Chiến lược theo xu hướng dựa trên chỉ báo RSI và đường trung bình động MA

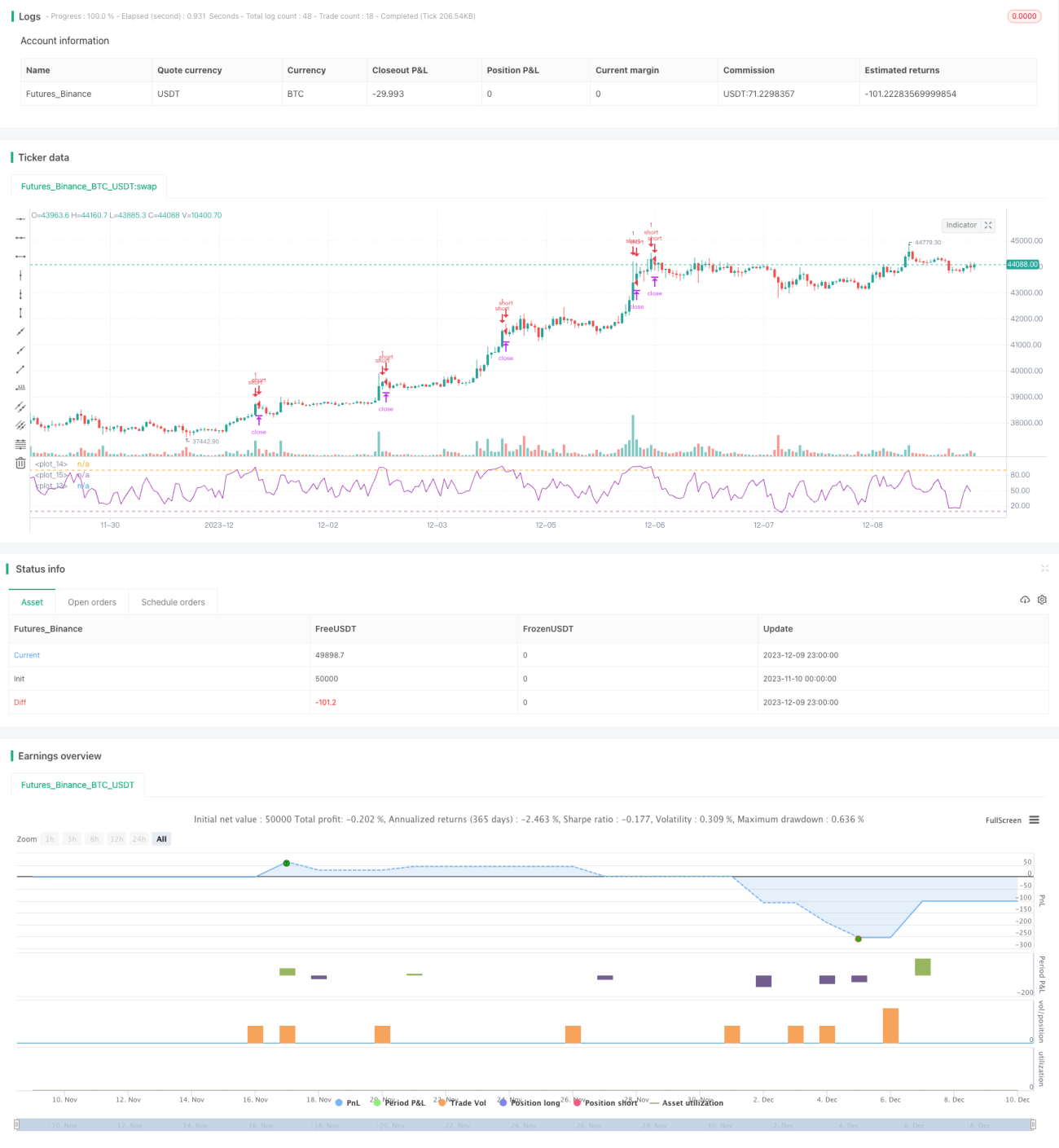
Tổng quan
Chiến lược này được gọi là RSI-MA theo dõi xu hướng chiến lược, ý tưởng của nó là sử dụng chỉ số RSI và đường trung bình MA để xác định xu hướng giá cả và gửi tín hiệu giao dịch. Khi chỉ số RSI vượt quá giá giảm giá, tín hiệu giao dịch được tạo ra, trong khi đường MA được sử dụng để lọc tín hiệu giả, chỉ khi giá tiếp tục tăng hoặc giảm. Điều này có thể lọc hiệu quả tình trạng xung đột trong khi vẫn giữ một khoảng trống lợi nhuận.
