دماغ میں ویکٹر مشینوں کو سپورٹ کریں۔
 0
2106
0
2106
دماغ میں ویکٹر مشینوں کو سپورٹ کریں۔
سپورٹ ویکٹر مشین (SVM) ایک اہم مشین لرننگ کلاسریٹر ہے جو غیر لکیری تبدیلیوں کا استعمال کرتے ہوئے کم جہتی خصوصیات کو اعلی جہت میں پیش کرتا ہے ، جو درجہ بندی کے زیادہ پیچیدہ کاموں کو انجام دے سکتا ہے۔ SWM ایسا لگتا ہے کہ اس نے ایک ریاضیاتی ہنر کا استعمال کیا ہے ، لیکن حقیقت میں یہ دماغ کے کوڈنگ کے طریقہ کار کے مطابق ہوتا ہے۔ ہم 2013 کے فطرت کے ایک مضمون سے پڑھ سکتے ہیں ، مشین لرننگ اور دماغ کے کام کرنے کے اصولوں کے گہرے روابط کو سمجھنے کے لئے (مشین لرننگ کا استعمال کرتے ہوئے دماغ کی سطح پر رابطے کا مطالعہ کیا جاتا ہے) ۔ مقالے کا نام: پیچیدہ علمی کاموں میں مخلوط انتخابیت کی اہمیت (by Omri Barak al. )
- #### SVM
اس حیرت انگیز ربط کو کہاں سے دیکھا جاسکتا ہے؟ آئیے پہلے نیورول کوڈنگ کی نوعیت کے بارے میں بات کرتے ہیں: جانور ایک مخصوص سگنل کو قبول کرتے ہیں اور اس کے مطابق ایک خاص عمل کرتے ہیں ، ایک یہ ہے کہ بیرونی سگنل کو نیورو الیکٹرک سگنل میں تبدیل کیا جائے ، اور دوسرا یہ ہے کہ نیورو الیکٹرک سگنل کو فیصلہ سازی کے سگنل میں تبدیل کیا جائے ، پہلے عمل کو کوڈنگ کہا جاتا ہے ، اور بعد میں اس کو ڈی کوڈنگ کہا جاتا ہے۔ اور نیورول کوڈنگ کا اصل مقصد یہ ہے کہ اس کے بعد اس کو ڈی کوڈ کیا جائے اور فیصلہ کیا جائے۔ لہذا ، مشین لرننگ کے ذریعہ بصری کوڈ کو ڈی کوڈ کرنے کا سب سے آسان طریقہ یہ ہے کہ ایک درجہ بندی کرنے والا ، یا یہاں تک کہ ایک لاجسٹک ماڈل کا ایک لکیری درجہ بندی کرنے والا ، ان پٹ سگنل کو کسی خاص خصوصیت کے مطابق درجہ بندی کریں۔ جیسے کہ شیر کو بھاگتے ہوئے دیکھنا ، یا بندرگاہ کو کھانے کو دیکھنا۔ یقینا ، بعض اوقات ایسا کرنا اچھا ہوتا ہے ، مثال کے طور پر ، جب نیورول سگنل بالآخر
