
Một chuyến tham quan các thuật toán học máy
Sau khi hiểu được các vấn đề học máy mà chúng ta cần giải quyết, chúng ta có thể suy nghĩ về những dữ liệu chúng ta cần thu thập và những thuật toán chúng ta có thể sử dụng. Trong bài viết này, chúng ta sẽ đi qua các thuật toán học máy phổ biến nhất để hiểu rõ hơn về các phương pháp có thể được sử dụng.
Có rất nhiều thuật toán trong lĩnh vực học máy, và mỗi thuật toán có rất nhiều phần mở rộng, vì vậy làm thế nào để xác định một thuật toán đúng cho một vấn đề cụ thể là rất khó.
-
Cách học
Các thuật toán được phân loại theo cách chúng xử lý kinh nghiệm, môi trường hoặc bất kỳ dữ liệu nào chúng ta gọi là đầu vào. Các sách giáo khoa về học máy và trí tuệ nhân tạo thường xem xét cách thức học mà các thuật toán có thể thích ứng.
Đây chỉ là một vài trong số các phong cách học tập hay mô hình học tập chính, và có một vài ví dụ cơ bản. Cách phân loại hay tổ chức này rất tốt, bởi vì nó buộc bạn phải suy nghĩ về vai trò của dữ liệu đầu vào và quá trình chuẩn bị mô hình, sau đó chọn một thuật toán phù hợp nhất với vấn đề của bạn, để có được kết quả tốt nhất.
Học giám sát: Dữ liệu đầu vào được gọi là dữ liệu đào tạo và có kết quả được biết hoặc được đánh dấu. Ví dụ như nói rằng một email là thư rác hay giá cổ phiếu trong một khoảng thời gian. Mô hình đưa ra dự đoán, nếu sai sẽ được sửa chữa, và quá trình này tiếp tục cho đến khi nó đạt được một tiêu chuẩn chính xác nhất định đối với dữ liệu đào tạo. Ví dụ về vấn đề bao gồm các vấn đề phân loại và hồi quy, ví dụ về thuật toán bao gồm hồi quy logic và mạng thần kinh đảo ngược.
Học không giám sát: Dữ liệu đầu vào không được đánh dấu và không có kết quả xác định. Mô hình quy kết cấu và giá trị số của dữ liệu. Ví dụ về vấn đề bao gồm học luật liên kết và câu hỏi tập hợp, ví dụ về thuật toán bao gồm thuật toán Apriori và thuật toán K-mean.
Học bán giám sát: Dữ liệu đầu vào là sự pha trộn của dữ liệu được đánh dấu và không được đánh dấu, có một số vấn đề dự đoán nhưng mô hình cũng phải học cấu trúc và thành phần của dữ liệu. Ví dụ về vấn đề bao gồm phân loại và quy trình hồi quy, ví dụ về thuật toán về cơ bản là phần mở rộng của thuật toán học không giám sát.
Học tăng cường: Dữ liệu đầu vào có thể kích thích mô hình và khiến mô hình phản ứng. Phản hồi không chỉ được lấy từ quá trình học của học giám sát, mà còn từ phần thưởng hoặc hình phạt trong môi trường. Ví dụ về vấn đề là kiểm soát robot, ví dụ về thuật toán bao gồm Q-learning và học chênh lệch thời gian.Khi tích hợp các quyết định kinh doanh mô phỏng dữ liệu, hầu hết đều sử dụng các phương pháp học tập giám sát và học tập không giám sát. Một chủ đề nóng tiếp theo là học tập bán giám sát, chẳng hạn như vấn đề phân loại hình ảnh, trong đó có một cơ sở dữ liệu lớn, nhưng chỉ có một phần nhỏ hình ảnh được đánh dấu.
-
Sự tương đồng của thuật toán
Các thuật toán được phân loại về cơ bản theo chức năng hoặc hình thức. Ví dụ, thuật toán dựa trên cây, thuật toán mạng thần kinh. Đây là một cách phân loại rất hữu ích, nhưng không hoàn hảo. Vì có nhiều thuật toán có thể dễ dàng được chia thành hai loại, ví dụ như Learning Vector Quantization đồng thời là thuật toán thuộc loại mạng thần kinh và phương pháp dựa trên ví dụ.
