

Giao dịch theo cặp là một ví dụ tuyệt vời về việc phát triển chiến lược giao dịch dựa trên phân tích toán học. Trong bài viết này, chúng tôi sẽ trình bày cách tận dụng dữ liệu để tạo và tự động hóa chiến lược giao dịch theo cặp.
Nguyên tắc cơ bản
Giả sử bạn có một cặp khoản đầu tư X và Y có một số mối tương quan cơ bản, chẳng hạn như cả hai công ty đều sản xuất cùng một sản phẩm, chẳng hạn như Pepsi và Coca-Cola. Bạn muốn tỷ lệ giá hoặc cơ sở (còn gọi là chênh lệch) giữa hai loại này luôn ổn định theo thời gian. Tuy nhiên, chênh lệch giữa hai cặp tiền này có thể khác nhau tùy từng thời điểm do những thay đổi tạm thời về cung và cầu, chẳng hạn như lệnh mua/bán lớn cho một mục tiêu đầu tư, phản ứng với tin tức quan trọng về một trong các công ty, v.v. Trong trường hợp này, một khoản đầu tư tăng lên và khoản đầu tư còn lại giảm xuống so với nhau. Nếu bạn mong đợi sự phân kỳ này sẽ bình thường hóa theo thời gian, bạn có thể phát hiện ra cơ hội giao dịch (hoặc cơ hội chênh lệch giá). Những cơ hội kinh doanh chênh lệch giá như vậy xuất hiện ở khắp mọi nơi trên thị trường tiền kỹ thuật số hoặc thị trường tương lai hàng hóa trong nước, chẳng hạn như mối quan hệ giữa BTC và tài sản trú ẩn an toàn; mối quan hệ giữa bột đậu nành, dầu đậu nành và các loại đậu nành trong tương lai.
Khi có sự chênh lệch giá tạm thời, giao dịch sẽ bán khoản đầu tư có hiệu suất cao hơn (khoản đầu tư đã tăng) và mua khoản đầu tư có hiệu suất thấp hơn (khoản đầu tư đã giảm). Bạn có thể chắc chắn rằng có sự chênh lệch giữa hai khoản đầu tư. chênh lệch cuối cùng sẽ được phản ánh bằng khoản đầu tư hiệu quả hơn giảm trở lại hoặc khoản đầu tư kém hiệu quả tăng trở lại, hoặc cả hai. Giao dịch của bạn sẽ kiếm được tiền trong tất cả các tình huống này. Nếu các khoản đầu tư cùng tăng hoặc cùng giảm mà không thay đổi chênh lệch giữa chúng, bạn sẽ không kiếm được hoặc mất tiền.
Do đó, giao dịch theo cặp là chiến lược giao dịch trung lập với thị trường, cho phép các nhà giao dịch kiếm lợi nhuận từ hầu hết mọi điều kiện thị trường: xu hướng tăng, xu hướng giảm hoặc đi ngang.
Giải thích khái niệm: hai mục tiêu đầu tư giả định
- Xây dựng môi trường nghiên cứu của chúng tôi trên Nền tảng định lượng Inventor
Trước hết, để công việc được trôi chảy, chúng ta cần xây dựng môi trường nghiên cứu của mình. Trong bài viết này, chúng tôi sử dụng Inventor Quantitative Platform (FMZ.COM) để xây dựng môi trường nghiên cứu, chủ yếu là để chúng tôi có thể sử dụng API thuận tiện và nhanh chóng giao diện và đóng gói nền tảng này sau. Hệ thống Docker hoàn chỉnh.
Trong tên chính thức của Inventor Quantitative Platform, hệ thống Docker này được gọi là hệ thống lưu trữ.
Để biết thêm thông tin về cách triển khai máy chủ và rô-bốt, vui lòng tham khảo bài viết trước của tôi: https://www.fmz.com/bbs-topic/4140
Bạn đọc muốn mua máy chủ triển khai điện toán đám mây riêng có thể tham khảo bài viết này: https://www.fmz.com/bbs-topic/2848
Sau khi triển khai thành công dịch vụ điện toán đám mây và hệ thống máy chủ, chúng ta sẽ cài đặt công cụ Python mạnh mẽ nhất: Anaconda
Để có được tất cả các môi trường chương trình có liên quan cần thiết cho bài viết này (thư viện phụ thuộc, quản lý phiên bản, v.v.), cách dễ nhất là sử dụng Anaconda. Đây là hệ sinh thái khoa học dữ liệu Python được đóng gói và trình quản lý phụ thuộc.
