

Ausgereifter Klassifikator: Support Vector Machine (SVM) ist ein leistungsstarker und ausgereifter binärer (oder multivariater) Klassifizierungsalgorithmus. Die Vorhersage, ob die Aktie steigen oder fallen wird, ist ein typisches Problem der binären Klassifizierung.
Nichtlineare Fähigkeit: Durch die Verwendung von Kernelfunktionen (wie dem RBF-Kernel) kann SVM komplexe nichtlineare Beziehungen zwischen Eingabefunktionen erfassen, was für Finanzmarktdaten von entscheidender Bedeutung ist.
Merkmalsorientiert: Die Effektivität des Modells hängt maßgeblich von den Merkmalen ab, mit denen Sie es füttern. Der jetzt berechnete Alpha-Faktor ist ein guter Anfang, und wir können weitere solcher Merkmale einbauen, um die Vorhersagekraft zu verbessern.
Dieses Mal habe ich mit 3 Funktionsübersichten begonnen:
1: Merkmale des hochfrequenten Auftragsflusses:
alpha_1min: Auftragsfluss-Ungleichgewichtsfaktor, berechnet auf Grundlage aller Ticks in der letzten Minute.
alpha_5min: Auftragsfluss-Ungleichgewichtsfaktor, berechnet auf Grundlage aller Ticks der letzten 5 Minuten.
alpha_15min: Auftragsfluss-Ungleichgewichtsfaktor, berechnet auf Grundlage aller Ticks der letzten 15 Minuten.
ofi_1min (Order Flow Imbalance): Das Verhältnis von (Kaufvolumen/Verkaufsvolumen) innerhalb einer Minute. Dies ist direkter als Alpha.
vol_per_trade_1min: Das durchschnittliche Volumen pro Trade innerhalb von 1 Minute. Ein Zeichen dafür, dass große Aufträge den Markt beeinflussen.
2: Preis- und Volatilitätsmerkmale:
log_return_5min: Die logarithmische Rücklaufquote der letzten 5 Minuten, log(P_t / P_{t-5min}).
volatility_15min: Die Standardabweichung der Log-Renditen der letzten 15 Minuten, ein Maß für die kurzfristige Volatilität.
atr_14 (Average True Range): ATR-Wert basierend auf den letzten 14 1-Minuten-Kerzen, ein klassischer Volatilitätsindikator.
rsi_14 (Relative Strength Index): Dies ist ein Maß für überkaufte und überverkaufte Bedingungen basierend auf den RSI-Werten der letzten 14 1-Minuten-Kerzen.
3: Zeitliche Merkmale:
hour_of_day: Aktuelle Stunde (0-23). Märkte verhalten sich in verschiedenen Zeiträumen unterschiedlich (z. B. asiatische/europäische/amerikanische Sitzungen).
day_of_week: Wochentag (0-6). Wochenenden und Wochentage weisen unterschiedliche Schwankungsmuster auf.
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
Verwenden Sie dann drei Kategorien, um zwischen steigenden, fallenden und seitwärts gerichteten Kursen zu unterscheiden.
Die Kernidee des Feature-Screenings: „Gute Teammitglieder“ finden und „schlechte Teammitglieder“ eliminieren
Unser Ziel ist es, eine Reihe von Funktionen zu finden, die:
- Hohe Relevanz: Jedes Merkmal weist eine starke Korrelation mit zukünftigen Preisänderungen auf (unsere Zielbezeichnung).
- Geringe Redundanz: Features sollten nicht zu viele doppelte Informationen enthalten. Beispielsweise sind „5-Minuten-Momentum“ und „6-Minuten-Momentum“ sehr ähnlich. Die Einbeziehung beider Werte verbessert das Modell nicht wesentlich und kann sogar zu Rauschen führen.
- Stabilität: Die Gültigkeit einer Funktion darf sich im Laufe der Zeit nicht zu schnell ändern. Eine Funktion, die nur einen Tag gültig ist, ist gefährlich.
