Bạn có thể chạy nhanh hơn khỉ đột bằng cách cá cược (giao dịch) với máy vectơ SVM không?
 3
3843
3
3843
Bạn có thể chạy nhanh hơn khỉ đột bằng cách cá cược (giao dịch) với máy vectơ SVM không?
Hôm nay, chúng ta sẽ cố gắng hết sức để đánh bại một con chim khỉ, một trong những đối thủ đáng sợ nhất trong lĩnh vực tài chính. Chúng ta sẽ cố gắng dự đoán lợi nhuận của các loại giao dịch tiền tệ khác. Tôi đảm bảo với bạn rằng thậm chí đánh bại một con chim ưng ý và có 50% cơ hội thắng cũng là một việc rất khó. Chúng ta sẽ sử dụng một thuật toán học máy sẵn có, nó hỗ trợ cho bộ phân loại vector. Máy vector SVM là một phương pháp cực kỳ mạnh mẽ để giải quyết các nhiệm vụ hồi quy và phân loại.
- SVM hỗ trợ máy vector
Máy vectơ SVM dựa trên một ý tưởng: chúng ta có thể sử dụng siêu phẳng để phân loại không gian đặc tính p. Thuật toán máy vectơ SVM sử dụng một siêu phẳng và một nhận thức Margin để tạo ra ranh giới quyết định phân loại, như hình dưới đây.
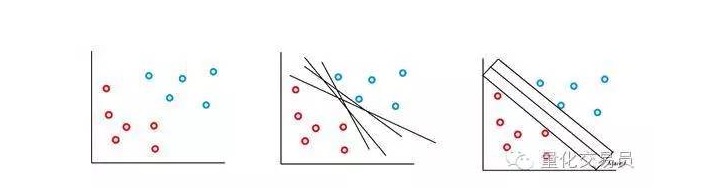
Trong trường hợp đơn giản nhất, phân loại tuyến tính là có thể. Thuật toán chọn biên giới quyết định, nó có thể tối đa hóa khoảng cách giữa các lớp.
Trong hầu hết các chuỗi thời gian tài chính mà bạn gặp phải, bạn sẽ không gặp phải các tập hợp đơn giản, có thể tách rời theo đường thẳng, nhưng các trường hợp không thể tách rời thường xuyên xảy ra. Máy vector SVM đã giải quyết vấn đề này bằng cách thực hiện một phương pháp được gọi là “phương pháp biên mềm”.
Trong trường hợp này, một số trường hợp phân loại sai được cho phép, nhưng chúng tự thực hiện các hàm, để đưa C (các lỗi về chi phí hoặc ngân sách có thể được cho phép) thành tỷ lệ thuận với các nhân và giảm thiểu khoảng cách từ sai đến biên giới.
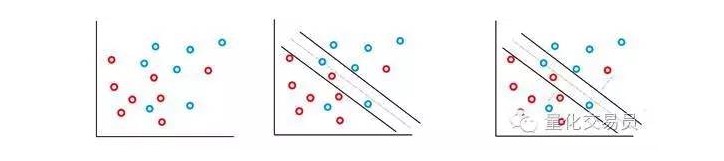
Về cơ bản, máy sẽ cố gắng tối đa hóa khoảng cách giữa các phân loại, đồng thời giảm thiểu các hình phạt của nó được C tăng trọng.
Một tính năng tuyệt vời của bộ phân loại SVM là vị trí và kích thước của ranh giới quyết định phân loại chỉ được quyết định bởi một phần dữ liệu, tức là phần dữ liệu gần nhất với ranh giới quyết định. Tính năng của thuật toán này cho phép nó chống lại sự can thiệp của các giá trị bất thường ở khoảng cách xa. Ví dụ như trong biểu đồ trên, điểm xanh ở bên phải, ảnh hưởng đến ranh giới quyết định rất nhỏ.
Có phải là quá phức tạp? Ồ, tôi nghĩ là niềm vui chỉ mới bắt đầu.
Hãy xem xét các trường hợp sau đây (để tách các chấm đỏ và các chấm màu khác):
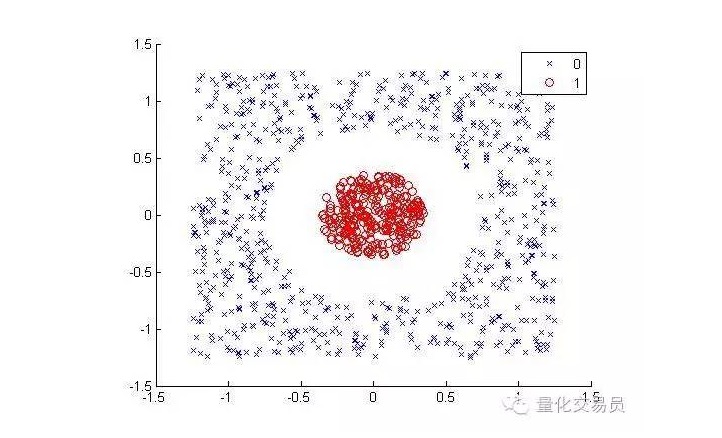
Đối với con người, nó rất đơn giản để phân loại (một đường cong là tốt) ¦ nhưng đối với máy móc thì không. Rõ ràng, nó không thể làm thành một đường thẳng (một đường thẳng không thể tách các điểm đỏ ra).
