

Bài viết trước đã nghiên cứu khoảng thời gian đến của đơn hàng và chứng minh lý do tại sao chúng ta cần điều chỉnh các tham số một cách linh hoạt và cách đánh giá chất lượng ước tính. Bài viết này sẽ tập trung vào dữ liệu chuyên sâu và nghiên cứu mức giá trung bình (còn gọi là giá hợp lý, giá siêu nhỏ, v.v.).
Dữ liệu độ sâu
Binance cung cấp dữ liệu lịch sử tải xuống của các báo giá tốt nhất, bao gồm best_bid_price: giá thầu tốt nhất, tức là giá thầu tối đa, best_bid_qty: số lượng giá thầu tốt nhất, best_ask_price: giá chào bán tốt nhất, best_ask_qty: số lượng giá chào bán tốt nhất , transaction_time: dấu thời gian. Dữ liệu này không bao gồm các lệnh chờ cấp độ hai và các lệnh chờ sâu hơn. Tình hình thị trường được phân tích ở đây là YGG vào ngày 7 tháng 8. Biến động thị trường vào ngày hôm đó rất mạnh và lượng dữ liệu lên tới hơn 9 triệu.
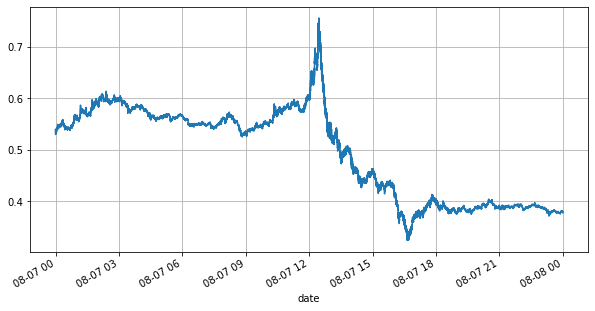
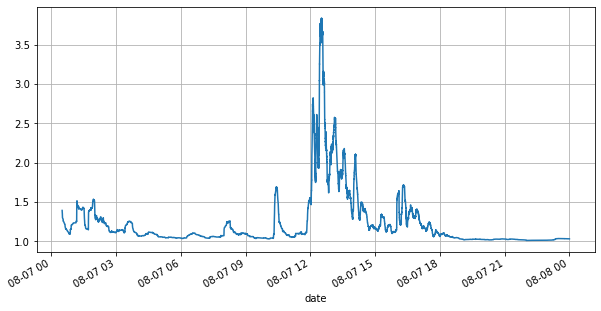
Trước tiên, chúng ta hãy xem xét thị trường trong ngày. Nó có những thăng trầm lớn. Ngoài ra, số lượng lệnh chờ trong ngày cũng thay đổi rất nhiều theo sự biến động của thị trường. Đặc biệt, chênh lệch (sự khác biệt giữa giá bán và giá mua) đã phản ánh rõ nét tình hình biến động của thị trường. Theo thống kê thị trường YGG ngày hôm đó, 20% thời gian chênh lệch lớn hơn 1 tick. Trong thời đại mà nhiều loại robot cạnh tranh trên thị trường như hiện nay, tình huống này rất hiếm gặp.
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
python
books = pd.read_csv('YGGUSDT-bookTicker-2023-08-07.csv')
python
tick_size = 0.0001
python
books['date'] = pd.to_datetime(books['transaction_time'], unit='ms')
books.index = books['date']
python
books['spread'] = round(books['best_ask_price'] - books['best_bid_price'],4)
python
books['best_bid_price'][::10].plot(figsize=(10,5),grid=True);
python
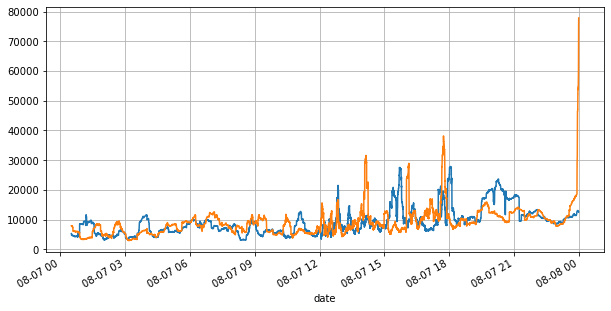
books['best_bid_qty'][::10].rolling(10000).mean().plot(figsize=(10,5),grid=True);
books['best_ask_qty'][::10].rolling(10000).mean().plot(figsize=(10,5),grid=True);
python
(books['spread'][::10]/tick_size).rolling(10000).mean().plot(figsize=(10,5),grid=True);
python
books['spread'].value_counts()[books['spread'].value_counts()>500]/books['spread'].value_counts().sum()
0.0001 0.799169
0.0002 0.102750
0.0003 0.042472
0.0004 0.022821
0.0005 0.012792
0.0006 0.007350
0.0007 0.004376
0.0008 0.002712