تو آئیے دیکھتے ہیں کہ نیورل کوڈنگ کس طرح کی جاتی ہے، پہلے نیورون بنیادی طور پر ایک آر سی سرکٹ کی طرح دیکھا جا سکتا ہے جو بیرونی وولٹیج کے مطابق مزاحمت اور گنجائش کو ایڈجسٹ کرتا ہے، جب بیرونی سگنل کافی بڑا ہوتا ہے، تو وہ ڈائیورٹ ہو جاتا ہے، ورنہ بند ہو جاتا ہے، اور ایک خاص وقت میں بجلی کی فراہمی کی فریکوئنسی کے ذریعے ایک سگنل کی نمائندگی کرتا ہے۔ اور ہم کوڈنگ کے بارے میں بات کرتے ہیں، اکثر وقت کے ساتھ ایک بکھرے ہوئے پروسیسنگ کرتے ہیں، یہ سوچتے ہیں کہ ایک چھوٹی سی وقت کی ونڈو میں، یہ بجلی کی فراہمی کی شرح غیر متغیر ہے، اس طرح ایک نیورل نیٹ ورک اس وقت کی ونڈو میں سیل کی بجلی کی فراہمی کی مقدار کو ایک ساتھ دیکھ سکتا ہے ایک این جہتی سمت، این نیورون کی تعداد ہے، یہ این جہتی مقدار، ہم اسے کوڈنگ کہتے ہیں، اور اس کی نمائندگی کرتا ہے کہ جانور کیا دیکھ سکتا ہے، یا آوازیں سن سکتا ہے، اور اس سے متعلقہ پرتوں کے نیورل نیٹ ورکس کو خارج
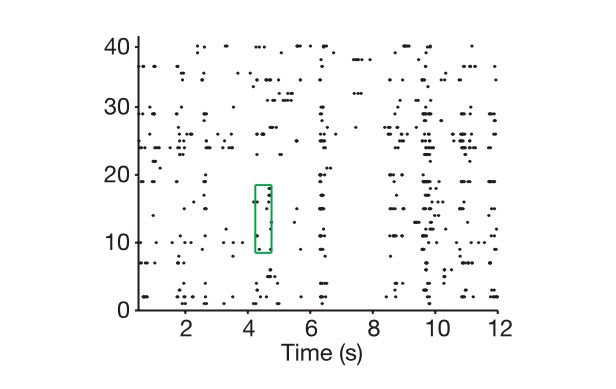
اور یہ کہ ہم کس طرح نیورل کوڈ کو نکالتے ہیں اس کا اندازہ لگایا جا سکتا ہے۔
یقیناً N-dimensional vector اور neural encoding کی حقیقی جہتیں مختلف ہیں، تو پھر اس کی حقیقی جہتوں کی تعریف کیسے کی جائے؟ پہلے ہم اس N-dimensional vector سے نشان زد N-dimensional space میں داخل ہوتے ہیں، پھر ہم ہر ممکن کام کا مجموعہ دیتے ہیں، جیسے کہ آپ کو ایک ہزار تصاویر دکھانا۔ فرض کریں کہ یہ تصاویر پوری دنیا کی نمائندگی کرتی ہیں، اور ہر بار جب ہمیں نیورل کوڈ ملتا ہے تو ہم اس جگہ کو ایک نقطہ کے طور پر نشان زد کرتے ہیں، اور آخر میں ہم اس ہزار پوائنٹس پر مشتمل ذیلی جگہ کی جہتوں کو دیکھنے کے لئے ویکٹر الجبرا کی سوچ کا استعمال کرتے ہیں، جسے نیورل علامت کی حقیقی جہت کہا جاتا ہے۔ میرا فرض ہے کہ تمام پوائنٹس اس N-dimensional space کی ایک لائن پر واقع ہیں، تو پھر یہ علامت ایک جہتی ہے، اس کے مطابق اگر تمام پوائنٹس ایک دو جہتی سطح پر ہوں، جو کہ دو جہتی ہے۔ سائنسدانوں نے دریافت کیا ہے کہ نیورل کوڈ عام طور پر بہت زیادہ جہتوں کا ہوتا ہے، اور یقیناً اگر N-dimensional
