

Classificateur mature : La machine à vecteurs de support (SVM) est un algorithme de classification binaire (ou multivariée) puissant et mature. Prédire la hausse ou la baisse d'une action est un problème typique de classification binaire.
Capacité non linéaire : en utilisant des fonctions de noyau (telles que le noyau RBF), SVM peut capturer des relations non linéaires complexes entre les caractéristiques d'entrée, ce qui est crucial pour les données du marché financier.
Axé sur les fonctionnalités : l'efficacité du modèle dépend en grande partie des « fonctionnalités » que vous lui fournissez. Le facteur alpha calculé maintenant est un bon début, et nous pouvons développer davantage de fonctionnalités de ce type pour améliorer la puissance prédictive.
Cette fois, j'ai commencé avec 3 aperçus de fonctionnalités :
1 : Caractéristiques du flux d'ordres à haute fréquence :
alpha_1min : Facteur de déséquilibre du flux d'ordres calculé sur la base de tous les ticks de la dernière minute.
alpha_5min : Facteur de déséquilibre du flux d'ordres calculé sur la base de tous les ticks au cours des 5 dernières minutes.
alpha_15min : Facteur de déséquilibre du flux d'ordres calculé sur la base de tous les ticks au cours des 15 dernières minutes.
ofi_1min (Déséquilibre du flux d'ordres) : ratio (volume d'achat / volume de vente) sur une période d'une minute. Ce ratio est plus direct que l'alpha.
vol_per_trade_1min : Volume moyen par transaction sur une minute. Signe d'un impact des ordres importants sur le marché.
2 : Caractéristiques du prix et de la volatilité :
log_return_5min : Le taux de retour logarithmique au cours des 5 dernières minutes, log(P_t / P_{t-5min}).
volatilité_15min : L'écart type des rendements logarithmiques au cours des 15 dernières minutes, une mesure de la volatilité à court terme.
atr_14 (Average True Range) : valeur ATR basée sur les 14 derniers chandeliers d'une minute, un indicateur de volatilité classique.
rsi_14 (indice de force relative) : il s'agit d'une mesure des conditions de surachat et de survente basée sur les valeurs RSI des 14 derniers chandeliers d'une minute.
3 : Caractéristiques temporelles :
hour_of_day : Heure actuelle (0-23). Les marchés se comportent différemment selon les périodes (par exemple, sessions asiatiques, européennes ou américaines).
day_of_week : Jour de la semaine (0-6). Les week-ends et les jours de semaine présentent des fluctuations différentes.
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
Utilisez ensuite trois catégories pour distinguer entre la montée, la descente et le déplacement latéral.
L'idée principale du filtrage des fonctionnalités : trouver de « bons coéquipiers » et éliminer les « mauvais coéquipiers »
Notre objectif est de trouver un ensemble de fonctionnalités qui :
- Haute pertinence : chaque fonctionnalité a une forte corrélation avec les changements de prix futurs (notre étiquette cible).
- Faible redondance : les caractéristiques ne doivent pas contenir trop d'informations dupliquées. Par exemple, « momentum de 5 minutes » et « momentum de 6 minutes » sont très similaires. Inclure les deux n'améliorera pas beaucoup le modèle et pourrait même introduire du bruit.
- Stabilité : La validité d'une fonctionnalité ne peut pas évoluer trop rapidement au fil du temps. Une fonctionnalité qui n'est valide qu'un jour est dangereuse.
