Vũ khí của AlphaGo: Thuật toán Monte Carlo, bạn sẽ hiểu sau khi đọc bài viết này! (có ví dụ về mã)--In lại
 0
23883
0
23883
Alpha Dog’s Algorithm: Các thuật toán Monte Carlo, bạn có thể hiểu được!
Một sự kiện lớn trong thế giới Go đã diễn ra từ ngày 9 đến ngày 15 tháng 3 năm nay, với 5 trận đấu giữa người và máy diễn ra tại Seoul, Hàn Quốc. Kết quả của trận đấu này là con người đã thua, và vô địch thế giới Go Shih Tzu đã đánh bại AlphaGo, một chương trình trí tuệ nhân tạo của Google, 1 - 4. Vậy AlphaGo là gì, và chìa khóa để chiến thắng ở đâu?
- ### AlphaGo và thuật toán Monte Carlo
AlphaGo là một chương trình chơi Go được phát triển bởi nhóm DeepMind của Google, được các fan hâm mộ Trung Quốc gọi là “bộ chó Alpha” (阿狗).
Trong bài viết trước, chúng tôi đã đề cập đến các thuật toán mạng thần kinh mà Google đang phát triển để cho phép máy móc tự học, và AlphaGo cũng là một sản phẩm tương tự.
Phó chủ tịch Hội đồng Quản trị và Tổng thư ký Hiệp hội Tự động hóa Trung Quốc Vương Lưu nói rằng các lập trình viên không cần phải thành thạo Go, chỉ cần hiểu các quy tắc cơ bản của Go. AlphaGo được xây dựng bởi một nhóm các nhà khoa học máy tính xuất sắc, đúng hơn là các chuyên gia trong lĩnh vực học máy. Các nhà khoa học sử dụng thuật toán mạng thần kinh để nhập hồ sơ trận đấu của các chuyên gia cờ vua vào máy tính và cho máy tính tự chơi với chính mình, trong quá trình này liên tục học tập.
Vậy đâu là chìa khóa để AlphaGo tự học và trở thành một tài năng? Đó là thuật toán Monte Carlo.
Thuật toán Monte Carlo là gì? Chúng ta có thể giải thích thuật toán Monte Carlo thông thường: Nếu trong giỏ có 1000 quả táo, bạn có thể nhắm mắt mỗi lần để tìm ra quả táo lớn nhất, và không giới hạn số lần bạn chọn. Vì vậy, bạn có thể nhắm mắt và chọn một quả táo ngẫu nhiên, sau đó chọn một quả táo ngẫu nhiên để so sánh với quả táo đầu tiên, để lại quả táo lớn, và chọn một quả táo ngẫu nhiên để so sánh với quả táo trước đó, để lại quả táo lớn.
Nói cách khác, thuật toán Monte Carlo là càng nhiều mẫu, càng có thể tìm ra giải pháp tốt nhất, nhưng không đảm bảo là tốt nhất, bởi vì nếu có 10.000 quả táo, có lẽ sẽ tìm ra một cái lớn hơn.
Có một sự so sánh đáng chú ý với thuật toán Las Vegas: Theo cách nói thông thường, nếu có một khóa, có 1000 chìa khóa để lựa chọn, nhưng chỉ có 1 chìa khóa là đúng. Vì vậy, mỗi lần ngẫu nhiên lấy 1 chìa khóa để thử, không mở được, hãy thay đổi 1 chìa khóa. Càng nhiều lần thử, cơ hội mở giải pháp tốt nhất càng lớn, nhưng trước khi mở, những chìa khóa sai đều không có ích.
Vì vậy, thuật toán Las Vegas là giải pháp tốt nhất có thể, nhưng không nhất thiết phải tìm thấy. Giả sử trong số 1000 chìa khóa, không có bất kỳ chìa khóa nào được mở, chìa khóa thực sự là 1001 thứ, nhưng trong mẫu không có thuật toán số 1001, thuật toán Las Vegas không thể tìm thấy chìa khóa mở khóa.
Thuật toán Monte Carlo của AlphaGo Khó khăn của trò chơi Go là đặc biệt lớn đối với trí tuệ nhân tạo, bởi vì có quá nhiều cách chơi Go mà máy tính khó phân biệt. Vương Liễu nói: Đầu tiên, có quá nhiều khả năng của cờ vây. Mỗi bước của cờ vây có rất nhiều khả năng, người chơi cờ vây có 19 × 19 = 361 lựa chọn rơi. Trong một trận đấu 150 vòng, có thể có đến 10.170 tình huống.
AlphaGo không chỉ là một thuật toán Monte Carlo mà còn là một phiên bản nâng cấp của nó.
Trước khi đối đầu với Li Shih Tzu, Google đã bắt đầu huấn luyện mạng thần kinh của con chó Alpha với gần 30 triệu bước đi của con người, để nó có thể dự đoán cách người chơi cờ vua chuyên nghiệp của con người đánh bại. Tiếp theo, AlphaGo tự chơi cờ vua với chính mình, tạo ra một bảng cờ mới với quy mô khổng lồ. Các kỹ sư của Google đã tuyên bố rằng AlphaGo có thể thử một triệu bước đi mỗi ngày.
Nhiệm vụ của chúng là hợp tác để chọn ra những bước cờ có triển vọng hơn, loại bỏ những trò chơi có lỗi rõ ràng, và do đó kiểm soát số lượng tính toán trong phạm vi máy tính có thể thực hiện. Về cơ bản, điều này giống như những gì người chơi cờ làm.