کوڈنگ کے حقیقی طول و عرض کے علاوہ، ہمارے پاس ایک تصور ہے کہ بیرونی سگنل کی حقیقی طول و عرض، یہاں سگنل اعصابی نیٹ ورک کی طرف اشارہ کرتا ہے بیرونی سگنل، یقینا آپ کو بیرونی سگنل کی تمام تفصیلات کو دوبارہ کرنا پڑے گا یہ ایک لامحدود مسئلہ ہے، تاہم ہمارے درجہ بندی اور فیصلے کی بنیاد ہمیشہ اہم خصوصیت ہے، ایک کمی کا عمل ہے، یہ بھی پی سی اے کی سوچ ہے۔ یہاں ہم حقیقی مشن میں اہم متغیر کو مشن کی حقیقی طول و عرض کے طور پر دیکھ سکتے ہیں، مثلا آپ ایک بازو کی تحریک کو کنٹرول کرنا چاہتے ہیں، آپ کو عام طور پر صرف جوڑ کے گھومنے کے زاویہ کو کنٹرول کرنے کی ضرورت ہوتی ہے، اگر آپ اسے ایک ٹھوس حرکیات کا مسئلہ سمجھتے ہیں تو، طول و عرض شاید 10 سے زیادہ نہیں ہو گی، ہم اسے K کہتے ہیں۔ یہاں تک کہ اگر یہ ایک چہرہ کی شناخت کا مسئلہ ہے تو، طول و عرض کا مسئلہ اب بھی انفرادی نیورونوں کی تعداد سے بہت کم ہے۔
تو سائنسدانوں کو ایک بنیادی سوال درپیش ہے، کیوں اس کوڈ کی ایک بڑی تعداد اور نیورونوں کی ایک بڑی تعداد کے ساتھ حل کرنے کی کوشش کی جائے؟ کیا یہ ضائع نہیں ہے؟
اور کمپیوٹنگ نیوروسینس اور مشین لرننگ کے ساتھ مل کر ہمیں بتاتا ہے کہ نیورولوجیکل اشارے کی اعلی جہتی خصوصیات ہی اس کی اعلی تعلیمی صلاحیتوں کی بنیاد ہیں۔ کوڈنگ کی اونچائی ، سیکھنے کی صلاحیت زیادہ ہے۔ نوٹ کریں کہ ہم یہاں گہرائی کے نیٹ ورک میں بھی شامل نہیں ہوئے ہیں۔ کیوں؟ یہاں ہم کہتے ہیں کہ نیورولوجیکل کوڈنگ کا طریقہ کار ایس وی ایم کی طرح کے اصولوں کا استعمال کرتا ہے ، جب ہم ایک کم جہتی سگنل کو اعلی جہت میں پیش کرتے ہیں تو ہم زیادہ سے زیادہ درجہ بندی کرسکتے ہیں ، یہاں تک کہ اگر یہ ایک لکیری درجہ بندی کرنے والا ہے تو ، آپ کو بے شمار مسائل حل کرنے کی ضرورت ہے ، اور یہ کیسے؟ اور یہ ایس وی ایم کو مشین کے اصولوں کے لئے کس طرح تعاون کرتا ہے؟
