

Trong bài viết này, chúng tôi sẽ viết một chiến lược giao dịch trong ngày. Nó sẽ sử dụng khái niệm giao dịch cổ điển là “cặp giao dịch hồi quy trung bình”. Trong ví dụ này, chúng tôi sẽ sử dụng hai quỹ giao dịch trên sàn (ETF), SPY và IWM, được giao dịch trên Sàn giao dịch chứng khoán New York (NYSE) và cố gắng đại diện cho các chỉ số thị trường chứng khoán Hoa Kỳ, S&P 500 và Russell 2000. .
Chiến lược này tạo ra "lợi thế chênh lệch" bằng cách mua một ETF và bán một ETF khác. Tỷ lệ dài-ngắn có thể được xác định theo nhiều cách, ví dụ như sử dụng phương pháp chuỗi thời gian đồng tích hợp thống kê. Trong kịch bản này, chúng ta sẽ tính tỷ lệ phòng ngừa giữa SPY và IWM thông qua hồi quy tuyến tính lăn. Điều này sẽ cho phép chúng ta tạo ra một “khoảng chênh lệch” giữa SPY và IWM được chuẩn hóa theo điểm số z. Khi điểm z vượt quá ngưỡng nhất định, tín hiệu giao dịch sẽ được tạo ra vì chúng tôi tin rằng "chênh lệch" này sẽ trở lại mức trung bình.
Cơ sở cho chiến lược này là cả SPY và IWM đều đại diện cho cùng một kịch bản thị trường, cụ thể là hiệu suất giá cổ phiếu của một nhóm các công ty lớn và nhỏ tại Hoa Kỳ. Tiền đề là nếu bạn chấp nhận lý thuyết "trở lại giá trung bình" của giá cả, thì nó sẽ luôn trở lại, bởi vì "các sự kiện" có thể ảnh hưởng đến S&P500 và Russell 2000 riêng biệt trong một khoảng thời gian rất ngắn, nhưng "chênh lệch lãi suất" giữa chúng sẽ luôn trở lại mức trung bình bình thường và chuỗi giá dài hạn của cả hai luôn luôn đồng tích hợp.
Chiến lược
Chiến lược được thực hiện như sau:
Dữ liệu - Nhận biểu đồ nến 1 phút của SPY và IWM từ tháng 4 năm 2007 đến tháng 2 năm 2014.
Xử lý - Căn chỉnh dữ liệu một cách chính xác và xóa các thanh bị thiếu. (Nếu thiếu một mặt thì cả hai mặt sẽ bị xóa)
Chênh lệch - Tỷ lệ phòng ngừa rủi ro giữa hai ETF được tính toán bằng hồi quy tuyến tính lăn. Được xác định là hệ số hồi quy beta sử dụng cửa sổ nhìn lại được dịch chuyển về phía trước 1 thanh và hệ số hồi quy được tính toán lại. Do đó, tỷ lệ phòng ngừa βi, bi K-line được sử dụng để theo dõi K-line bằng cách tính toán điểm giao nhau từ bi-1-k đến bi-1.
Điểm Z - Giá trị của Chênh lệch chuẩn được tính theo cách thông thường. Điều này có nghĩa là trừ đi giá trị trung bình của độ chênh lệch (mẫu) và chia cho độ lệch chuẩn của độ chênh lệch (mẫu). Lý do để làm như vậy là để hiểu tham số ngưỡng dễ hơn vì Điểm Z là một đại lượng không có đơn vị. Tôi cố tình đưa "thiên kiến nhìn trước" vào các phép tính để cho thấy nó tinh vi đến mức nào. Hãy thử xem!
Giao dịch - Tín hiệu mua được tạo ra khi giá trị điểm z âm giảm xuống dưới ngưỡng được xác định trước (hoặc sau khi tối ưu hóa), trong khi tín hiệu bán được tạo ra theo cách ngược lại. Khi giá trị tuyệt đối của điểm z giảm xuống dưới ngưỡng bổ sung, tín hiệu đóng vị thế sẽ được tạo ra. Đối với chiến lược này, tôi (khá tùy ý) chọn |z| = 2 làm ngưỡng vào và |z| = 1 làm ngưỡng thoát. Giả sử sự hồi quy trung bình đóng vai trò trong sự chênh lệch giá, hy vọng những điều trên sẽ nắm bắt được mối quan hệ chênh lệch giá này và mang lại lợi nhuận tốt.