0.0009 0.001657
0.0010 0.001089
0.0011 0.000740
0.0012 0.000496
0.0013 0.000380
0.0014 0.000258
0.0015 0.000197
0.0016 0.000140
0.0017 0.000112
0.0018 0.000088
0.0019 0.000063
Name: spread, dtype: float64
Trích dẫn không cân bằng
Từ những điều trên, chúng ta có thể thấy rằng khối lượng lệnh mua và lệnh bán thường rất khác nhau. Sự khác biệt này có tác động dự báo mạnh mẽ đến các điều kiện thị trường ngắn hạn. Lý do tương tự như lý do đã đề cập ở bài viết trước là các lệnh mua nhỏ thường dẫn đến sự sụt giảm. Nếu các lệnh chờ ở một bên nhỏ hơn đáng kể so với các lệnh ở bên kia và giả sử khối lượng lệnh mua và bán đang hoạt động gần nhau, thì bên có lệnh chờ nhỏ hơn sẽ có nhiều khả năng bị bán hết, do đó thúc đẩy giá. thay đổi. Dấu ngoặc kép không cân bằng được biểu thị bằng I:
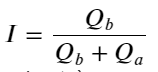
Trong đó Q_b biểu thị số lượng lệnh mua (best_bid_qty) và Q_a biểu thị số lượng lệnh bán (best_ask_qty).
Định nghĩa giá trung bình: 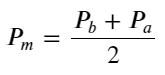
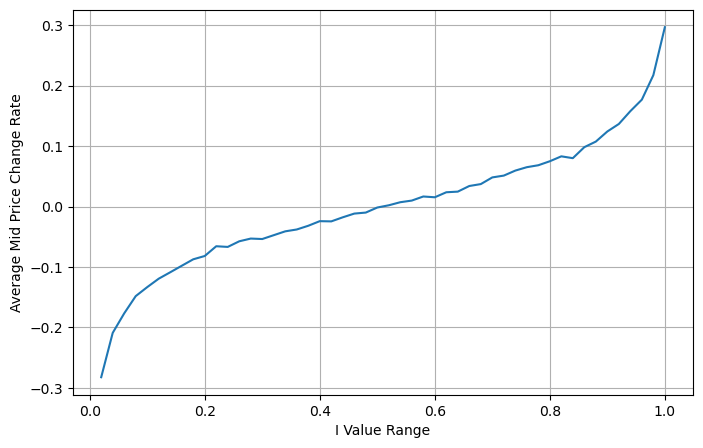
Hình sau đây cho thấy mối quan hệ giữa tỷ lệ thay đổi của giá trung bình trong khoảng thời gian tiếp theo và sự mất cân bằng I. Như mong đợi, khi I tăng, giá có nhiều khả năng tăng và càng gần 1, thì biên độ của giá cả thay đổi cũng tăng tốc. Trong giao dịch tần suất cao, mục đích của việc đưa ra giá trung gian là để dự đoán tốt hơn những thay đổi về giá trong tương lai. Nói cách khác, chênh lệch so với giá trong tương lai càng nhỏ thì giá trung gian được xác định càng tốt. Rõ ràng, sự mất cân bằng của các lệnh đang chờ cung cấp thêm thông tin cho dự đoán của chiến lược. Có tính đến điều này, chúng tôi định nghĩa giá trung bình có trọng số:
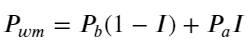
python
books['I'] = books['best_bid_qty'] / (books['best_bid_qty'] + books['best_ask_qty'])
python
books['mid_price'] = (books['best_ask_price'] + books['best_bid_price'])/2
python
bins = np.linspace(0, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['price_change'] = (books['mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['price_change'].mean()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Average Mid Price Change Rate');
plt.grid(True)
python
books['weighted_mid_price'] = books['mid_price'] + books['spread']*books['I']/2