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
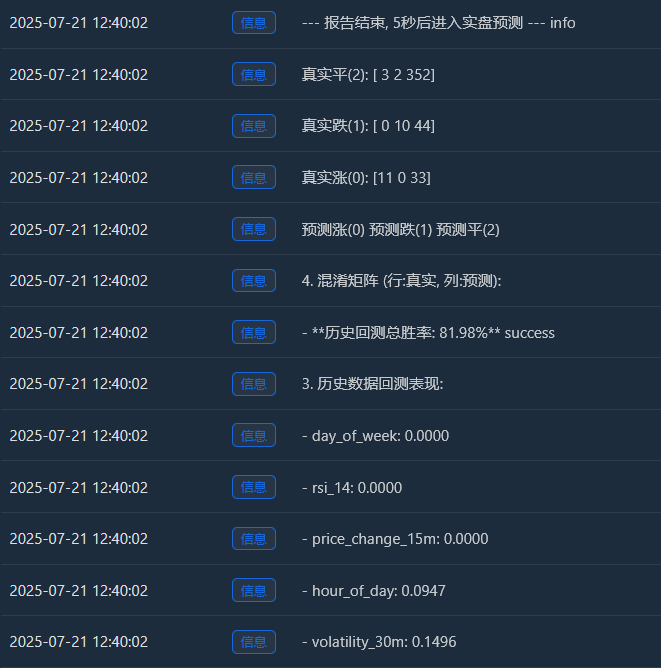
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
Der Ablauf ist:
Datenerfassung
Funktionsbedeutung

Gegenseitige Informationen zwischen Features und Labels sowie Backtest-Informationen
Ursprünglich dachte ich, eine Gewinnrate von 65 % wäre ausreichend, aber ich hatte nicht erwartet, dass sie 81,98 % erreichen würde. Meine erste Reaktion sollte sein: „Das ist toll, aber zu schön, um wahr zu sein. Hier muss es etwas geben, das es wert ist, erforscht zu werden.“
1. Ausführliche Interpretation des Analyseberichts, Interpretation der Berichtsinhalte nacheinander:
- Funktionsbedeutung und gegenseitige Information:
Die wichtigsten Merkmale sind Volatilität_30m und Preisänderung_15m. Dies ist logisch und weist darauf hin, dass der aktuelle Markttrend und die Volatilität die stärksten Prädiktoren für die Zukunft sind.
Auch die Tageszeit trägt ein wenig bei und zeigt an, dass das Modell die Handelsmuster zu verschiedenen Tageszeiten erfasst.
Die Beiträge von rsi_14 und day_of_week liegen bei nahezu 0. Dies deutet darauf hin, dass diese beiden Merkmale im aktuellen Datensatz und der Merkmalskombination möglicherweise „Schweine-Teamkollegen“ sind. Wir können in Erwägung ziehen, sie in Zukunft zu entfernen, um das Modell zu vereinfachen und Rauschen zu vermeiden. - Verwirrungsmatrix (das sind viele Informationen!)
Realer Anstieg (0):[11 0 33] -> Von 44 (11+0+33) echten Rallyes hat das Modell 11 richtig vorhergesagt, es aber 33 Mal fälschlicherweise als „Konsolidierung“ vorhergesagt.
Realer Tropfen (1):[0 10 44] -> Von 54 (0+10+44) realen Rückgängen hat das Modell 10 richtig vorhergesagt, es jedoch 44 Mal als „Seitwärtstrend“ fälschlicherweise vorhergesagt.
Echter Ping (2):[3 2 352] -> Von 357 (3+2+352) echten Konsolidierungen hat das Modell 352 richtig vorhergesagt! - Historische Backtest-Gesamtgewinnrate: 81,98 %
Der Hauptgrund für diese hohe Gewinnrate ist die extrem hohe Genauigkeit des Modells bei der Vorhersage von „Konsolidierungen“! Unter den insgesamt etwa 455 Stichproben befanden sich mehr als 350 Konsolidierungsmärkte, und das Modell identifizierte sie nahezu perfekt.