Nguyên tắc chiến lược
Chiến lược này chủ yếu sử dụng chỉ số RSI và đường trung bình MA. RSI được sử dụng để đánh giá quá mua quá bán, MA được sử dụng để xác định hướng xu hướng.
-
Tính RSI và thiết lập mức 90 và mức 10 trên RSI. Nếu RSI trên 90 là dấu hiệu mua quá mức và dưới 10 là dấu hiệu bán quá mức.
-
Xác định đường MA trung bình trong một chu kỳ nhất định (ví dụ như 4 ngày). Khi giá tiếp tục tăng, đường MA tăng; khi giá tiếp tục giảm, đường MA giảm.
-
Khi RSI vượt quá 90 đồng thời MA lên đường, hãy thả lỗ; khi RSI dưới 10 đồng thời MA xuống đường, hãy thả nhiều hơn.
-
Stop loss được thiết lập là số điểm cố định cho mỗi tay, stop loss là phần trăm cố định cho mỗi tay.
Phân tích lợi thế chiến lược
Chiến lược này kết hợp các chỉ số RSI và đường trung bình MA để lọc hiệu quả các tín hiệu giả trong tình huống biến động. Đồng thời, bằng cách đặt RSI, tránh tín hiệu đến quá muộn, đảm bảo một khoảng trống lợi nhuận. Sử dụng MA để xác định hướng xu hướng, tránh giao dịch ngược. Ngoài ra, các tham số chiến lược đơn giản, dễ hiểu và tối ưu hóa.
Phân tích rủi ro
Những rủi ro chính của chiến lược này là:
-
Sự kiện bất ngờ gây ra sự sụt giảm mạnh hoặc tăng mạnh, cả RSI và MA đều không phản ứng và có thể gây ra tổn thất lớn.
-
RSI và MA có thể phát ra các tín hiệu thường xuyên trong tình huống xung đột, làm tăng phí giao dịch và chi phí điểm trượt do giao dịch quá thường xuyên.
-
Các tham số được đặt không đúng cũng có thể ảnh hưởng đến hiệu suất của chiến lược, chẳng hạn như RSI trên hoặc dưới giới hạn được đặt quá rộng, tín hiệu bị trì hoãn, và thiết lập quá hẹp, tín hiệu quá thường xuyên.
Hướng tối ưu hóa
Chiến lược này có thể được tối ưu hóa hơn bao gồm:
-
Thử nghiệm và tối ưu hóa dựa trên các tham số khác nhau về giống và chu kỳ, thiết lập kết hợp tham số tối ưu.
-
Thêm kết hợp các chỉ số khác, chẳng hạn như thêm KDJ, BOLL, và các điều kiện lọc nghiêm ngặt hơn để giảm khả năng giao dịch sai.
-
Thiết lập các cơ chế dừng lỗ tự điều chỉnh, chẳng hạn như điều chỉnh giá dừng lỗ theo biến động và ATR.
-
Thêm các thuật toán học máy, điều chỉnh các tham số chiến lược theo tình trạng thị trường và tối ưu hóa các tham số động.
Tóm tắt
Chiến lược RSI-MA nói chung là khá đơn giản và thực tế, kết hợp với theo dõi xu hướng và phán đoán mua quá bán, có thể mang lại lợi nhuận tốt hơn trong môi trường thị trường tốt. Tuy nhiên, cũng có một số rủi ro giao dịch sai có xác suất cần được tối ưu hóa hơn nữa để giảm rủi ro và tăng sự ổn định.
/*backtest
start: 2023-11-10 00:00:00
end: 2023-12-10 00:00:00
period: 1h
basePeriod: 15m
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT"}]
*/
//@version=2
//This strategy is best used with the Chrome Extension AutoView for automating TradingView alerts.
//You can get the AutoView extension for FREE using the following link
//https://chrome.google.com/webstore/detail/autoview/okdhadoplaoehmeldlpakhpekjcpljmb?utm_source=chrome-app-launcher-info-dialog- 1