

Vorwort
Das Backtesting-System der Inventor Quantitative Trading Platform ist ein Backtesting-System, das ständig iteriert, aktualisiert und verbessert wird. Ausgehend von den anfänglichen grundlegenden Backtesting-Funktionen werden nach und nach Funktionen hinzugefügt und die Leistung optimiert. Im Zuge der Weiterentwicklung der Plattform wird das Backtesting-System weiter optimiert und verbessert. Heute werden wir ein Thema besprechen, das auf dem Backtesting-System basiert: „Strategietests basierend auf zufälligen Marktbedingungen“.
brauchen
Im Bereich des quantitativen Handels sind die Entwicklung und Optimierung von Strategien nicht von der Überprüfung realer Marktdaten zu trennen. Aufgrund des komplexen und sich ändernden Marktumfelds kann es jedoch in der Praxis zu Mängeln bei der Verwendung historischer Daten für Backtests kommen, z. B. wenn extreme Marktbedingungen oder spezielle Szenarien nicht abgedeckt werden. Daher ist die Entwicklung eines effizienten Zufallsgenerators für den Markt ein wirksames Werkzeug für Entwickler quantitativer Strategien.
Wenn wir die Strategie anhand historischer Daten an einer bestimmten Börse oder Währung einem Backtesting unterziehen müssen, können wir für das Backtesting die offizielle Datenquelle der FMZ-Plattform verwenden. Manchmal möchten wir auch sehen, wie sich eine Strategie auf einem völlig „unbekannten“ Markt bewährt. Zu diesem Zeitpunkt können wir einige Daten „erfinden“, um die Strategie zu testen.
Die Bedeutung der Verwendung zufälliger Marktdaten liegt darin:
-
- Bewertung der Robustheit der Strategie
Der Zufallsgenerator kann eine Vielzahl möglicher Marktszenarien erzeugen, darunter extreme Volatilität, geringe Volatilität, Trendmärkte und volatile Märkte. Durch das Testen einer Strategie in diesen simulierten Umgebungen können Sie beurteilen, ob ihre Leistung unter verschiedenen Marktbedingungen stabil ist. Zum Beispiel:
Kann sich die Strategie an Trend- und Schockwechsel anpassen?
Führt die Strategie bei extremen Marktbedingungen zu erheblichen Verlusten? - Bewertung der Robustheit der Strategie
-
- Identifizieren Sie potenzielle Schwachstellen in Ihrer Strategie
Durch die Simulation einiger abnormaler Marktsituationen (wie etwa hypothetischer Black-Swan-Ereignisse) können potenzielle Schwächen der Strategie entdeckt und verbessert werden. Zum Beispiel:
Verlässt sich die Strategie zu stark auf eine bestimmte Marktstruktur?
Besteht die Gefahr einer Überanpassung der Parameter? - Identifizieren Sie potenzielle Schwachstellen in Ihrer Strategie
-
- Optimierung der Strategieparameter
Zufällig generierte Daten bieten eine vielfältigere Testumgebung für die Feinabstimmung von Strategieparametern, ohne dass man sich vollständig auf historische Daten verlassen muss. Dadurch ist eine umfassendere Auswahl an Strategieparametern möglich und man ist nicht auf bestimmte Marktmuster in historischen Daten beschränkt.
- Optimierung der Strategieparameter
-
- Lücken in historischen Daten schließen
In manchen Märkten (wie etwa Schwellenmärkten oder Märkten, in denen kleine Währungen gehandelt werden) reichen die historischen Daten möglicherweise nicht aus, um alle möglichen Marktbedingungen abzudecken. Der Zufallsgenerator kann eine große Menge an Zusatzdaten liefern, um umfassendere Tests zu ermöglichen.
- Lücken in historischen Daten schließen
-
- Schnelle iterative Entwicklung
Die Verwendung von Zufallsdaten für Schnelltests kann die Iteration der Strategieentwicklung beschleunigen, ohne auf Echtzeit-Marktbedingungen oder zeitaufwändige Datenbereinigung und -organisation angewiesen zu sein.