Trong phần này, tôi đã liệt kê các thuật toán phân loại mà tôi cho là trực quan nhất. Tôi không có tất cả các thuật toán hoặc cách phân loại, nhưng tôi nghĩ rằng nó sẽ rất hữu ích cho người đọc để có một cái nhìn tổng quát. Nếu bạn biết những gì tôi không liệt kê, hãy chia sẻ.
-
Regression
Regression quan tâm đến mối quan hệ giữa các biến. Nó áp dụng các phương pháp thống kê, một số ví dụ về thuật toán bao gồm:
Ordinary Least Squares
Logistic Regression
Stepwise Regression
Multivariate Adaptive Regression Splines (MARS)
Locally Estimated Scatterplot Smoothing (LOESS) -
Instance-based Methods
Học dựa trên ví dụ (instance based learning) mô phỏng một vấn đề quyết định, ví dụ hoặc ví dụ được sử dụng rất quan trọng đối với mô hình. Phương pháp này xây dựng một cơ sở dữ liệu cho dữ liệu hiện có và sau đó thêm dữ liệu mới vào đó, sau đó sử dụng một phương pháp đo tương tự để tìm ra một trận đấu tốt nhất trong cơ sở dữ liệu, để đưa ra một dự đoán. Vì lý do này, phương pháp này cũng được gọi là phương pháp chiến thắng và phương pháp dựa trên bộ nhớ.
k-Nearest Neighbour (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM) -
Regularization Methods
Đây là một phần mở rộng của các phương pháp khác (thường là phương pháp hồi quy), phần mở rộng này có lợi cho các mô hình đơn giản hơn và tốt hơn trong quy. Tôi liệt kê nó ở đây vì nó phổ biến và mạnh mẽ.
Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO)
Elastic Net -
Decision Tree Learning
Decision tree methods (phương pháp cây quyết định) xây dựng một mô hình dựa trên các quyết định giá trị thực tế trong dữ liệu. Cây quyết định được sử dụng để giải quyết các vấn đề khôi phục và hồi quy.
Classification and Regression Tree (CART)
Iterative Dichotomiser 3 (ID3)
C4.5
Chi-squared Automatic Interaction Detection (CHAID)
Decision Stump
Random Forest
Multivariate Adaptive Regression Splines (MARS)
Gradient Boosting Machines (GBM) -
Bayesian
Bayesian method là phương pháp áp dụng định lý của Bayes trong việc giải quyết các vấn đề phân loại và hồi quy.
Naive Bayes
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN) -
Kernel Methods
Phương pháp Kernel nổi tiếng nhất là Máy Vector Hỗ trợ. Phương pháp này lập bản đồ dữ liệu đầu vào ở chiều cao hơn, một số vấn đề phân loại và hồi quy dễ dàng mô hình hơn.
Support Vector Machines (SVM)
Radial Basis Function (RBF)
Linear Discriminate Analysis (LDA) -
Clustering Methods
Clustering ((clustering), tự nó mô tả vấn đề và phương pháp. Các phương pháp clustering thường được phân loại bởi các phương pháp mô hình. Tất cả các phương pháp clustering được tổ chức dữ liệu bằng cấu trúc dữ liệu thống nhất, để mỗi nhóm có nhiều điểm chung nhất.
K-Means
Expectation Maximisation (EM) -
Association Rule Learning
Association rule learning là một phương pháp để rút ra các quy luật giữa các dữ liệu, thông qua các quy luật này có thể tìm thấy các mối liên hệ giữa một lượng lớn dữ liệu trong không gian đa chiều, và các mối liên hệ quan trọng này có thể được sử dụng bởi tổ chức.
Apriori algorithm
Eclat algorithm -
Artificial Neural Networks
Mạng thần kinh nhân tạo được lấy cảm hứng từ cấu trúc và chức năng của mạng thần kinh sinh học. Nó thuộc loại phù hợp với mô hình, thường được sử dụng cho các vấn đề hồi quy và phân loại, nhưng nó bao gồm hàng trăm thuật toán và biến thể.
