

📢 Armure multicouche
Cet article estUn ouvrage de vulgarisation scientifique sur la transformée en ondelettes pour le trading pratiqueLe code est une version pédagogique simplifiée (omettant les étapes complexes telles que la décomposition multiniveau, le débruitage par seuillage et la reconstruction par transformée inverse des ondelettes standard), ne conservant que les idées principales :**Utilisez les coefficients d'ondelettes pour effectuer un lissage multi-échelle sur les prix afin d'en extraire des informations sur les tendances.**Convient au développement de stratégies et à la validation rapide, mais pas à la recherche universitaire ni à la publication d'articles.
I. Introduction : Démystifier le « gourou Zhihu » (expert)
Ceux qui consultent régulièrement des sujets financiers et quantitatifs sur Zhihu ont certainement déjà vu ce scénario :
Certains « experts » ne cessent de répéter :
- réduction du bruit par transformée en ondelettes
- période d'extraction de la transformée de Fourier
- Le lissage de Laplace élimine les valeurs aberrantes.
Il a stupéfié tout le monde, comme s'il avait maîtrisé l'arme nucléaire du trading quantitatif.
Mais vous voulez qu'il vous montre le code ?
« Ceci… est un secret commercial, et je ne peux pas le divulguer. »
Demandez-lui d'expliquer le principe.
« Ceci… implique des mathématiques avancées, vous ne comprendriez pas même si je vous l’expliquais. »
Aujourd'hui, nous allons explorer les sujets fréquemment évoqués par ces « experts de Zhihu », présenter les applications pratiques de la transformée en ondelettes sur le marché financier et aider chacun à développer une compréhension correcte de cette technologie.
II. Qu'est-ce que la transformée en ondelettes exactement ?
Explication simple
Imaginez que vous écoutez une chanson, mais qu'il y a du bruit de fond dans l'enregistrement :
Enregistrement original = voix humaine + bruit de fond + bruit statique
La transformée en ondelettes est comme uneFiltres intelligents:
- Préservez la voix
- Filtrer le bruit
- Il peut également vous indiquer quelle partie est le refrain et quelle partie est le couplet.
Passez au marché financier :
Prix initial = Tendance réelle + Fluctuations à court terme + Bruit aléatoire
La transformée en ondelettes peut vous aider :
- Extraire la véritable tendance(Orientation à long terme)
- Filtrage des fluctuations à court terme(Fluctuations intraday)
- Identifier les points d'inflexion clés(Inversion de tendance)
Concept fondamental : Décomposition en fonctions de base
L'essence de la transformée en ondelettes estDécomposer le signal original à l'aide d'un ensemble spécifique de « fonctions de base » (ondelettes).。
Imaginez que vous vouliez décrire l'apparence d'une personne :
- Méthode traditionnelle : description pixel par pixel, ce qui est très fastidieux.
- Méthode des ondelettes : utilisation de facteurs tels que « la taille des yeux, la hauteur du nez et le contour du visage »fonctionnalitéCombiner les descriptions
En termes de prix financiers :
Série de prix d'origine = Fonction de base 1 × Poids 1 + Fonction de base 2 × Poids 2 + ... + Bruit
**Les fonctions de base sont les « modèles » correspondant aux coefficients d'ondelettes.**Les différents types d'ondelettes (Haar, Daubechies, chapeau mexicain, etc.) utilisent des modèles différents, tout comme on utilise différents « extracteurs de caractéristiques » pour décomposer les prix.
Filtre : Un tamis dans le domaine fréquentiel
La transformée en ondelettes est essentiellement une...banc de filtres multi-échelles:
Filtre haute fréquence → Capture les fluctuations rapides (bruit quotidien, fluctuations au niveau des ticks)
Filtre de fréquence intermédiaire → Capture les tendances à moyen terme (bandes allant de quelques heures à quelques jours).
Filtres basse fréquence → Capturent les tendances à long terme (tendances hebdomadaires et mensuelles).
Pourquoi l'appelle-t-on « ondelette » ?
- La transformée de Fourier traditionnelle utiliseOnde sinusoïdale infiniment longueComme une règle infiniment longue
- La transformée en ondelettes est utiliséeOnde « petite » de longueur finieComme un ensemble de règles de différentes longueurs
Le problème de l'utilisation des ondes sinusoïdales pour analyser les prix financiers : les ondes sinusoïdales supposent que le signal se répète périodiquement, or les marchés financiers ne le font pas ! Le BTC pourrait augmenter de 10 % aujourd'hui et chuter de 8 % demain, sans aucune cyclicité.
Avantages des ondelettes :Analyse de localisationElle peut vous indiquer « la tendance des prix était principalement à la hausse entre 15 h et 17 h le 20 décembre 2025 », plutôt qu'une conclusion générale comme « le marché dans son ensemble a fluctué ».
Reconstruction : De la décomposition à la reconstruction
La transformée en ondelettes estRéversibleC'est très important !
Prix initial ---> Décomposition en ondelettes ---> Composante de tendance + Composante de volatilité + Composante de bruit
Composante de tendance + composante de volatilité + composante de bruit ---> reconstruction par ondelettes ---> prix d'origine
Processus de refactorisationIl s'agit de décomposer les composants individuels.Combiner sélectivement les retours:
- Composante de tendance =[99800, 99850, 99900, 99950, ...] # Ce que nous voulons
- Composante de fluctuation =[+200, -150, +180, -120, ...] # Peut être utile
- Composante de bruit =[±10, ±15, ±8, ±12, ...] # Jeter !
N'utilisez les composantes de tendance que pendant la reconstruction
Après décomposition, on a obtenu le résultat suivant
- Prix reconstitué = Composante de tendance + Composante de volatilité partielle
Dans les transactions réelles, nous avons généralementReconstruisez uniquement la partie basse fréquence(Tendance) Les composantes haute fréquence (bruit) sont directement éliminées. C'est le principe de la « réduction du bruit » par ondelettes.
Principes des mathématiques (version simplifiée)
Laissons de côté les formules intégrales complexes et expliquons-le en termes simples :
Transformée en ondelettes = moyenne pondérée des séries de prix à l'aide d'un ensemble de « coefficients d'ondelettes »
Formule de base :
Lissage des prix[i] = Σ(prix initial)[i-j] × coefficients d'ondelettes[j]) / Σ(coefficients d'ondelettes)[j])
Perspective du filtre:
Le prix initial est filtré par un filtre à ondelettes → les composantes de différentes fréquences sont « sélectionnées ».
La clé estSélection des coefficients d'ondelettes:
- Différentes ondelettes = différentes caractéristiques de filtre = différentes réponses en fréquence
- Différents niveaux = différentes échelles de temps = différents cycles de tendance
Par exemple:
En supposant que vous utilisiez les ondelettes de Daubechies 4, les coefficients sont[0.483, 0.837, 0.224, -0.129]:
Cet ensemble de coefficients définit un filtre :
- Coefficients positifs (0,483, 0,837, 0,224) → Conserver le prix pour ces positions.
- Coefficient négatif (-0,129) → Atténue les mouvements de prix antérieurs
- Pondération par coefficient → détermine la contribution de chaque prix.
La transformation en ondelettes est terminée lorsque vous « faites glisser » ce filtre sur l'ensemble de la série de prix. Chaque glissement implique des calculs.Moyenne pondérée des prix dans la fenêtre actuelleLes poids sont les coefficients d'ondelettes.
Pourquoi peut-il « décomposer » les signaux ?
Parce que cela peut être prouvé mathématiquement :**Tout signal peut être représenté comme une combinaison linéaire de fonctions de base d'ondelettes.**De même que toute couleur peut être créée en mélangeant les trois couleurs primaires du RVB, toute série de prix peut être obtenue en combinant des fonctions de base d'ondelettes. Différents types d'ondelettes offrent différentes « bibliothèques de fonctions de base », adaptées à différents types d'analyse de signaux.
III. Cet essai : application pratique de 7 transformées en ondelettes
Approche applicative : Simplification de la théorie à la pratique
Dans les manuels de traitement du signal, la transformée en ondelettes implique généralement des opérations complexes...Décomposition multiniveau, reconstruction et débruitage par seuillageMesures:
Flux de travail complet d'analyse par ondelettes :
- Décomposition multi-échelle → donne des coefficients d'approximation et des coefficients de détail.
- Seuil → Seuil doux/dur appliqué aux coefficients de détail pour réduire le bruit
- Reconstruction par transformation inverse → restauration des coefficients traités dans le signal
- Extension de la limite → Gestion des effets de limite du signal
- Normalisation énergétique → assure la conservation de l'énergie avant et après la transformation
MaisApplications pratiques des transactions financièresEn Chine, nous n'avons pas besoin que ce soit aussi compliqué. Parce que :
1. Le trading ne nécessite que la direction de la tendance ; une reconstruction parfaite n'est pas nécessaire.
La recherche académique peut exiger une marge d'erreur de reconstruction inférieure à 0,01 %, mais en trading, il suffit de déterminer si le prix va monter ou baisser. Même avec une erreur de reconstruction de 5 %, la stratégie peut rester rentable si la tendance est correctement anticipée.
2. Les exigences en temps réel simplifient les calculs.
Une décomposition complète en ondelettes nécessite le calcul récursif de plusieurs couches de coefficients, ce qui peut engendrer une latence importante pour le trading haute fréquence. La convolution directe, en revanche, peut être effectuée en quelques millisecondes, répondant ainsi aux exigences du trading en temps réel.
3. Les caractéristiques particulières des signaux financiers
Les prix financiers ne constituent pas des signaux stables et ne présentent pas de cyclicité stricte. Une décomposition fréquentielle complexe n'est pas pertinente ici ; une simple extraction de tendance est plus pratique.
Cette stratégie de simplification
Par conséquent, cet articleExtraire l'essence de la transformation en ondelettesSe concentrer sur les aspects les plus pratiques des marchés financiers :
Simplification fondamentale 1 : Utiliser uniquement des coefficients approximatifs (tendances basse fréquence)
Décomposition en ondelettes traditionnelle → coefficients d'approximation + coefficients de détail (multicouche)
Cette application : ne conserve que les coefficients approximatifs → obtention directe de la tendance lissée.
Simplification de base 2 : Convolution directe, sans débruitage par seuillage
Décomposition en ondelettes traditionnelle → seuillage des coefficients de détail → reconstruction
Cette application : Convolution directe → pour obtenir des prix lissés
Simplification du noyau 3 : Ignorer le traitement des frontières
Les ondelettes traditionnelles nécessitent un traitement tel que l'extension symétrique et l'extension périodique des limites du signal.
Cette application se concentre uniquement sur la section centrale ; les erreurs aux limites sont acceptables.
Méthode d'implémentation : Convolution du filtre
python
def convolve(src, coeffs, step):
"""
核心算法:用小波系数对价格序列做加权平均
src: 价格序列 [100000, 101000, 99000, ...]
coeffs: 小波系数 [0.483, 0.837, 0.224, -0.129]
step: 采样步长(用于多层级)
"""
sum_val = 0.0 # 加权和
sum_w = 0.0 # 权重和
for i, weight in enumerate(coeffs):
idx = i * step
if idx < len(src):
sum_val += src[idx] * weight
sum_w += weight
return sum_val / sum_w # 归一化
Cette fonction est...Le cœur des filtres à ondelettes:
- Pour chaque chandelier, il regarde N chandeliers en arrière (N = nombre de coefficients d'ondelettes).
- Calculez la moyenne pondérée en utilisant les coefficients d'ondelettes comme pondérations.
- En ajustant
stepLes paramètres permettent un lissage multiniveau (niveau 1/2/3...).
Pourquoi cette simplification est-elle raisonnable ?
Car l'exigence essentielle des transactions est :Détecter les tendances dans le bruitLes coefficients d'approximation de la transformée en ondelettes constituent eux-mêmes un « filtre passe-bas » pour le signal, préservant les composantes de tendance basse fréquence, ce qui est exactement ce dont nous avons besoin.
Bien que l'analyse complète par ondelettes soit plus précise, dans le domaine du trading financier :
- **Les profits proviennent de la direction de la tendance.**Cela ne provient pas de la précision de la reconstitution.
- Les méthodes plus simples sont plus robustesLes modèles complexes sont sujets au surapprentissage.
- **La vitesse de calcul est plus importante.**Dans le monde réel des transactions boursières, chaque milliseconde compte.
Acquisition de données : La commodité de la plateforme FMZ
utiliser**Le moteur de backtesting local de la plateforme Inventor Quantization (FMZ)**C'est très pratique d'obtenir des données !
python
'''backtest
start: 2025-12-17 00:00:00
end: 2025-12-23 08:00:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","fee":[0,0]}]
'''
from fmz import *
task = VCtx(__doc__)
def main():
exchange.SetCurrency("BTC_USDT")
exchange.SetContractType("swap")
records = exchange.GetRecords(PERIOD_H1, 500)
return records
records = main()
Aucune intégration API complexe ni aucun nettoyage de données ne sont nécessaires ; les données de chandeliers standardisées sont directement accessibles. Cela nous permet de vérifier rapidement les effets réels des sept types d’ondelettes, sans nous enliser dans un traitement de données fastidieux.
Cible de test
En comparant les performances de sept types d'ondelettes courants (Haar, Daubechies 4, Symlet 4, Biorthogonal 3.3, Mexican Hat, Morlet et Discrete Meyer) sur les prix des cryptomonnaies, la démonstration visuelle suivante est fournie :
- Différences d'intensité de lissage entre les différentes ondelettes
- Variations d'effet à différents niveaux d'une même ondelette
- Quelles ondelettes sont adaptées au trading à court terme, et lesquelles sont adaptées au suivi de tendance ?
**L'accent n'est pas mis sur la rigueur de la démonstration mathématique, mais sur la comparaison visuelle des résultats pratiques.**Cela aide les traders à développer une compréhension intuitive et à choisir le type d'ondelette qui convient à leur stratégie.
IV. Explication détaillée des 7 types d'ondelettes
1. Ondelette Haar - la moyenne la plus simple
L'ondelette de Haar est le type d'ondelette le plus élémentaire, avec seulement deux coefficients :[0.5, 0.5]Il s'agit essentiellement d'une simple moyenne de deux prix adjacents.
Code principal :
python
coeffs = [0.5, 0.5]
# 对价格序列 [100000, 101000, 99000, 102000, 98000] 处理
def smooth(prices, i):
return (prices[i] * 0.5 + prices[i-1] * 0.5) / 1.0
# 结果:[100000, 100500, 100000, 100500, 100000]
Comme vous pouvez le constater, le prix, initialement très fluctuant (de 99 000 à 102 000), se stabilise après le traitement de Haar. C’est l’effet du « débruitage » par ondelettes : les fluctuations brutales à court terme sont lissées, ce qui permet d’observer une tendance de prix plus régulière.
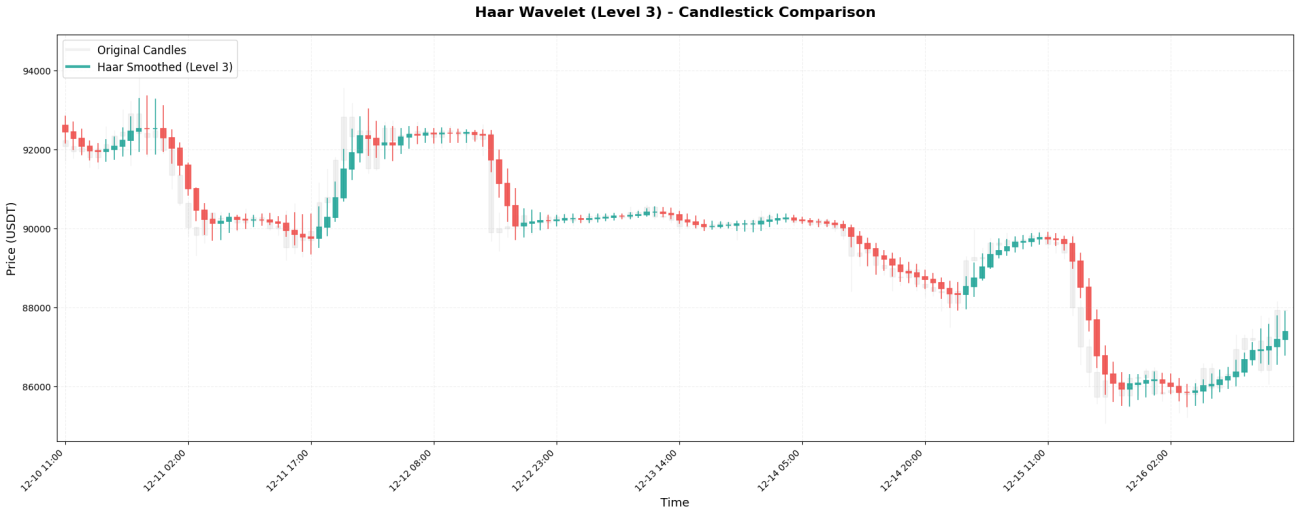
2. Daubechies 4 - Couramment utilisé dans les projets d'ingénierie
L'ondelette de Daubechies 4 (DB4) est l'une des plus utilisées en ingénierie. Ses coefficients sont :[0.483, 0.837, 0.224, -0.129]Notez que le dernier coefficient est...nombre négatifC'est ce qui le rend unique.
Code principal :
python
coeffs = [0.483, 0.837, 0.224, -0.129]
# 处理第i个价格点
def smooth(prices, i):
weighted_sum = (prices[i] * 0.483 + # 当前价格
prices[i-1] * 0.837 + # 前1根,权重最大!
prices[i-2] * 0.224 + # 前2根
prices[i-3] * (-0.129)) # 前3根,负权重
weight_sum = 0.483 + 0.837 + 0.224 + (-0.129) # = 1.415
return weighted_sum / weight_sum
# 示例:smooth([100000, 101000, 99000, 102000], 3) ≈ 100251
**Caractéristiques principales :**Le poids de la bougie précédente (0,837) est supérieur à celui du prix actuel (0,483) ! Cela signifie que db4 accorde plus d’importance au « prix qui vient d’être enregistré », et le coefficient de pondération négatif aura un effet « compensateur » sur le prix précédent, renforçant ainsi la régularité.
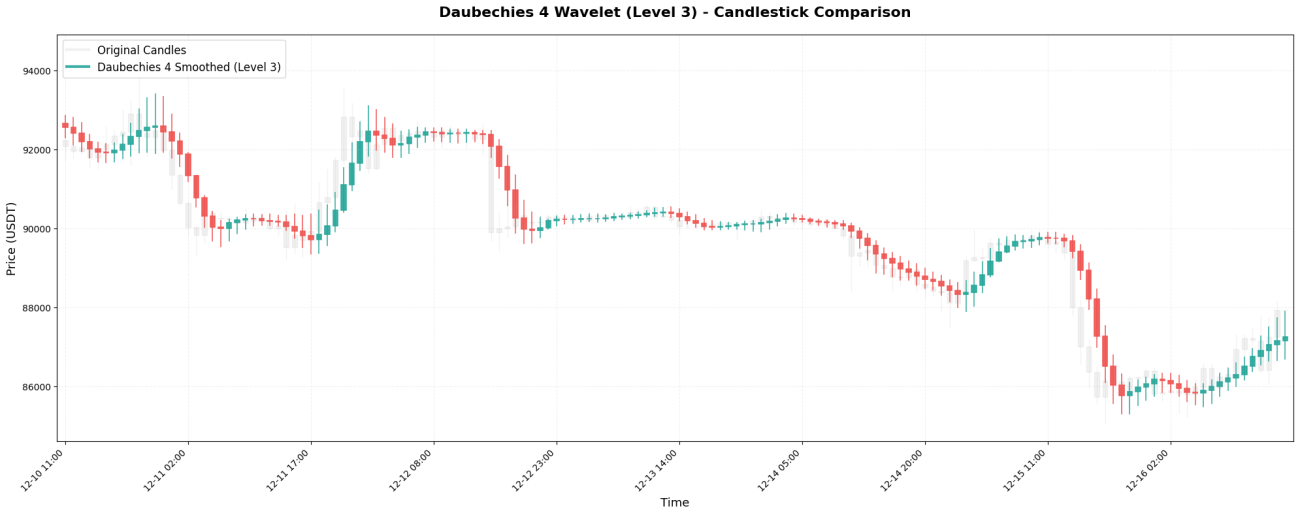
3. Symlet 4 - Une version symétrique améliorée
Symlet 4 est une version améliorée de Daubechies, visant une meilleure symétrie. Coefficients :[-0.076, -0.030, 0.498, 0.804, 0.298, -0.099, -0.013, 0.032]。
Code principal :
python
coeffs = [-0.076, -0.030, 0.498, 0.804, 0.298, -0.099, -0.013, 0.032]
# 向前看8根K线
def smooth(prices, i):
weighted_sum = sum(prices[i-j] * coeffs[j] for j in range(8))
weight_sum = sum(coeffs)
return weighted_sum / weight_sum
# 平滑效果比Haar和db4都强,但反应速度更慢
**Caractéristiques principales :**Une fenêtre d'observation de 8 chandeliers permet une meilleure « mémoire » des prix. Un véritable retournement de tendance peut ne pas être visible sur une courbe lisse avant la fin de cette période de 8 chandeliers.
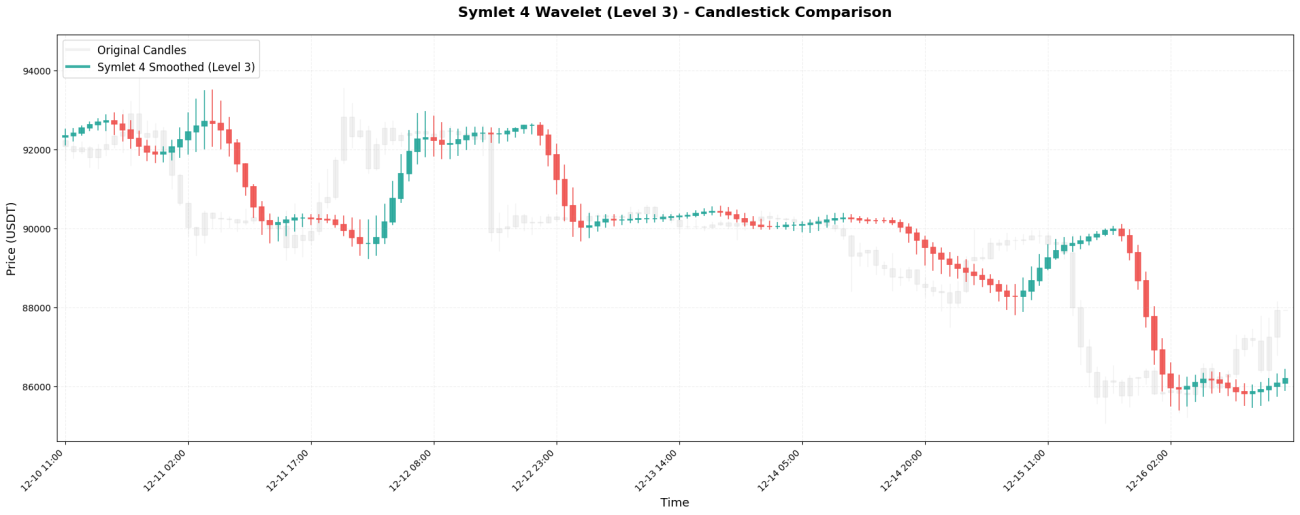
4. Biorthogonal 3.3 - Symétrie parfaite
Biorthogonal 3.3 (abrégé en bior3.3) est une ondelette parfaitement symétrique avec des coefficients :[-0.066, 0.283, 0.637, 0.283, -0.066]。
Code principal :
python
coeffs = [-0.066, 0.283, 0.637, 0.283, -0.066]
# ↑ 中心↑ ↑
# 完全对称的两端
# 处理中间价格点
def smooth(prices, i):
# 实际应用:只向前看,不使用未来数据
weighted_sum = (prices[i-4] * (-0.066) + # 前4根
prices[i-3] * 0.283 + # 前3根
prices[i-2] * 0.637 + # 前2根,权重最大
prices[i-1] * 0.283 + # 前1根
prices[i] * (-0.066)) # 当前
weight_sum = sum(coeffs) # = 1.071
return weighted_sum / weight_sum
**Caractéristiques principales :**La symétrie garantit l'absence de « distorsion de phase » : la courbe lissée ne se décalera pas inexplicablement vers la gauche ou la droite.
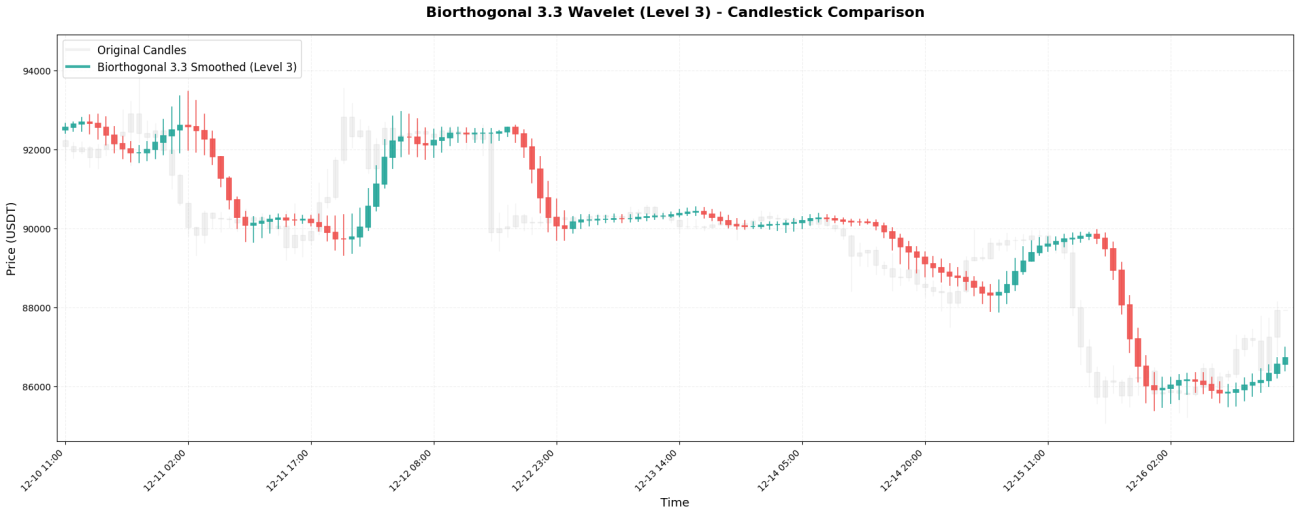
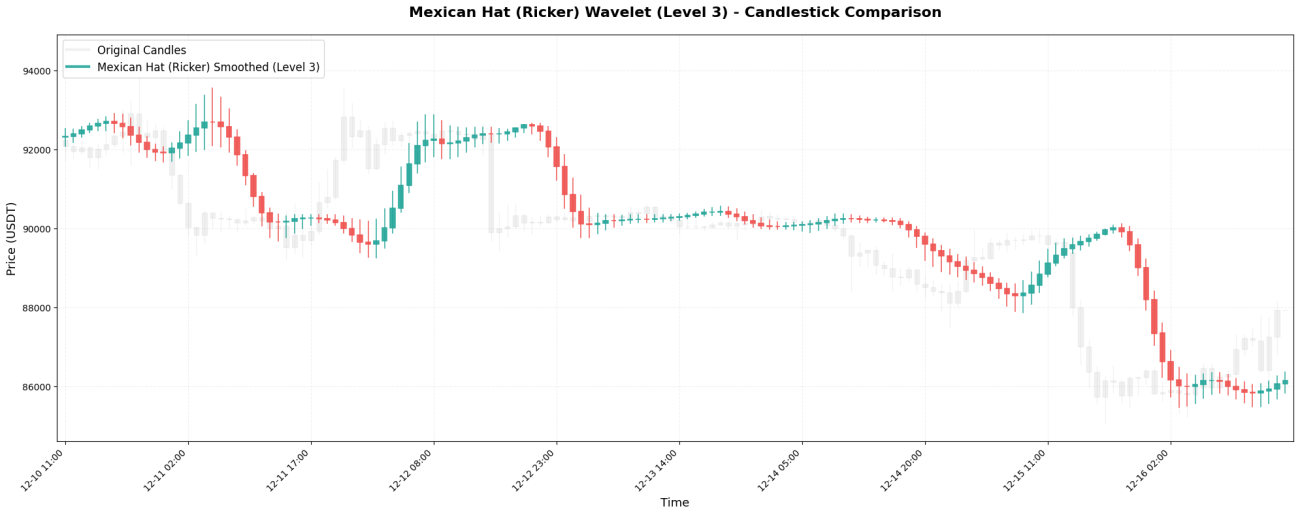
5. Chapeau mexicain - Chasseur de points tournants
Coefficients de l'ondelette chapeau mexicain (également appelée ondelette de Ricker) :[-0.1, 0.0, 0.4, 0.8, 0.4, 0.0, -0.1]Il a la forme d'un sombrero mexicain.
Code principal :
python
coeffs = [-0.1, 0.0, 0.4, 0.8, 0.4, 0.0, -0.1]
# 负值 零 正值 最大 正值 零 负值
# ↓ ↓
# "惩罚"两端,增强拐点检测能力
def smooth(prices, i):
weighted_sum = (prices[i-6] * (-0.1) + # 左3,负权重
prices[i-5] * 0.0 + # 左2
prices[i-4] * 0.4 + # 左1
prices[i-3] * 0.8 + # 中心,权重最大
prices[i-2] * 0.4 + # 右1
prices[i-1] * 0.0 + # 右2
prices[i] * (-0.1)) # 右3,负权重
weight_sum = sum(coeffs)
return weighted_sum / weight_sum
**Caractéristiques principales :**Sa structure « large au centre, négative aux deux extrémités » la rend particulièrement performante en détection.point d'inflexionLe moment critique où les prix s'inversent, passant d'une tendance haussière à une tendance baissière (ou inversement). Le coefficient de pondération négatif « pénalise » les prix éloignés, captant rapidement les changements de tendance.
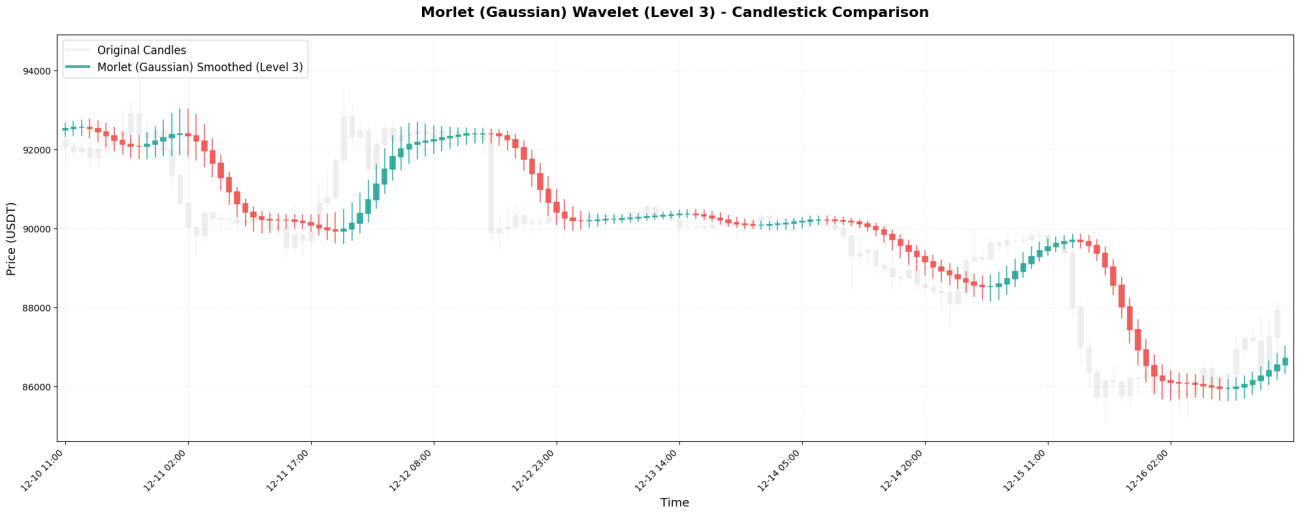
6. Morlet - Le roi du lissage gaussien
L'ondelette de Morlet est basée sur une distribution gaussienne (normale), avec des coefficients :[0.0625, 0.25, 0.375, 0.25, 0.0625]。
Code principal :
python
coeffs = [0.0625, 0.25, 0.375, 0.25, 0.0625]
# ↓ ↓ ↓中心 ↓ ↓
# 远端 近端 最高 近端 远端
# 完美的高斯钟形曲线
def smooth(prices, i):
weighted_sum = (prices[i-4] * 0.0625 + # 左2,6.25%
prices[i-3] * 0.25 + # 左1,25%
prices[i-2] * 0.375 + # 中心,37.5%
prices[i-1] * 0.25 + # 右1,25%
prices[i] * 0.0625) # 右2,6.25%
# 权重和正好 = 1.0,无需除法
return weighted_sum
**Caractéristiques principales :**La plus « douce » de toutes les ondelettes, elle n'utilise pas de pondération négative et intègre progressivement tous les prix dans le calcul. La courbe résultante est extrêmement lisse, mais sa réactivité est lente : les variations de prix soudaines peuvent ne se refléter que plusieurs chandeliers plus tard.
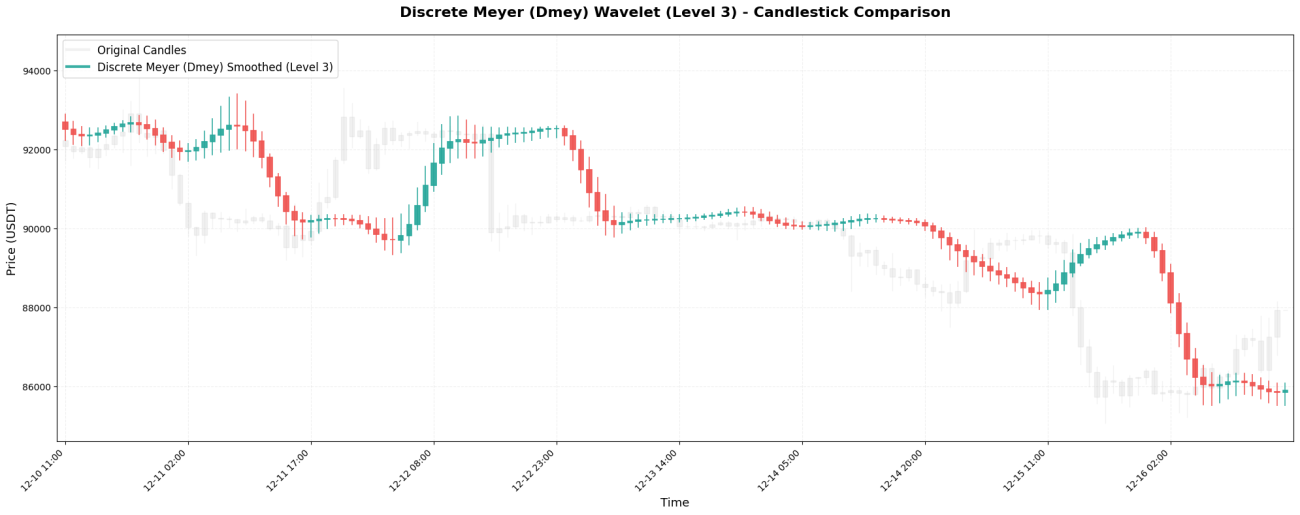
7. Discret Meyer - Lissage Ultime
L'ondelette de Meyer discrète est l'ondelette la plus complexe, avec des coefficients :[-0.015, -0.025, 0.0, 0.28, 0.52, 0.28, 0.0, -0.025, -0.015]。
Code principal :
python
coeffs = [-0.015, -0.025, 0.0, 0.28, 0.52, 0.28, 0.0, -0.025, -0.015]
# ↑ ↑ ↑ ↑中心↑ ↑ ↑ ↑
# 完全对称,中心权重超过50%
def smooth(prices, i):
# 向前看9根K线
weighted_sum = sum(prices[i-j] * coeffs[j] for j in range(9))
weight_sum = sum(coeffs) # = 1.0
return weighted_sum
# 注意:第4根之前的K线权重是0.52,超过50%!
# 实际上在告诉你"4根K线之前的中期趋势"
**Caractéristiques principales :**Elle présente le plus grand nombre de coefficients (9), les données historiques les plus longues et l'effet de lissage le plus marqué. Elle convient à l'extraction des tendances hebdomadaires, mais souffre d'un délai important : même si le prix a chuté de 10 %, sa courbe peut encore indiquer une hausse continue.
5. Pourquoi observe-t-on des différences dans l'effet de lissage ?
Après avoir passé en revue les sept types d'ondelettes, vous devriez avoir remarqué une régularité :
Plus de coefficients = vision plus détaillée = lissage plus important = latence plus élevée
Haar (2 coefficients) → Considérer seulement 1 barre → Presque non lisse
Daubechies 4 (4 pièces) → Voir 3 ci-dessus → Légèrement lisse
Chapeau mexicain (7) → Voir 6 ci-dessus → Lissage modéré
Meyer discret (9) → Avant l'affichage de 8 barres → Lissage important
L'effet des pondérations négatives est d'accroître la sensibilité et de faciliter la détection des changements.
Haar/Morlet (pas de poids négatifs) → Doux et lisse, insensible
Chapeau mexicain (négatif aux deux extrémités) → Sensible aux points d'inflexion
Daubechies 4 (négatif) → Sensible aux changements de tendance
Le rôle de la symétrie = absence de distorsion = maintien de la forme originale
Asymétrie (Daubechies) → Peut se décaler vers la gauche ou la droite
Symétrie (biorthogonale/Meyer) → Maintien de la position centrale
VI. L’impact des niveaux de lissage
La transformée en ondelettes peut être appliquée de manière récursive, à la manière de poupées russes. La première application est appelée Niveau 1, la réapplication au résultat du Niveau 1 est appelée Niveau 2, et ainsi de suite.
Les échelles de temps observées à différents niveaux :
En supposant que nous utilisions des graphiques en chandeliers d'une heure pour le trading de BTC :
Niveau 1 → Observer les fluctuations à court terme sur 2 à 4 heures
Niveau 2 → Observer la tendance sur 4 à 8 heures
Niveau 3 → Observer la tendance à moyen terme sur 1 à 2 jours (stratégie couramment utilisée)
Niveau 4 → Observez la fourchette de prix de 2 à 4 jours
Niveau 5 → Observer les grandes tendances sur 4 à 8 jours
Comparaison des résultats réels :
Prix initial du BTC (graphique horaire) :99500, 99800, 99200, 100200, 99800, 100500, 100100, ...
Traitement de niveau 1 : 99600, 99650, 99500, 99900, 99950, 100200, 100250, ...
(Légèrement lissé, mais les fluctuations restent visibles)
Traitement de niveau 3 : 99620, 99650, 99700, 99800, 99950, 100100, 100200, ...
(Lissé, indiquant une tendance à moyen terme)
Traitement de niveau 5 : 99630, 99640, 99660, 99700, 99760, 99840, 99930, ...
(Extrêmement lisse, ne montrant que la direction générale)
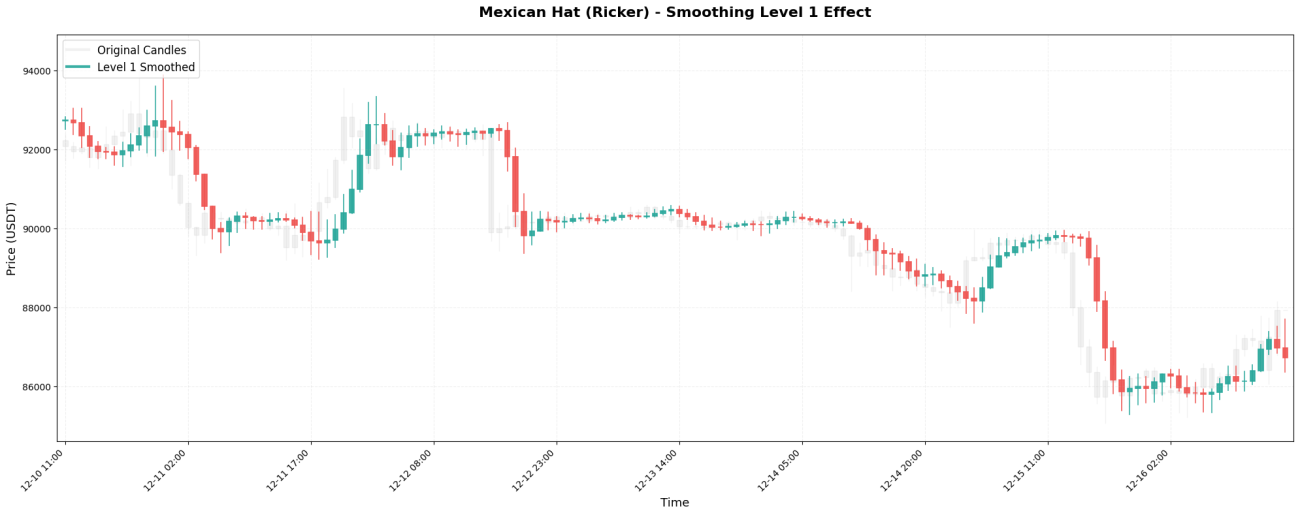
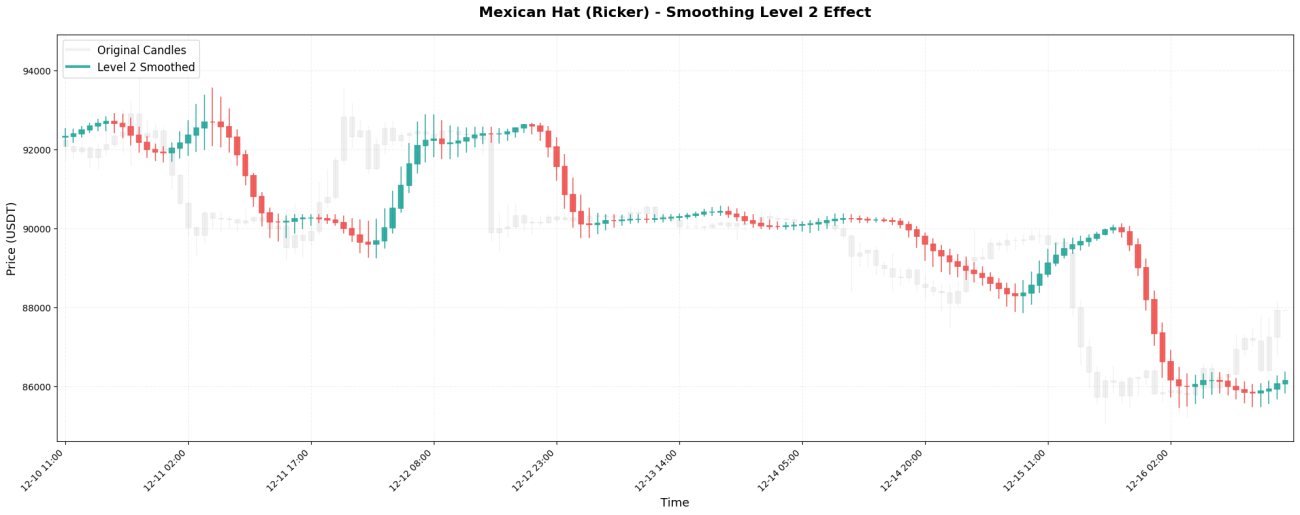
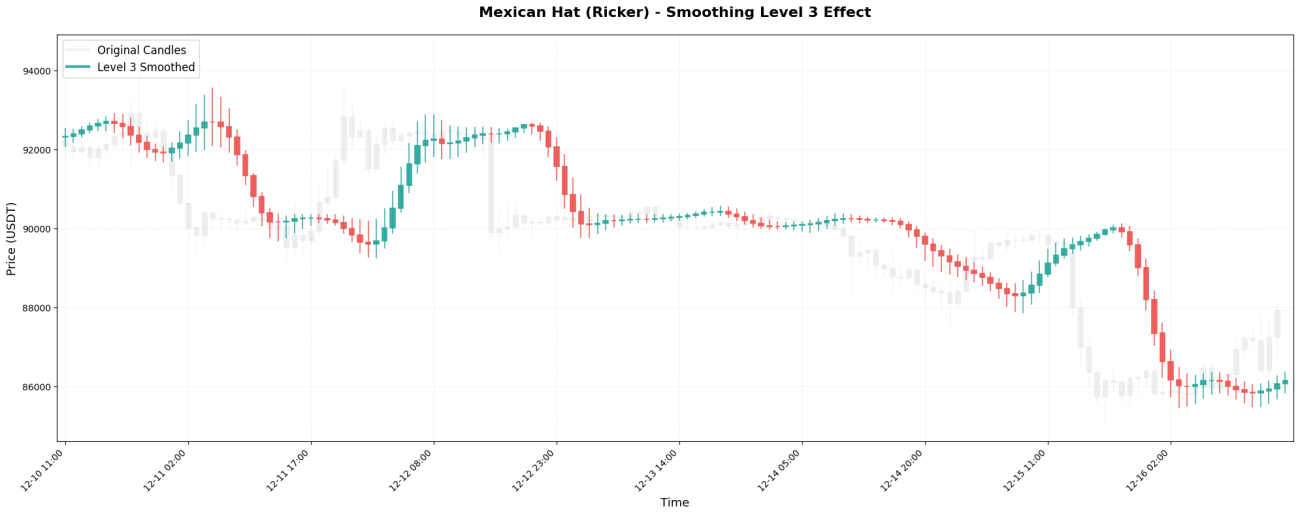
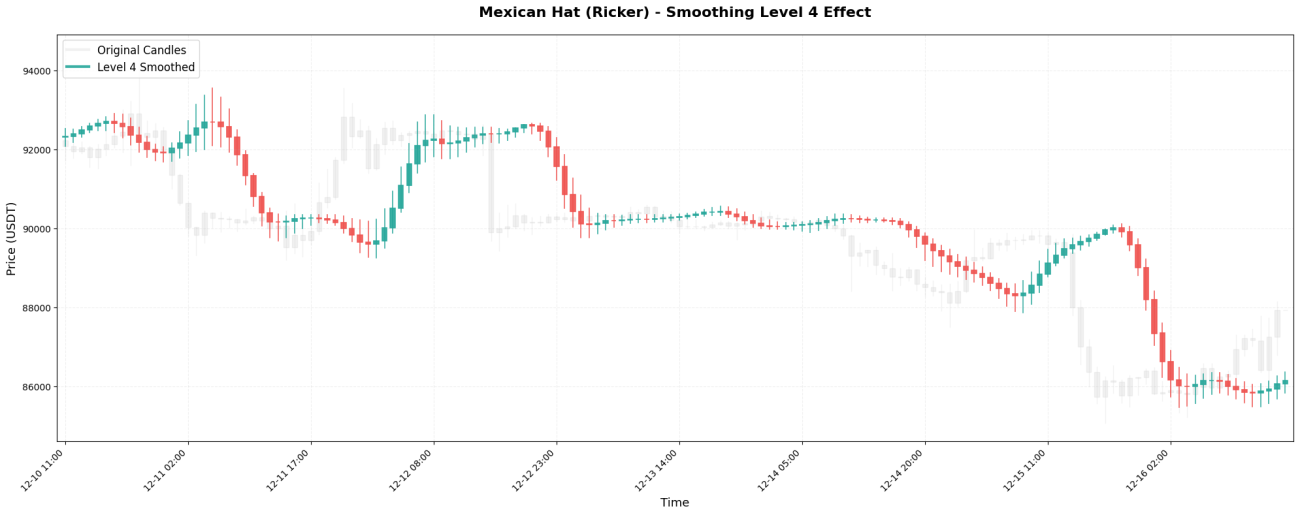
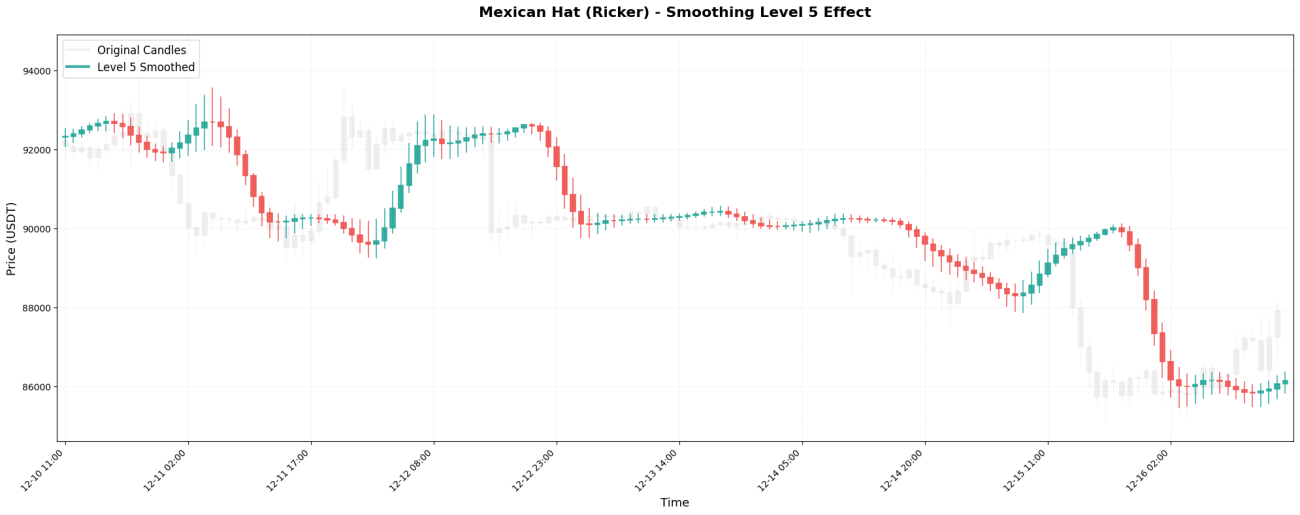
Le principe de sélection est simple : utilisez le niveau correspondant à votre période de détention.
scalpage en 15 minutes → Niveau 1-2
Trading intraday → Niveau 2-3
Quelques jours de swing → Niveau 3-4
Analyse des tendances à long terme → Niveau 4-5
VII. Idées d'application pratique
L'application de la transformée en ondelettes au trading est très directe : on utilise la courbe de prix lissée qu'elle génère pour déterminer la direction de la tendance et on intervient lorsque celle-ci s'inverse. Concrètement, si le prix de clôture lissé est supérieur au précédent, cela indique une tendance haussière ; il faut donc acheter. À l'inverse, si le prix de clôture lissé est inférieur au précédent, cela indique une tendance baissière ; il faut alors clôturer la position ou vendre à découvert. Cette logique est efficace car les ondelettes éliminent les fluctuations aléatoires à court terme, ne laissant apparaître qu'une forte probabilité de véritable changement de tendance (« hausse » ou « baisse »), et non un faux signal dû au bruit.
python
# 执行小波变换
transformed = transformer.transform_ohlc(df)
# 获取最近两根K线的平滑收盘价
w_close_current = transformed['w_close'].values[-1] # 当前平滑收盘价
w_close_prev = transformed['w_close'].values[-2] # 前一根平滑收盘价
# 判断趋势方向
signal = 0
if w_close_current > w_close_prev:
signal = 1 # 平滑价格向上 → 做多
elif w_close_current < w_close_prev:
signal = -1 # 平滑价格向下 → 做空
# 获取账户信息
account = exchange.GetAccount()
ticker = exchange.GetTicker()
if not account or not ticker:
Log("[Warning] Failed to get account/ticker info")
Sleep(5000)
continue
current_price = ticker['Last']
Log(f"[Price] 原始: {df['Close'].values[-1]:.2f}, "
f"平滑当前: {w_close_current:.2f}, 平滑前值: {w_close_prev:.2f}")
Log(f"[Trend] {'↑ 向上' if signal == 1 else '↓ 向下' if signal == -1 else '→ 横盘'}")
# 执行交易逻辑
if signal == 1 and position != 1:
# 平滑价格向上 → 做多
Log(f"[信号] 趋势向上,开多 @ {current_price:.2f}")
if position == -1:
# 先平空仓
exchange.SetDirection("closesell")
exchange.Buy(current_price, 1)
Log(f"[平仓] 平空仓")
# 开多仓
exchange.SetDirection("buy")
exchange.Buy(current_price, 1)
Log(f"[开仓] 开多仓")
position = 1
elif signal == -1 and position != -1:
# 平滑价格向下 → 做空
Log(f"[信号] 趋势向下,开空 @ {current_price:.2f}")
if position == 1:
# 先平多仓
exchange.SetDirection("closebuy")
exchange.Sell(current_price, 1)
Log(f"[平仓] 平多仓")
# 开空仓
exchange.SetDirection("sell")
exchange.Sell(current_price, 1)
Log(f"[开仓] 开空仓")
position = -1
else:
Log(f"[持仓] 当前{'多头' if position == 1 else '空头' if position == -1 else '空仓'},无需操作")
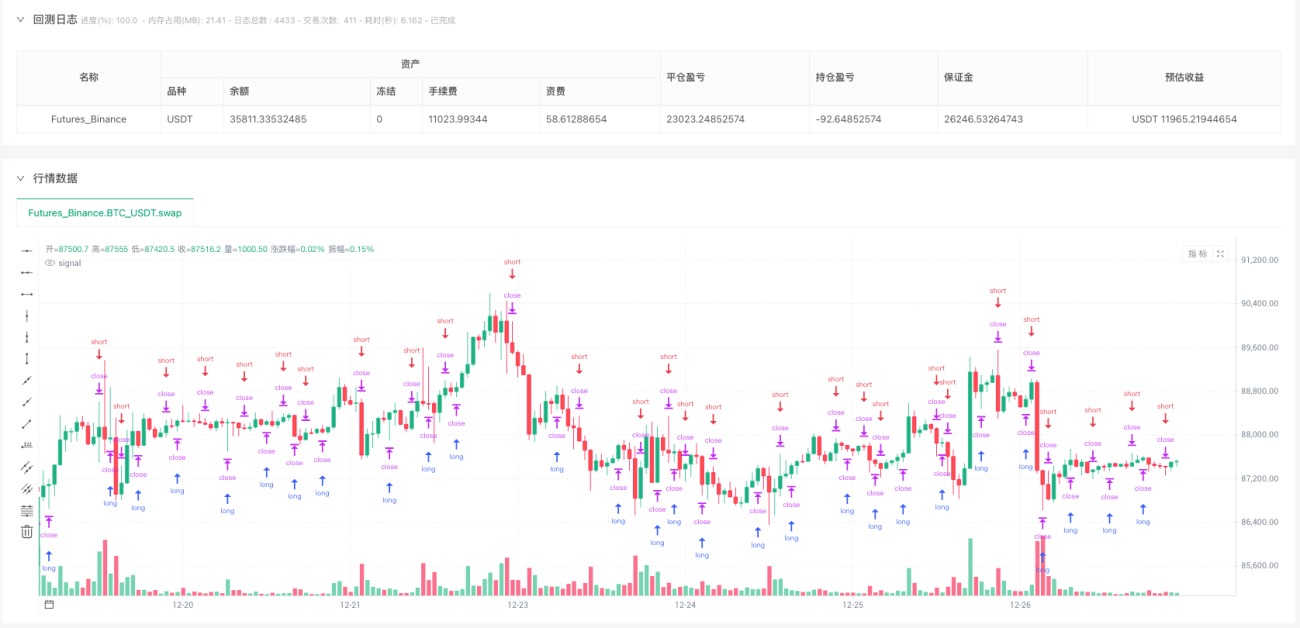
Bien sûr, en pratique, c'est plus complexe. Vous pouvez utiliser simultanément plusieurs niveaux d'ondelettes, par exemple le niveau 2 indiquant la tendance à court terme et le niveau 4 la tendance à long terme. N'ouvrez une position que lorsque les deux niveaux évoluent dans la même direction, ce qui réduit considérablement les faux signaux. Vous pouvez également ajouter d'autres critères de filtrage, comme exiger un volume de transactions plus élevé, une volatilité suffisamment élevée ou une cassure de prix au-dessus d'un niveau clé ; tous ces éléments peuvent améliorer le taux de réussite. Pour les ordres stop-loss, vous pouvez les paramétrer dynamiquement en fonction de l'amplitude de fluctuation du prix lissé par ondelettes ; par exemple, un stop-loss peut être déclenché si le prix descend en dessous du prix lissé moins deux fois l'ATR. En matière de gestion de position, plus la tendance est marquée (plus la pente du prix lissé est forte), plus la taille de la position doit être importante ; si la tendance est incertaine, privilégiez une position plus légère ou restez à l'écart.
L'idée de base reste la même : utiliser les ondelettes pour transformer les fluctuations de prix en tendances claires, puis tirer des conclusions à partir de ces tendances. Cette méthode est bien plus fiable que l'observation directe des variations sur le graphique en chandeliers original, car ce dernier peut afficher une hausse de 3 % aujourd'hui, une baisse de 2 % demain, puis une hausse de 4 % le surlendemain. Il est alors impossible de distinguer une tendance d'une fluctuation. La courbe traitée par ondelettes, quant à elle, indique que « la tendance générale sur cette période est haussière, malgré des fluctuations ponctuelles ».
VIII. Conclusion : Une vision rationnelle de l’« approche à trois volets »
En termes d'effets pratiques de lissage, la transformée en ondelettes peut effectivement jouer un rôle dans le traitement des données financières : elle permet de filtrer une partie du bruit à court terme et d'extraire des informations de tendance relativement claires. Cependant, cette technique présente également des limitations importantes.**Le problème du décalage ne peut être totalement évité.**Cependant, elle ne peut traiter que des données historiques et ne permet pas de prédire les tendances futures. De plus, l'utilisation de la transformée en ondelettes seule présente des limites ; elle doit être combinée à d'autres méthodes analytiques et à des mesures de contrôle des risques pour constituer un système de trading complet.
La principale raison de cette limitation réside dans la nature unique des marchés financiers. Dans les domaines traditionnels du traitement du signal, tels que la reconnaissance vocale et le traitement d'images, les caractéristiques du bruit sont relativement stables et les motifs du signal tendent à se répéter. Par conséquent, la transformée en ondelettes permet de séparer efficacement les signaux du bruit. Or, les marchés financiers sont fondamentalement différents : les fluctuations considérées aujourd'hui comme du « bruit » peuvent devenir demain des « signaux » reflétant les variations du marché ; les modèles analytiques performants aujourd'hui peuvent devenir inadaptés à l'avenir.**Le marché lui-même est non stationnaire et en constante évolution.**Il n'existe pas de lois immuables en matière de transformée en ondelettes, ce qui exige que son application dans le domaine financier soit adaptée avec souplesse à l'environnement spécifique du marché.
Lorsque vous voyez quelqu'un exagérer les effets réels des transformées en ondelettes et de Fourier, posez-lui les questions suivantes : Quel type d'ondelette a été utilisé ? Sur quoi se base ce choix plutôt qu'un autre ? Comment le niveau de lissage a-t-il été défini ? Existe-t-il des résultats de tests rétrospectifs et des procédures de sélection des paramètres ?Ceux qui possèdent véritablement des connaissances professionnelles seront capables d'expliquer clairement ces détails techniques essentiels.
Sur la base de nos connaissances limitées, nous avons mené cette exploration pratique.**L'idée principale est de partager les concepts d'application de la transformée en ondelettes de manière simple et facile à comprendre.**Cet article vise à familiariser les lecteurs avec les principes fondamentaux de cette technologie. Nous accordons une grande importance aux chercheurs quantitatifs qui œuvrent dans ce domaine ; si vous êtes expert en la matière, nous vous invitons à nous signaler toute lacune de l’article, notamment concernant les fondements théoriques du choix des paramètres d’ondelettes, les méthodes d’optimisation des combinaisons multi-échelles et les modalités d’implémentation de la sélection adaptative d’ondelettes. Nous accueillerons avec intérêt vos suggestions et nous nous efforcerons d’améliorer continuellement le contenu.
Fonction de traçage : appliquée dans le moteur de backtesting local de l’inventeur
python
'''backtest
start: 2025-12-17 00:00:00
end: 2025-12-23 08:00:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","fee":[0,0]}]
'''
from fmz import *
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
task = VCtx(__doc__)
# ==================== 小波系数库 ====================
class WaveletCoefficients:
"""Wavelet Coefficients Definition"""
@staticmethod
def get_coeffs(wavelet_name):
"""Get coefficients for different wavelet types"""
coeffs = {
"Haar": [0.5, 0.5],
"Daubechies 4": [
0.48296291314453414,
0.8365163037378079,
0.22414386804201339,
-0.12940952255126037
],
"Symlet 4": [
-0.05357, -0.02096, 0.35238,
0.56833, 0.21062, -0.07007,
-0.01941, 0.03268
],
"Biorthogonal 3.3": [
-0.06629, 0.28289, 0.63678,
0.28289, -0.06629
],
"Mexican Hat (Ricker)": [
-0.1, 0.0, 0.4, 0.8, 0.4, 0.0, -0.1
],
"Morlet (Gaussian)": [
0.0625, 0.25, 0.375, 0.25, 0.0625
],
"Discrete Meyer (Dmey)": [
-0.015, -0.025, 0.0,
0.28, 0.52, 0.28,
0.0, -0.025, -0.015
]
}
return coeffs.get(wavelet_name, coeffs["Mexican Hat (Ricker)"])
# ==================== 小波变换引擎 ====================
class WaveletTransform:
"""Wavelet Transform Engine"""
def __init__(self, wavelet_type="Mexican Hat (Ricker)", smoothing_level=3):
self.wavelet_type = wavelet_type
self.smoothing_level = smoothing_level
self.coeffs = WaveletCoefficients.get_coeffs(wavelet_type)
def convolve(self, src, coeffs, step):
"""
Convolution operation - Core algorithm
Args:
src: Source data sequence
coeffs: Wavelet coefficients
step: Sampling step
Returns:
Convolved value
"""
sum_val = 0.0
sum_w = 0.0
for i, weight in enumerate(coeffs):
idx = i * step
if idx < len(src):
val = src[idx]
sum_val += val * weight
sum_w += weight
# Normalization - Critical fix
return sum_val / sum_w if sum_w != 0 else sum_val
def calc_level(self, data, target_level):
"""
Calculate wavelet transform for specified level
Args:
data: Original data array
target_level: Target smoothing level
Returns:
Transformed data array
"""
result = []
coeffs = self.coeffs
for i in range(len(data)):
# Get data from current position backwards
src = data[max(0, i - 50):i + 1][::-1]
# Level 1
val = self.convolve(src, coeffs, 1)
# Level 2
if target_level >= 2:
src_temp = [val] + [self.convolve(data[max(0, j - 50):j + 1][::-1], coeffs, 1)
for j in range(max(0, i - 10), i)][::-1]
val = self.convolve(src_temp, coeffs, 2)
# Level 3
if target_level >= 3:
val = self.convolve([val] * len(coeffs), coeffs, 4)
# Level 4+
if target_level >= 4:
val = self.convolve([val] * len(coeffs), coeffs, 8)
result.append(val)
return np.array(result)
def transform_ohlc(self, df):
"""
Perform wavelet transform on OHLC data
Args:
df: DataFrame with Open/High/Low/Close
Returns:
Transformed DataFrame
"""
result_df = df.copy()
# Transform each price series
result_df['w_open'] = self.calc_level(df['Open'].values, self.smoothing_level)
result_df['w_high'] = self.calc_level(df['High'].values, self.smoothing_level)
result_df['w_low'] = self.calc_level(df['Low'].values, self.smoothing_level)
result_df['w_close'] = self.calc_level(df['Close'].values, self.smoothing_level)
# Reconstruct logically consistent candlesticks
result_df['real_high'] = result_df[['w_high', 'w_low', 'w_open', 'w_close']].max(axis=1)
result_df['real_low'] = result_df[['w_high', 'w_low', 'w_open', 'w_close']].min(axis=1)
return result_df
# ==================== K线图可视化工具 ====================
class WaveletCandlestickVisualizer:
"""Wavelet Candlestick Visualization"""
@staticmethod
def plot_single_wavelet(df, wavelet_type, smoothing_level=3, n_bars=200):
"""
Plot single wavelet type comparison
Args:
df: Original candlestick data
wavelet_type: Wavelet type
smoothing_level: Smoothing level
n_bars: Number of bars to display
"""
# Take only last n_bars
df_plot = df.iloc[-n_bars:].copy()
# Create figure
fig, ax = plt.subplots(figsize=(20, 8))
# Perform wavelet transform
transformer = WaveletTransform(wavelet_type, smoothing_level)
transformed = transformer.transform_ohlc(df)
transformed_plot = transformed.iloc[-n_bars:].copy()
# Draw original candlesticks (gray background)
WaveletCandlestickVisualizer._draw_candlesticks(
ax, df_plot,
color_up='lightgray',
color_down='lightgray',
alpha=0.3,
label='Original Candles'
)
# Draw wavelet smoothed candlesticks
WaveletCandlestickVisualizer._draw_candlesticks(
ax, transformed_plot,
use_wavelet=True,
color_up='#26A69A', # Green
color_down='#EF5350', # Red
alpha=0.9,
linewidth=1.2,
label=f'{wavelet_type} Smoothed (Level {smoothing_level})'
)
# Set title and labels
ax.set_title(f'{wavelet_type} Wavelet (Level {smoothing_level}) - Candlestick Comparison',
fontsize=16, fontweight='bold', pad=20)
ax.set_ylabel('Price (USDT)', fontsize=13)
ax.set_xlabel('Time', fontsize=13)
ax.grid(True, alpha=0.2, linestyle='--')
ax.legend(loc='upper left', fontsize=12)
# Format x-axis
ax.set_xlim(-1, len(df_plot))
ax.set_xticks(range(0, len(df_plot), max(1, len(df_plot) // 10)))
ax.set_xticklabels([df_plot.index[i].strftime('%m-%d %H:%M')
for i in range(0, len(df_plot), max(1, len(df_plot) // 10))],
rotation=45, ha='right')
plt.tight_layout()
plt.show()
return fig
@staticmethod
def plot_single_level(df, wavelet_type, level, n_bars=200):
"""
Plot single smoothing level
Args:
df: Original candlestick data
wavelet_type: Wavelet type
level: Smoothing level
n_bars: Number of bars to display
"""
# Take only last n_bars
df_plot = df.iloc[-n_bars:].copy()
# Create figure
fig, ax = plt.subplots(figsize=(20, 8))
# Perform wavelet transform
transformer = WaveletTransform(wavelet_type, level)
transformed = transformer.transform_ohlc(df)
transformed_plot = transformed.iloc[-n_bars:].copy()
# Draw original candlesticks
WaveletCandlestickVisualizer._draw_candlesticks(
ax, df_plot,
color_up='lightgray',
color_down='lightgray',
alpha=0.3,
label='Original Candles'
)
# Draw wavelet smoothed candlesticks
WaveletCandlestickVisualizer._draw_candlesticks(
ax, transformed_plot,
use_wavelet=True,
color_up='#26A69A',
color_down='#EF5350',
alpha=0.9,
linewidth=1.2,
label=f'Level {level} Smoothed'
)
# Set title and labels
ax.set_title(f'{wavelet_type} - Smoothing Level {level} Effect',
fontsize=16, fontweight='bold', pad=20)
ax.set_ylabel('Price (USDT)', fontsize=13)
ax.set_xlabel('Time', fontsize=13)
ax.grid(True, alpha=0.2, linestyle='--')
ax.legend(loc='upper left', fontsize=12)
# Format x-axis
ax.set_xlim(-1, len(df_plot))
ax.set_xticks(range(0, len(df_plot), max(1, len(df_plot) // 10)))
ax.set_xticklabels([df_plot.index[i].strftime('%m-%d %H:%M')
for i in range(0, len(df_plot), max(1, len(df_plot) // 10))],
rotation=45, ha='right')
plt.tight_layout()
plt.show()
return fig
@staticmethod
def _draw_candlesticks(ax, df, use_wavelet=False, color_up='green',
color_down='red', alpha=1.0, linewidth=1.0, label=''):
"""
Draw candlestick chart
Args:
ax: Matplotlib axis
df: Data DataFrame
use_wavelet: Whether to use wavelet data
color_up: Up color
color_down: Down color
alpha: Transparency
linewidth: Line width
label: Legend label
"""
if use_wavelet:
opens = df['w_open'].values
highs = df['real_high'].values
lows = df['real_low'].values
closes = df['w_close'].values
else:
opens = df['Open'].values
highs = df['High'].values
lows = df['Low'].values
closes = df['Close'].values
for i in range(len(df)):
x = i
open_price = opens[i]
high_price = highs[i]
low_price = lows[i]
close_price = closes[i]
color = color_up if close_price >= open_price else color_down
# Draw wick
ax.plot([x, x], [low_price, high_price],
color=color, linewidth=linewidth, alpha=alpha)
# Draw body
height = abs(close_price - open_price)
bottom = min(open_price, close_price)
rect = Rectangle((x - 0.3, bottom), 0.6, height,
facecolor=color, edgecolor=color,
alpha=alpha, linewidth=linewidth)
ax.add_patch(rect)
# Add legend (only once)
if label:
ax.plot([], [], color=color_up, linewidth=3, alpha=alpha, label=label)
# ==================== 主函数 ====================
def main():
"""Main execution flow"""
exchange.SetCurrency("BTC_USDT")
exchange.SetContractType("swap")
# Get candlestick data
records = exchange.GetRecords(PERIOD_H1, 500)
# Convert to DataFrame
df = pd.DataFrame(records, columns=['Time', 'Open', 'High', 'Low', 'Close', 'Volume'])
df['Time'] = pd.to_datetime(df['Time'], unit='ms')
df.set_index('Time', inplace=True)
print(f"Data loaded: {len(df)} bars")
print(f"Time range: {df.index[0]} to {df.index[-1]}")
print(f"Price range: ${df['Low'].min():.2f} - ${df['High'].max():.2f}")
return df
# ==================== 执行绘图 ====================
try:
# Get candlestick data
kline = main()
print("\n" + "="*70)
print("Generating Wavelet Candlestick Charts (Each in Separate Window)...")
print("="*70)
# ========== Chart Series 1: Different Wavelet Types ==========
print("\n[Series 1] Comparing Different Wavelet Types")
print("-" * 70)
wavelet_types = [
"Haar",
"Daubechies 4",
"Symlet 4",
"Biorthogonal 3.3",
"Mexican Hat (Ricker)",
"Morlet (Gaussian)",
"Discrete Meyer (Dmey)" # ✅ 添加了 Discrete Meyer
]
for i, wavelet_type in enumerate(wavelet_types, 1):
print(f" Chart {i}/{len(wavelet_types)}: {wavelet_type}")
fig = WaveletCandlestickVisualizer.plot_single_wavelet(
kline,
wavelet_type=wavelet_type,
smoothing_level=3,
n_bars=150
)
# ========== Chart Series 2: Different Smoothing Levels ==========
print("\n[Series 2] Comparing Different Smoothing Levels")
print("-" * 70)
levels = [1, 2, 3, 4, 5]
for i, level in enumerate(levels, 1):
print(f" Chart {i}/5: Level {level}")
fig = WaveletCandlestickVisualizer.plot_single_level(
kline,
wavelet_type="Mexican Hat (Ricker)",
level=level,
n_bars=150
)
print("\n" + "="*70)
print("All charts generated successfully!")
print(f"Total charts: {len(wavelet_types) + len(levels)} ({len(wavelet_types)} wavelets + {len(levels)} levels)")
print("="*70)
except Exception as e:
print(f"Error: {str(e)}")
import traceback
print(traceback.format_exc())
finally:
print("\nStrategy testing completed.")
Fonctions transactionnelles : appliquées sur la plateforme Inventors
python
'''backtest
start: 2025-01-17 00:00:00
end: 2025-12-23 08:00:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","fee":[0,0]}]
'''
import numpy as np
import pandas as pd
# ==================== 小波系数库 ====================
class WaveletCoefficients:
"""与上部分函数一致"""
# ==================== 小波变换引擎 ====================
class WaveletTransform:
"""与上部分函数一致"""
def main():
"""小波交易主函数 - 基于平滑价格趋势"""
# ========== 配置参数 ==========
WAVELET_TYPE = "Mexican Hat (Ricker)" # 小波类型
SMOOTHING_LEVEL = 1 # 平滑阶数
# 初始化
exchange.SetCurrency("BTC_USDT")
exchange.SetContractType("swap")
Log(f"=" * 70)
Log(f"Wavelet Trend Following Strategy")
Log(f"Wavelet: {WAVELET_TYPE}, Level: {SMOOTHING_LEVEL}")
Log(f"Logic: 平滑收盘价向上→做多, 平滑收盘价向下→做空")
Log(f"=" * 70)
# 初始化小波变换器
transformer = WaveletTransform(WAVELET_TYPE, SMOOTHING_LEVEL)
# 持仓状态
position = 0 # 0: 无持仓, 1: 多头, -1: 空头
while True:
# 获取K线数据
records = exchange.GetRecords(PERIOD_H1, 500)
if not records:
Log("[Warning] Failed to get kline data")
Sleep(5000)
continue
df = pd.DataFrame(records, columns=['Time', 'Open', 'High', 'Low', 'Close', 'Volume'])
df['Time'] = pd.to_datetime(df['Time'], unit='ms')
df.set_index('Time', inplace=True)
# 执行小波变换
transformed = transformer.transform_ohlc(df)
# 获取最近两根K线的平滑收盘价
w_close_current = transformed['w_close'].values[-1] # 当前平滑收盘价
w_close_prev = transformed['w_close'].values[-2] # 前一根平滑收盘价
# 判断趋势方向
signal = 0
if w_close_current > w_close_prev:
signal = 1 # 平滑价格向上 → 做多
elif w_close_current < w_close_prev:
signal = -1 # 平滑价格向下 → 做空
# 获取账户信息
account = exchange.GetAccount()
ticker = exchange.GetTicker()
if not account or not ticker:
Log("[Warning] Failed to get account/ticker info")
Sleep(5000)
continue
current_price = ticker['Last']
Log(f"[Price] 原始: {df['Close'].values[-1]:.2f}, "
f"平滑当前: {w_close_current:.2f}, 平滑前值: {w_close_prev:.2f}")
Log(f"[Trend] {'↑ 向上' if signal == 1 else '↓ 向下' if signal == -1 else '→ 横盘'}")
# 执行交易逻辑
if signal == 1 and position != 1:
# 平滑价格向上 → 做多
Log(f"[信号] 趋势向上,开多 @ {current_price:.2f}")
if position == -1:
# 先平空仓
exchange.SetDirection("closesell")
exchange.Buy(current_price, 1)
Log(f"[平仓] 平空仓")
# 开多仓
exchange.SetDirection("buy")
exchange.Buy(current_price, 1)
Log(f"[开仓] 开多仓")
position = 1
elif signal == -1 and position != -1:
# 平滑价格向下 → 做空
Log(f"[信号] 趋势向下,开空 @ {current_price:.2f}")
if position == 1:
# 先平多仓
exchange.SetDirection("closebuy")
exchange.Sell(current_price, 1)
Log(f"[平仓] 平多仓")
# 开空仓
exchange.SetDirection("sell")
exchange.Sell(current_price, 1)
Log(f"[开仓] 开空仓")
position = -1
else:
Log(f"[持仓] 当前{'多头' if position == 1 else '空头' if position == -1 else '空仓'},无需操作")
Log(f"[账户] 余额: {account['Balance']:.2f}, 权益: {account['Equity']:.2f}")
Log("-" * 70)
Sleep(60000 * 60)
- 1