
Eine vorläufige Studie zur Anwendung des Python-Crawlers auf der FMZ-Plattform - Crawling von Binance-Ankündigungsinhalten
Ich habe mir kürzlich die Community und die Bibliothek angesehen und keine relevanten Informationen zu Python-Crawlern gefunden, die auf dem Geist der umfassenden Entwicklung als QUANT basieren. Ich habe die Konzepte und Kenntnisse im Zusammenhang mit Crawlern sehr einfach erlernt. Nachdem ich mehr darüber erfahren hatte, stellte ich fest, dass die „Crawler-Technologie“ eine ziemlich große „Falle“ ist. Dieser Artikel ist nur eine vorläufige Erkundung der „Crawler-Technologie“. Lassen Sie uns die einfachste Übung der Crawler-Technologie auf der quantitativen Handelsplattform FMZ durchführen.
brauchen
Händler, die gerne in neue Münzen investieren, hoffen immer, so schnell wie möglich Informationen über die Notierung der Münzen an der Börse zu erhalten. Es ist offensichtlich unrealistisch, die Website der Börse manuell im Auge zu behalten. Anschließend müssen Sie mithilfe eines Crawler-Skripts die Ankündigungsseite der Börse überwachen und neue Ankündigungen erkennen, damit Sie schnellstmöglich benachrichtigt und daran erinnert werden können.
Erste Erkundung
Lassen Sie uns als Ausgangspunkt ein sehr einfaches Programm verwenden (ein wirklich leistungsfähiges Crawler-Skript ist viel komplizierter, also lassen Sie sich Zeit). Die Programmlogik ist sehr einfach: Das Programm greift kontinuierlich auf die Ankündigungsseite der Börse zu, analysiert den erhaltenen HTML-Inhalt und erkennt, ob der Inhalt eines bestimmten Tags aktualisiert wird.
Implementierungscode
Sie können einige nützliche Crawler-Frameworks verwenden. Da die Anforderung jedoch sehr einfach ist, ist es auch möglich, sie direkt zu schreiben.
Es werden Python-Bibliotheken benötigt:
requests, das einfach als eine Bibliothek zum Zugriff auf Webseiten verstanden werden kann.
bs4, was einfach als eine Bibliothek zum Parsen des HTML-Codes einer Webseite verstanden werden kann.
Code:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
laufen
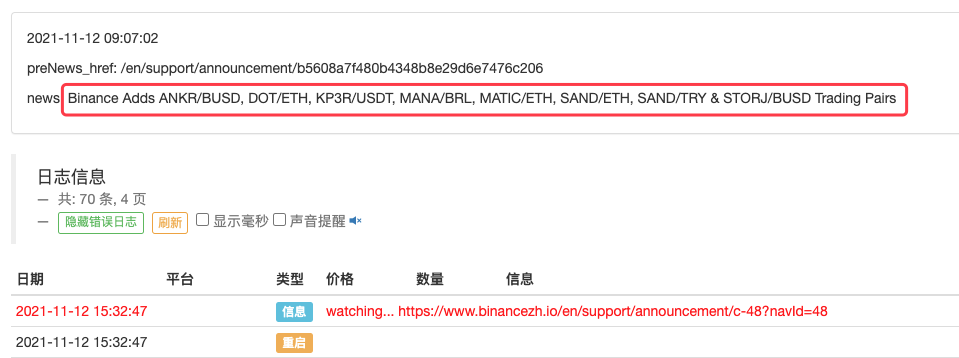
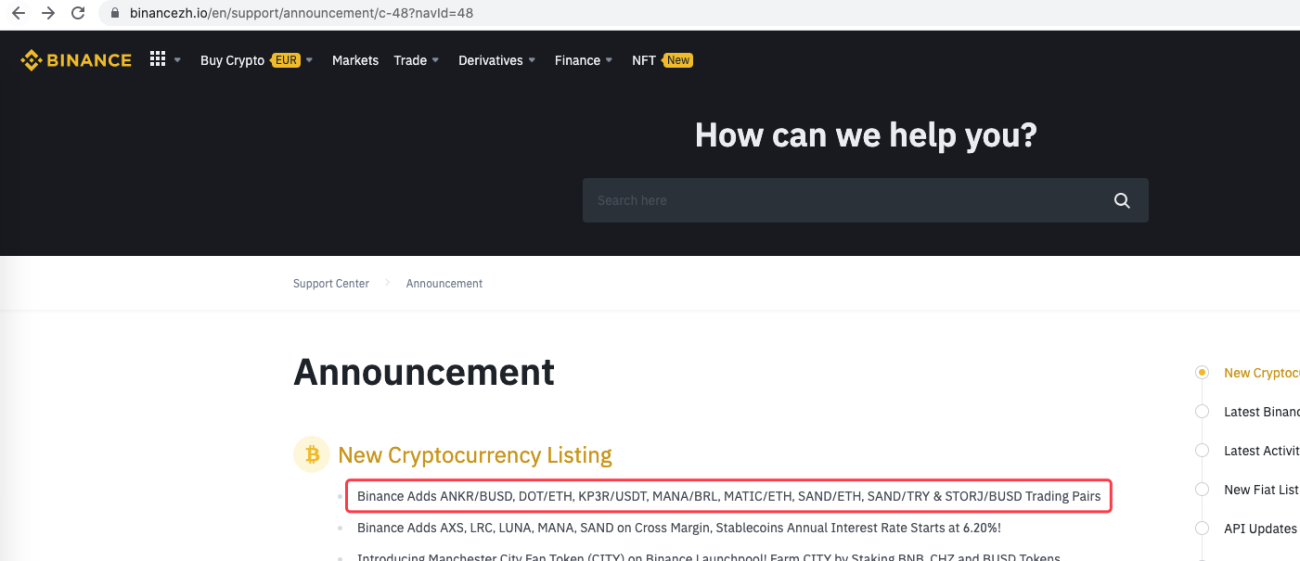
Es kann sogar erweitert werden, um beispielsweise zu erkennen, wann eine neue Ankündigung erscheint. Analysieren Sie die neuen Währungen in der Ankündigung und erteilen Sie automatisch Aufträge für neue Transaktionen.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1