Perceptron
Back-Propagation
Hopfield Network
Self-Organizing Map (SOM)
Learning Vector Quantization (LVQ) -
Deep Learning
Phương pháp học sâu là một loại cập nhật hiện đại của mạng thần kinh nhân tạo. Nó có cấu trúc mạng phức tạp hơn nhiều so với mạng thần kinh truyền thống, nhiều phương pháp quan tâm đến học bán giám sát, có rất nhiều dữ liệu về các vấn đề học tập như vậy, nhưng rất ít trong số đó là dữ liệu được đánh dấu.
Restricted Boltzmann Machine (RBM)
Deep Belief Networks (DBN)
Convolutional Network
Stacked Auto-encoders -
Dimensionality Reduction
Dimensionality Reduction (Giảm kích thước), giống như phương pháp tập hợp, theo đuổi và sử dụng cấu trúc thống nhất trong dữ liệu, nhưng nó sử dụng ít thông tin hơn để tổng hợp và mô tả dữ liệu. Điều này rất hữu ích để hình dung hoặc đơn giản hóa dữ liệu.
Principal Component Analysis (PCA)
Partial Least Squares Regression (PLS)
Sammon Mapping
Multidimensional Scaling (MDS)
Projection Pursuit -
Ensemble Methods
Phương pháp tập hợp (tiếng Anh: Ensemble methods) bao gồm nhiều mô hình nhỏ được đào tạo độc lập, đưa ra kết luận độc lập, và cuối cùng tạo thành một dự đoán tổng thể. Nhiều nghiên cứu tập trung vào những gì mô hình được sử dụng và làm thế nào các mô hình được kết hợp. Đây là một kỹ thuật rất mạnh mẽ và phổ biến.
Boosting
Bootstrapped Aggregation (Bagging)
AdaBoost
Stacked Generalization (blending)
Gradient Boosting Machines (GBM)
Random Forest
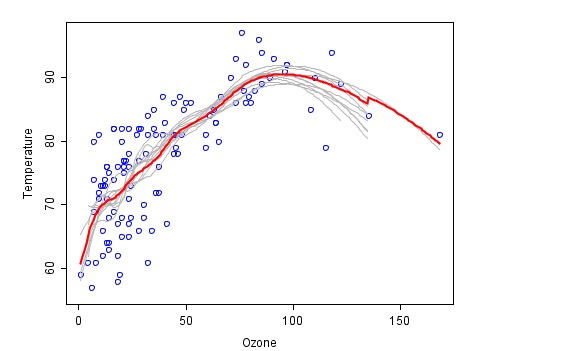
Đây là một ví dụ về việc tổng hợp bằng phương pháp kết hợp (được lấy từ wiki), với mỗi luật cứu hỏa được thể hiện bằng màu xám, và dự đoán cuối cùng của tổng hợp cuối cùng là màu đỏ.
-
Các nguồn khác
Chuyến du lịch này nhằm cung cấp cho bạn một cái nhìn tổng quan về các thuật toán và một số công cụ liên quan đến thuật toán.
Dưới đây là một số tài nguyên khác, đừng nghĩ rằng nó quá nhiều, bạn càng biết nhiều về các thuật toán càng tốt, nhưng hiểu sâu về một số thuật toán cũng sẽ hữu ích.
- List of Machine Learning Algorithms: Đây là một tài nguyên trên wiki, mặc dù đầy đủ, nhưng tôi nghĩ rằng nó không được phân loại tốt.
- Machine Learning Algorithms Category: Đây cũng là tài nguyên trên wiki, tốt hơn một chút so với ở trên, được sắp xếp theo chữ cái.
- CRAN Task View: Machine Learning & Statistical Learning: một phần mở rộng của ngôn ngữ R cho các thuật toán học máy, để bạn có thể so sánh những gì người khác đang sử dụng.
- Top 10 Algorithms in Data Mining: Đây là một bài viết đã được xuất bản và bây giờ là một cuốn sách, bao gồm các thuật toán khai thác dữ liệu phổ biến nhất. Một danh sách các thuật toán cơ bản khác, trong đó không có nhiều thuật toán được liệt kê, sẽ giúp bạn tìm hiểu sâu hơn.
Tóm tắt từ bài viết của Berle / nhà phát triển Python.
- 1