Để biết phương pháp cài đặt Anaconda, vui lòng tham khảo hướng dẫn chính thức của Anaconda: https://www.anaconda.com/distribution/
Bài viết này cũng sẽ sử dụng numpy và pandas, hai thư viện rất phổ biến và quan trọng trong khoa học tính toán Python.
Đối với công việc cơ bản trên, bạn cũng có thể tham khảo bài viết trước của tôi, trong đó giới thiệu cách thiết lập môi trường Anaconda và hai thư viện numpy và pandas. Để biết chi tiết, vui lòng xem: https://www.fmz.com/digest- chủ đề/4169
Tiếp theo, chúng ta hãy sử dụng mã để triển khai "hai mục tiêu đầu tư giả định"
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
Có, chúng ta cũng sẽ sử dụng matplotlib, một thư viện biểu đồ rất nổi tiếng trong Python.
Hãy tạo ra một tài sản đầu tư giả định X và mô phỏng việc biểu diễn lợi nhuận hàng ngày của nó bằng cách sử dụng phân phối chuẩn. Sau đó, chúng tôi thực hiện tính tổng tích lũy để có được giá trị X hàng ngày.
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
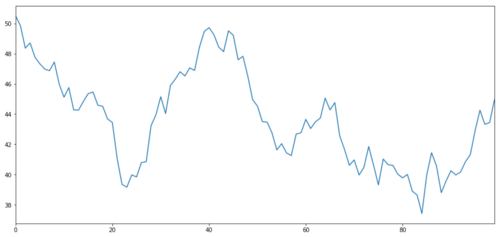
Mục tiêu đầu tư X, mô phỏng và rút ra lợi nhuận hàng ngày của nó thông qua phân phối chuẩn
Bây giờ chúng ta tạo ra Y có mối tương quan chặt chẽ với X, do đó giá của Y sẽ thay đổi rất giống với những thay đổi trong X. Chúng tôi mô hình hóa điều này bằng cách lấy X, dịch chuyển nó lên và thêm một số nhiễu ngẫu nhiên lấy từ phân phối chuẩn.
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
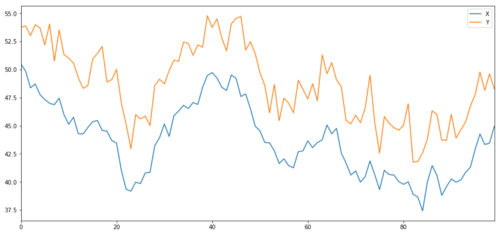
Đồng tích hợp mục tiêu đầu tư X và Y
Sự đồng tích hợp
Đồng tích hợp rất giống với tương quan, nghĩa là tỷ lệ giữa hai chuỗi dữ liệu sẽ thay đổi quanh giá trị trung bình. Hai chuỗi Y và X tuân theo quy tắc sau:
Y = ⍺ X + e
trong đó ⍺ là tỉ lệ hằng số và e là nhiễu.
Đối với cặp giao dịch giữa hai chuỗi thời gian, giá trị kỳ vọng của tỷ lệ theo thời gian phải hội tụ về giá trị trung bình, tức là chúng phải được tích hợp đồng thời. Chuỗi thời gian chúng tôi xây dựng ở trên là chuỗi thời gian đồng tích hợp. Bây giờ chúng ta sẽ vẽ tỷ lệ giữa hai hình này để có thể thấy nó sẽ trông như thế nào.
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
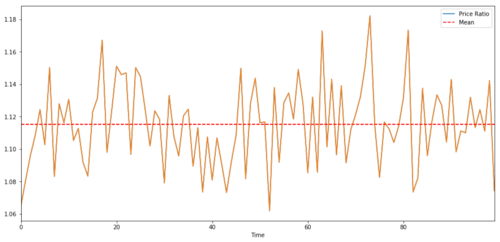
Tỷ lệ và giá trung bình của hai khoản đầu tư đồng tích hợp
Kiểm tra đồng tích hợp
Một cách thuận tiện để kiểm tra điều này là sử dụng statsmodels.tsa.stattools. Chúng ta sẽ thấy giá trị p rất thấp vì chúng ta đã tạo ra hai chuỗi dữ liệu có sự đồng tích hợp nhất định.