Dies ist an sich schon eine sehr wertvolle Fähigkeit! Ein Modell, das Ihnen genau sagen kann, „es ist am besten, jetzt nicht zu handeln“, kann Ihnen helfen, eine Menge Gebühren und ungültige Transaktionen zu sparen.
2Warum könnte die tatsächliche Gewinnrate niedriger als 81,98 % sein?
- Die Definition von „Konsolidierung“ ist zu locker: Unser SPREAD_THRESHOLD beträgt 0,5 %. Preisschwankungen von nicht mehr als 0,5 % innerhalb von 15 Minuten sind jedoch recht häufig. Daher machen Konsolidierungsstichproben den Großteil (ca. 80 %) unseres Datensatzes aus. Das Modell hat geschickt gelernt: „Wenn ich unsicher bin, rate ich mit hoher Genauigkeit ‚Konsolidierung‘.“ Das ist statistisch korrekt, aber im Handel geht es uns eher um die Vorhersage von Preisbewegungen.
- Fähigkeit, Anstieg und Abfall vorherzusagen:
Gewinnrate bei der Vorhersage von Aufwärtstrends: Das Modell sagte 11 + 0 + 3 = 14 Aufwärtstrends voraus, von denen nur 11 richtig waren. Die Gewinnrate beträgt 11 / 14 = 78,5 %. Ausgezeichnet!
Gewinnrate bei der Vorhersage von Rückgängen: Das Modell prognostizierte 0 + 10 + 2 = 12 Rückgänge und lag bei 10 davon richtig. Die Gewinnrate beträgt 10 / 12 = 83,3 %. Wieder einmal sehr beeindruckend! - In-Sample Overfitting: Dieser Test wird mit Daten durchgeführt, die dem Modell „bekannt“ sind (d. h. mit den Daten, die für Training und Test verwendet wurden). Dies ist vergleichbar mit der Bitte an einen Schüler, einen gerade abgeschlossenen Test zu wiederholen. Die Punktzahl wird in der Regel hoch sein. Die Leistung des Modells bei neuen, unbekannten Daten (Live-Trading) wird fast immer niedriger sein als diese Punktzahl.
Wir verfügen nun über ein vorläufiges, aber potenziell riesiges „Alpha-Modell“. Obwohl wir die Zahl von 81,98 % nicht direkt als realistische Prognose für die Zukunft interpretieren können, ist sie ein starkes positives Signal und zeigt, dass in den Daten vorhersehbare Muster vorhanden sind und dass unser Framework diese erfolgreich erfasst hat!
Wir haben jetzt das Gefühl, gerade das erste Stück hochwertiges Golderz am Fuße eines Berges gefunden zu haben. Unser nächster Schritt besteht nicht darin, es sofort zu verkaufen, sondern speziellere Werkzeuge und Techniken (Optimierung von Funktionen und Anpassung von Parametern) einzusetzen, um den gesamten Berg effizienter und stabiler abzubauen.
Lassen Sie uns nun den Nebel des Krieges im „Mikrokosmos“ einführen – Auftragsfluss und Auftragsbuchmerkmale
Schritt 1: Datenerfassung aktualisieren – tiefere Kanäle abonnieren
Um Auftragsbuchdaten zu erhalten, muss die WebSocket-Verbindungsmethode von der ausschließlichen Anmeldung zu aggTrade (Deals) auf die Anmeldung zu aggTrade und depth (Tiefe) geändert werden.
Dies erfordert die Verwendung einer allgemeineren URL für Multi-Stream-Abonnements.
Schritt 2: Feature Engineering verbessern – Erstellen Sie eine Dreifaltigkeits-Feature-Matrix für „See, Land und Luft“.
