

1. Breve introducción
Las redes neuronales profundas se han vuelto cada vez más populares en los últimos años, resolviendo problemas previamente irresolubles en muchos campos y demostrando sus poderosas capacidades. En la predicción de series temporales, la red neuronal de precios que se utiliza habitualmente es la RNN, porque la RNN no solo tiene entrada de datos actuales, sino también de datos históricos. Por supuesto, cuando hablamos de la predicción de precios por RNN, a menudo hablamos de un tipo de RNN. :LSTM. Este artículo construirá un modelo para predecir los precios de Bitcoin basado en PyTorch. Aunque hay mucha información relevante en Internet, todavía no es lo suficientemente completa y hay relativamente pocas personas que usan PyTorch. Aún es necesario escribir un artículo. El resultado final es utilizar el precio de apertura, el precio de cierre, precio más alto, precio más bajo y volumen de transacciones del mercado de Bitcoin. para predecir el próximo precio de cierre. Mi conocimiento personal de redes neuronales es promedio y agradezco sus críticas y correcciones.
Este tutorial ha sido elaborado por FMZ, el inventor de la plataforma de comercio cuantitativo de divisas digitales (www.fmz.com). Le damos la bienvenida a unirse al grupo QQ: 863946592 para comunicarse.
2. Datos y referencias
Un ejemplo de predicción de precios relacionado: https://yq.aliyun.com/articles/538484
Introducción detallada al modelo RNN: https://zhuanlan.zhihu.com/p/27485750
Comprender la entrada y la salida de RNN: https://www.zhihu.com/question/41949741/answer/318771336
Acerca de pytorch: Documentación oficial https://pytorch.org/docs Busque otra información usted mismo.
Además, se requieren algunos conocimientos previos para comprender este artículo, como pandas/crawlers/procesamiento de datos, etc., pero no importa si no los sabes.
3. Parámetros del modelo LSTM de PyTorch
Parámetros de LSTM:
Cuando vi por primera vez estos parámetros densamente empaquetados en el documento, mi reacción fue:

Mientras leía lentamente, finalmente lo entendí.

input_size: El tamaño de la característica del vector de entrada x. Si se utiliza el precio de cierre para predecir el precio de cierre, entonces input_size=1; si el precio de cierre se predice mediante el máximo de apertura y el mínimo de cierre, entonces input_size=4
hidden_size:Tamaño de la capa oculta
num_layers: Número de capas de RNN
batch_first: Si es verdadero, la primera dimensión de entrada es batch_size. Este parámetro también es muy confuso y se describirá en detalle a continuación.
Parámetros de datos de entrada:
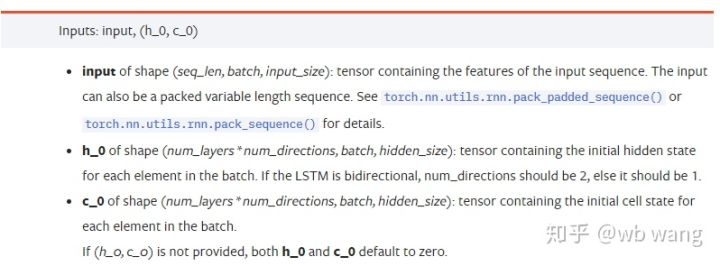
input:Los datos de entrada específicos son un tensor tridimensional con una forma específica de (seq_len, batch, input_size). Entre ellos, seq_len se refiere a la longitud de la secuencia, es decir, cuánto tiempo debe tener en cuenta el LSTM de datos históricos. Tenga en cuenta que esto se refiere únicamente al formato de los datos, no a la estructura interna del LSTM. El mismo modelo LSTM puede Los datos de entrada tienen diferentes seq_len y pueden dar predicciones. Resultado; lote se refiere al tamaño del lote, que representa cuántos grupos de datos diferentes hay; input_size es el input_size anterior.
h_0: Estado oculto inicial, la forma es (num_layers * num_directions, lote, tamaño_oculto), si es una red bidireccional num_directions=2
c_0:Estado inicial de la celda, la forma es la misma que la anterior, se puede dejar sin especificar.