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
Kết quả là: 1.81864477307e-17
Lưu ý: Tương quan và Đồng tích hợp
Mặc dù tương quan và đồng tích hợp về mặt lý thuyết là tương tự nhau, nhưng chúng không giống nhau. Hãy cùng xem xét các ví dụ về chuỗi dữ liệu có tương quan nhưng không đồng tích hợp và ngược lại. Đầu tiên, hãy kiểm tra mối tương quan của chuỗi dữ liệu mà chúng ta vừa tạo ra.
X.corr(Y)
Kết quả là: 0,951
Như chúng tôi dự đoán, con số này rất cao. Nhưng còn hai chuỗi có tương quan nhưng không đồng tích hợp thì sao? Một ví dụ đơn giản là hai chuỗi dữ liệu phân kỳ.
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
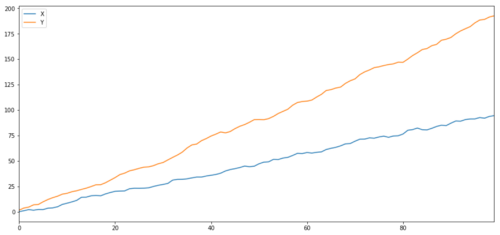
Hai chuỗi liên quan (không tích hợp đồng thời)
Hệ số tương quan: 0,998
Giá trị p của kiểm định đồng tích hợp: 0,258
Ví dụ đơn giản về đồng tích hợp không có tương quan là chuỗi phân phối chuẩn và sóng vuông.
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
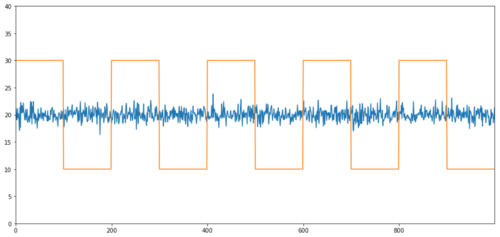
Tương quan: 0,007546
Giá trị p của kiểm định đồng tích hợp: 0,0
Mức tương quan rất thấp, nhưng giá trị p cho thấy sự đồng tích hợp hoàn hảo!
Làm thế nào để thực hiện giao dịch theo cặp?
Do hai chuỗi thời gian đồng tích hợp (như X và Y ở trên) di chuyển gần nhau và xa nhau nên có những thời điểm có cơ sở cao và có cơ sở thấp. Chúng tôi thực hiện giao dịch theo cặp bằng cách mua một khoản đầu tư và bán một khoản đầu tư khác. Theo cách này, nếu hai mục tiêu đầu tư cùng giảm hoặc cùng tăng, chúng ta sẽ không kiếm được tiền cũng không mất tiền, tức là chúng ta trung lập với thị trường.
Quay lại X và Y trong Y = ⍺ X + e ở trên, chúng ta kiếm tiền bằng cách làm cho tỷ lệ (Y/X) di chuyển xung quanh giá trị trung bình ⍺ của nó. Để làm điều này, chúng ta lưu ý rằng khi X Khi giá trị của ⍺ quá cao hoặc quá thấp, giá trị của ⍺ quá cao hoặc quá thấp:
-
Tỷ lệ dài: Đây là khi tỷ lệ ⍺ nhỏ và chúng ta mong đợi nó sẽ lớn hơn. Trong ví dụ trên, chúng ta mở một vị thế bằng cách mua Y và bán X.
-
Tỷ lệ ngắn: Đây là khi tỷ lệ ⍺ lớn và chúng tôi kỳ vọng nó sẽ trở nên nhỏ hơn. Trong ví dụ trên, chúng ta mở một vị thế bằng cách bán khống Y và mua vào X.
Lưu ý rằng chúng ta luôn có “vị thế phòng ngừa”: nếu vị thế mua cơ bản mất giá, vị thế bán sẽ kiếm được tiền và ngược lại, do đó chúng ta không bị ảnh hưởng bởi biến động chung của thị trường.
Khi tài sản X và Y di chuyển tương đối với nhau, chúng ta sẽ kiếm được tiền hoặc mất tiền.
Sử dụng dữ liệu để tìm các giao dịch có hành vi tương tự
Cách tốt nhất để thực hiện điều này là bắt đầu với các giao dịch mà bạn nghi ngờ có thể có sự kết hợp và thực hiện các thử nghiệm thống kê. Nếu bạn thực hiện một thử nghiệm thống kê trên tất cả các cặp giao dịch, bạn sẽSai lệch so sánh nhiềunạn nhân của.