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
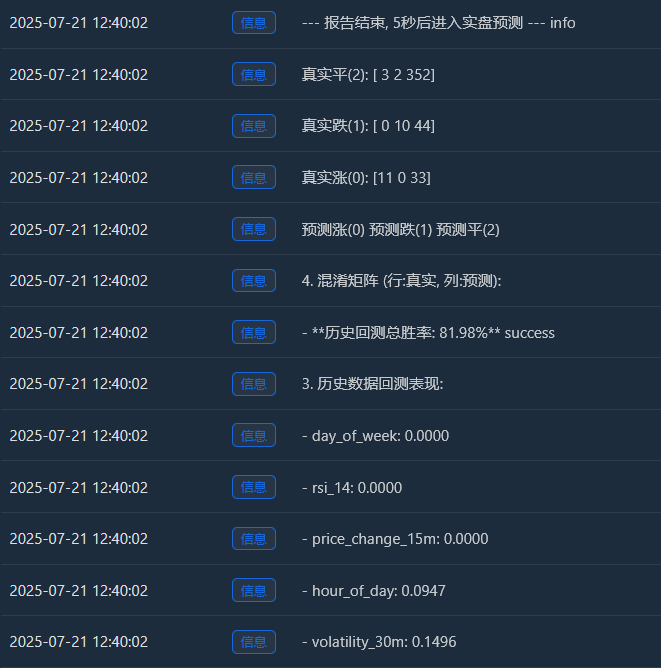
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
Le processus est le suivant :
Collecte de données
Importance des fonctionnalités

Informations mutuelles entre les fonctionnalités et les étiquettes et informations de backtest
Au départ, je pensais qu'un taux de réussite de 65 % serait suffisant, mais je ne m'attendais pas à ce qu'il atteigne 81,98 %. Ma première réaction devrait être : « C'est formidable, mais c'est trop beau pour être vrai. Il doit y avoir quelque chose à explorer ici. »
1. Interprétation approfondie du rapport d'analyse, en interprétant le contenu du rapport un par un :
- Importance des fonctionnalités et informations mutuelles :
Volatilité_30m et variation_prix_15m sont les caractéristiques les plus importantes. Ceci est logique, indiquant que la tendance récente du marché et la volatilité sont les meilleurs indicateurs de l'avenir.
L'heure du jour contribue également un peu, indiquant que le modèle capture les modèles de trading à différents moments de la journée.
Les contributions de rsi_14 et day_of_week sont quasiment nulles, ce qui suggère que ces deux caractéristiques pourraient être des « coéquipiers de cochon » dans le jeu de données et la combinaison de caractéristiques actuels. Nous pourrions envisager de les supprimer ultérieurement afin de simplifier le modèle et d'éviter le bruit. - Matrice de confusion (c'est beaucoup d'informations !)
Augmentation réelle (0) :[[11 0 33] -> Sur 44 (11+0+33) rallyes réels, le modèle en a correctement prédit 11, mais les a prédits à tort comme étant des « consolidations » 33 fois.
Chute réelle (1) :[0 10 44] -> Sur 54 (0+10+44) baisses réelles, le modèle en a correctement prédit 10, mais l'a prédit à tort comme une « tendance latérale » 44 fois.
Ping réel (2) :[3 2 352] -> Sur 357 (3+2+352) consolidations réelles, le modèle en a correctement prédit 352 ! - Taux de réussite total des backtests historiques : 81,98 %
La principale raison de ce taux de réussite élevé réside dans la très grande précision du modèle dans la prédiction de la « consolidation » ! Parmi un total d'environ 455 échantillons, plus de 350 correspondaient à des marchés de consolidation, et le modèle les a identifiés presque parfaitement.
C'est une capacité très précieuse en soi ! Un modèle capable de vous indiquer avec précision qu'il est préférable de ne pas bouger maintenant peut vous aider à éviter de nombreux frais et transactions invalides.
2Pourquoi le taux de gain réel pourrait-il être inférieur à 81,98 % ?
- La définition de « consolidation » est trop vague : notre SPREAD_THRESHOLD est de 0,5 %. Des fluctuations de prix ne dépassant pas 0,5 % sur une période de 15 minutes sont fréquentes. Par conséquent, les échantillons de « consolidation » représentent la grande majorité (environ 80 %) de notre ensemble de données. Le modèle a intelligemment appris : « En cas de doute, je devine « consolidation » avec une grande précision. » C’est statistiquement correct, mais en trading, nous nous intéressons davantage à la prédiction des mouvements de prix.
- Capacité à prédire la hausse et la baisse :
Taux de réussite des prédictions de tendance haussière : Le modèle a prédit 11 + 0 + 3 = 14 tendances haussières, dont seulement 11 étaient correctes. Le taux de réussite est de 11 / 14 = 78,5 %. Excellent !