bins = np.linspace(-1, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['weighted_price_change'] = (books['weighted_mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['weighted_price_change'].mean()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Weighted Average Mid Price Change Rate');
plt.grid(True)
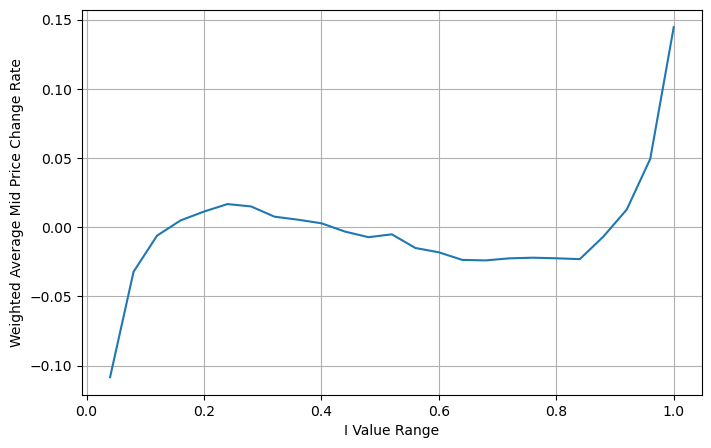
Điều chỉnh giá trung bình có trọng số
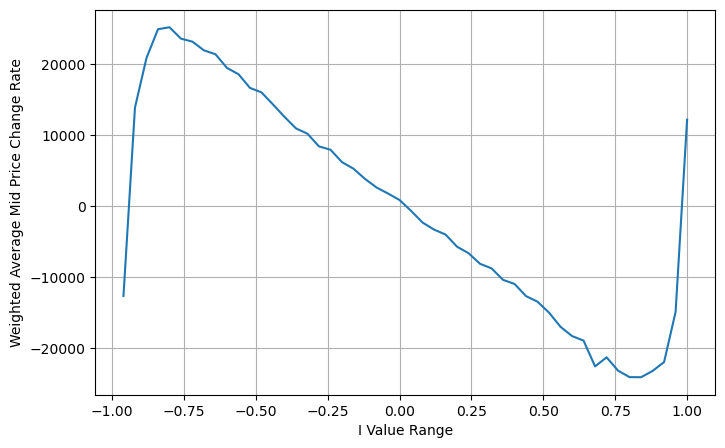
Từ hình vẽ, chúng ta có thể thấy rằng giá trung bình có trọng số thay đổi ít hơn nhiều so với giá trị I khác nhau, điều đó có nghĩa là giá trung bình có trọng số phù hợp hơn. Nhưng vẫn có một số quy luật, chẳng hạn như khoảng 0,2 và 0,8, khi đó độ lệch tương đối lớn. Điều này cho thấy tôi vẫn có thể đóng góp thêm thông tin. Bởi vì giá trung bình có trọng số giả định rằng điều khoản hiệu chỉnh giá hoàn toàn tuyến tính với I, điều này rõ ràng là không đúng. Như có thể thấy từ hình trên, khi I gần bằng 0 và 1, độ lệch nhanh hơn và không phải là mối quan hệ tuyến tính.
Để có cái nhìn trực quan hơn, I được định nghĩa lại ở đây:
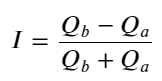
vào thời điểm này:
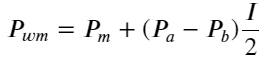
Quan sát biểu mẫu này, chúng ta có thể thấy rằng giá trung bình có trọng số là một sự điều chỉnh cho giá trung bình. Hệ số của thuật ngữ điều chỉnh là Spread, và thuật ngữ điều chỉnh là một hàm của I. Giá trung bình có trọng số chỉ đơn giản là giả định rằng mối quan hệ này là I/2. Lúc này, lợi thế của phân phối hiệu chỉnh của I (-1,1) được phản ánh. I đối xứng qua gốc tọa độ, giúp chúng ta dễ dàng tìm ra mối quan hệ phù hợp của hàm. Quan sát đồ thị, hàm này phải thỏa mãn mối quan hệ lũy thừa lẻ của I, phù hợp với sự tăng trưởng nhanh của cả hai vế và tính đối xứng quanh gốc tọa độ. Ngoài ra, có thể quan sát thấy giá trị gần gốc tọa độ gần với tuyến tính, và khi I bằng 0, kết quả của hàm là 0, và khi I bằng 1, kết quả của hàm là 0,5. Vậy hãy đoán xem hàm này trông như thế nào:
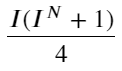
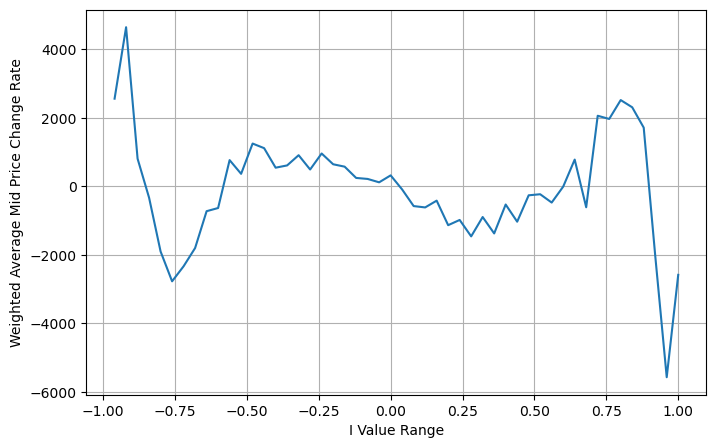
Ở đây N là số chẵn dương. Sau khi thử nghiệm thực tế, tốt hơn là N bằng 8. Cho đến nay, bài viết này đề xuất một mức giá trung bình có trọng số đã được sửa đổi:
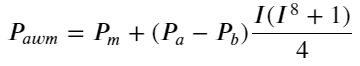
Vào thời điểm này, sự thay đổi trong mức giá trung bình dự đoán về cơ bản không liên quan gì đến I. Mặc dù kết quả này tốt hơn giá trung bình đơn giản có trọng số, nhưng nó không thể áp dụng trong giao dịch thực tế. Đây chỉ là một ý tưởng được đưa ra ở đây. Một bài viết năm 2017 của S Stoikov đã giới thiệu phương pháp chuỗi MarkovMicro-Pricevà cung cấp mã có liên quan, bạn cũng có thể nghiên cứu nó.