Sai lệch so sánh nhiềuđề cập đến tình huống mà khả năng tạo ra giá trị p đáng kể một cách sai lệch tăng lên khi chạy nhiều thử nghiệm, vì chúng ta cần chạy một số lượng lớn các thử nghiệm. Nếu chúng ta chạy thử nghiệm này 100 lần trên dữ liệu ngẫu nhiên, chúng ta sẽ thấy 5 giá trị p dưới 0,05. Nếu bạn đang so sánh n công cụ để đồng tích hợp, bạn sẽ thực hiện n(n-1)/2 phép so sánh và bạn sẽ thấy nhiều giá trị p không chính xác, giá trị này sẽ tăng lên khi quy mô mẫu thử nghiệm của bạn tăng lên. Và tăng lên. Để tránh điều này, hãy chọn một vài cặp giao dịch mà bạn có lý do để tin rằng có khả năng tích hợp chung, sau đó thử nghiệm từng cặp. Điều này sẽ làm giảm đáng kểSai lệch so sánh nhiều。
Vậy hãy thử tìm một số công cụ thể hiện sự đồng tích hợp. Hãy lấy một rổ cổ phiếu công nghệ vốn hóa lớn của Hoa Kỳ trong S&P 500. Các công cụ này hoạt động trong các phân khúc thị trường tương tự và thể hiện sự đồng tích hợp. giá. Chúng tôi quét danh sách các công cụ giao dịch và kiểm tra tính đồng nhất giữa tất cả các cặp.
Ma trận điểm kiểm tra đồng tích hợp được trả về, ma trận giá trị p và tất cả các kết quả khớp từng cặp có giá trị p nhỏ hơn 0,05 đều được bao gồm.Phương pháp này dễ dẫn đến sai lệch khi so sánh nhiều lần, do đó trên thực tế họ cần phải thực hiện xác thực lần thứ hai. Trong bài viết này, để thuận tiện cho việc giải thích, chúng tôi sẽ bỏ qua điều này trong các ví dụ.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
Lưu ý: Chúng tôi đã đưa chuẩn mực thị trường (SPX) vào dữ liệu của mình - thị trường thúc đẩy dòng chảy của nhiều công cụ và thường bạn có thể thấy hai công cụ có vẻ như được tích hợp chung; nhưng trên thực tế chúng không được tích hợp chung với nhau, mà là Tích hợp chung với thị trường. Đây được gọi là biến nhiễu. Điều quan trọng là phải xem xét sự tham gia của thị trường trong bất kỳ mối quan hệ nào bạn tìm thấy.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

Bây giờ chúng ta hãy thử tìm cặp giao dịch đồng tích hợp bằng phương pháp của chúng tôi.
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
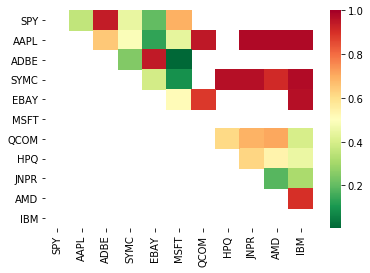
Có vẻ như 'ADBE' và 'MSFT' được tích hợp chung. Hãy cùng xem xét giá để đảm bảo rằng nó thực sự hợp lý.
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
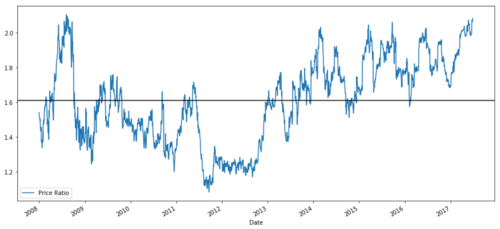
Biểu đồ tỷ lệ giá giữa MSFT và ADBE từ năm 2008 đến năm 2017
Tỷ lệ này có vẻ giống như mức trung bình ổn định. Tỷ lệ tuyệt đối không thực sự hữu ích về mặt thống kê. Sẽ hữu ích hơn nếu chuẩn hóa tín hiệu bằng cách xem nó dưới dạng điểm số z. Điểm Z được định nghĩa như sau:
Z Score (Value) = (Value — Mean) / Standard Deviation
cảnh báo
Trong thực tế, chúng ta thường cố gắng áp dụng một số phép mở rộng cho dữ liệu, nhưng chỉ khi dữ liệu được phân phối chuẩn. Tuy nhiên, nhiều dữ liệu tài chính không phân phối chuẩn, do đó chúng ta phải rất cẩn thận để không chỉ đơn giản cho rằng dữ liệu có tính chuẩn hoặc bất kỳ phân phối cụ thể nào khi tạo số liệu thống kê. Sự phân bố thực sự của các tỷ lệ có thể có đuôi béo, và dữ liệu có xu hướng hướng tới các giá trị cực đoan có thể làm nhầm lẫn mô hình của chúng ta và dẫn đến những tổn thất lớn.
