

Clasificador maduro: La Máquina de Vectores de Soporte (SVM) es un algoritmo de clasificación binaria (o multivariante) potente y maduro. Predecir si una acción subirá o bajará es un problema típico de clasificación binaria.
Capacidad no lineal: al utilizar funciones de kernel (como el kernel RBF), SVM puede capturar relaciones no lineales complejas entre características de entrada, lo cual es crucial para los datos del mercado financiero.
Basado en características: La eficacia del modelo depende en gran medida de las características que se le proporcionen. El factor alfa calculado ahora es un buen comienzo, y podemos desarrollar más características similares para mejorar la capacidad predictiva.
Esta vez comencé con 3 esquemas de características:
1: Características del flujo de órdenes de alta frecuencia:
alpha_1min: Factor de desequilibrio del flujo de órdenes calculado en función de todos los ticks del último minuto.
alpha_5min: Factor de desequilibrio del flujo de órdenes calculado en función de todos los ticks de los últimos 5 minutos.
alpha_15min: Factor de desequilibrio del flujo de órdenes calculado en función de todos los ticks de los últimos 15 minutos.
ofi_1min (Desequilibrio del flujo de órdenes): La relación entre el volumen de compra y el volumen de venta en un período de 1 minuto. Es más directo que el alfa.
vol_per_trade_1min: Volumen promedio por operación en 1 minuto. Indica que las órdenes grandes impactan el mercado.
2: Características de precio y volatilidad:
log_return_5min: La tasa de retorno logarítmica durante los últimos 5 minutos, log(P_t / P_{t-5min}).
volatility_15min: La desviación estándar de los retornos logarítmicos durante los últimos 15 minutos, una medida de volatilidad a corto plazo.
atr_14 (Rango verdadero promedio): valor ATR basado en las últimas 14 velas de 1 minuto, un indicador de volatilidad clásico.
rsi_14 (Índice de fuerza relativa): es una medida de las condiciones de sobrecompra y sobreventa basada en los valores RSI de las últimas 14 velas de 1 minuto.
3: Características del tiempo:
hour_of_day: Hora actual (0-23). Los mercados se comportan de forma diferente en distintos períodos de tiempo (p. ej., sesiones asiáticas, europeas o americanas).
day_of_week: Día de la semana (0-6). Los fines de semana y los días laborables tienen diferentes patrones de fluctuación.
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
Luego utilice tres categorías para distinguir entre ascendente, descendente y lateral.
La idea central de la selección de características: encontrar "buenos compañeros de equipo" y eliminar "malos compañeros de equipo".
Nuestro objetivo es encontrar un conjunto de características que:
- Alta relevancia: cada característica tiene una fuerte correlación con los cambios de precios futuros (nuestra etiqueta objetivo).
- Baja redundancia: Las características no deben contener demasiada información duplicada. Por ejemplo, el "momento de 5 minutos" y el "momento de 6 minutos" son muy similares. Incluir ambos no mejorará mucho el modelo e incluso podría generar ruido.
- Estabilidad: La validez de una característica no puede cambiar demasiado rápido con el tiempo. Una característica que solo es válida un día es peligrosa.
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
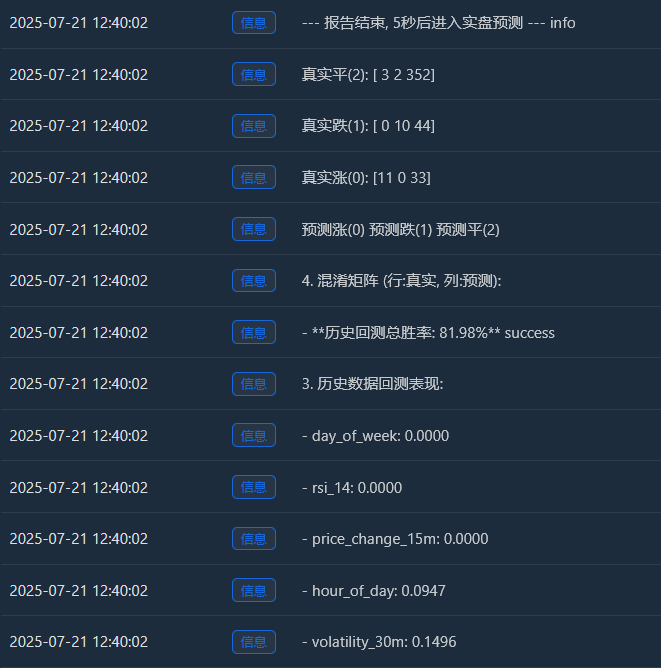
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
El proceso es:
Recopilación de datos
Importancia de las características

Información mutua entre características y etiquetas e información de backtesting
Al principio pensé que una tasa de victorias del 65% sería suficiente, pero no esperaba que alcanzara el 81,98%. Mi primera reacción debería ser: "Genial, pero es demasiado bueno para ser verdad. Debe haber algo que valga la pena explorar aquí".
