھیلنے دیں ، جس سے بڑے پیمانے پر ایک نیا شطرنج پیدا ہوگا۔ گوگل انجینئرز نے اعلان کیا ہے کہ AlphaGo ایک دن میں لاکھوں چلنے کی کوشش کرسکتا ہے۔
ان کا کام یہ ہے کہ وہ مشترکہ طور پر زیادہ امید افزا چالوں کو منتخب کریں اور واضح طور پر خراب چالوں کو چھوڑ دیں ، اس طرح کمپیوٹر کے ذریعہ انجام دینے کے قابل حد تک حساب کتاب کو کنٹرول کریں۔ بنیادی طور پر ، یہ وہی ہے جو انسانی شطرنج کھلاڑی کرتے ہیں۔
چائنا اکیڈمی آف سائنسز کے آٹومیشن انسٹی ٹیوٹ کے محقق ایجیان یانگ نے کہا کہ روایتی شطرنج سافٹ ویئر ، عام طور پر تشدد کی تلاش کا استعمال کرتا ہے ، بشمول گہرے نیلے رنگ کے کمپیوٹر ، جو تمام ممکنہ نتائج کے لئے تلاش کا درخت بناتا ہے ((ہر نتیجہ درخت کا ایک پھل ہے) ، جس کی ضرورت کے مطابق تلاش کی تلاش کی جاتی ہے۔ یہ طریقہ شطرنج ، شطرنج وغیرہ کے لئے بھی قابل عمل ہے ، لیکن یہ گو کے لئے قابل عمل نہیں ہے ، کیونکہ گو ہر 19 لائنوں میں گھومتا ہے ، اس کا امکان اتنا زیادہ ہے کہ کمپیوٹر اس درخت کی تعمیر نہیں کرسکتا (بہت زیادہ پھل) گھومنے والی تلاش کو انجام دینے کے لئے۔ اور الفاگو نے بہت ہوشیار طریقہ اپنایا ، اس مسئلے کو بہترین طریقے سے حل کیا۔ اس نے گہری سیکھنے کے طریقہ کار کو استعمال کیا جس نے درخت کی تلاش کی پیچیدگی کو کم کردیا ، تلاش کی جگہ کم ہوگئی۔ مثال کے طور پر ، حکمت عملی نیٹ ورک کمپیوٹر کو تلاش کرنے کی ہدایت کرتا ہے جو انسان کے ہاتھ کی طرح زیادہ اونچی جگہ پر گرنے کا اندازہ کرتا
ڈونگاچی نے مزید وضاحت کی کہ گہرائی میں نیورل نیٹ ورک کی بنیادی اکائی ہمارے انسانی دماغ کی طرح نیورونز کی طرح ہے، بہت سی تہوں سے جڑی ہوئی یہ انسانی دماغ کی نیورل نیٹ ورک کی طرح ہے۔ الفاگو کے دو نیورل نیٹ ورکس دماغ کی چنگاری ہیں حکمت عملی نیٹ ورک اور تشخیصی نیٹ ورک۔
حکمت عملی نیٹ ورک بنیادی طور پر گرنے کی حکمت عملی پیدا کرنے کے لئے استعمال کیا جاتا ہے۔ شطرنج کھیلنے کے دوران ، اس نے یہ نہیں سوچا کہ اسے کیا ہونا چاہئے ، بلکہ یہ سوچا کہ انسان کے اعلی ہاتھ کیا ہوں گے۔ یعنی ، یہ ان پٹ شیڈ کی موجودہ حالت کی بنیاد پر پیش گوئی کرے گا کہ انسان کا اگلا شطرنج کہاں ہوگا ، اور کچھ قابل عمل اقدامات پیش کرے گا جو انسانی سوچ کے مطابق ہیں۔
تاہم ، حکمت عملی کے نیٹ ورک کو یہ نہیں معلوم ہے کہ آیا اس کی چال اچھی ہے یا نہیں ، یہ صرف یہ جانتا ہے کہ آیا یہ چال انسانوں کی طرح ہی ہے ، اور اس وقت تشخیصی نیٹ ورک کو کام کرنے کی ضرورت ہے۔