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
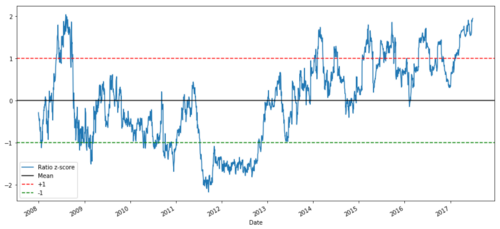
Tỷ lệ giá Z giữa MSFT và ADBE từ năm 2008 đến năm 2017
Bây giờ, dễ dàng hơn để thấy tỷ lệ di chuyển xung quanh giá trị trung bình, nhưng đôi khi nó có xu hướng lệch lớn so với giá trị trung bình, mà chúng ta có thể khai thác.
Bây giờ chúng ta đã thảo luận về những điều cơ bản của chiến lược giao dịch theo cặp và xác định mục tiêu đồng kết hợp dựa trên lịch sử giá, hãy thử phát triển một tín hiệu giao dịch. Trước tiên, chúng ta hãy xem lại các bước phát triển tín hiệu giao dịch bằng kỹ thuật dữ liệu:
-
Thu thập dữ liệu đáng tin cậy và làm sạch dữ liệu
-
Tạo các hàm từ dữ liệu để xác định tín hiệu/logic giao dịch
-
Các tính năng có thể là đường trung bình động hoặc dữ liệu giá, mối tương quan hoặc tỷ lệ của các tín hiệu phức tạp hơn - kết hợp những thứ này để tạo ra các tính năng mới
-
Sử dụng các tính năng này để tạo tín hiệu giao dịch, tức là tín hiệu nào là vị thế mua, bán hoặc bán khống
May mắn thay, chúng ta có Nền tảng định lượng Inventor (fmz.com) để hoàn thành bốn khía cạnh trên cho chúng ta. Đây là một phước lành lớn cho các nhà phát triển chiến lược. Chúng ta có thể dành năng lượng và thời gian của mình cho logic chiến lược, thiết kế và mở rộng chức năng.
Trên Inventor Quantitative Platform, có các giao diện đóng gói của nhiều sàn giao dịch chính thống khác nhau. Tất cả những gì chúng ta cần làm là gọi các giao diện API này. Phần còn lại của logic triển khai cơ bản đã được một nhóm chuyên nghiệp hoàn thiện.
Để đảm bảo tính hoàn chỉnh về mặt logic và giải thích các nguyên lý, chúng tôi sẽ trình bày các logic cơ bản này một cách chi tiết, nhưng trong quá trình vận hành thực tế, độc giả có thể trực tiếp gọi giao diện API của Inventor Quant để hoàn thiện bốn khía cạnh trên.
Chúng ta hãy bắt đầu:
Bước 1: Thiết lập vấn đề của bạn
Ở đây chúng ta đang cố gắng tạo ra một tín hiệu cho chúng ta biết tỷ lệ sẽ là mua hay bán tại thời điểm tiếp theo, đó chính là biến dự báo Y của chúng ta:
Y = Ratio is buy (1) or sell (-1)
Y(t)= Sign(Ratio(t+1) — Ratio(t))
Lưu ý rằng chúng ta không cần phải dự đoán giá thực tế của tài sản cơ bản hoặc thậm chí giá trị thực tế của tỷ lệ (mặc dù chúng ta có thể), chúng ta chỉ cần dự đoán hướng đi tiếp theo của tỷ lệ.
Bước 2: Thu thập dữ liệu đáng tin cậy và chính xác
Nhà phát minh Quant chính là bạn của bạn! Bạn chỉ cần chỉ định công cụ bạn muốn giao dịch và nguồn dữ liệu bạn muốn sử dụng, công cụ này sẽ trích xuất dữ liệu cần thiết và dọn dẹp dữ liệu đó để phân chia cổ tức và công cụ. Vì vậy, dữ liệu của chúng tôi ở đây đã rất sạch.