Parámetros de salida:
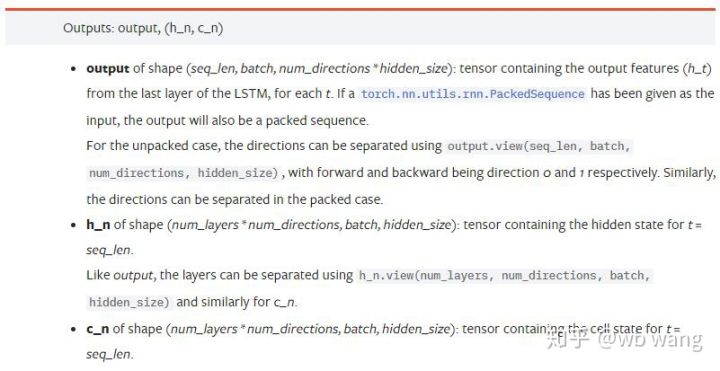
output: Forma de salida (seq_len, batch, num_directions * hidden_size), tenga en cuenta que está relacionada con el parámetro de modelo batch_first
h_n: estado h en el momento t = seq_len, misma forma que h_0
c_n: estado c en el momento t = seq_len, misma forma que c_0
4. Ejemplo simple de entrada y salida de LSTM
Primero importe los paquetes necesarios
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
Definición del modelo LSTM
python
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
Preparando datos de entrada
python
x = torch.randn(3,4,5)
# x的值为:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
La forma de x es (3,4,5), ya que definimosbatch_first=True, en este momento, batch_size es 3, sqe_len es 4 y input_size es 5. incógnita[0] representa el primer lote.
Si no se define batch_first, el valor predeterminado es Falso y los datos se representan de forma completamente diferente, con un tamaño de lote de 4, un sqe_len de 3 y un input_size de 5. En este momento x[0] representa los datos de todos los lotes en t=0, y así sucesivamente. Personalmente creo que esta configuración no es intuitiva, por eso agregué el parámetrobatch_first=True.
La conversión de datos entre ambos también es muy conveniente:x.permute(1,0,2)
Entrada y salida
La forma de entrada y salida del LSTM es fácil de confundir, con la ayuda de la siguiente figura se puede ayudar a comprender:
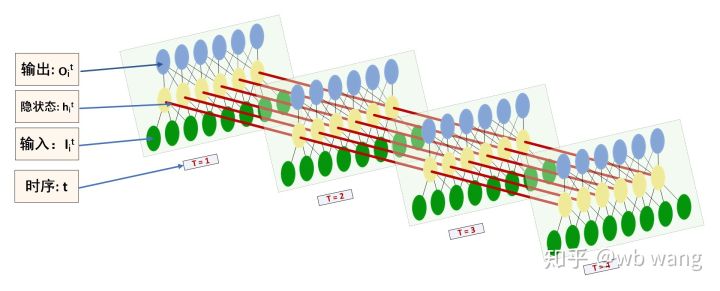
Fuente: https://www.zhihu.com/question/41949741/answer/318771336
python
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) #在这里思考一下,如果batch_first=False输出的大小会是多少?
print(hn.size())
print(cn.size())
#结果
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
Observe los resultados de salida, que son consistentes con la explicación del parámetro anterior. Tenga en cuenta que el segundo valor de hn.size() es 3, lo cual es consistente con el tamaño de batch_size, lo que indica que no se guarda ningún estado intermedio en hn, solo el último paso.
Dado que nuestra red LSTM tiene dos capas, la salida de la última capa de hn es en realidad el valor de la salida, y la forma de la salida es[3, 4, 10], guarda los resultados de todos los momentos t=0,1,2,3, por lo que:
python
hn[-1][0] == output[0][-1] #第一个batch在hn最后一层的输出等于第一个batch在t=3时output的结果
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5. Preparar los datos del mercado de Bitcoin
Mucho de lo que he dicho antes es solo un preludio. Es muy importante comprender la entrada y la salida de LSTM. De lo contrario, es fácil cometer errores si copia al azar algunos códigos de Internet. Debido a la poderosa capacidad de LSTM en series temporales, incluso si el modelo está equivocado, se puede obtener al final. Buenos resultados.