ڈونگاچی نے کہا: “ٹریکٹ ویلیو نیٹ ورک ہر قابل عمل اختیارات کے لئے پورے ڈسپلے کی صورتحال کا اندازہ کرتا ہے ، اور پھر ایک جیتنے کی شرح ٹریکٹ دیتا ہے۔ یہ اقدار مونٹی کارلو درخت تلاش کے الگورتھم میں واپس آتی ہیں ، جو اس طرح کے عمل کو دہرانے کے ذریعے جیتنے کی شرح ٹریکٹ کا سب سے زیادہ راستہ پیش کرتی ہیں۔ مونٹی کارلو درخت تلاش کے الگورتھم نے فیصلہ کیا ہے کہ حکمت عملی کا نیٹ ورک صرف اس جگہ پر جاری رہے گا جہاں جیتنے کی شرح ٹریکٹ زیادہ ہے ، لہذا کچھ راستوں کو چھوڑ دیا جاسکتا ہے ، اور ایک راستہ کے حساب سے کالے تک نہیں پہنچ سکتا ہے۔ “
الفاگو ان دونوں ٹولز کا استعمال حالات کا تجزیہ کرنے اور ہر چھوٹی حکمت عملی کی خوبیوں اور خامیوں کا فیصلہ کرنے کے لئے کرتا ہے ، جیسے انسانی شطرنج کھلاڑی موجودہ صورتحال کا فیصلہ کرتے ہیں اور مستقبل کے حالات کا اندازہ لگاتے ہیں۔ مونٹی کارلو ٹری سرچ الگورتھم کا استعمال کرتے ہوئے تجزیہ کیا گیا ہے کہ مثال کے طور پر اگلے 20 اقدامات کے معاملے میں ، یہ فیصلہ کیا جاسکتا ہے کہ کون سا چھوٹا جیتنے کا امکان زیادہ ہوگا۔
لیکن اس میں کوئی شک نہیں کہ مونٹی کارلو الگورتھم الفاگو کے بنیادی حصوں میں سے ایک ہے۔
دو چھوٹے تجربات آخر میں مونٹی کارلو الگورتھم کے دو چھوٹے تجربات دیکھیں۔
- ### 1۔ دائرے کا حساب لگائیں۔
اصول: پہلے ایک مربع کھینچیں، اس کے اندر کاٹ دائرے کو کھینچیں، پھر اس مربع کے اندر بے ترتیب ڈرائنگ پوائنٹ، سیٹ پوائنٹ دائرے کے اندر تقریبا P ہے، تو P = دائرے کا رقبہ / مربع کا رقبہ۔ P=(Pi*R*R)/(2R*2R) = Pi/4، یعنی Pi = 4P
اقدامات: 1۔ دائرے کا مرکز اصل مقام پر رکھیں اور R کو شعاع کے طور پر دائرے میں رکھیں، پھر پہلے چوکور کا 1⁄4 دائرے کا رقبہ Pi ہے*R*R/4 2. اس 1 / 4 دائرے کے باہر سے منسلک مربع بنائیں ، جس کے کوآرڈینیٹ ہیں:*R 3۔ فوراً پوائنٹ لے لے ((X،Y) ، تاکہ 0<=X<=R اور 0<=Y<=R، یعنی پوائنٹ مربع کے اندر ہو فارمولہ X کے ذریعے 4.*X+Y*Y*کیا R کا فیصلہ 1⁄4 دائرے کے اندر ہے؟ 5. تمام پوائنٹس ((یعنی تجربات کی تعداد) کی تعداد N ہے، اور 1⁄4 دائرے کے اندر پوائنٹس ((مطابق قدم 4 کے پوائنٹس) کی تعداد M ہے،
P=M/N تو Pi=4 ہے*N/M
 تصویر نمبر 1
تصویر نمبر 1
M_C{10000} کا نتیجہ 3.1424 ہے
- ### 2. مونٹی کارلو نے فنکشن کی انتہا کو ماڈل کیا تاکہ مقامی انتہا میں پھنسنے سے بچا جاسکے
# درمیان میں[- 2، 2] میں ایک نمبر کو بے ترتیب طور پر جنریٹ کریں، اس کا y جواب تلاش کریں، اور اس میں سب سے بڑا فاریکس ٹریڈنگ کیا ہے؟ تصور کریں کہ یہ فنکشن[-2,2] پر ایک بہت بڑی قیمت
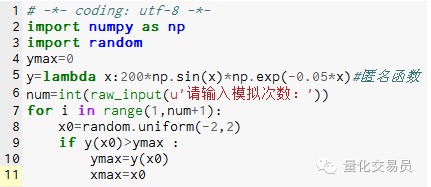 تصویر نمبر 2
تصویر نمبر 2
ایک ہزار بار کے بعد 185.12292832389875 (بہت درست)
یہاں دیکھ کر آپ سمجھ گئے ہوں گے۔ کوڈ کو ہاتھ سے لکھا جا سکتا ہے، بہت مزے کی بات ہے! ویکیپیڈیا کے عوامی شمارے سے نقل کیا گیا