Kỹ thuật hạt nhân là một kỹ thuật toán học rất thông minh, nó cho phép chúng ta giải quyết các vấn đề phân loại tuyến tính trong không gian chiều cao. Bây giờ chúng ta hãy xem nó được làm như thế nào.
Chúng ta sẽ chuyển từ không gian đặc trưng hai chiều sang không gian ba chiều bằng cách dựng lên bản đồ, và trở lại không gian hai chiều sau khi phân loại xong.
Dưới đây là hình ảnh sau khi phân loại được thực hiện:
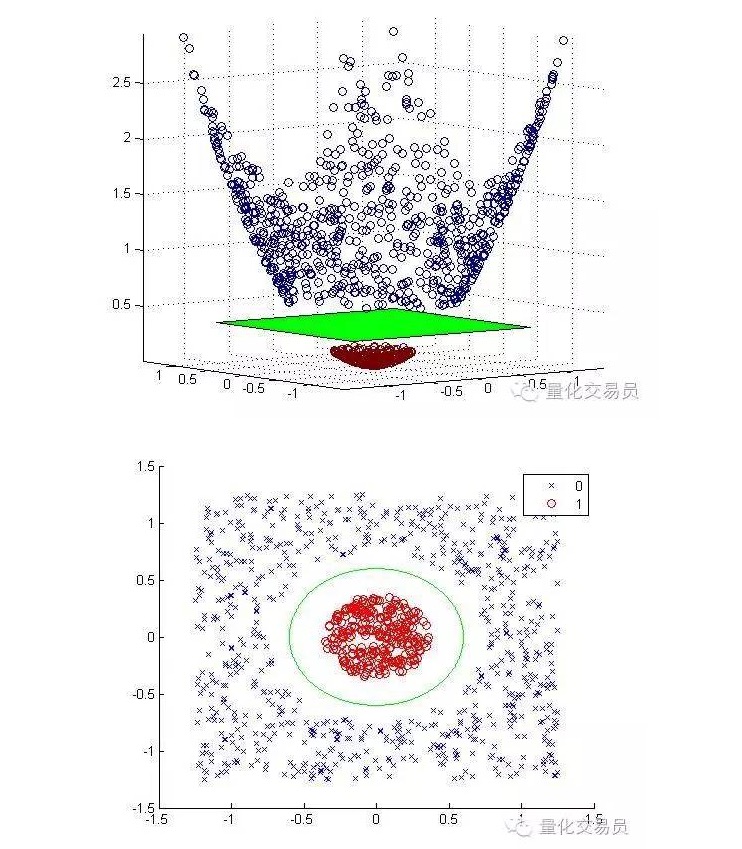
Nói chung, nếu có d đầu vào, bạn có thể sử dụng một bản đồ từ không gian đầu vào d chiều đến không gian tính p chiều. Chạy các giải pháp mà thuật toán tối thiểu hóa trên sẽ tạo ra, sau đó bản đồ trở lại không gian đầu vào ban đầu của bạn p chiều siêu phẳng.
Một tiền đề quan trọng của giải pháp toán học trên là nó phụ thuộc vào việc làm thế nào để tạo ra một tập hợp mẫu điểm tốt trong không gian đặc trưng.
Bạn chỉ cần các tập hợp mẫu điểm này để thực hiện tối ưu hóa biên giới, bản đồ không cần phải rõ ràng, các điểm của không gian đầu vào trong không gian đặc trưng chiều cao có thể được tính toán một cách an toàn thông qua hàm hạt nhân ((và một chút sự giúp đỡ của định lý Mercer)).
Ví dụ, bạn muốn giải quyết vấn đề phân loại của bạn trong một không gian đặc điểm rất lớn, giả sử là 100000 chiều. Bạn có thể tưởng tượng được sức mạnh tính toán mà bạn cần không? Tôi rất nghi ngờ về việc bạn có thể làm được điều đó.
- Thách thức và con khỉ
Bây giờ chúng ta đang chuẩn bị để đối mặt với thách thức của việc đánh bại khả năng dự đoán của Jeff.
Jeff là một chuyên gia về thị trường tiền tệ, ông có thể đạt được độ chính xác dự đoán 50% bằng cách đặt cược ngẫu nhiên, độ chính xác này là tín hiệu dự đoán lợi nhuận trong ngày giao dịch tiếp theo.
Chúng tôi sẽ sử dụng các chuỗi thời gian cơ bản khác nhau, bao gồm cả chuỗi thời gian giá hiện tại, mỗi chuỗi thời gian có lợi nhuận lên đến 10lags, tổng cộng 55features.
Máy vector SVM mà chúng tôi chuẩn bị xây dựng là sử dụng lõi 3 độ. Bạn có thể nghĩ rằng chọn một lõi phù hợp là một nhiệm vụ rất khó khăn khác, để hiệu chỉnh các tham số C và Γ, 3 lần xác minh chéo chạy trên lưới các tham số có thể, và một trong những nhóm tốt nhất sẽ được chọn.