1Interpretación en profundidad del informe de análisis, interpretando su contenido uno por uno:
- Importancia de las características e información mutua:
La volatilidad_30m y la variación de precio_15m son las características más importantes. Esto es lógico, ya que indica que la tendencia reciente del mercado y la volatilidad son los predictores más sólidos del futuro.
La hora del día también contribuye un poco, indicando que el modelo captura los patrones comerciales en diferentes momentos del día.
Las contribuciones de rsi_14 y day_of_week son casi nulas, lo que sugiere que estas dos características podrían ser "compañeras de equipo" con el conjunto de datos y la combinación de características actuales. Podemos considerar eliminarlas en el futuro para simplificar el modelo y evitar el ruido. - Matriz de confusión (¡esto es mucha información!)
Aumento real (0):[11 0 33] -> De 44 (11+0+33) repuntes reales, el modelo predijo correctamente 11, pero los predijo erróneamente como “consolidación” 33 veces.
Caída real (1):[0 10 44] -> De 54 (0+10+44) caídas reales, el modelo predijo correctamente 10, pero las predijo erróneamente como una "tendencia lateral" 44 veces.
Ping real (2):[3 2 352] -> ¡De 357 (3+2+352) consolidaciones reales, el modelo predijo correctamente 352 de ellas! - Tasa total de éxito de backtest histórico: 81,98 %
La principal razón de esta alta tasa de éxito reside en la altísima precisión del modelo para predecir la consolidación. De un total de aproximadamente 455 muestras, más de 350 eran mercados de consolidación, y el modelo los identificó casi a la perfección.
¡Esta es una habilidad muy valiosa en sí misma! Un modelo que te diga con precisión "mejor no moverte ahora" puede ayudarte a ahorrarte muchas comisiones y transacciones inválidas.
2¿Por qué la tasa de ganancias real podría ser inferior al 81,98%?
- La definición de "consolidación" es demasiado imprecisa: nuestro SPREAD_THRESHOLD es del 0,5 %. Las fluctuaciones de precios no superiores al 0,5 % en un período de 15 minutos son bastante comunes. Por lo tanto, las muestras de "consolidación" representan la gran mayoría (aproximadamente el 80 %) de nuestro conjunto de datos. El modelo ha aprendido ingeniosamente: "Cuando no estoy seguro, adivino 'consolidación' con gran precisión". Esto es estadísticamente correcto, pero en el trading, nos preocupa más predecir los movimientos de precios.
- Capacidad de predecir ascensos y descensos:
Tasa de acierto en la predicción de tendencias alcistas: El modelo predijo 11 + 0 + 3 = 14 tendencias alcistas, de las cuales solo 11 fueron correctas. La tasa de acierto es de 11/14 = 78,5 %. ¡Excelente!
Tasa de éxito en la predicción de descensos: El modelo predijo 0 + 10 + 2 = 12 descensos y acertó en 10 de ellos. La tasa de éxito es de 10/12 = 83,3 %. ¡Impresionante! - Sobreajuste en la muestra: Esta prueba se realiza con datos conocidos por el modelo (es decir, los datos utilizados para el entrenamiento y las pruebas). Es como pedirle a un estudiante que realice un examen que acaba de completar; la puntuación suele ser alta. El rendimiento del modelo con datos nuevos e inéditos (operaciones en tiempo real) casi siempre será inferior a esta puntuación.
Ahora contamos con un "Modelo Alfa" preliminar, pero potencialmente enorme. Si bien no podemos interpretar directamente la cifra del 81,98 % como una predicción realista para el futuro, es una señal muy positiva que demuestra que existen patrones predecibles en los datos y que nuestro marco los ha capturado con éxito.
Ahora sentimos que acabamos de encontrar el primer mineral de oro de alta calidad al pie de una montaña. Nuestro siguiente paso no es venderlo inmediatamente, sino usar herramientas y técnicas más especializadas (optimizando características y ajustando parámetros) para extraer toda la montaña de forma más eficiente y estable.
Ahora introduzcamos la niebla de guerra en el “microcosmos”: características del flujo de órdenes y del libro de órdenes.
Paso 1: Actualizar la recopilación de datos: suscribirse a canales más profundos
Para obtener datos del libro de órdenes, el método de conexión WebSocket debe modificarse de suscribirse solo a aggTrade (transacciones) a suscribirse tanto a aggTrade como a Depth (profundidad).
Esto requiere que utilicemos una URL de suscripción de transmisión múltiple más general.
Paso 2: Mejorar la ingeniería de características: crear una matriz de características trinitaria para "mar, tierra y aire".