Chúng tôi đã sử dụng dữ liệu sau từ Yahoo Finance cho các ngày giao dịch trong 10 năm qua (khoảng 2.500 điểm dữ liệu): mở, đóng, cao, thấp và khối lượng
Bước 3: Phân chia dữ liệu
Đừng quên bước rất quan trọng này là kiểm tra độ chính xác của mô hình. Chúng tôi đang sử dụng phân chia dữ liệu đào tạo/xác thực/kiểm tra sau đây
-
Training 7 years ~ 70%
-
Test ~ 3 years 30%
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
Trong trường hợp lý tưởng, chúng ta cũng có thể tạo một bộ xác thực, nhưng hiện tại chúng ta sẽ không thực hiện điều đó.
Bước 4: Kỹ thuật tính năng
Các chức năng liên quan có thể là gì? Chúng ta muốn dự đoán hướng thay đổi tỷ lệ. Chúng ta đã thấy rằng hai công cụ của chúng ta được tích hợp đồng thời, do đó tỷ lệ này sẽ có xu hướng dịch chuyển và trở lại mức trung bình. Có vẻ như tính năng của chúng ta phải là một số phép đo giá trị trung bình của tỷ lệ và sự khác biệt giữa giá trị hiện tại và giá trị trung bình có thể tạo ra tín hiệu giao dịch của chúng ta.
Chúng tôi sử dụng các chức năng sau:
-
Tỷ lệ trung bình động 60 ngày: Một thước đo của trung bình động
-
Tỷ lệ trung bình động 5 ngày: Một thước đo giá trị hiện tại của giá trị trung bình
-
Độ lệch chuẩn 60 ngày
-
Điểm z: (MA 5 ngày - MA 60 ngày) / SD 60 ngày
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
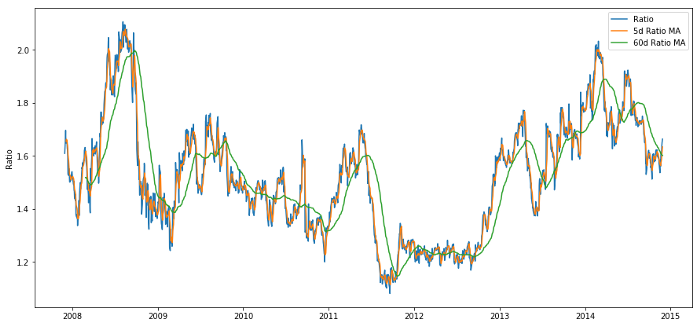
Tỷ lệ giá của MA 60 ngày và 5 ngày
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
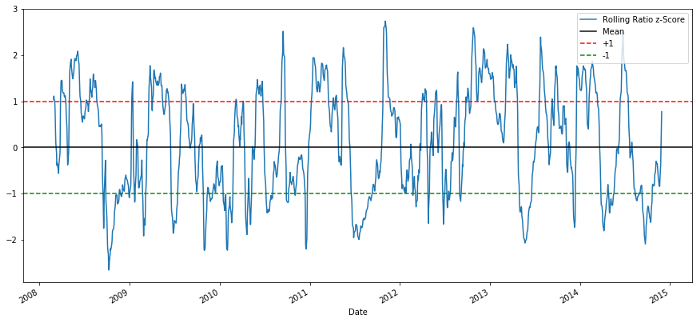
Tỷ lệ giá điểm Z 60-5
Điểm Z của giá trị trung bình lăn thực sự làm nổi bật bản chất quay trở lại giá trị trung bình của tỷ lệ!