Wir werden der Funktion calculate_features_and_labels die folgenden neuen Funktionen hinzufügen:
- Merkmale des Auftragsflusses (Alpha – Short):
alpha_15m: Der 15-Minuten-Orderflow-Ungleichgewichtsfaktor. Dies ist die Kernmetrik für den Orderflow, die wir zuvor besprochen haben. - Merkmale des Auftragsbuchs (Buch - Armee):
wobi_10s: Gewichtetes Orderbuch-Ungleichgewicht der letzten 10 Sekunden. Dies ist ein sehr hochfrequenter Indikator, der den Kauf- und Verkaufsdruck auf dem Markt misst.
spread_10s: Die durchschnittliche Geld-Brief-Spanne der letzten 10 Sekunden. Spiegelt die kurzfristige Liquidität wider. - Ursprüngliche Eigenschaften (Preis - Marine):
Wir werden die leistungsstärksten Funktionen der vorherigen Version beibehalten und optimieren.
Diese neue Feature-Matrix ist wie ein gemeinsames Kampfkommando, das gleichzeitig Echtzeitinformationen aus der „See (Preistrends)“, „Land (Marktpositionen)“ und „Luft (Auswirkungen von Transaktionen)“ erfasst und dessen Entscheidungsfindungsfähigkeiten den bisherigen weit überlegen sind.
Der Code lautet wie folgt:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
Dieser Code erfordert viele K-Line-Berechnungen
Dieser Bericht ist ein Vermögen wert, da er uns die „Idee“ und den „Charakter“ des Modells verrät.
- Historische Backtesting-Gesamtgewinnrate: 93,33 %
Das ist eine äußerst beeindruckende Zahl! Obwohl wir sie objektiv betrachten müssen (es handelt sich um einen In-Sample-Test), zeigt sie deutlich die enorme Vorhersagekraft unserer neu hinzugefügten Funktionen für Auftragsfluss und Auftragsbuch! Das Modell hat in den historischen Daten sehr ausgeprägte Muster gefunden. - Merkmalsbedeutung und gegenseitige Information
Der König ist geboren: volatility_15m (Volatilität) und price_change_5m (Preisänderung) sind weiterhin absolut zentral, was auch zu erwarten ist.
Rising Star: rsi_14 hat deutlich an Bedeutung gewonnen! Dies deutet darauf hin, dass der Stimmungsindikator „überkauft/überverkauft“ des RSI im kürzeren 5-Minuten-Zeitraum an Bedeutung gewonnen hat.
Möglicherweise zeigen auch wobi_10s (Orderbuch-Ungleichgewicht) und spread_10s (Spread) einen gewissen Beitrag. Das ist sehr ermutigend und deutet darauf hin, dass unsere Mikrostrukturfunktionen langsam funktionieren!
Reflexion: Der Beitrag von alpha_5m (Order Flow) ist nahezu Null. Dies kann an einer zu starken Vereinfachung unserer Alpha-Berechnungsmethode liegen, oder das 5-Minuten-Alpha und die 5-Minuten-Preisänderungen selbst enthalten zu viele überlappende Informationen. Dies ist für uns ein wichtiger Optimierungspunkt für die Zukunft. - Verwirrungsmatrix (wichtiger Beweis für Erfolg!)
Realer Anstieg (0):[22 0] -> Bei allen 22 realen Rallyes hat das Modell sie zu 100 % richtig vorhergesagt, ohne Fehler!
Realer Tropfen (1):[2 6] -> Von 8 tatsächlichen Rückgängen hat das Modell 6 richtig vorhergesagt und 2 übersehen (weil es sie für Anstiege gehalten hat).
Interpretation: Dieses Modell weist eine sehr interessante Persönlichkeit auf: Es ist ein extrem starker Bullen-Detektor, der bullische Signale nahezu perfekt erfasst. Es erkennt auch bärische Trends gut (6/8 = 75 % Genauigkeit), macht aber gelegentlich den Fehler, einen bärischen Trend mit einem Aufwärtstrend zu verwechseln.