Agregaremos las siguientes características nuevas a la función calculate_features_and_labels:
- Características del flujo de órdenes (Alfa - Corto):
alpha_15m: El factor de desequilibrio del flujo de órdenes de 15 minutos. Esta es la métrica principal del flujo de órdenes que analizamos anteriormente. - Características del Libro de Órdenes (Libro - Ejército):
wobi_10s: Desequilibrio ponderado del libro de órdenes en los últimos 10 segundos. Este indicador de alta frecuencia mide la presión de compra y venta en el mercado.
spread_10s: El diferencial promedio entre oferta y demanda de los últimos 10 segundos. Refleja la liquidez a corto plazo. - Características originales (Precio – Marina):
Mantendremos las características de mejor rendimiento de la versión anterior y las optimizaremos.
Esta nueva matriz de características es como un comando de combate conjunto, que capta simultáneamente inteligencia en tiempo real del "mar (tendencias de precios)", "tierra (posiciones de mercado)" y "aire (impacto de las transacciones)", y su capacidad de toma de decisiones será muy superior a la anterior.
El código es el siguiente:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
Este código requiere muchos cálculos de línea K
Este informe vale una fortuna, ya que nos cuenta el "pensamiento" y el "carácter" de la modelo.
- Tasa total de éxito de backtesting histórico: 93,33 %
¡Esta es una cifra impresionante! Si bien debemos analizarla objetivamente (se trata de una prueba dentro de la muestra), demuestra claramente el inmenso poder predictivo de nuestras nuevas funciones de flujo de órdenes y libro de órdenes. El modelo ha encontrado patrones muy sólidos en los datos históricos. - Importancia de las características e información mutua
Ha nacido el rey: volatility_15m (volatilidad) y price_change_5m (cambio de precio) siguen siendo absolutamente fundamentales, lo cual es como se esperaba.
Estrella en ascenso: ¡El rsi_14 ha experimentado un aumento significativo en su importancia! Esto indica que, en el marco temporal más corto de 5 minutos, el indicador de sentimiento de "sobrecompra/sobreventa" del RSI ha cobrado mayor relevancia.
Potencialmente, wobi_10s (desequilibrio del libro de órdenes) y spread_10s (spread) también muestran cierta contribución. Esto es muy alentador y sugiere que nuestras características de microestructura están empezando a funcionar.
Reflexión: La contribución de alpha_5m (flujo de órdenes) es prácticamente nula. Esto podría deberse a una simplificación excesiva de nuestro método de cálculo de alfa, o a que el alfa de 5 minutos y los cambios de precio de 5 minutos contienen demasiada información superpuesta. Este es un punto de optimización importante para nosotros en el futuro. - Matriz de confusión (¡evidencia clave del éxito!)
Aumento real (0):[22 0] -> En los 22 rallies reales, el modelo los predijo con un 100% de acierto, ¡sin ningún error!
Caída real (1):[2 6] -> De 8 disminuciones reales, el modelo predijo correctamente 6 y no detectó 2 (confundiéndolas con aumentos).
Interpretación: Este modelo exhibe una personalidad muy interesante: es un detector alcista extremadamente potente, que capta señales alcistas casi a la perfección. También es eficaz en la identificación de tendencias bajistas (6/8 = 75 % de precisión), pero ocasionalmente comete el error de confundir una tendencia bajista con una alcista.
¿Y luego qué viene?
Presentamos la "Máquina de estados de señales comerciales"
Esta es la parte principal y más ingeniosa de esta actualización. Introduciremos una variable de estado global, como g_active_signal, para gestionar el estado de posición actual de la estrategia (tenga en cuenta que se trata solo de un estado de posición virtual y no implica operaciones reales).
La lógica de funcionamiento de esta máquina de estados es la siguiente:
- Estado inicial: inactivo
- Cuando la estrategia esté en este estado, hará predicciones para cada nueva línea K, tal como lo hace ahora.
- Transiciones de régimen: Una vez que el modelo predice una señal clara (por ejemplo, “Arriba”), la estrategia:
- Imprime una señal de entrada única y llamativa en el diario, por ejemplo: 🎯 Nueva señal de trading: ¡Pronóstico al alza! Periodo de observación: 15 minutos.
- Cambia el estado de la estrategia de Inactivo a En señal.
Registre el tiempo de activación y la dirección de la señal actual.
- Estado de la posición: en señal
- Cuando la estrategia se encuentra en este estado, deja de predecir nuevas líneas K. Ya no le importan las fluctuaciones de cada minuto y entra en modo de "soltar la bala".
- Lo único que hace es comprobar el tiempo: si han pasado 15 minutos (la duración de PREDICT_HORIZON) desde que se activó la señal.
- Transición de estado: Después del período de observación de 15 minutos, la política:
- Imprima una señal de salida clara en el registro, como el final del periodo de la señal 🏁. Reinicie la estrategia y busque nuevas oportunidades...
