

Bài viết trước đã giới thiệu sơ bộ về các phương pháp tính giá trung bình khác nhau và đưa ra bản sửa đổi về giá trung bình. Bài viết này tiếp tục đi sâu vào chủ đề này.
Dữ liệu bắt buộc
Dữ liệu luồng lệnh và mười cấp độ dữ liệu sâu được thu thập từ giao dịch thực tế và tần suất cập nhật là 100ms. Thị trường thực chỉ chứa dữ liệu mua và bán, được cập nhật theo thời gian thực. Để đơn giản, hiện tại nó không được sử dụng. Do dữ liệu quá lớn nên chỉ giữ lại 100.000 hàng dữ liệu chuyên sâu và điều kiện thị trường của từng cấp độ cũng được tách thành các cột riêng biệt.
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
python
tick_size = 0.0001
python
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
python
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
python
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
python
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
python
depths = depths.iloc[:100000]
python
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
python
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# 应用到每一行,得到新的df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# 在原有df上进行扩展
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
python
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
python
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
Trước tiên, hãy xem xét sự phân bổ của 20 điều kiện thị trường này. Nó phù hợp với kỳ vọng. Càng xa thời điểm mở cửa thị trường, càng có nhiều lệnh chờ, và lệnh mua và lệnh bán gần như đối xứng.
python
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
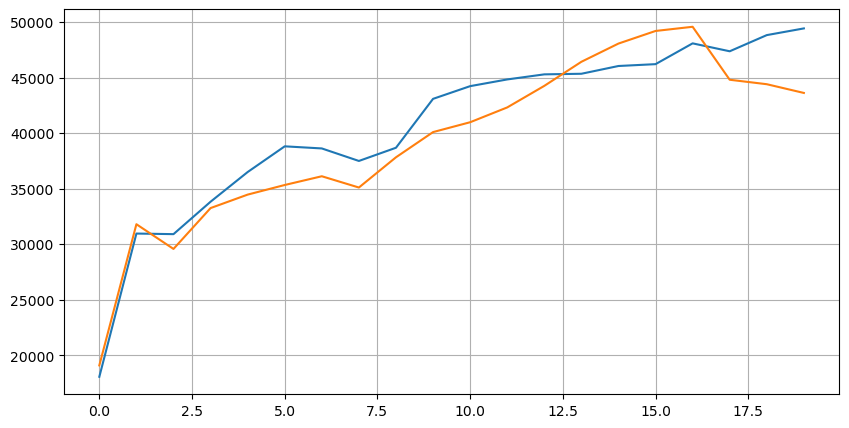
Kết hợp dữ liệu độ sâu và dữ liệu giao dịch để tạo điều kiện thuận lợi cho việc đánh giá độ chính xác của dự báo. Ở đây chúng tôi đảm bảo rằng dữ liệu giao dịch đều muộn hơn dữ liệu độ sâu. Không tính đến độ trễ, chúng tôi tính trực tiếp lỗi bình phương trung bình giữa giá trị dự đoán và giá giao dịch thực tế. Được sử dụng để đo độ chính xác của dự đoán.
Xét theo kết quả, lỗi của mid_price, giá trị trung bình của cặp mua-bán, là lớn nhất. Sau khi đổi thành weight_mid_price, lỗi ngay lập tức trở nên nhỏ hơn nhiều và được cải thiện hơn nữa bằng cách điều chỉnh giá giữa có trọng số. Sau khi bài viết ngày hôm qua được xuất bản, một số người báo cáo rằng họ chỉ sử dụng I^3/2. Tôi đã kiểm tra ở đây và thấy rằng kết quả tốt hơn. Sau khi suy nghĩ về lý do, nó phải là sự khác biệt về tần suất của các sự kiện. Khi I gần với -1 và 1, đó là một sự kiện có xác suất thấp. Để hiệu chỉnh các xác suất thấp này, dự đoán các sự kiện có tần suất cao không chính xác lắm. Do đó, để xử lý các sự kiện có tần suất cao, tôi đã thực hiện một số điều chỉnh (đây hoàn toàn là các thông số thử nghiệm và không hữu ích cho giao dịch thực tế):
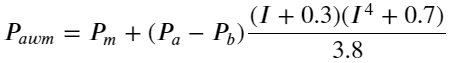
Kết quả thì tốt hơn một chút. Như đã đề cập trong bài viết trước, các chiến lược nên được dự đoán với nhiều dữ liệu hơn. Với dữ liệu sâu hơn và dữ liệu hoàn thành đơn hàng, sự cải thiện có thể đạt được bằng cách liên kết với giá thị trường đã rất yếu.