نوٹ کریں کہ یہاں زیر بحث اعصابی کوڈنگ بنیادی طور پر اعلی اعصابی مرکزوں کی اعصابی کوڈنگ کا حوالہ دیتی ہے ، جیسے کہ پی ایف سی (Prefrontal Cortex ((PFC)) جس پر مضمون میں بحث کی گئی ہے ، کیونکہ نچلے اعصابی مرکزوں کے کوڈنگ قوانین درجہ بندی اور فیصلے میں زیادہ شامل نہیں ہیں۔
اعلی درجے کے دماغ کے علاقے PFC کی نمائندگی کرتے ہیں
نیورون کوڈنگ کے اسرار کو نیورون کی تعداد N سے بھی پتہ چلتا ہے ، اور اس کا تعلق حقیقی مسئلے کی جہت K سے ہے (یہ فرق 200 گنا تک پہنچ سکتا ہے) ۔ نیورون کی تعداد کی بظاہر ضرورت سے زیادہ تعداد کو معیار کی چھلانگ کیوں لگ سکتی ہے؟ سب سے پہلے ، ہم فرض کرتے ہیں کہ ہم ایک لکیری درجہ بندی کا استعمال کرتے ہوئے غیر لکیری درجہ بندی کے مسئلے سے نمٹنے کے قابل نہیں ہوں گے جب ہماری کوڈنگ کی جہت حقیقی مشن میں اہم متغیر کی جہت کے برابر ہے۔ (فرض کریں کہ آپ کو ایک سیپنگ سے سیپنگ کو الگ کرنا ہے ، آپ کو سیپنگ سے سیپنگ کو ایک لکیری بارڈر سے الگ نہیں کیا جاسکتا ہے) ، یہ بھی ایک عام مسئلہ ہے جسے ہم ڈیپ لرننگ اور ایس وی ایم کے بغیر مشین لرننگ میں حل کرنا مشکل سمجھتے ہیں۔ اس قسم کے مسئلے کے لئے ایس وی ایم کے بنیادی تشریح کو دوبارہ نمائندگی کے طور پر استعمال کیا جاتا ہے ، یعنی ہم اپنے اصل کوآرڈینیٹ کو ایک نئے سیٹ میں تبدیل کرتے ہیں جس میں ایک اعلی جہتی کوآرڈینی
SVM ((ویکٹر مشین کی حمایت):
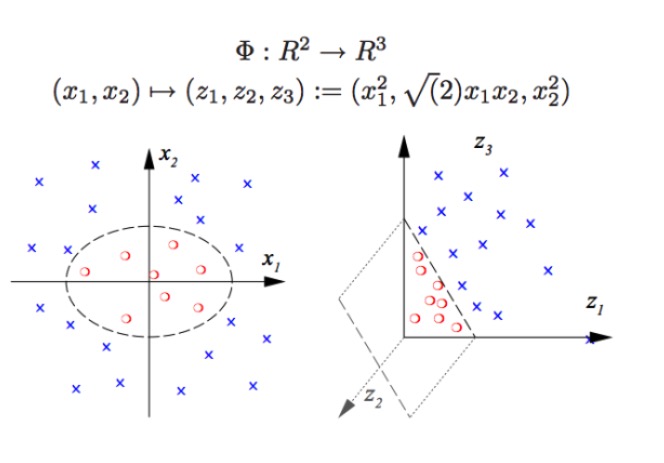