Theo nghiên cứu viên của Viện nghiên cứu tự động hóa của Viện Hàn lâm Khoa học Trung Quốc, Ai Yan Yan, phần mềm cờ bạc truyền thống của Liu, thường sử dụng tìm kiếm bạo lực, bao gồm máy tính màu xanh đậm, nó tạo ra cây tìm kiếm cho tất cả các kết quả có thể (mỗi kết quả là một trái cây trên cây), tìm kiếm theo nhu cầu. Phương pháp này cũng có thể thực hiện được trong cờ vua, cờ vua, v.v., nhưng không thể thực hiện được cho Go, vì Go trải dài 19 đường, khả năng rơi quá lớn đến mức máy tính không thể xây dựng cây này (có quá nhiều trái cây) để thực hiện tìm kiếm qua.
Trong một bài phát biểu khác của mình, Longchamp giải thích rằng một đơn vị cơ bản nhất của mạng lưới thần kinh sâu giống như một tế bào thần kinh trong não người, với nhiều lớp kết nối giống như một mạng lưới thần kinh trong não người. Hai mạng lưới thần kinh của AlphaGo là mạng lưới chiến lược và mạng lưới đánh giá.
Mạng lưới chiến lược cờ vua chủ yếu được sử dụng để tạo ra chiến lược rơi. Trong quá trình chơi cờ vua, nó không nghĩ về việc mình nên chơi thế nào, mà nghĩ về việc bàn tay cao của con người sẽ chơi thế nào.
Tuy nhiên, các mạng lưới chiến lược không biết được liệu những bước đi của họ có tốt hay không, họ chỉ biết rằng những bước đi của họ có giống với con người hay không, và khi đó mạng lưới đánh giá sẽ có tác dụng.
Trong một bài báo, ông nói: “Mạng lưới đánh giá giá trị kim loại sẽ đánh giá toàn bộ vị trí cho các giải pháp khả thi, sau đó đưa ra một kim loại tỷ lệ thắng. Những giá trị này sẽ được phản hồi vào thuật toán tìm kiếm cây Monte Carlo, bằng cách lặp lại các quá trình như trên để đưa ra các bước có tỷ lệ thắng cao nhất.
AlphaGo sử dụng cả hai công cụ này để phân tích tình hình và đánh giá ưu và xấu của mỗi chiến lược tiếp theo, giống như một người chơi cờ vua sẽ đánh giá tình hình hiện tại và suy ra tình hình trong tương lai. Sử dụng thuật toán tìm kiếm cây Monte Carlo để phân tích ví dụ như 20 bước trong tương lai, có thể xác định nơi có khả năng chiến thắng của tiếp theo.
Nhưng không nghi ngờ gì, thuật toán Monte Carlo là một trong những yếu tố cốt lõi của AlphaGo.
Hai thí nghiệm nhỏ Cuối cùng, hãy nhìn vào hai thí nghiệm nhỏ của thuật toán Monte Carlo.
- ### 1. Tính chu vi pi.
Nguyên tắc: Bắt đầu vẽ một hình vuông, vẽ một vòng tròn bên trong, sau đó vẽ một điểm ngẫu nhiên bên trong hình vuông, đặt điểm nằm trong vòng tròn là P, P = diện tích vòng tròn / diện tích hình vuông. P=(Pi*R*R)/(2R*2R) = Pi/4, tức là Pi = 4P
Bước 3: 1. Đặt tâm của vòng tròn tại điểm gốc, làm vòng tròn với R là bán kính, thì 1⁄4 diện tích vòng tròn của tứ giác đầu tiên là Pi*R*R/4 2. Làm một hình vuông ngoài của 1 / 4 vòng tròn, tọa độ là ((0,0) ((0,R) ((R,0) ((R,R), thì diện tích của hình vuông là R*R 3. Bắt điểm ((X, Y), để 0 <= X <= R và 0 <= Y <= R, tức là điểm nằm trong hình vuông 4. Bằng phương trình X*X+Y*Y*Điểm R có nằm trong vòng 1⁄4 vòng tròn không? 5. Giả sử tất cả các điểm (tức là số lần thử nghiệm) là N, và các điểm nằm trong vòng 1⁄4 (tức là các điểm đáp ứng bước 4) là M, thì
P=M/N, Pi=4*N/M
 Hình 1
Hình 1
M_C(10000) kết quả là 3.1424
- ### 2. Mô phỏng Monte Carlo tìm các cực đại của hàm, tránh bị mắc kẹt trong các cực đại địa phương
# Trong khoảng cách[-2,2] tạo ra một số ngẫu nhiên, tìm ra y của nó, tìm ra trong đó lớn nhất là hàm trong[-2,2] trên cực đại
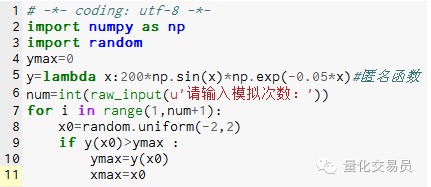 Hình 2
Hình 2
Mô phỏng 1000 lần và tìm thấy giá trị tối đa là 185.12292832389875 (cực kỳ chính xác)
Bạn có thể viết mã bằng tay, thật thú vị! Hình ảnh: WeChat Public