Was kommt dann als nächstes
Einführung der „Trading Signal State Machine“
Dies ist der zentrale und genialste Teil dieses Upgrades. Wir werden eine globale Statusvariable wie g_active_signal einführen, um den aktuellen „Positions“-Status der Strategie zu verwalten (beachten Sie, dass dies nur ein virtueller Positionsstatus ist und keinen tatsächlichen Handel beinhaltet).
Die Arbeitslogik dieser Zustandsmaschine ist wie folgt:
- Ausgangszustand: Leerlauf
- Wenn sich die Strategie in diesem Zustand befindet, macht sie Vorhersagen für jede neue K-Linie, genau wie jetzt.
- Regimeübergänge: Sobald das Modell ein klares Signal vorhersagt (z. B. „Aufwärts“), wird die Strategie:
- Druckt ein einzelnes, auffälliges Einstiegssignal ins Journal, zum Beispiel: 🎯 Neues Handelssignal: Prognose nach oben! Beobachtungszeitraum 15 Minuten.
- Ändert den Strategiestatus von „Leerlauf“ auf „Im Signal“.
Notieren Sie die Auslösezeit und Richtung des Stromsignals.
- Positionsstatus: Im Signal
- Wenn sich die Strategie in diesem Zustand befindet, wird sie die Vorhersage neuer K-Linien vollständig einstellen. Sie kümmert sich nicht mehr um die Schwankungen jeder Minute und wechselt in den Modus „Lass die Kugel fliegen“.
- Es prüft lediglich die Zeit: ob seit der Auslösung des Signals 15 Minuten (die Länge von PREDICT_HORIZON) vergangen sind.
- Zustandsübergang: Nach der 15-minütigen Beobachtungsphase wird die Richtlinie:
- Drucken Sie ein klares Ausstiegssignal in das Protokoll, z. B. das Ende des 🏁-Signalzeitraums. Setzen Sie die Strategie zurück und suchen Sie nach neuen Möglichkeiten …
- Ändert den Strategiestatus von „Halten“ auf „Leerlauf“.
- An diesem Punkt beginnt die Strategie erneut mit der Vorhersage der neuen K-Linie und sucht nach der nächsten Handelsmöglichkeit.
Mit dieser einfachen Zustandsmaschine haben wir die Anforderungen perfekt erfüllt: ein Signal, ein vollständiger Beobachtungszyklus und keine Störinformationen während des Zeitraums.
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
Dann führe ich diesen Code aus
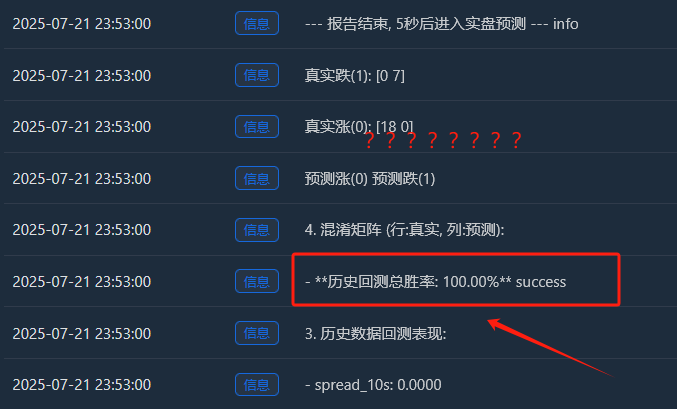
Detaillierte Analyse: Warum gibt es eine „perfekte“ Gewinnquote von 100 %?
Dieses „perfekte“ Ergebnis offenbart mehrere wichtige und tiefgreifende Erkenntnisse über maschinelles Lernen und Finanzmärkte. Es handelt sich nicht um einen Fehler, sondern um ein typisches Phänomen namens „Overfitting“, das unter bestimmten Bedingungen auftreten kann.