ایس وی ایم غیر لکیری درجہ بندی کرسکتا ہے ، مثال کے طور پر گراف میں سرخ نقطہ اور نیلے نقطہ کو الگ کرنا ، ہم لکیری سرحد کے ساتھ سرخ نقطہ اور نیلے نقطہ کو الگ نہیں کرسکتے ہیں (تصویر بائیں) ، لہذا ایس وی ایم کا طریقہ صرف طول و عرض کو بڑھانا ہے۔ جب کہ صرف متغیرات کی تعداد میں اضافہ کرنا ناممکن ہے ، جیسے کہ (x1 ، x2 ، x1 + x2) کو نقشہ کرنا (سسٹم اصل میں دو جہتی لکیری جگہ ہے) ، صرف غیر لکیری فنکشن (x1 ^ 2 ، x1) کا استعمال کرتے ہوئے*x2، x2^2، تو ہم اصل میں ایک کم طول و عرض سے ایک اعلی طول و عرض کی طرف منتقل ہو رہے ہیں، اور اس وقت آپ نیلے رنگ کے نقطہ کو ہوا میں پھینک دیتے ہیں، اور پھر آپ ہوا میں ایک سطح بناتے ہیں، اور پھر آپ نیلے رنگ کے نقطہ کو سرخ سے الگ کرتے ہیں، جیسا کہ دائیں تصویر میں دکھایا گیا ہے۔
اصل میں ، حقیقی نیورل نیٹ ورک بالکل اسی طرح کام کرتا ہے۔ اس طرح کے ایک لکیری درجہ بندی کرنے والے (ڈیکوڈر) کے ذریعہ انجام دی جانے والی درجہ بندی کی اقسام میں بہت زیادہ اضافہ ہوا ہے ، یعنی ہمیں پہلے سے کہیں زیادہ مضبوط نمونہ شناخت کی صلاحیت ملی ہے۔ یہاں ، اعلی طول و عرض اعلی توانائی ہے ، اعلی طول و عرض کی ہڑتال سچ ہے۔
تو، کس طرح اعصابی کوڈنگ کے اعلی طول و عرض حاصل کرنے کے لئے؟ نور نیورونز کی ایک بڑی تعداد کے لئے کوئی فائدہ نہیں ہے. کیونکہ ہم نے سیکھا ہے کہ لکیری الجبرا ہم جانتے ہیں کہ اگر ہمارے پاس ایک بہت بڑی تعداد میں N نیورونز ہیں، اور ہر نیورون کی ڈسچارج کی شرح صرف K اہم خصوصیت کے ساتھ لکیری طور پر منسلک ہے، تو ہم آخر میں صرف مسئلہ کے طول و عرض کے برابر ہے کہ طول و عرض کی نمائندگی کریں گے، آپ کے N نیورونز کو کوئی اثر نہیں ہے ((زیادہ سے زیادہ نیورونز پہلے K نیورونز کے لکیری مجموعہ ہیں). اس نقطہ کو توڑنے کے لئے، آپ کو K خصوصیت کے ساتھ غیر لکیری طور پر منسلک نیورونز ہونا ضروری ہے، یہاں ہم اسے غیر لکیری ہائبرڈ نیورون کہتے ہیں، اور اس قسم کے نیورونز کی نمائندگی بہت پیچیدہ ہے، اور اس طرح کے طور پر اس کے طور پر اسی طرح کے طور پر SVM میں اس کے غیر لکیری عناصر پر مشتمل ہے.