python
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
python
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
python
print('平均值 mid_price的误差:', ((df['price']-df['mid_price'])**2).sum())
print('挂单量加权 mid_price的误差:', ((df['price']-df['weight_mid_price'])**2).sum())
print('调整后的 mid_price的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的 mid_price_2的误差:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('调整后的 mid_price_3的误差:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
平均值 mid_price的误差: 0.0048751924999999845
挂单量加权 mid_price的误差: 0.0048373440193987035
调整后的 mid_price的误差: 0.004803654771638586
调整后的 mid_price_2的误差: 0.004808216498329721
调整后的 mid_price_3的误差: 0.004794984755260528
调整后的 mid_price_4的误差: 0.0047909595497071375
Hãy xem xét độ sâu của bánh răng thứ hai
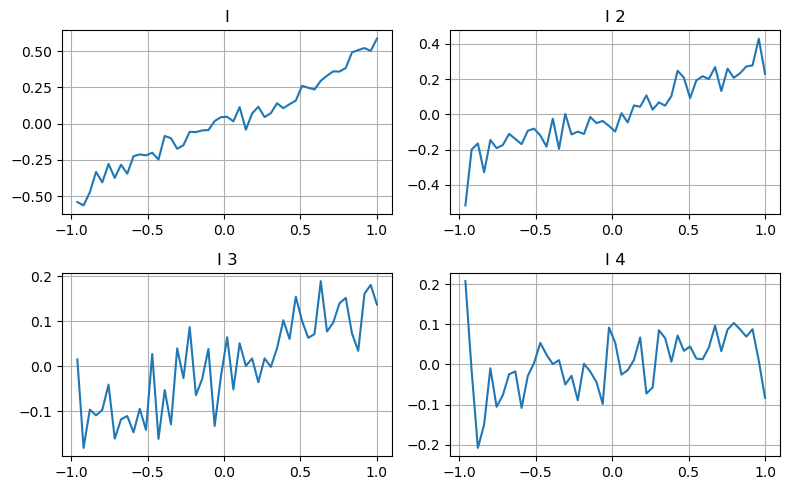
Ở đây chúng tôi sử dụng ý tưởng của bài viết trước để xem xét các phạm vi giá trị khác nhau của một tham số ảnh hưởng nhất định và những thay đổi trong giá giao dịch để đo lường sự đóng góp của tham số này vào giá trung bình. Như thể hiện trong biểu đồ độ sâu cấp độ đầu tiên, khi I tăng, giá giao dịch tiếp theo có nhiều khả năng thay đổi theo hướng tích cực, nghĩa là I có đóng góp tích cực.
Mẻ thứ hai được xử lý theo cách tương tự và thấy rằng mặc dù hiệu ứng nhỏ hơn một chút so với mẻ thứ nhất nhưng vẫn không đáng kể. Mức độ sâu thứ ba cũng có đóng góp nhỏ, nhưng tính đơn điệu tệ hơn nhiều, và độ sâu sâu hơn về cơ bản không có giá trị tham chiếu.
Theo các mức đóng góp khác nhau, các trọng số khác nhau được gán cho các tham số mất cân bằng của ba mức. Kiểm tra thực tế cho thấy các lỗi dự đoán được giảm thêm cho các phương pháp tính toán khác nhau.
python
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
python
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
python
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('调整后的 mid_price_5的误差:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('调整后的 mid_price_6的误差:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('调整后的 mid_price_7的误差:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('调整后的 mid_price_8的误差:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
调整后的 mid_price_4的误差: 0.0047909595497071375
调整后的 mid_price_5的误差: 0.0047884350488318714
调整后的 mid_price_6的误差: 0.0047778319053133735
调整后的 mid_price_7的误差: 0.004773578540592192
调整后的 mid_price_8的误差: 0.004771415189297518
Xem xét dữ liệu giao dịch
Dữ liệu giao dịch phản ánh trực tiếp mức độ vị thế dài và ngắn. Xét cho cùng, đây là một lựa chọn liên quan đến tiền thật, chi phí đặt lệnh thấp hơn nhiều, thậm chí còn có trường hợp cố tình gian lận đặt lệnh. Do đó, khi dự đoán giá trung bình, chiến lược nên tập trung vào dữ liệu giao dịch.