- Schnelle iterative Entwicklung
Allerdings ist auch eine rationale Bewertung der Strategie notwendig. Bei zufällig generierten Marktdaten ist zu beachten:
-
- Obwohl Zufallsgeneratoren nützlich sind, hängt ihre Aussagekraft von der Qualität der generierten Daten und der Gestaltung des Zielszenarios ab:
-
- Die Generierungslogik muss nah am realen Markt sein: Wenn die zufällig generierten Marktbedingungen völlig realitätsfern sind, fehlt den Testergebnissen möglicherweise der Referenzwert. Beispielsweise kann der Generator in Kombination mit tatsächlichen statistischen Marktmerkmalen (wie Volatilitätsverteilung, Trendverhältnis) entwickelt werden.
-
- Es kann das Testen mit realen Daten nicht vollständig ersetzen: Zufallsdaten können die Entwicklung und Optimierung von Strategien nur ergänzen. Die endgültige Strategie muss noch anhand realer Marktdaten auf ihre Wirksamkeit überprüft werden.
Nachdem das alles gesagt ist, stellt sich die Frage, wie wir einige Daten „erfinden“ können. Wie können wir bequem, schnell und einfach Daten für die Verwendung in einem Backtesting-System „erstellen“?
Gestaltungsideen
Dieser Artikel soll einen Ausgangspunkt für die Diskussion bieten und bietet eine relativ einfache Berechnung der zufälligen Marktgenerierung. Tatsächlich gibt es eine Vielzahl von Simulationsalgorithmen, Datenmodellen und anderen Technologien, die angewendet werden können. Aufgrund des begrenzten Diskussionsraums , wir werden keine besonders komplexen Datensimulationsmethoden verwenden.
Wir haben ein Programm in Python geschrieben, indem wir die benutzerdefinierte Datenquellenfunktion des Backtesting-Systems der Plattform kombiniert haben.
-
- Generieren Sie zufällig einen Satz von K-Line-Daten und schreiben Sie sie zur dauerhaften Aufzeichnung in eine CSV-Datei, sodass die generierten Daten gespeichert werden können.
-
- Erstellen Sie dann einen Dienst, um Datenquellenunterstützung für das Backtesting-System bereitzustellen.
-
- Zeigen Sie die generierten K-Linien-Daten im Diagramm an.
Für einige Standards zur Generierung und Dateispeicherung von K-Line-Daten können die folgenden Parametersteuerungen definiert werden:
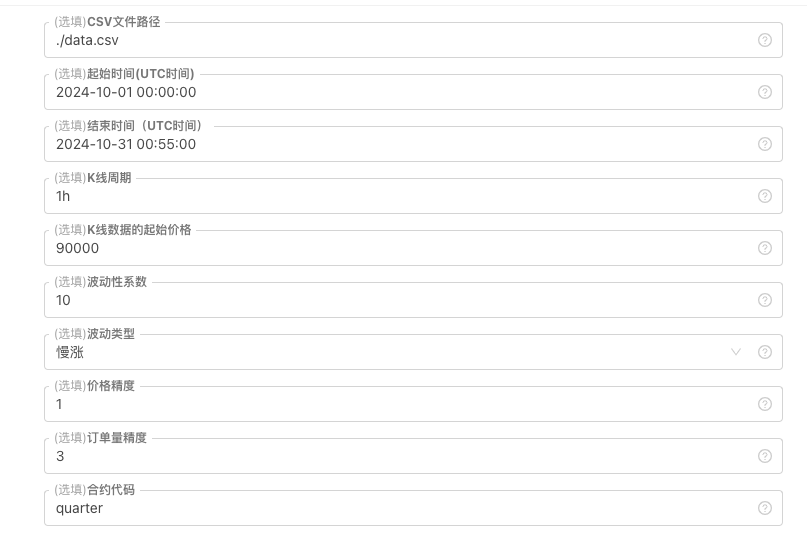
-
Zufällig generiertes Datenmuster
Zur Simulation des Schwankungstyps von K-Linien-Daten wird einfach ein einfaches Design unter Verwendung der unterschiedlichen Wahrscheinlichkeiten positiver und negativer Zufallszahlen durchgeführt. Wenn die generierten Daten nicht groß sind, wird das erforderliche Marktmuster möglicherweise nicht wiedergegeben. Wenn es einen besseren Weg gibt, können Sie diesen Teil des Codes ersetzen.