- Cambia el estado de la estrategia de retención a inactivo.
- En este punto, la estrategia comenzará a predecir nuevamente la nueva línea K y buscará la próxima oportunidad comercial.
Con esta sencilla máquina de estados, hemos logrado perfectamente los requisitos: una señal, un ciclo de observación completo y ninguna información de interferencia durante el período.
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
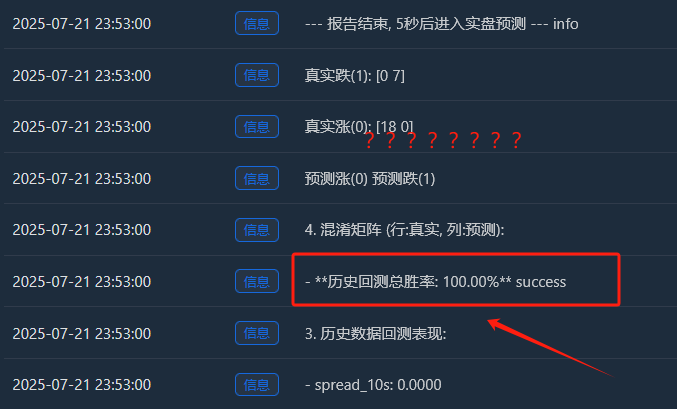
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
Luego ejecuto este código
Análisis en profundidad: ¿Por qué existe una tasa de ganancia “perfecta” del 100%?
Este resultado "perfecto" revela varias perspectivas importantes y profundas sobre el aprendizaje automático y los mercados financieros. No se trata de un error, sino de un fenómeno típico conocido como "sobreajuste", que puede ocurrir en ciertas condiciones.
¿Qué significa “sobreajuste”?
-
He aquí una analogía vívida: Imaginemos que un estudiante (nuestro modelo SVM) realiza una serie de ejercicios muy cortos y sencillos (los 200 puntos de datos de velas que recopilamos). Este estudiante es muy inteligente y, en lugar de aprender métodos generales de resolución de problemas, simplemente memoriza las respuestas a estos pocos ejercicios.
-
Resultado: Al realizarle el mismo conjunto de preguntas de práctica (este es nuestro "backtest histórico"), seguramente obtendrá una puntuación perfecta de 100. Sin embargo, si le damos un conjunto de preguntas completamente nuevo que nunca ha visto (mercados de futuros reales), es probable que no pueda responder a ninguna.
- ¿Por qué nuestro modelo se “sobreajusta”?
-
Las muestras de entrenamiento son "demasiado escasas" y "demasiado especiales":
-
Aunque recolectamos 200 líneas K (aproximadamente 3,3 horas), según el registro, el número final de muestras de "ascenso y descenso efectivos" que cumplieron con nuestra definición fue solo 18 + 7 = 25.
-
Para un modelo SVM complejo, 25 muestras son como unas cuantas olas en el océano, lo cual es demasiado pequeño.
-
Más importante aún, estas 25 muestras provienen de una situación de mercado altamente correlacionada en la misma tarde. Es probable que tengan rutinas muy similares.
- Las capacidades del modelo son “demasiado fuertes”:
- SVM es un clasificador no lineal muy potente. Su capacidad es como la de un cerebro con supermemoria.
- Cuando un modelo poderoso aprende de un conjunto de datos demasiado simple y repetitivo, tiende a "memorizar" todos los detalles y el ruido de los datos en lugar de aprender las leyes macro más universales que hay detrás de ellos.
- Evidencia de la matriz de confusión:
- Aumento real (0):[18 0] -> 18 muestras ascendentes, todas perfectamente memorizadas.
- Caída real (1):[0 7] -> 7 muestras cayendo, todas recordadas perfectamente.
- Este perfecto[ [18, 0], [La matriz [0, 7] es una prueba irrefutable del sobreajuste del modelo. Prácticamente no comete errores, lo cual es inherentemente anormal en un mercado financiero lleno de aleatoriedad.
Por lo tanto, debemos interpretar esta tasa de éxito del 100% de la siguiente manera:
El modelo ha aprendido y memorizado de forma notable todos los patrones de las condiciones específicas del mercado durante las últimas tres horas. Esto demuestra la eficacia de nuestra ingeniería de características y del marco del modelo. Sin embargo, no podemos esperar en absoluto que mantenga una tasa de éxito tan alta en el mercado real en el futuro. Esto se parece más a un examen sorpresa perfecto que al resultado final de un examen de admisión a la universidad.

El aprendizaje automático también es algo que he estado explorando recientemente. ¡Hablaremos de ello en el próximo número!
Necesitamos llevar a cabo una profunda transformación mental en este estudiante con prejuicios. Nuestro objetivo es romper sus prejuicios y permitirle ver sus altibajos de forma justa y objetiva.