Xét về hình thức, định nghĩa mất cân bằng lượng lệnh đến trung bình VI, Vb, Vs lần lượt biểu diễn lượng lệnh mua và lệnh bán trung bình trên một đơn vị sự kiện.
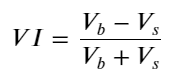
Kết quả cho thấy lượng hàng đến trong thời gian ngắn là yếu tố quan trọng nhất trong việc dự đoán sự thay đổi giá. Khi VI nằm trong khoảng (0,1-0,9) thì tương quan âm với giá, nhưng nằm ngoài phạm vi thì tương quan dương với giá. Điều này cho thấy rằng khi thị trường không cực đoan, nó chủ yếu được đặc trưng bởi các biến động và giá sẽ trở lại mức trung bình. Khi các điều kiện thị trường cực đoan xảy ra, chẳng hạn như số lượng lớn lệnh mua áp đảo lệnh bán, xu hướng sẽ di chuyển ra khỏi xu hướng . Ngay cả khi chúng ta bỏ qua những tình huống có xác suất thấp này và chỉ giả định rằng xu hướng và VI thỏa mãn mối quan hệ tuyến tính âm thì lỗi dự đoán của giá trung bình cũng giảm đáng kể. Chữ a trong công thức biểu thị hệ số.
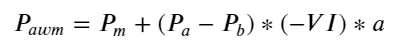
python
alpha=0.1
python
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
python
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
python
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
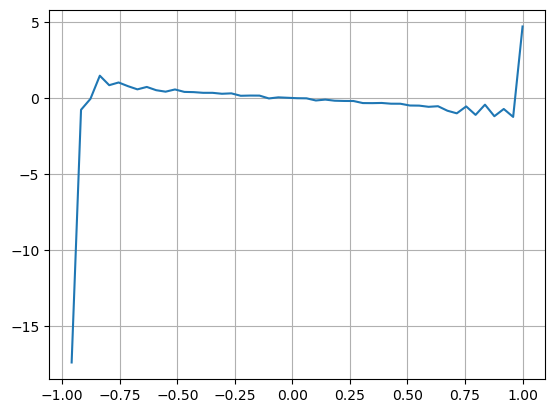
python
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
python
print('调整后的mid_price 的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的mid_price_9 的误差:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('调整后的mid_price_10的误差:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
调整后的mid_price 的误差: 0.0048373440193987035
调整后的mid_price_9 的误差: 0.004629586542840461
调整后的mid_price_10的误差: 0.004401790287167206
Giá trung bình toàn diện
Xem xét rằng cả lệnh chờ và dữ liệu giao dịch đều hữu ích cho việc dự đoán giá trung bình, hai tham số này có thể được kết hợp. Việc chỉ định trọng số ở đây là tùy ý và không xem xét các điều kiện biên. Trong những trường hợp cực đoan, giá trung bình dự đoán có thể là Không giữa mua một và bán một, nhưng miễn là có thể giảm thiểu được sai sót thì những chi tiết này không quan trọng.
Cuối cùng, lỗi dự đoán đã giảm từ 0,00487 ban đầu xuống 0,0043. Chúng tôi sẽ không đi sâu vào chi tiết ở đây. Vẫn còn nhiều điều cần khám phá về giá trung bình. Sau cùng, dự đoán giá trung bình chính là dự đoán giá. Bạn có thể tự mình thử .
python
#注意VI需要延后一个使用
df['price_change'] = np.log(df['price']/df['price'].rolling(40).mean())
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3 + 150*df['price_change'].shift(1)
python
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('调整后的mid_price_11的误差:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
调整后的mid_price_11的误差: 0.00421125960463469
Tóm tắt
Bài báo này kết hợp dữ liệu độ sâu và dữ liệu giao dịch để cải thiện hơn nữa phương pháp tính giá trung bình. Bài báo này cung cấp phương pháp đo độ chính xác và cải thiện độ chính xác của việc dự đoán thay đổi giá. Nhìn chung, các thông số khác nhau không thực sự chặt chẽ và chỉ mang tính chất tham khảo. Với mức giá trung bình chính xác hơn, bước tiếp theo là thực sự áp dụng mức giá trung bình để kiểm tra ngược. Phần này cũng có nhiều nội dung, vì vậy chúng tôi sẽ ngừng cập nhật trong một thời gian.


