Chiến lược giao dịch định lượng trung bình động hàm mũ không độ trễ thích ứng

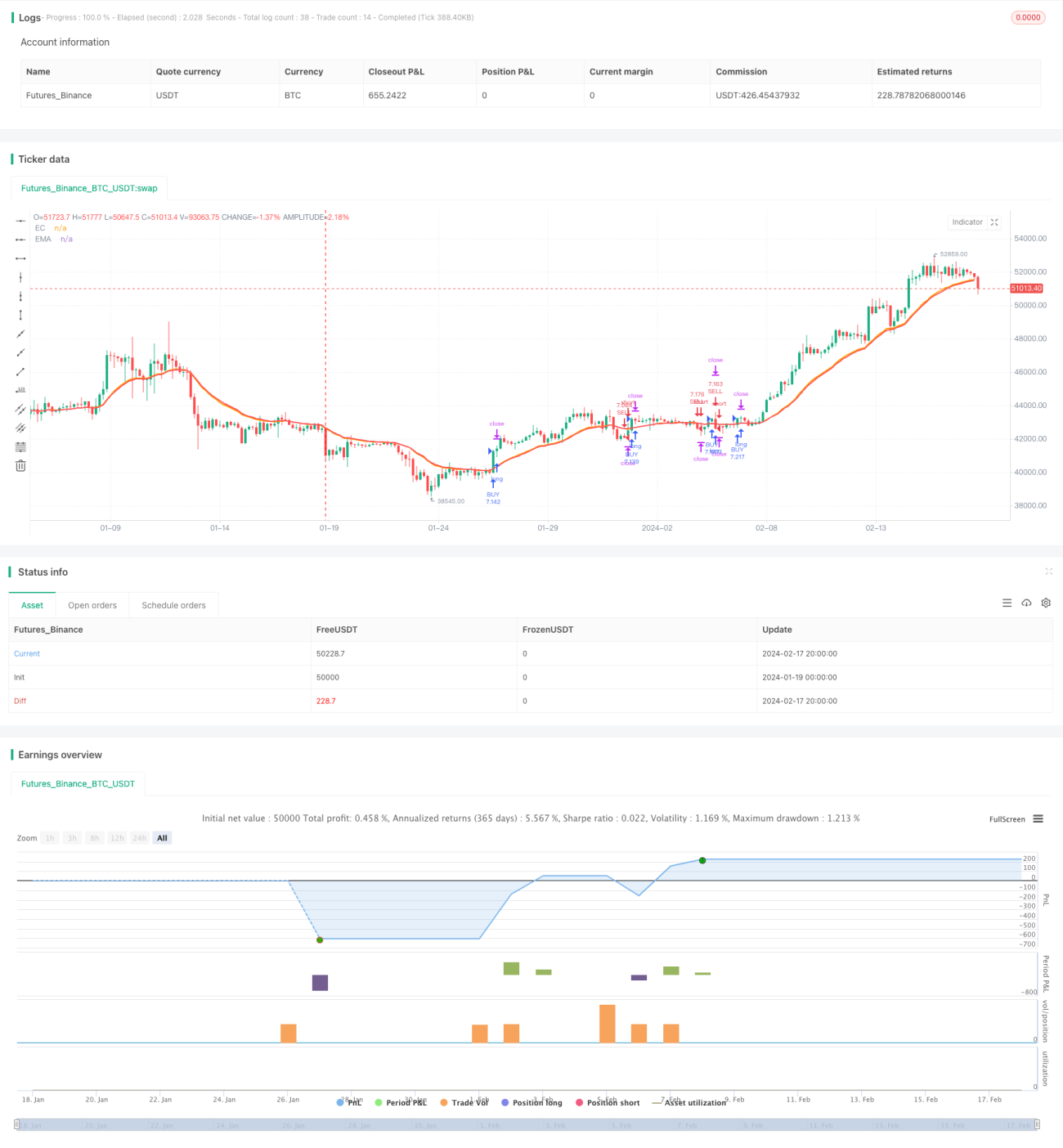
Tổng quan
Adaptive Zero Lag Exponential Moving Average Quantitative Trading Strategy là một chiến lược giao dịch định lượng được phát triển dựa trên tư tưởng ZERO LAG EXPONENTIAL MOVING AVERAGE của Ehlers. Chiến lược này sử dụng chỉ số trung bình di chuyển như một chỉ số cơ bản và thêm vào các tham số chu kỳ của chỉ số di chuyển theo phương pháp thích ứng của đo tần số tức thời.