Adquisición de datos
Los datos utilizados son los datos de mercado del par comercial BTC_USD del intercambio Bitfinex.
python
import requests
import json
resp = requests.get('https://q.fmz.com/chart/history?symbol=bitfinex.btc_usd&resolution=15&from=0&to=0&from=1525622626&to=1562658565')
data = resp.json()
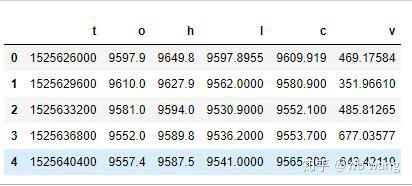
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
El formato de los datos es el siguiente:
Preprocesamiento de datos
python
df.index = df['t'] # index设为时间戳
df = (df-df.mean())/df.std() # 数据的标准化,否则模型的Loss会非常大,不利于收敛
df['n'] = df['c'].shift(-1) # n为下一个周期的收盘价,是我们预测的目标
df = df.dropna()
df = df.astype(np.float32) # 改变下数据格式适应pytorch
El método de estandarización de datos es muy básico y puede presentar algunos problemas. Es solo una demostración. Puedes utilizar la estandarización de datos como el rendimiento.
Preparando datos de entrenamiento
python
seq_len = 10 # 输入10个周期的数据
train_size = 800 # 训练集batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) #变化形状,-1代表的值会自动计算
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
Las formas finales de train_x y train_y son: antorcha.Size([800, 10, 5]), torch.Size([800, 10, 1]). Dado que nuestro modelo predice el precio de cierre del próximo período basándose en datos de 10 períodos, teóricamente, 800 lotes solo requieren 800 precios de cierre previstos. Pero train_y tiene 10 datos en cada lote. De hecho, se conservan los resultados intermedios de cada predicción de lote, no solo el último. Al calcular la pérdida final, se pueden tener en cuenta los 10 resultados de predicción y compararlos con los valores reales en train_y. En teoría, también es posible calcular únicamente la pérdida del último resultado de predicción. Dibujé un diagrama aproximado para ilustrar este problema. Dado que el modelo LSTM en realidad no contiene el parámetro seq_len, el modelo se puede aplicar a diferentes longitudes y los resultados de predicción intermedios también son significativos, por lo que tiendo a fusionar el cálculo de pérdida.
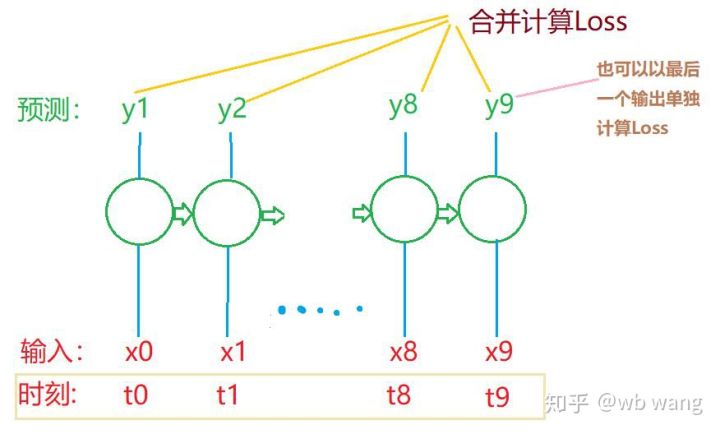
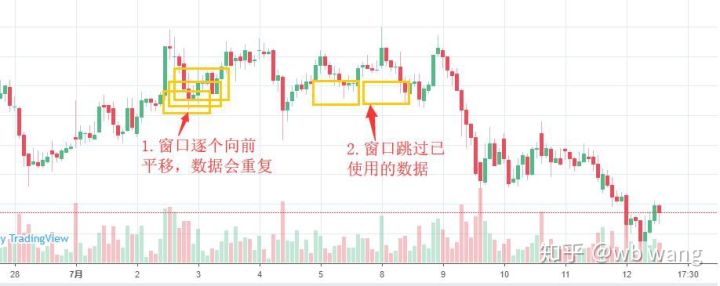
Tenga en cuenta que al preparar los datos de entrenamiento, el movimiento de la ventana es irregular y los datos que se han utilizado ya no se utilizan. Por supuesto, las ventanas también se pueden mover una a una, de modo que el conjunto de entrenamiento obtenido sea mucho más grande. . Pero sentí que los datos del lote adyacente eran demasiado repetitivos, así que adopté el método actual.