Bước 5: Lựa chọn mô hình
Chúng ta hãy bắt đầu với một mô hình rất đơn giản. Khi nhìn vào biểu đồ điểm z, chúng ta có thể thấy rằng bất cứ khi nào điểm z quá cao hoặc quá thấp, nó đều thoái lui. Chúng ta hãy sử dụng +1/-1 làm ngưỡng để xác định mức quá cao và quá thấp, sau đó chúng ta có thể sử dụng mô hình sau để tạo tín hiệu giao dịch:
-
Khi z nhỏ hơn -1.0, tỷ lệ là (1) vì chúng ta mong đợi z trở về 0, do đó tỷ lệ tăng
-
Khi z lớn hơn 1.0, tỷ lệ là bán (-1) vì chúng ta mong đợi z sẽ trở về 0, do đó làm giảm tỷ lệ
Bước 6: Đào tạo, Xác thực và Tối ưu hóa
Cuối cùng, chúng ta hãy xem tác động thực sự của mô hình lên dữ liệu thực tế? Hãy xem tín hiệu này hoạt động như thế nào trong tỷ lệ thực tế
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
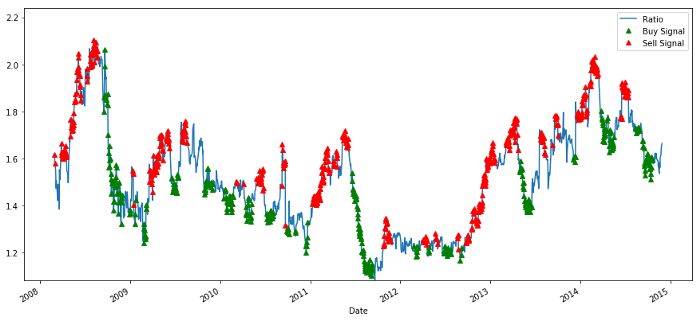
Tín hiệu tỷ lệ giá mua và bán
Tín hiệu này có vẻ hợp lý, chúng ta có vẻ bán tỷ lệ khi nó cao hoặc tăng (chấm đỏ) và mua lại khi nó thấp (chấm xanh) và giảm. Điều này có ý nghĩa gì đối với nội dung thực tế của giao dịch của chúng ta? chúng ta hãy xem
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
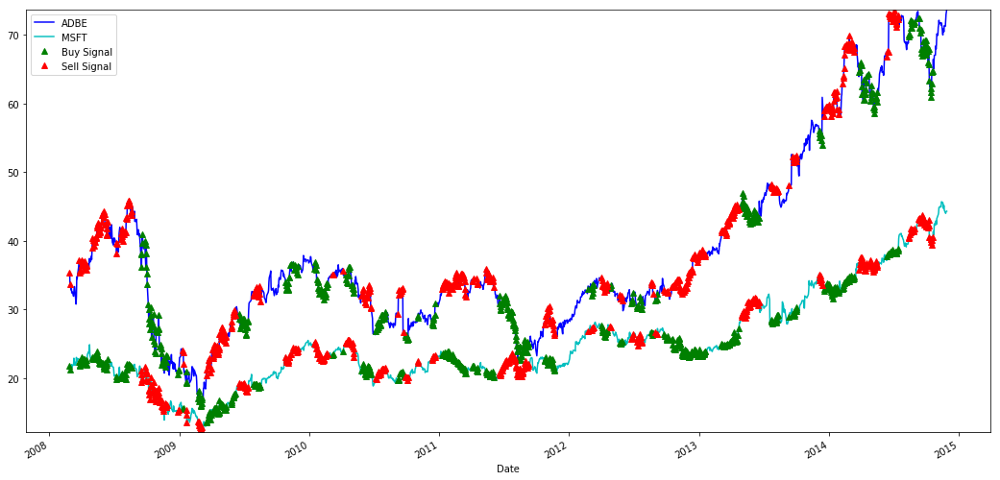
Tín hiệu mua và bán cổ phiếu MSFT và ADBE
Lưu ý rằng đôi khi chúng ta kiếm được tiền ở "chân ngắn", đôi khi ở "chân dài" và đôi khi là cả hai.
Chúng tôi hài lòng với tín hiệu của dữ liệu đào tạo. Hãy cùng xem tín hiệu này có thể tạo ra lợi nhuận như thế nào. Chúng ta có thể tạo một backtester đơn giản mua 1 tỷ lệ (mua 1 cổ phiếu ADBE và bán tỷ lệ x cổ phiếu MSFT) khi tỷ lệ thấp và bán 1 tỷ lệ (bán 1 cổ phiếu ADBE và tỷ lệ mua x cổ phiếu MSFT) và tính toán các giao dịch PnL cho các giao dịch này tỷ lệ.
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
Kết quả là: 1783.375
Vậy thì chiến lược này có vẻ có lợi! Bây giờ, chúng ta có thể tối ưu hóa hơn nữa bằng cách thay đổi cửa sổ thời gian trung bình động, bằng cách thay đổi ngưỡng cho các vị thế mua/bán và đóng, v.v. và kiểm tra những cải tiến về hiệu suất trên dữ liệu xác thực.
Chúng ta cũng có thể thử các mô hình phức tạp hơn như Hồi quy logistic, SVM, v.v. để dự đoán 1/-1.
Bây giờ, chúng ta hãy tiến hành mô hình này, điều này đưa chúng ta đến
Bước 7: Kiểm tra lại dữ liệu thử nghiệm
Ở đây tôi muốn đề cập đến Nền tảng định lượng Inventor. Nó sử dụng công cụ kiểm tra ngược QPS/TPS hiệu suất cao để thực sự tái tạo môi trường lịch sử, loại bỏ các bẫy kiểm tra ngược định lượng phổ biến và nhanh chóng phát hiện ra những thiếu sót của chiến lược, để cung cấp tốt hơn - đầu tư thời gian. Đề nghị giúp đỡ.
