
Un estudio preliminar sobre la aplicación del rastreador Python en la plataforma FMZ: rastreo del contenido del anuncio de Binance
Recientemente revisé la comunidad y la biblioteca y no encontré información relevante sobre los rastreadores de Python, basado en el espíritu de desarrollo integral como QUANT. Aprendí los conceptos y conocimientos relacionados con los crawlers de forma muy sencilla. Después de aprender más sobre el tema, descubrí que la "tecnología de rastreo" es un gran "pozo". Este artículo es solo una exploración preliminar de la "tecnología de rastreo". Realicemos la práctica más simple de tecnología de rastreo en la plataforma de comercio cuantitativo FMZ.
necesidad
Los comerciantes a quienes les gusta invertir en nuevas monedas, siempre esperan obtener la información sobre la inclusión de monedas en el intercambio lo antes posible. Obviamente, no es realista vigilar manualmente el sitio web de intercambio. Luego, debe utilizar un script de rastreo para monitorear la página de anuncios de intercambio y detectar nuevos anuncios para que pueda recibir notificaciones y recordatorios lo antes posible.
Exploración inicial
Utilicemos un programa muy simple como inicio (un script de rastreo verdaderamente potente es mucho más complicado, así que tómate tu tiempo). La lógica del programa es muy simple: permitir que el programa acceda continuamente a la página de anuncios del intercambio, analice el contenido HTML obtenido y detecte si el contenido de una etiqueta específica se actualiza.
Código de Implementación
Puedes utilizar algunos marcos de rastreo útiles. Sin embargo, considerando que el requisito es muy simple, también es posible escribirlo directamente.
Se necesitan bibliotecas de Python:
requests, que puede entenderse simplemente como una biblioteca utilizada para acceder a páginas web.
bs4, que puede entenderse simplemente como una biblioteca utilizada para analizar el código HTML de una página web.
Código:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
correr
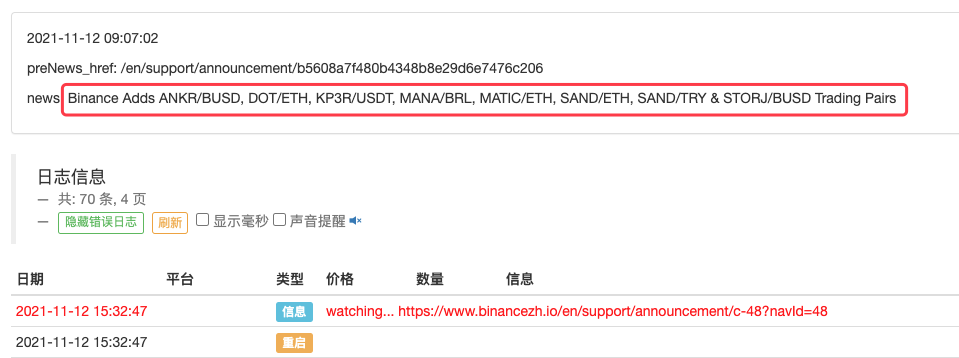
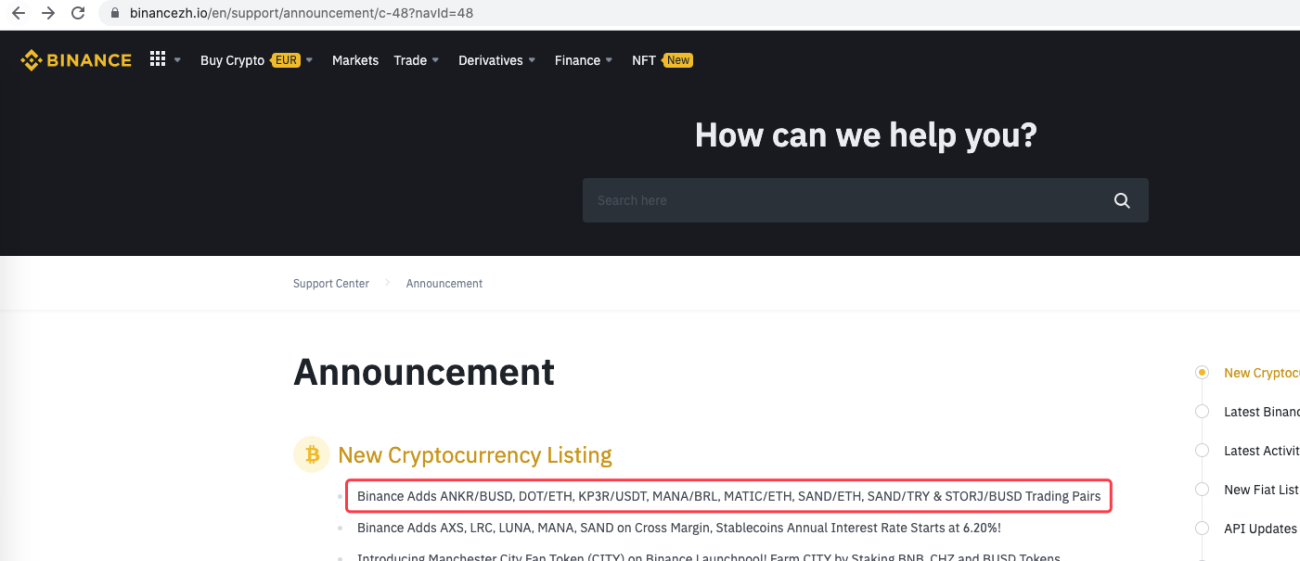
Incluso se puede ampliar para detectar cuándo aparece un nuevo anuncio, por ejemplo. Analice las nuevas monedas en el anuncio y coloque automáticamente órdenes para nuevas transacciones.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1