Nguyên tắc chiến lược
Ý tưởng cốt lõi của chiến lược này bắt nguồn từ lý thuyết bộ lọc trễ không của John Ehlers. Mặc dù chỉ số trung bình di chuyển chỉ số là một chỉ số kỹ thuật được biết đến rộng rãi, nhưng nó có vấn đề về độ trễ. Bằng cách thêm một yếu tố điều chỉnh lỗi vào công thức tính toán của chỉ số trung bình di chuyển, Ehlers có thể loại bỏ hiệu quả sự trễ, làm cho chỉ số trung bình di chuyển chỉ số trễ không có thể theo dõi sự thay đổi giá một cách nhạy cảm hơn.
Trong chiến lược EMA tự điều chỉnh, chúng tôi sử dụng phương pháp đo tần số tức thời để tự điều chỉnh các tham số chu kỳ của chỉ số di chuyển trung bình với độ trễ bằng không. Đo tần số tức thời được phân thành hai phương pháp chốt và giao tiếp chính, có thể đo chu kỳ thống trị của sự thay đổi chuỗi giá. Chúng tôi theo dõi các chu kỳ tốt nhất được tính toán bởi hai phương pháp đo lường này trong thời gian thực, động thiết lập các tham số chu kỳ của chỉ số di chuyển trung bình với độ trễ bằng không, để phù hợp hơn với môi trường thị trường hiện tại.
Khi đường nhanh (trên đường trung bình di chuyển của chỉ số 0) đi qua đường chậm (trên đường trung bình di chuyển của chỉ số thông thường), làm nhiều khi đi qua, làm rỗng khi đi xuống, do đó tạo ra một tín hiệu chiến lược giao dịch tương tự như đường trung bình di chuyển.
Lợi thế chiến lược
Chiến lược EMA tự điều chỉnh với độ trễ không kết hợp bộ lọc không trễ và phương pháp tối ưu hóa chu kỳ tự điều chỉnh với các ưu điểm sau:
- Loại bỏ sự chậm trễ, làm cho tín hiệu nhạy cảm và đáng tin cậy hơn
- Các tham số tự điều chỉnh chu kỳ, thích nghi với môi trường thị trường rộng lớn hơn
- ít tham số chiến lược, dễ kiểm tra và tối ưu hóa
- Có thể cấu hình điểm dừng lỗ cố định, rủi ro dễ kiểm soát
Rủi ro chiến lược
Các chiến lược EMA tự điều chỉnh với độ trễ bằng không cũng có một số rủi ro, đặc biệt là:
- Các tham số chu kỳ tự điều chỉnh có thể không hiệu quả trong một số trường hợp thị trường nhất định
- Cài đặt không đúng điểm dừng cố định có thể dẫn đến tổn thất hoặc mất lợi nhuận quá mức
- Thử nghiệm tối ưu hóa tham số kém có thể dẫn đến hiệu suất đĩa cứng kém
Để kiểm soát những rủi ro này, chúng tôi cần kiểm tra đầy đủ các thiết lập tham số trong các môi trường thị trường khác nhau, điều chỉnh điểm dừng lỗ thích hợp và xác minh đầy đủ các môi trường thực tế mô phỏng trong phản hồi.
Hướng tối ưu hóa chiến lược
Chiến lược EMA tự điều chỉnh với độ chậm trễ bằng không có nhiều khả năng tối ưu hóa, bao gồm:
- Thử các phương pháp đo chu kỳ tự điều chỉnh khác nhau, chẳng hạn như tỷ lệ dao động tự điều chỉnh MA
- Thêm các điều kiện lọc bổ sung, chẳng hạn như khối lượng giao dịch, cặp moving average
- Tối ưu hóa các chiến lược dừng lỗ như trailing stop, Chandelier Exit
- Định lượng vị trí động, phối hợp với quản lý rủi ro
- Xác nhận nhiều chu kỳ thời gian, cải thiện chất lượng tín hiệu
Những phương pháp tối ưu hóa này có thể giúp cải thiện hơn nữa tỷ lệ chiến thắng, tỷ lệ lợi nhuận, chỉ số điều chỉnh rủi ro của chiến lược.
Tóm tắt
Chiến lược EMA tự thích ứng với độ trễ không kết hợp thành công với bộ lọc trễ không và ý tưởng tối ưu hóa chu kỳ động, là một chiến lược giao dịch định lượng ít tham số, dễ vận hành và tối ưu hóa. Nó có tính năng nhạy cảm, tự thích ứng, hoạt động tốt trong thị trường xu hướng.
- 1