Để giải thích nguyên lý, bài viết này chọn cách trình bày logic cơ bản. Trong ứng dụng thực tế, khuyến nghị độc giả sử dụng Inventor Quantitative Platform. Ngoài việc tiết kiệm thời gian, điều quan trọng là cải thiện tỷ lệ chịu lỗi.
Kiểm thử ngược rất đơn giản. Chúng ta có thể sử dụng hàm trên để xem PnL của dữ liệu kiểm thử.
trade(data[‘ADBE’].iloc[1762:], data[‘MSFT’].iloc[1762:], 60, 5)
Kết quả là: 5262.868
Mô hình này được làm rất tốt! Nó đã trở thành mô hình giao dịch cặp đơn giản đầu tiên của chúng tôi.
Tránh quá phù hợp
Trước khi kết thúc, tôi muốn nói cụ thể về hiện tượng quá khớp. Quá phù hợp là cạm bẫy nguy hiểm nhất trong các chiến lược giao dịch. Thuật toán quá khớp có thể hoạt động cực kỳ tốt khi kiểm tra ngược nhưng lại thất bại khi xử lý dữ liệu mới chưa biết - nghĩa là nó không thực sự tiết lộ bất kỳ xu hướng nào trong dữ liệu và không có sức mạnh dự đoán thực sự. Chúng ta hãy lấy một ví dụ đơn giản.
Trong mô hình của mình, chúng tôi sử dụng ước tính tham số lăn và hy vọng tối ưu hóa độ dài cửa sổ thời gian. Chúng ta có thể quyết định lặp lại tất cả các khả năng, độ dài cửa sổ thời gian hợp lý và chọn độ dài thời gian mà mô hình của chúng ta hoạt động tốt nhất. Bên dưới, chúng tôi viết một vòng lặp đơn giản để chấm điểm độ dài cửa sổ thời gian dựa trên PNL của dữ liệu đào tạo và tìm vòng lặp tốt nhất.
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
Bây giờ chúng ta kiểm tra hiệu suất của mô hình trên dữ liệu thử nghiệm và thấy rằng độ dài cửa sổ thời gian này không hề tối ưu! Điều này là do lựa chọn ban đầu của chúng tôi rõ ràng phù hợp hơn với dữ liệu mẫu.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
Rõ ràng những gì hiệu quả với dữ liệu mẫu của chúng tôi không phải lúc nào cũng mang lại kết quả tốt trong tương lai. Chỉ để thử nghiệm, chúng ta hãy vẽ biểu đồ điểm số chiều dài được tính toán từ hai tập dữ liệu
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
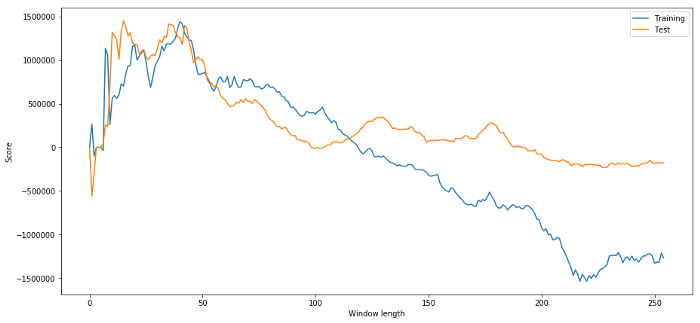
Chúng ta có thể thấy rằng bất kỳ mức nào trong khoảng từ 20-50 đều là lựa chọn tốt cho khung thời gian này.
Để tránh tình trạng quá khớp, chúng ta có thể sử dụng lý luận kinh tế hoặc các đặc tính của thuật toán để chọn độ dài cửa sổ thời gian. Chúng ta cũng có thể sử dụng bộ lọc Kalman, không yêu cầu chúng ta phải chỉ định độ dài; phương pháp này sẽ được đề cập sau trong một bài viết khác.
Bước tiếp theo
Trong bài viết này, chúng tôi trình bày một số phương pháp cơ bản để minh họa quá trình xây dựng chiến lược giao dịch. Trong thực tế, cần sử dụng số liệu thống kê phức tạp hơn và bạn có thể cân nhắc các lựa chọn sau:
-
Số mũ Hurst
-
Chu kỳ bán rã của sự trở lại trung bình được suy ra từ quá trình Ornstein-Uhlenbeck
-
Bộ lọc Kalman