Có lẽ cách tốt nhất để hiểu sâu sắc một chiến lược là thực sự triển khai nó. Phần sau đây trình bày chi tiết mã Python hoàn chỉnh (tệp đơn) được sử dụng để triển khai chiến lược hoàn nguyên trung bình này. Tôi đã thêm các chú thích mã chi tiết để giúp bạn hiểu rõ hơn.
Triển khai Python
Giống như tất cả các hướng dẫn về Python/pandas, môi trường Python của bạn phải được thiết lập như mô tả trong hướng dẫn này. Sau khi thiết lập hoàn tất, nhiệm vụ đầu tiên là nhập các thư viện Python cần thiết. Điều này là bắt buộc khi sử dụng matplotlib và pandas.
Các phiên bản thư viện cụ thể mà tôi đang sử dụng như sau:
Python - 2.7.3
NumPy - 1.8.0
pandas - 0.12.0
matplotlib - 1.1.0
Chúng ta hãy tiếp tục và nhập các thư viện này:
# mr_spy_iwm.py
import matplotlib.pyplot as plt
import numpy as np
import os, os.path
import pandas as pd
Hàm create_pairs_dataframe sau đây sẽ nhập hai tệp CSV chứa nến trong ngày của hai biểu tượng. Trong trường hợp của chúng tôi, đó sẽ là SPY và IWM. Sau đó, nó tạo ra một "cặp khung dữ liệu" riêng biệt sử dụng chỉ mục của cả hai tệp gốc. Dấu thời gian của chúng có thể thay đổi do giao dịch bị bỏ lỡ và lỗi. Đây là một trong những lợi ích chính của việc sử dụng thư viện phân tích dữ liệu như pandas. Chúng tôi xử lý mã "chuẩn" theo cách rất hiệu quả.
# mr_spy_iwm.py
def create_pairs_dataframe(datadir, symbols):
"""Creates a pandas DataFrame containing the closing price
of a pair of symbols based on CSV files containing a datetime
stamp and OHLCV data."""
# Open the individual CSV files and read into pandas DataFrames
print "Importing CSV data..."
sym1 = pd.io.parsers.read_csv(os.path.join(datadir, '%s.csv' % symbols[0]),
header=0, index_col=0,
names=['datetime','open','high','low','close','volume','na'])
sym2 = pd.io.parsers.read_csv(os.path.join(datadir, '%s.csv' % symbols[1]),
header=0, index_col=0,
names=['datetime','open','high','low','close','volume','na'])
# Create a pandas DataFrame with the close prices of each symbol
# correctly aligned and dropping missing entries
print "Constructing dual matrix for %s and %s..." % symbols
pairs = pd.DataFrame(index=sym1.index)
pairs['%s_close' % symbols[0].lower()] = sym1['close']
pairs['%s_close' % symbols[1].lower()] = sym2['close']
pairs = pairs.dropna()
return pairs
Bước tiếp theo là thực hiện hồi quy tuyến tính lăn giữa SPY và IWM. Trong trường hợp này, IWM là yếu tố dự báo ('x') và SPY là yếu tố phản hồi ('y'). Tôi đặt cửa sổ nhìn lại mặc định là 100 nến. Như đã đề cập ở trên, đây là các thông số của chiến lược. Để một chiến lược được coi là mạnh mẽ, lý tưởng nhất là chúng ta muốn thấy báo cáo lợi nhuận lồi trong suốt thời gian nhìn lại (hoặc một số thước đo hiệu suất khác). Do đó, ở giai đoạn sau của mã, chúng tôi sẽ thực hiện phân tích độ nhạy bằng cách thay đổi khoảng thời gian nhìn lại trong phạm vi.
Sau khi tính toán hệ số beta lăn trong mô hình hồi quy tuyến tính cho SPY-IWM, hãy thêm nó vào cặp DataFrame và xóa các hàng trống. Điều này xây dựng bộ nến đầu tiên, bằng với phép đo cắt bớt của độ dài nhìn lại. Sau đó, chúng tôi tạo ra mức chênh lệch giữa hai ETF, một đơn vị SPY và một đơn vị -βi của IWM. Rõ ràng, đây không phải là một kịch bản thực tế vì chúng ta chỉ sử dụng một lượng nhỏ IWM, điều này là không thể thực hiện được trong thực tế.