Basierend auf diesem einfachen Design kann das Anpassen des Zufallszahlengenerierungsbereichs und einiger Koeffizienten im Code den generierten Dateneffekt beeinflussen. -
Datenüberprüfung
Die generierten K-Line-Daten müssen außerdem auf Rationalität überprüft werden, um zu prüfen, ob die hohen Eröffnungs- und niedrigen Schlusskurse die Definition verletzen, um die Kontinuität der K-Line-Daten zu überprüfen usw.
Backtesting-System Zufallsquotierungsgenerator
python
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Praxis im Backtesting-System
- Erstellen Sie die obige Richtlinieninstanz, konfigurieren Sie die Parameter und führen Sie sie aus.
- Der reale Markt (die Strategieinstanz) muss auf einem Host ausgeführt werden, der auf einem Server bereitgestellt ist, da für das Backtesting-System eine öffentliche IP-Adresse erforderlich ist, um darauf zuzugreifen und Daten abzurufen.
- Klicken Sie auf die interaktive Schaltfläche und die Strategie beginnt automatisch mit der Generierung zufälliger Marktdaten.

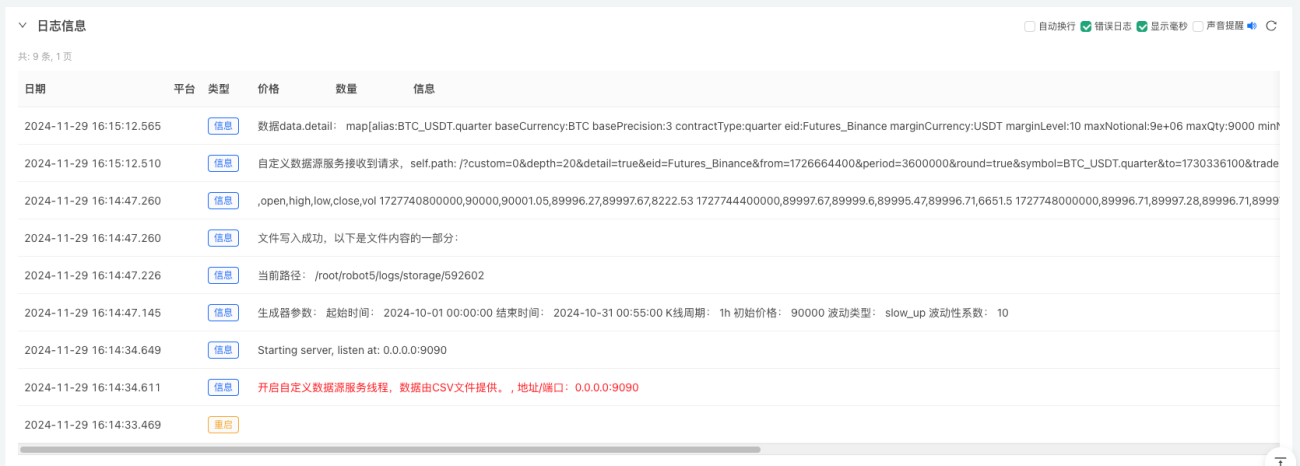
- Die generierten Daten werden zur einfachen Beobachtung im Diagramm angezeigt und in der lokalen Datei data.csv aufgezeichnet
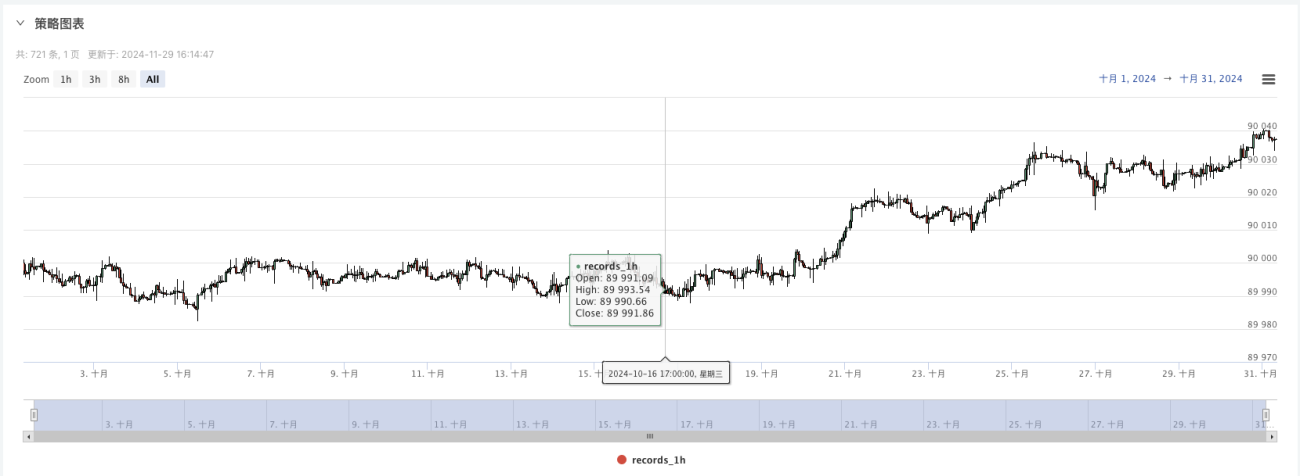
- Jetzt können wir diese zufällig generierten Daten verwenden und jede Strategie für Backtests verwenden
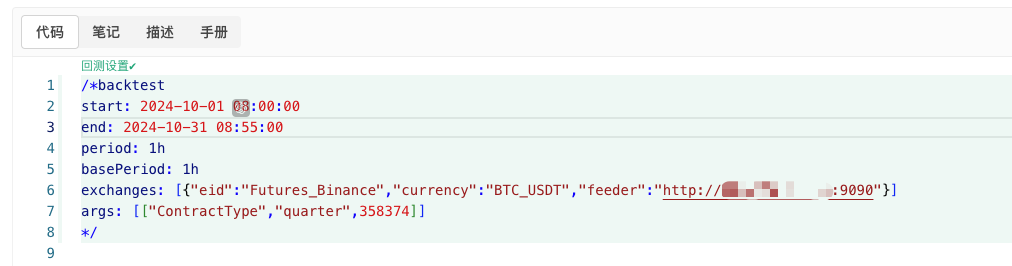
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Konfigurieren Sie entsprechend den oben genannten Informationen und nehmen Sie die gewünschten Anpassungen vor.http://xxx.xxx.xxx.xxx:9090Es handelt sich um die Server-IP-Adresse und den offenen Port der realen Festplatte mit der Strategie zur zufälligen Marktgenerierung.
Dies ist eine benutzerdefinierte Datenquelle. Weitere Informationen finden Sie im Abschnitt „Benutzerdefinierte Datenquelle“ in der API-Dokumentation der Plattform.