Kết quả không mấy khích lệ:
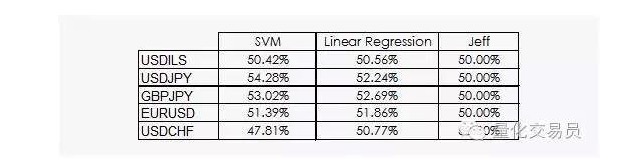
Chúng ta có thể thấy rằng cả hồi quy tuyến tính và máy vectơ SVM đều có thể đánh bại Jeff. Mặc dù kết quả không lạc quan, chúng ta cũng có thể rút ra một số thông tin từ dữ liệu, và đó là tin tốt, bởi vì trong ngành dữ liệu, lợi ích hàng ngày của chuỗi thời gian tài chính không phải là hữu ích nhất
Sau khi xác thực chéo, tập dữ liệu sẽ được đào tạo và thử nghiệm, chúng tôi ghi lại khả năng dự đoán của SVM được đào tạo, và để có một hiệu suất ổn định, chúng tôi lặp lại 1000 lần phân chia ngẫu nhiên cho mỗi loại tiền tệ.
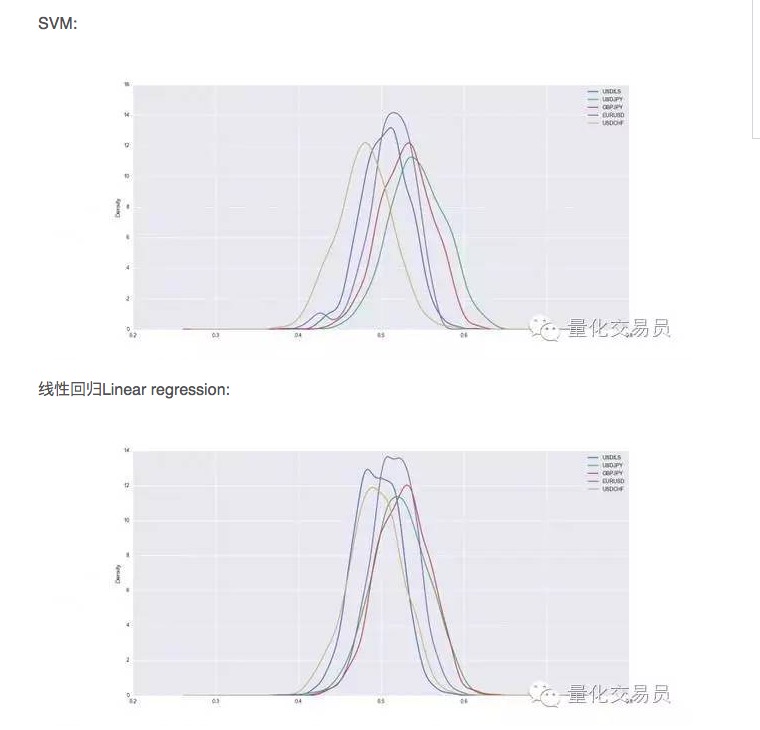
Vì vậy, trong một số trường hợp, SVM tốt hơn so với hồi quy tuyến tính đơn giản, nhưng sự khác biệt về hiệu suất cũng cao hơn một chút. Ví dụ, với đồng USD so với đồng JPY, tín hiệu dự đoán trung bình của chúng tôi chiếm 54% tổng số lần. Đây là một kết quả khá tốt, nhưng hãy xem xét kỹ hơn!
Ted là anh em họ của Jeff, và nó cũng là một con khỉ, nhưng nó thông minh hơn Jeff. Ted chú ý đến tập mẫu tập luyện, chứ không phải đặt cược ngẫu nhiên.
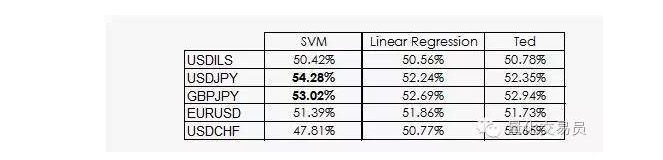
Như chúng ta đã thấy, hiệu suất của hầu hết các SVM chỉ xuất phát từ một thực tế: máy học rằng phân loại không có khả năng tương đương với tiền lệ. Trong thực tế, hồi quy tuyến tính không thể lấy bất kỳ thông tin nào từ không gian đặc trưng, nhưng độ phân đoạn ((intercept) có ý nghĩa trong hồi quy, và độ phân đoạn tương ứng với một phân loại nào đó hoạt động tốt hơn.
Một tin tốt hơn là SVM có thể lấy thêm một số thông tin phi tuyến tính từ dữ liệu, cho phép chúng ta đưa ra dự đoán chính xác hơn 2%.
Thật không may, chúng ta vẫn chưa biết được thông tin này là gì, giống như SVM có những nhược điểm chính của nó, điều mà chúng ta không thể giải thích rõ ràng.
Tác giả: P. López, xuất bản trên quantdare
Hình ảnh: WeChat Public