Cuối cùng, chúng ta tạo ra điểm số z của mức chênh lệch, được tính bằng cách trừ đi giá trị trung bình của mức chênh lệch và chuẩn hóa theo độ lệch chuẩn của mức chênh lệch. Điều quan trọng cần lưu ý là có một "khuynh hướng thiên về tương lai" khá tinh vi đang diễn ra ở đây. Tôi cố ý giữ nguyên điều này trong mã vì muốn nhấn mạnh rằng việc mắc lỗi như thế này trong nghiên cứu dễ dàng như thế nào. Tính giá trị trung bình và độ lệch chuẩn của toàn bộ chuỗi thời gian phân tán. Nếu điều này nhằm phản ánh tính chính xác lịch sử thực sự thì không thể thu thập được thông tin này vì nó ngầm sử dụng thông tin từ tương lai. Do đó, chúng ta nên sử dụng giá trị trung bình động và độ lệch chuẩn để tính điểm z.
# mr_spy_iwm.py
def calculate_spread_zscore(pairs, symbols, lookback=100):
"""Creates a hedge ratio between the two symbols by calculating
a rolling linear regression with a defined lookback period. This
is then used to create a z-score of the 'spread' between the two
symbols based on a linear combination of the two."""
# Use the pandas Ordinary Least Squares method to fit a rolling
# linear regression between the two closing price time series
print "Fitting the rolling Linear Regression..."
model = pd.ols(y=pairs['%s_close' % symbols[0].lower()],
x=pairs['%s_close' % symbols[1].lower()],
window=lookback)
# Construct the hedge ratio and eliminate the first
# lookback-length empty/NaN period
pairs['hedge_ratio'] = model.beta['x']
pairs = pairs.dropna()
# Create the spread and then a z-score of the spread
print "Creating the spread/zscore columns..."
pairs['spread'] = pairs['spy_close'] - pairs['hedge_ratio']*pairs['iwm_close']
pairs['zscore'] = (pairs['spread'] - np.mean(pairs['spread']))/np.std(pairs['spread'])
return pairs
Trong create_long_short_market_signals, tạo tín hiệu giao dịch. Những giá trị này được tính toán bằng cách đo giá trị điểm z vượt quá ngưỡng. Khi giá trị tuyệt đối của điểm z nhỏ hơn hoặc bằng ngưỡng khác (nhỏ hơn), tín hiệu đóng vị thế sẽ được đưa ra.
Để đạt được điều này, cần phải xác định xem chiến lược giao dịch là "mở" hay "đóng" cho mỗi đường K. Long_market và short_market là hai biến được định nghĩa để theo dõi các vị thế mua và bán. Thật không may, phương pháp này chậm về mặt tính toán vì lập trình theo cách lặp lại đơn giản hơn nhiều so với phương pháp vectơ hóa. Mặc dù biểu đồ nến 1 phút cần khoảng 700.000 điểm dữ liệu cho mỗi tệp CSV, nhưng vẫn có thể tính toán tương đối nhanh trên máy tính để bàn cũ của tôi!
Để lặp lại một pandas DataFrame (một hoạt động khá hiếm gặp), cần phải sử dụng phương thức iterrows, phương thức này cung cấp một trình tạo lặp lại:
# mr_spy_iwm.py
def create_long_short_market_signals(pairs, symbols,
z_entry_threshold=2.0,
z_exit_threshold=1.0):
"""Create the entry/exit signals based on the exceeding of
z_enter_threshold for entering a position and falling below
z_exit_threshold for exiting a position."""
# Calculate when to be long, short and when to exit
pairs['longs'] = (pairs['zscore'] <= -z_entry_threshold)*1.0
pairs['shorts'] = (pairs['zscore'] >= z_entry_threshold)*1.0
pairs['exits'] = (np.abs(pairs['zscore']) <= z_exit_threshold)*1.0
# These signals are needed because we need to propagate a
# position forward, i.e. we need to stay long if the zscore
# threshold is less than z_entry_threshold by still greater
# than z_exit_threshold, and vice versa for shorts.
pairs['long_market'] = 0.0
pairs['short_market'] = 0.0
# These variables track whether to be long or short while
# iterating through the bars
long_market = 0
short_market = 0
# Calculates when to actually be "in" the market, i.e. to have a
# long or short position, as well as when not to be.
# Since this is using iterrows to loop over a dataframe, it will
# be significantly less efficient than a vectorised operation,
# i.e. slow!
print "Calculating when to be in the market (long and short)..."