- Nachdem das Backtest-System die Datenquelle eingerichtet hat, können Sie die zufälligen Marktdaten testen
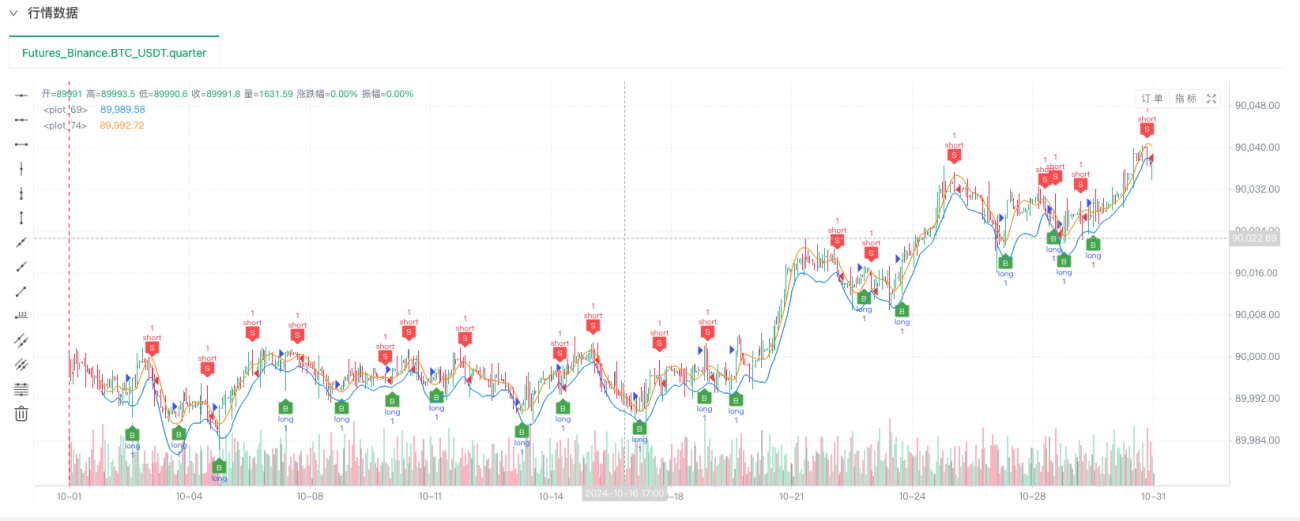
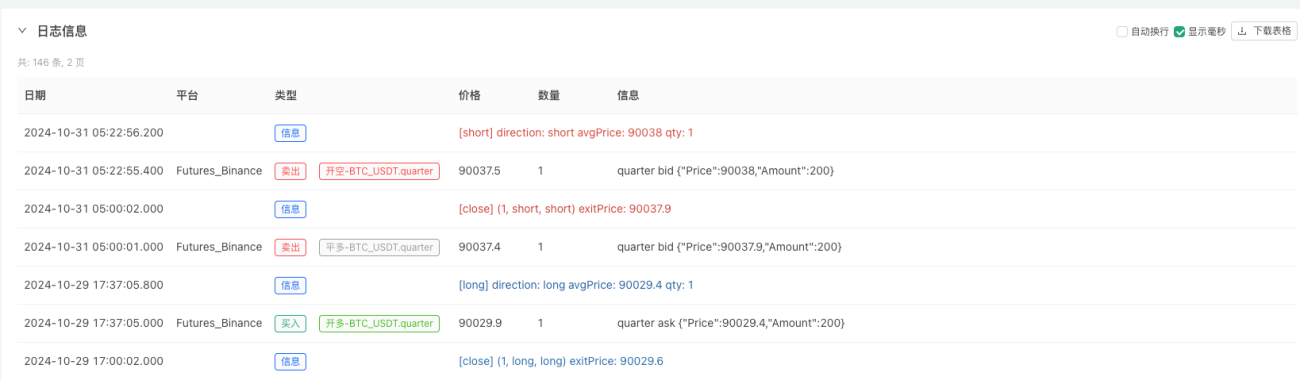
An diesem Punkt wird das Backtesting-System mithilfe unserer „erfundenen“ simulierten Daten getestet. Vergleichen Sie anhand der Daten im Marktdiagramm während des Backtests die Daten im Echtzeitdiagramm, die durch zufällige Marktbedingungen generiert wurden. Es ist der 16. Oktober 2024, 17:00 Uhr. Die Daten sind dieselben.
- Oh ja, das hätte ich fast vergessen zu sagen! Der Grund, warum dieses Python-Programm mit einem Zufallsgenerator für Märkte einen echten Markt erstellt, besteht darin, die Demonstration, Bedienung und Anzeige der generierten K-Line-Daten zu erleichtern. In der tatsächlichen Anwendung können Sie ein unabhängiges Python-Skript schreiben, sodass Sie die eigentliche Festplatte nicht ausführen müssen.
Quellcode der Strategie:Backtesting-System Zufallsquotierungsgenerator
Vielen Dank für Ihre Unterstützung und Ihr Lesen.
- 1