Taux de réussite des prédictions de déclin : Le modèle a prédit 0 + 10 + 2 = 12 déclins, et s'est avéré correct pour 10 d'entre eux. Le taux de réussite est de 10 / 12 = 83,3 %. Encore une fois, c'est très impressionnant ! - Surapprentissage dans l'échantillon : ce test est effectué sur des données connues du modèle (c'est-à-dire celles utilisées pour l'entraînement et les tests). C'est comme demander à un étudiant de passer un test qu'il vient de terminer ; le score sera généralement élevé. Les performances du modèle sur des données nouvelles et inédites (trading en direct) seront presque toujours inférieures à ce score.
Nous disposons désormais d'un « modèle alpha » préliminaire, mais potentiellement ambitieux. Bien que nous ne puissions pas interpréter directement le chiffre de 81,98 % comme une prédiction réaliste pour l'avenir, il s'agit d'un signal positif fort, démontrant que des tendances prévisibles existent dans les données et que notre cadre les a bien capturées !
Nous avons maintenant l'impression d'avoir trouvé le premier morceau de minerai d'or de haute qualité au pied d'une montagne. Notre prochaine étape ne consiste pas à le vendre immédiatement, mais à utiliser des outils et des techniques plus spécialisés (optimisation des caractéristiques et ajustement des paramètres) pour exploiter toute la montagne de manière plus efficace et stable.
Introduisons maintenant le brouillard de la guerre dans le « microcosme » — les caractéristiques du flux d’ordres et du carnet d’ordres
Étape 1 : Améliorer la collecte de données : s'abonner à des canaux plus approfondis
Pour obtenir les données du carnet d'ordres, la méthode de connexion WebSocket doit être modifiée pour passer de l'abonnement uniquement à aggTrade (transactions) à l'abonnement à la fois à aggTrade et à depth (profondeur).
Cela nous oblige à utiliser une URL d’abonnement multi-flux plus générale.
Étape 2 : Améliorer l'ingénierie des fonctionnalités : créer une matrice de fonctionnalités trinitaires pour « mer, terre et air »
Nous ajouterons les nouvelles fonctionnalités suivantes à la fonction calculate_features_and_labels :
- Caractéristiques du flux d'ordres (Alpha - Short) :
alpha_15m : Facteur de déséquilibre du flux d'ordres sur 15 minutes. Il s'agit de la mesure principale du flux d'ordres dont nous avons parlé précédemment. - Caractéristiques du carnet de commandes (Livre - Armée) :
wobi_10s : Déséquilibre pondéré du carnet d'ordres sur les 10 dernières secondes. Il s'agit d'un indicateur à très haute fréquence qui mesure la pression acheteuse et vendeuse sur le marché.
spread_10s : écart acheteur-vendeur moyen sur les 10 dernières secondes. Reflète la liquidité à court terme. - Caractéristiques d'origine (Prix - Marine) :
Nous conserverons les fonctionnalités les plus performantes de la version précédente et les optimiserons.
Cette nouvelle matrice de fonctionnalités est comme un commandement de combat interarmées, qui saisit simultanément des renseignements en temps réel provenant de la « mer (tendances des prix) », de la « terre (positions du marché) » et de « l'air (impacts des transactions) », et ses capacités de prise de décision seront bien supérieures à celles d'avant.
Le code est le suivant :
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
Ce code nécessite beaucoup de calculs de ligne K
Ce rapport vaut une fortune, car il nous raconte la « pensée » et le « caractère » du modèle.
- Taux de réussite total des backtests historiques : 93,33 %
C'est un chiffre extrêmement impressionnant ! Même s'il est important de l'examiner objectivement (il s'agit d'un test sur échantillon), il démontre clairement l'immense pouvoir prédictif de nos nouvelles fonctionnalités de flux d'ordres et de carnet d'ordres ! Le modèle a identifié des tendances très fortes dans les données historiques. - Importance des fonctionnalités et informations mutuelles
Le roi est né : volatilité_15m (volatilité) et prix_change_5m (variation de prix) sont toujours absolument essentiels, ce qui est comme prévu.
Étoile montante : l'indicateur RSI_14 a connu une augmentation significative de son importance ! Cela indique que sur l'unité de temps plus courte de 5 minutes, l'indicateur de sentiment « surachat/survente » du RSI a gagné en pertinence.
Potentiellement, wobi_10s (déséquilibre du carnet d'ordres) et spread_10s (spread) contribuent également. C'est très encourageant et suggère que nos caractéristiques de microstructure commencent à fonctionner !
Réflexion : La contribution d'alpha_5m (flux d'ordres) est quasi nulle. Cela peut être dû à une simplification excessive de notre méthode de calcul de l'alpha, ou au fait que l'alpha à 5 minutes et les variations de prix à 5 minutes contiennent trop d'informations qui se chevauchent. Il s'agit d'un point d'optimisation important pour nous à l'avenir. - Matrice de confusion (preuve clé de succès !)
Augmentation réelle (0) :[22 0] -> Dans les 22 rallyes réels, le modèle les a prédits à 100 % correctement, sans aucune erreur !
Chute réelle (1) :[2 6] -> Sur 8 baisses réelles, le modèle en a correctement prédit 6 et en a manqué 2 (les prenant pour des augmentations).
Interprétation : Ce modèle présente une personnalité très intéressante : c'est un détecteur haussier extrêmement performant, captant les signaux haussiers de manière quasi parfaite. Il est également performant pour identifier les tendances baissières (précision de 6/8 = 75 %), mais commet parfois l'erreur de confondre une tendance baissière avec une tendance haussière.
Et ensuite, qu'est-ce qui vient ensuite ?
Présentation de la « machine d'état des signaux de trading »
Il s'agit de l'élément central et le plus ingénieux de cette mise à niveau. Nous allons introduire une variable d'état globale, telle que g_active_signal, pour gérer l'état de position actuel de la stratégie (notez qu'il s'agit uniquement d'un état de position virtuel, sans trading réel).
La logique de fonctionnement de cette machine d'état est la suivante :
- État initial : inactif
- Lorsque la stratégie est dans cet état, elle fera des prédictions pour chaque nouvelle ligne K, comme elle le fait actuellement.
- Transitions de régime : Une fois que le modèle prédit un signal clair (par exemple, « à la hausse »), la stratégie va :
- Imprime un signal d'entrée unique et accrocheur dans le journal, par exemple, 🎯 Nouveau signal de trading : Prévisions à la hausse ! Période d'observation de 15 minutes.
- Bascule l'état de la stratégie de Inactif à En Signal.
Enregistrez l’heure de déclenchement et la direction du signal actuel.
- Statut du poste : En cours de signal
- Dans cet état, la stratégie cesse complètement de prédire de nouvelles lignes K. Elle ne se soucie plus des fluctuations de chaque minute et passe en mode « laisser filer la balle ».
- La seule chose qu'il fait est de vérifier l'heure : si 15 minutes (la durée de PREDICT_HORIZON) se sont écoulées depuis le déclenchement du signal.
- Transition d'état : Après la période d'observation de 15 minutes, la politique :
- Imprimez un signal de sortie clair dans le journal, comme la fin de la période du signal 🏁. Réinitialisez la stratégie et recherchez de nouvelles opportunités.
- Bascule l'état de la stratégie de maintien à inactif.
- À ce stade, la stratégie commencera à prédire à nouveau la nouvelle ligne K et recherchera la prochaine opportunité de trading.
Avec cette machine d'état simple, nous avons parfaitement atteint les exigences : un signal, un cycle d'observation complet et aucune information d'interférence pendant la période.
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
Ensuite, j'exécute ce code
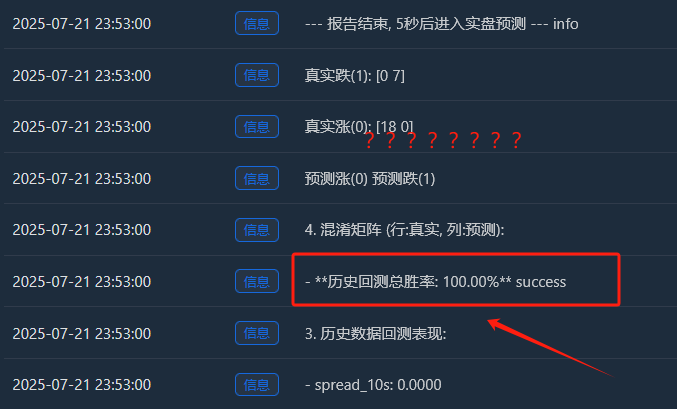
Analyse approfondie : Pourquoi existe-t-il un taux de réussite « parfait » de 100 % ?
Ce résultat « parfait » révèle plusieurs informations importantes et profondes sur l'apprentissage automatique et les marchés financiers. Il ne s'agit pas d'un bug, mais plutôt d'un phénomène courant appelé « surapprentissage », qui peut se produire dans certaines conditions.
Que signifie « surapprentissage » ?
-
Voici une analogie frappante : imaginez qu’un élève (notre modèle SVM) effectue une série d’exercices très courts et très simples (les 200 chandeliers que nous avons collectés). Cet élève est très intelligent et, au lieu d’apprendre des méthodes générales de résolution de problèmes, il mémorise simplement les réponses à ces quelques problèmes.
-
Résultat : Lorsque nous le testons avec le même ensemble de questions pratiques (c'est notre « backtest historique »), il peut certainement obtenir un score parfait de 100. Cependant, une fois que nous lui donnons un ensemble de questions complètement nouveau qu'il n'a jamais vu auparavant (de vrais marchés à terme), il est susceptible d'être incapable de répondre à aucune d'entre elles.
- Pourquoi notre modèle est-il « sur-ajusté » ?
-
Les échantillons de formation sont « trop peu nombreux » et « trop spéciaux » :
-
Bien que nous ayons collecté 200 lignes K (environ 3,3 heures), selon le journal, le nombre final d'échantillons de « montée et de descente effectives » qui répondaient à notre définition n'était que de 18 + 7 = 25.
-
Pour un modèle SVM complexe, 25 échantillons sont comme quelques vagues dans l’océan, ce qui est trop petit.
-
Plus important encore, ces 25 échantillons proviennent tous d'une situation de marché fortement corrélée, le même après-midi. Ils sont susceptibles d'avoir des « routines » très similaires.
- Les capacités du modèle sont « trop fortes » :
- SVM est un classificateur non linéaire très puissant. Ses capacités sont comparables à celles d'un cerveau doté d'une super mémoire.
- Lorsqu'un modèle puissant apprend à partir d'un ensemble de données trop simple et répétitif, il a tendance à « mémoriser » tous les détails et le bruit des données plutôt que d'apprendre les lois macroéconomiques plus universelles qui les sous-tendent.
- Preuves tirées de la matrice de confusion :
- Augmentation réelle (0) :[18 0] -> 18 échantillons ascendants, tous parfaitement mémorisés.
- Chute réelle (1) :[0 7] -> 7 échantillons en chute libre, tous parfaitement mémorisés.
- C'est parfait[ [18, 0], [La matrice [0, 7] est une preuve irréfutable du surapprentissage du modèle. Elle ne commet quasiment aucune erreur, ce qui est intrinsèquement anormal sur un marché financier où règne le hasard.
Par conséquent, nous devrions interpréter ce taux de réussite de 100 % comme suit :
Le modèle a remarquablement appris et mémorisé tous les schémas des conditions de marché spécifiques au cours des trois dernières heures. Cela démontre l'efficacité de notre ingénierie des fonctionnalités et de notre cadre de modélisation. Cependant, nous ne pouvons absolument pas nous attendre à ce qu'il maintienne un taux de réussite aussi élevé sur le marché réel à l'avenir. Cela ressemble davantage à un questionnaire surprise qu'au résultat final d'un examen d'entrée à l'université.

Le machine learning est également quelque chose que j’explore récemment, nous en parlerons dans le prochain numéro !
Nous devons procéder à une profonde transformation de la pensée de cet « élève biaisé ». Notre objectif est de briser ses préjugés et de lui permettre d'envisager les « hauts et les bas » de manière juste et objective.