python
books['I'] = (books['best_bid_qty'] - books['best_ask_qty']) / (books['best_bid_qty'] + books['best_ask_qty'])
python
books['weighted_mid_price'] = books['mid_price'] + books['spread']*books['I']/2
bins = np.linspace(-1, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['weighted_price_change'] = (books['weighted_mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['weighted_price_change'].sum()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Weighted Average Mid Price Change Rate');
plt.grid(True)
python
books['adjust_mid_price'] = books['mid_price'] + books['spread']*(books['I'])*(books['I']**8+1)/4
bins = np.linspace(-1, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['adjust_mid_price'] = (books['adjust_mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['adjust_mid_price'].sum()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Weighted Average Mid Price Change Rate');
plt.grid(True)
python
books['adjust_mid_price'] = books['mid_price'] + books['spread']*(books['I']**3)/2
bins = np.linspace(-1, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['adjust_mid_price'] = (books['adjust_mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['adjust_mid_price'].sum()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Weighted Average Mid Price Change Rate');
plt.grid(True)
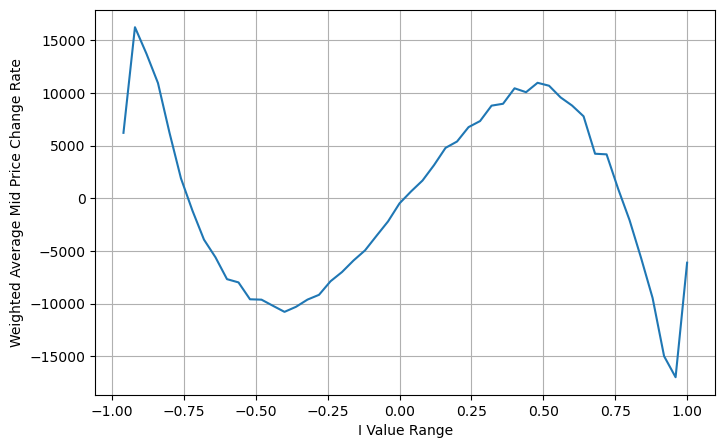
Tóm tắt
Giá trung bình rất quan trọng đối với các chiến lược tần suất cao. Đây là dự đoán về giá ngắn hạn trong tương lai, vì vậy giá trung bình phải chính xác nhất có thể. Các mức giá trung bình được giới thiệu ở trên đều dựa trên dữ liệu thị trường vì chỉ có một mức giá thị trường được sử dụng trong phân tích. Trong giao dịch thực tế, chiến lược nên sử dụng càng nhiều dữ liệu càng tốt, đặc biệt là khi có các giao dịch trao đổi trong giao dịch thực tế và dự đoán về giá trung bình nên được kiểm tra bằng giá giao dịch thực tế. Tôi nhớ Stoikov dường như đã đăng một dòng tweet nói rằng giá trung bình thực sự phải là giá trị trung bình có trọng số của xác suất giao dịch mua-một-bán. Vấn đề này vừa được nghiên cứu trong bài viết trước. Do khuôn khổ bài viết có hạn nên những vấn đề này sẽ được thảo luận chi tiết ở bài viết tiếp theo.