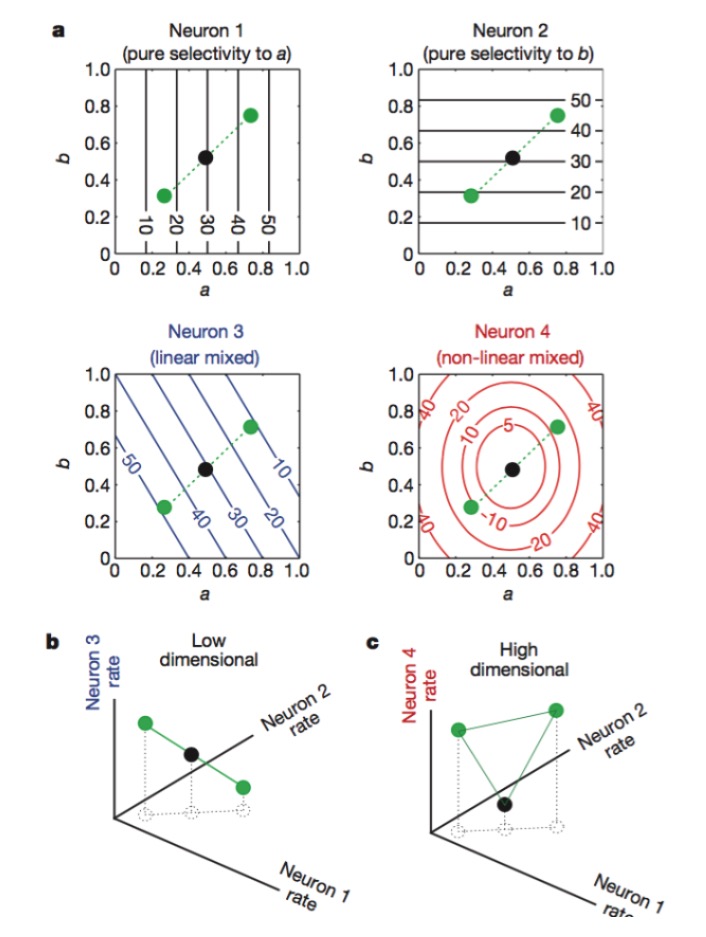
تصویر: نیورون 1 اور 2 بالترتیب صرف خصوصیت a اور b کے لئے حساس ہیں ، 3 خصوصیت a اور b کے لکیری مرکب کے لئے حساس ہیں ، اور 4 خصوصیت کے غیر لکیری مرکب کے لئے حساس ہیں۔ بالآخر صرف نیورون 1 ، 2 ، 4 کا مجموعہ نیورون کوڈنگ جہت میں اضافہ کرتا ہے (نیچے تصویر) ۔
اس طرح کی کوڈنگ کا سرکاری نام مخلوط کوڈنگ ہے، اور جب لوگوں کو اس طرح کی کوڈنگ کا اصول نہیں ملا تو ہمیں یہ سمجھ نہیں آتا تھا، کیونکہ یہ ایک ایسا نیورل نیٹ ورک ہے جو کسی خاص قسم کے سگنل پر بدقسمتی سے ردعمل ظاہر کرتا ہے۔ ارد گرد کے اعصابی نظام میں، نیورونز سینسر کی طرح کام کرتے ہیں، سگنل کی مختلف خصوصیات کو نکالنے اور پہچاننے کے لیے۔ ہر نیورون سیل کا کام کافی مخصوص ہوتا ہے، جیسے کہ ریٹنا میں موجود راڈس اور کونز فوٹون کو قبول کرنے کے لیے ذمہ دار ہوتے ہیں، اور اس کے بعد گینجیلیئن سیل کوڈنگ کرتا رہتا ہے، اور ہر نیورون ایک خاص طور پر تربیت یافتہ چوکی کی طرح ہوتا ہے۔ جبکہ دماغ کے اعلیٰ علاقوں میں، اس طرح کی واضح تفریق مشکل نظر آتی ہے، ہم نے پایا کہ ایک ہی نیورون مختلف خصوصیات کے لیے حساس ہو سکتا ہے، اور یہ حساسیت لکیری بھی نہیں ہے۔ یہ مختلف کاموں کے لیے ایک جیسی ہے، اور اس طرح کے مخصوص طریقوں کا پتہ لگانا بہت مشکل ہوتا ہے، جیسے کہ نیورونز کو الگ
فطرت کی ہر تفصیل میں فرنٹ اینڈ موجود ہے، بہت زیادہ ریڈینس اور مخلوط کوڈنگ۔ یہ غیر پیشہ ورانہ لگ رہا ہے، اور بظاہر گندا سگنل، اور آخر کار بہتر کمپیوٹنگ طاقت ملتی ہے۔ اس اصول کے بعد، ہم آسانی سے کچھ اس طرح کے کاموں کو سنبھال سکتے ہیں:
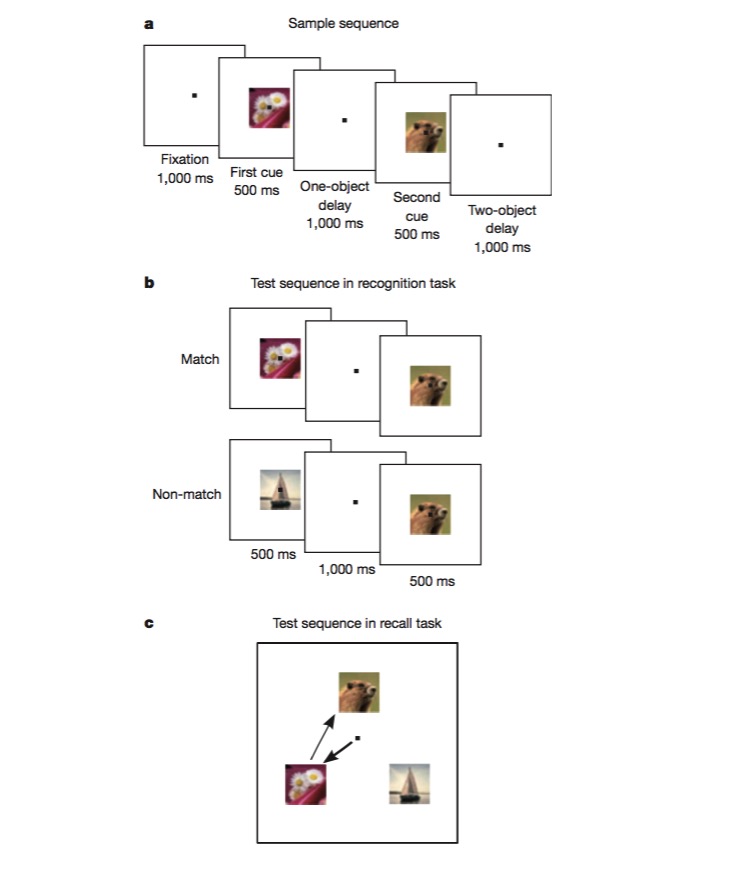