for i, b in enumerate(pairs.iterrows()):
# Calculate longs
if b[1]['longs'] == 1.0:
long_market = 1
# Calculate shorts
if b[1]['shorts'] == 1.0:
short_market = 1
# Calculate exists
if b[1]['exits'] == 1.0:
long_market = 0
short_market = 0
# This directly assigns a 1 or 0 to the long_market/short_market
# columns, such that the strategy knows when to actually stay in!
pairs.ix[i]['long_market'] = long_market
pairs.ix[i]['short_market'] = short_market
return pairs
Ở giai đoạn này, chúng tôi cập nhật các cặp để chứa các tín hiệu dài và ngắn thực tế, cho phép chúng tôi xác định xem có cần mở vị thế hay không. Bây giờ chúng ta cần tạo một danh mục đầu tư để theo dõi giá trị thị trường của các vị thế. Nhiệm vụ đầu tiên là tạo một cột vị trí kết hợp các tín hiệu dài và ngắn. Danh sách này sẽ chứa các phần tử từ (1,0,-1) trong đó 1 biểu thị vị thế mua, 0 biểu thị không có vị thế nào (cần phải đóng) và -1 biểu thị vị thế bán. Cột sym1 và sym2 biểu thị giá trị thị trường của các vị thế SPY và IWM vào cuối mỗi nến.
Sau khi giá trị thị trường ETF được tạo ra, chúng tôi sẽ cộng chúng lại để tạo ra tổng giá trị thị trường vào cuối mỗi nến. Sau đó, nó được chuyển đổi thành giá trị trả về thông qua phương thức pct_change của đối tượng đó. Các dòng mã tiếp theo sẽ dọn sạch các mục nhập lỗi (các phần tử NaN và inf) và cuối cùng tính toán đường cong vốn chủ sở hữu hoàn chỉnh.
# mr_spy_iwm.py
def create_portfolio_returns(pairs, symbols):
"""Creates a portfolio pandas DataFrame which keeps track of
the account equity and ultimately generates an equity curve.
This can be used to generate drawdown and risk/reward ratios."""
# Convenience variables for symbols
sym1 = symbols[0].lower()
sym2 = symbols[1].lower()
# Construct the portfolio object with positions information
# Note that minuses to keep track of shorts!
print "Constructing a portfolio..."
portfolio = pd.DataFrame(index=pairs.index)
portfolio['positions'] = pairs['long_market'] - pairs['short_market']
portfolio[sym1] = -1.0 * pairs['%s_close' % sym1] * portfolio['positions']
portfolio[sym2] = pairs['%s_close' % sym2] * portfolio['positions']
portfolio['total'] = portfolio[sym1] + portfolio[sym2]
# Construct a percentage returns stream and eliminate all
# of the NaN and -inf/+inf cells
print "Constructing the equity curve..."
portfolio['returns'] = portfolio['total'].pct_change()
portfolio['returns'].fillna(0.0, inplace=True)
portfolio['returns'].replace([np.inf, -np.inf], 0.0, inplace=True)
portfolio['returns'].replace(-1.0, 0.0, inplace=True)
# Calculate the full equity curve
portfolio['returns'] = (portfolio['returns'] + 1.0).cumprod()
return portfolio
Chức năng chính là liên kết tất cả lại với nhau. Các tệp CSV trong ngày nằm trong đường dẫn datadir. Hãy chắc chắn sửa đổi đoạn mã sau để trỏ đến thư mục cụ thể của bạn.
Để xác định mức độ nhạy cảm của chiến lược với giai đoạn nhìn lại, cần phải tính toán một loạt các số liệu đánh giá hiệu suất nhìn lại. Tôi đã chọn tỷ lệ lợi nhuận tổng thể cuối cùng của danh mục đầu tư làm thước đo hiệu suất và phạm vi nhìn lại.[50,200] với mức tăng là 10. Bạn có thể thấy trong đoạn mã bên dưới rằng hàm trước đó được bao bọc trong một vòng lặp for trên phạm vi này và các ngưỡng khác vẫn giữ nguyên. Nhiệm vụ cuối cùng là tạo biểu đồ đường biểu diễn giá trị nhìn lại so với giá trị trả về bằng matplotlib:
# mr_spy_iwm.py
if __name__ == "__main__":
datadir = '/your/path/to/data/' # Change this to reflect your data path!
symbols = ('SPY', 'IWM')
lookbacks = range(50, 210, 10)
returns = []
# Adjust lookback period from 50 to 200 in increments
# of 10 in order to produce sensitivities
for lb in lookbacks:
print "Calculating lookback=%s..." % lb
pairs = create_pairs_dataframe(datadir, symbols)
pairs = calculate_spread_zscore(pairs, symbols, lookback=lb)
pairs = create_long_short_market_signals(pairs, symbols,
z_entry_threshold=2.0,
z_exit_threshold=1.0)
portfolio = create_portfolio_returns(pairs, symbols)
returns.append(portfolio.ix[-1]['returns'])
print "Plot the lookback-performance scatterchart..."