Was bedeutet „Überanpassung“?
-
Hier ist eine anschauliche Analogie: Stellen Sie sich vor, wir lassen einen Studenten (unser SVM-Modell) eine Reihe sehr kurzer, sehr einfacher Übungen durchführen (die 200 Candlestick-Datenpunkte, die wir gesammelt haben). Dieser Student ist sehr intelligent und lernt nicht allgemeine Problemlösungsmethoden, sondern merkt sich einfach die Antworten auf diese wenigen Aufgaben.
-
Ergebnis: Wenn wir ihn mit demselben Satz Übungsfragen testen (das ist unser „historischer Backtest“), kann er sicherlich eine perfekte Punktzahl von 100 erreichen. Wenn wir ihm jedoch einen völlig neuen Satz Fragen geben, den er noch nie zuvor gesehen hat (reale Terminmärkte), wird er wahrscheinlich keine davon beantworten können.
- Warum ist unser Modell „überangepasst“?
-
Die Trainingsbeispiele sind „zu wenige“ und „zu speziell“:
-
Obwohl wir 200 K-Linien (ca. 3,3 Stunden) gesammelt haben, betrug die endgültige Anzahl der „effektiven Anstiegs- und Abfall“-Proben, die unserer Definition entsprachen, laut Protokoll nur 18 + 7 = 25.
-
Für ein komplexes SVM-Modell sind 25 Stichproben wie ein paar Wellen im Ozean, was zu wenig ist.
-
Noch wichtiger ist, dass diese 25 Stichproben alle aus einer stark korrelierten Marktsituation am selben Nachmittag stammen. Sie weisen wahrscheinlich sehr ähnliche „Routinen“ auf.
- Die Modellfähigkeiten sind „zu stark“:
- SVM ist ein sehr leistungsfähiger, nichtlinearer Klassifikator. Seine Fähigkeiten sind mit denen eines Gehirns mit Supergedächtnis vergleichbar.
- Wenn ein leistungsfähiges Modell aus einem zu einfachen und repetitiven Datensatz lernt, neigt es dazu, alle Details und Störungen der Daten zu „speichern“, anstatt die allgemeineren Makrogesetze dahinter zu erlernen.
- Beweise aus der Konfusionsmatrix:
- Realer Anstieg (0):[18 0] -> 18 ansteigende Samples, alle perfekt auswendig gelernt.
- Realer Tropfen (1):[0 7] -> 7 fallende Samples, alle perfekt gespeichert.
- Dieses perfekte[ [18, 0], [Die Matrix [0, 7] ist ein unwiderlegbarer Beweis für die Überanpassung des Modells. Es macht fast keine Fehler, was in einem Finanzmarkt voller Zufälligkeiten von Natur aus unnormal ist.
Daher sollten wir diese Gewinnrate von 100 % wie folgt interpretieren:
„Das Modell hat in den letzten drei Stunden alle Muster der spezifischen Marktbedingungen bemerkenswert gut gelernt und gespeichert. Dies zeigt die Effektivität unserer Feature-Entwicklung und unseres Modell-Frameworks. Wir können jedoch absolut nicht erwarten, dass es in Zukunft eine so hohe Gewinnrate auf dem realen Markt beibehält. Dies ähnelt eher einem perfekten ‚Überraschungstest‘ als dem Endergebnis der ‚Hochschulaufnahmeprüfung‘.“

Auch mit maschinellem Lernen habe ich mich in letzter Zeit beschäftigt. Wir werden in der nächsten Ausgabe darüber sprechen!
Wir müssen bei diesem „voreingenommenen Schüler“ eine gründliche „Gedankentransformation“ durchführen. Unser Ziel ist es, seine Vorurteile abzubauen und ihm zu ermöglichen, „Höhen und Tiefen“ fair und objektiv zu betrachten.