اس مشن میں ، بندر کو پہلے اس بات کی نشاندہی کرنے کی تربیت دی جاتی ہے کہ آیا ایک تصویر پچھلی تصویر سے مماثل ہے یا نہیں۔ اس کے بعد اس بات کا فیصلہ کرنے کی تربیت دی جاتی ہے کہ دو مختلف تصاویر کس ترتیب میں نمودار ہوئیں۔ اس طرح کے مشن کو انجام دینے کے لئے بندر کو مشن کے مختلف پہلوؤں کو کوڈ کرنے کے قابل ہونا چاہئے ، جیسے مشن کی قسم ، تصویر کی اقسام ، وغیرہ۔ اور یہ بالکل ٹھیک ہے ٹیسٹ کیا گیا ہے کہ آیا ہائبرڈ غیر لکیری کوڈنگ میکانزم موجود ہے۔ تجربات میں تصدیق کی گئی ہے کہ نیورون کی ایک بڑی تعداد ہائبرڈ خصوصیت کے لئے حساس ہے ، اور غیر لکیری موجود ہے۔
اس مضمون کو پڑھ کر ہم نے سیکھا کہ نیورل نیٹ ورکس کو ڈیزائن کرنے سے نمونوں کی شناخت میں بہتری آتی ہے اگر کچھ غیر لکیری یونٹس کو شامل کیا جائے۔ اور ایس وی ایم نے اس کو لاگو کیا اور غیر لکیری درجہ بندی کے مسئلے کو حل کیا۔ جبکہ کمپیوٹنگ نیورو سائنس اور مشین لرننگ ایک سکے کے دو رخ ہیں۔
ہم دماغ کے علاقوں کے افعال کا مطالعہ کرتے ہیں، پہلے مشین لرننگ کے طریقوں سے اعداد و شمار پر کارروائی کرتے ہیں، مثلاً پی سی اے کے ذریعے مسئلے کی اہم جہتیں تلاش کرتے ہیں، پھر مشین لرننگ کے نمونوں کو پہچاننے والے ذہنوں سے نیورل کوڈنگ اور ڈی کوڈ کو سمجھنے کے لیے۔ آخر میں ہم اگر کچھ نیا الہام حاصل کریں تو ہم مشین لرننگ کے طریقوں کو بہتر بنا سکتے ہیں۔ دماغ یا مشین لرننگ کے الگورتھم کے لیے، آخر میں سب سے اہم بات یہ ہے کہ معلومات کو مناسب طریقے سے نمائندگی کا طریقہ حاصل کیا جائے، اور اچھی نمائندگی کے ساتھ، سب کچھ آسان ہو جاتا ہے۔ یہی مشین لرننگ کا لکیری منطق سے واپس آکر کوانٹم میشن سپورٹ کرنے والی مشینوں سے گہری سیکھنے کی طرف قدم بہ قدم ارتقا کا عمل ہے، شاید یہ بھی ہمارے دماغ کے ارتقا کے لیے ممکن ہے، جس کے ذریعے ہم دنیا پر بڑھتی ہوئی قابو پانے کی صلاحیت رکھتے ہیں۔ یا شاید ارتقا کا مقصد یہ واضح ہونا چاہیے تھا کہ ٹائیگر کون ہے، بوڑ
ٹوئٹر پر ٹوئٹ کرتے ہوئے انہوں نے کہا: