
FMZ প্ল্যাটফর্মে পাইথন ক্রলারের প্রয়োগের উপর একটি প্রাথমিক গবেষণা - Binance ঘোষণার বিষয়বস্তু ক্রলিং
আমি সম্প্রতি সম্প্রদায় এবং লাইব্রেরির দিকে তাকিয়েছি এবং পাইথন ক্রলার সম্পর্কে কোন প্রাসঙ্গিক তথ্য নেই, একটি QUANT হিসাবে ব্যাপক বিকাশের চেতনার উপর ভিত্তি করে। আমি খুব সংক্ষিপ্তভাবে ক্রলার সম্পর্কিত ধারণা এবং জ্ঞান শিখেছি। এটি সম্পর্কে জানার পরে, আমি দেখতে পেলাম যে "সরীসৃপ প্রযুক্তি" এর "পিট" বেশ বড় এই নিবন্ধটি "সরীসৃপ প্রযুক্তি" এর একটি প্রাথমিক অনুসন্ধান মাত্র। আসুন FMZ পরিমাণগত ট্রেডিং প্ল্যাটফর্মে ক্রলার প্রযুক্তির সহজতম অনুশীলন করি।
প্রয়োজন
ব্যবসায়ীদের জন্য যারা নতুন বাজার অন্বেষণ করতে পছন্দ করে, তারা সবসময় যত তাড়াতাড়ি সম্ভব এক্সচেঞ্জে মুদ্রা তালিকা সম্পর্কে তথ্য পেতে চায়। এক্সচেঞ্জ ওয়েবসাইটে ম্যানুয়ালি নজর রাখা স্পষ্টতই অবাস্তব। তারপরে আপনাকে বিনিময় ঘোষণা পৃষ্ঠা নিরীক্ষণ করতে এবং নতুন ঘোষণা সনাক্ত করতে একটি ক্রলার স্ক্রিপ্ট ব্যবহার করতে হবে যাতে আপনি যত তাড়াতাড়ি সম্ভব বিজ্ঞপ্তি এবং অনুস্মারক পেতে পারেন।
প্রাথমিক অনুসন্ধান
আসুন একটি সূচনা পয়েন্ট হিসাবে একটি খুব সাধারণ প্রোগ্রাম ব্যবহার করি (সত্যিই শক্তিশালী ক্রলার স্ক্রিপ্ট অনেক বেশি জটিল, তাই প্রথমে আপনার সময় নিন)। প্রোগ্রাম লজিক খুবই সহজ, অর্থাৎ, প্রোগ্রামটি ক্রমাগত এক্সচেঞ্জের ঘোষণা পৃষ্ঠা অ্যাক্সেস করে, প্রাপ্ত HTML বিষয়বস্তু পার্স করে এবং নির্দিষ্ট ট্যাগ সামগ্রী আপডেট করা হয়েছে কিনা তা সনাক্ত করে।
কোড প্রয়োগ করুন
আপনি কিছু দরকারী ক্রলার ফ্রেমওয়ার্ক ব্যবহার করতে পারেন। যাইহোক, প্রয়োজনীয়তা খুব সহজ বিবেচনা করে, আপনি এটি সরাসরি লিখতে পারেন।
পাইথন লাইব্রেরি প্রয়োজন:
requests, যা সহজভাবে ওয়েব পৃষ্ঠাগুলি অ্যাক্সেস করার জন্য ব্যবহৃত একটি লাইব্রেরি হিসাবে বোঝা যেতে পারে।
bs4, যা সহজভাবে একটি ওয়েব পৃষ্ঠার HTML কোড বিশ্লেষণ করতে ব্যবহৃত একটি লাইব্রেরি হিসাবে বোঝা যেতে পারে।
কোড:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
চালান
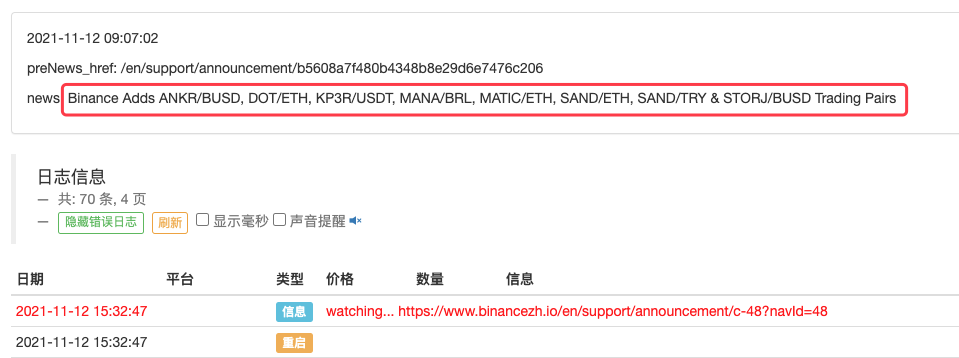
এটি এমনকি প্রসারিত করা যেতে পারে, যেমন নতুন ঘোষণা সনাক্ত করা। ঘোষণায় নতুন মুদ্রা বিশ্লেষণ করুন এবং নতুন লেনদেনের জন্য স্বয়ংক্রিয়ভাবে অর্ডার দিন।

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1