plt.plot(lookbacks, returns, '-o')
plt.show()
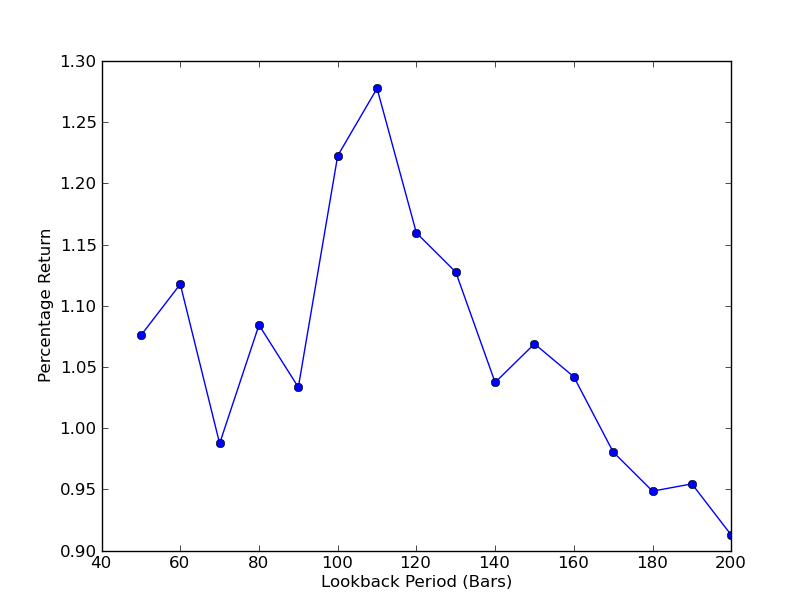
Bây giờ bạn có thể thấy biểu đồ về số liệu nhìn lại và lợi nhuận. Lưu ý rằng có một mức tối đa "toàn cầu" cho việc xem lại, bằng 110 thanh. Nếu chúng ta thấy một tình huống mà việc xem lại không liên quan gì đến lợi nhuận thì đó là do:
Phân tích độ nhạy của tỷ lệ phòng ngừa hồi quy tuyến tính SPY-IWM
Không có bài viết kiểm tra ngược nào có thể hoàn thiện nếu thiếu đường cong lợi nhuận dốc lên! Vì vậy, nếu bạn muốn biểu đồ lợi nhuận tích lũy theo thời gian, bạn có thể sử dụng mã sau. Nó sẽ vẽ biểu đồ danh mục đầu tư cuối cùng được tạo ra từ nghiên cứu tham số nhìn lại. Do đó, cần phải chọn chế độ xem lại theo biểu đồ mà bạn muốn trực quan hóa. Biểu đồ này cũng thể hiện lợi nhuận của SPY trong cùng kỳ để hỗ trợ việc so sánh:
# mr_spy_iwm.py
# This is still within the main function
print "Plotting the performance charts..."
fig = plt.figure()
fig.patch.set_facecolor('white')
ax1 = fig.add_subplot(211, ylabel='%s growth (%%)' % symbols[0])
(pairs['%s_close' % symbols[0].lower()].pct_change()+1.0).cumprod().plot(ax=ax1, color='r', lw=2.)
ax2 = fig.add_subplot(212, ylabel='Portfolio value growth (%%)')
portfolio['returns'].plot(ax=ax2, lw=2.)
fig.show()
Biểu đồ đường cong vốn chủ sở hữu bên dưới có thời gian nhìn lại là 100 ngày:
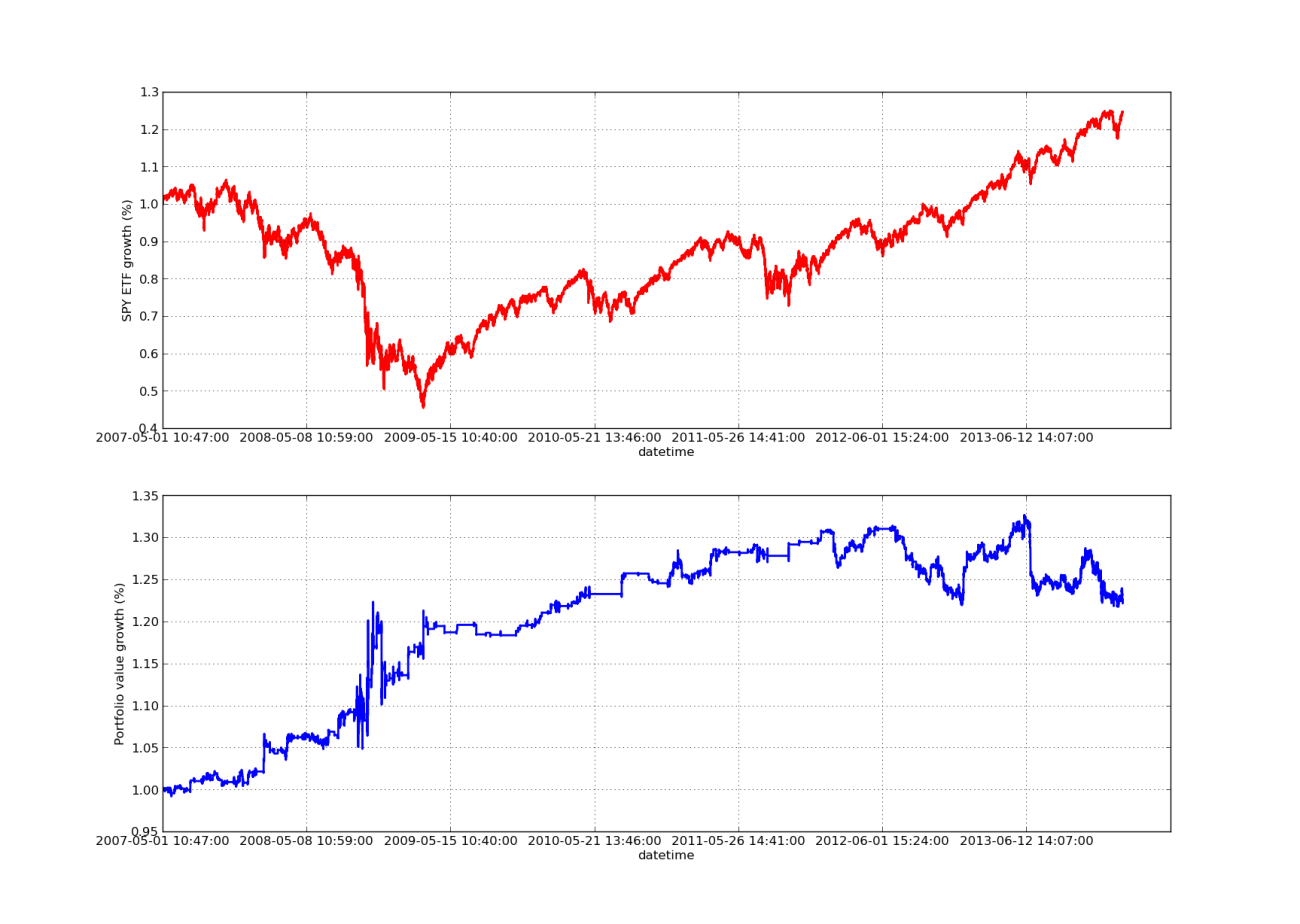
Phân tích độ nhạy của tỷ lệ phòng ngừa hồi quy tuyến tính SPY-IWM
Lưu ý rằng mức giảm của SPY khá lớn vào năm 2009 trong cuộc khủng hoảng tài chính. Chiến lược cũng đang trong giai đoạn hỗn loạn. Ngoài ra, lưu ý rằng hiệu suất đã giảm sút trong năm qua do bản chất xu hướng mạnh mẽ của SPY trong giai đoạn này phản ánh S&P 500.
Lưu ý rằng chúng ta vẫn cần tính đến “sai số dự đoán” khi tính toán mức chênh lệch điểm z. Hơn nữa, tất cả các tính toán này đều được thực hiện mà không mất chi phí giao dịch. Khi những yếu tố này được tính đến, chiến lược này chắc chắn sẽ không hiệu quả. Hiện tại, cả phí và mức trượt giá đều chưa được xác định. Ngoài ra, chiến lược này giao dịch theo từng đơn vị ETF, điều này cũng rất không thực tế.
Trong bài viết sau, chúng tôi sẽ tạo ra một công cụ kiểm tra ngược theo sự kiện phức tạp hơn, có thể tính đến tất cả những điều trên, giúp chúng tôi tự tin hơn vào đường cong vốn chủ sở hữu và các chỉ số hiệu suất của mình.
- 1