6. Construcción del modelo LSTM
El modelo final es el siguiente, que incluye un LSTM de dos capas y una capa lineal.
python
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # 线性层,把LSTM的结果输出成一个值
def forward(self, x):
x, _ = self.rnn(x) # 如果不理解前向传播中数据维度的变化,可单独调试
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size为5,代表了高开低收和交易量. 隐含层为10.
7. Comience a entrenar el modelo
Por fin empecé el entrenamiento, el código es el siguiente:
python
criterion = nn.MSELoss() # 使用了简单的均方差损失函数
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # 优化函数,lr可调
for epoch in range(600): # 由于速度很快,这里的epoch多一些
out = net(train_x) # 由于数据量很小, 直接拿全量数据计算
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # 反向传播损失
optimizer.step() # 更新参数
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
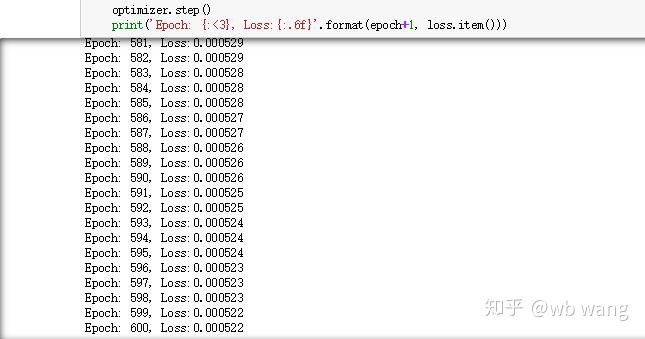
Los resultados del entrenamiento son los siguientes:
8. Evaluación del modelo
Los valores previstos del modelo son:
python
p = net(torch.from_numpy(data_X))[:,-1,0] # 这里只取最后一个预测值作为比较
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
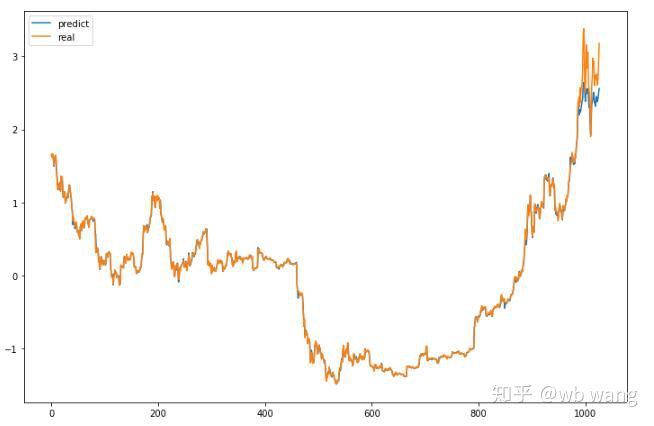
Como se puede ver en la figura, el grado de ajuste de los datos de entrenamiento (antes de 800) es muy alto, pero el precio de Bitcoin ha subido a un nuevo máximo más tarde, y el modelo no ha visto estos datos, por lo que la predicción es Incapaz de desempeñarse bien. Esto también demuestra que había un problema en la estandarización de datos anterior.
Aunque el precio previsto puede no ser exacto, ¿qué tan precisa es la predicción de la subida y la bajada? Eche un vistazo a una sección de los datos de predicción:
python
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
La precisión de la predicción de subida y bajada alcanzó el 81,4%, lo que superó mis expectativas. No sé si cometí un error en alguna parte.
Por supuesto, este modelo no tiene ningún valor real, pero es simple y fácil de entender. Úselo como punto de partida. Habrá más cursos introductorios sobre la aplicación de redes neuronales en la cuantificación de monedas digitales.


