
Market Collector est à nouveau mis à niveau : prend en charge l'importation de fichiers au format CSV et fournit une source de données personnalisée
Récemment, un utilisateur a eu besoin d’utiliser son propre fichier au format CSV comme source de données pour le système de backtesting de la plateforme de trading quantitatif Inventor. Le système de backtesting de la plateforme de trading quantitative Inventor possède de nombreuses fonctions et est simple et efficace à utiliser. Tant que vous disposez des données, vous pouvez effectuer des backtesting et vous n'êtes plus limité aux échanges et aux produits pris en charge par le centre de données de la plateforme .
Idées de conception
L'idée de conception est en fait très simple. Nous devons simplement apporter une légère modification au collecteur de marché précédent. Nous ajoutons un paramètre au collecteur de marché.isOnlySupportCSVUtilisé pour contrôler s'il faut utiliser uniquement des fichiers CSV comme sources de données pour le système de backtesting et ajouter un autre paramètrefilePathForCSV, utilisé pour définir le chemin d'accès au fichier de données CSV sur le serveur sur lequel s'exécute le robot collecteur de marché. Enfin, selonisOnlySupportCSVLe paramètre est-il défini surTruePour décider quelle source de données utiliser (1. collectées par vous-même, 2. données dans un fichier CSV), ce changement concerne principalementProviderClassedo_GETfonction.
Qu'est-ce qu'un fichier CSV ?
Les valeurs séparées par des virgules (CSV, parfois également appelées valeurs séparées par des caractères car les caractères de délimitation peuvent être autres que des virgules) sont des fichiers qui stockent des données tabulaires (nombres et texte) en texte brut. Le texte brut signifie que le fichier est une séquence de caractères et ne contient aucune donnée devant être interprétée comme des nombres binaires. Un fichier CSV se compose d'un nombre quelconque d'enregistrements, séparés par une sorte de caractère de saut de ligne ; chaque enregistrement se compose de champs, et le séparateur entre les champs est constitué d'autres caractères ou chaînes, dont les plus courants sont les virgules ou les tabulations. En règle générale, tous les enregistrements ont exactement la même séquence de champs. Il s’agit généralement de fichiers texte brut. Il est recommandé d'utiliser WORDPAD ou le Bloc-notes pour l'ouvrir. Une autre méthode consiste à l'enregistrer en tant que nouveau fichier, puis à l'ouvrir avec EXCEL.
Il n'existe pas de norme universelle pour le format de fichier CSV, mais il existe certaines règles, généralement une ligne par enregistrement, la première ligne étant l'en-tête. Les données de chaque ligne sont séparées par des virgules.
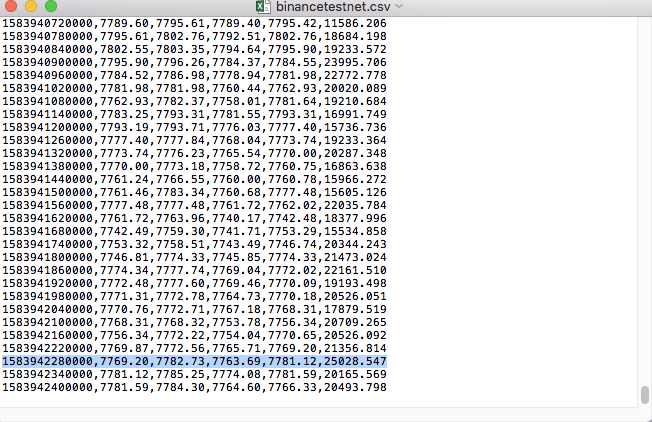
Par exemple, le fichier CSV que nous avons utilisé pour les tests ressemble à ceci lorsqu'il est ouvert avec le Bloc-notes :
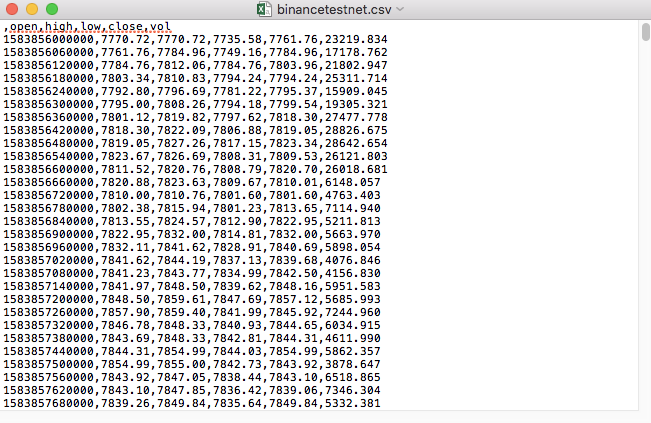
Notez que la première ligne du fichier CSV est l’en-tête du tableau.
,open,high,low,close,vol
Nous devons analyser et organiser ces données, puis les construire dans le format requis par la source de données personnalisée du système de backtesting. Cette opération a déjà été traitée dans le code de notre article précédent et ne nécessite que de légères modifications.
Code modifié
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Exécution de tests
Tout d’abord, nous démarrons le robot collecteur de marché, ajoutons un échange au robot et laissons le robot fonctionner.
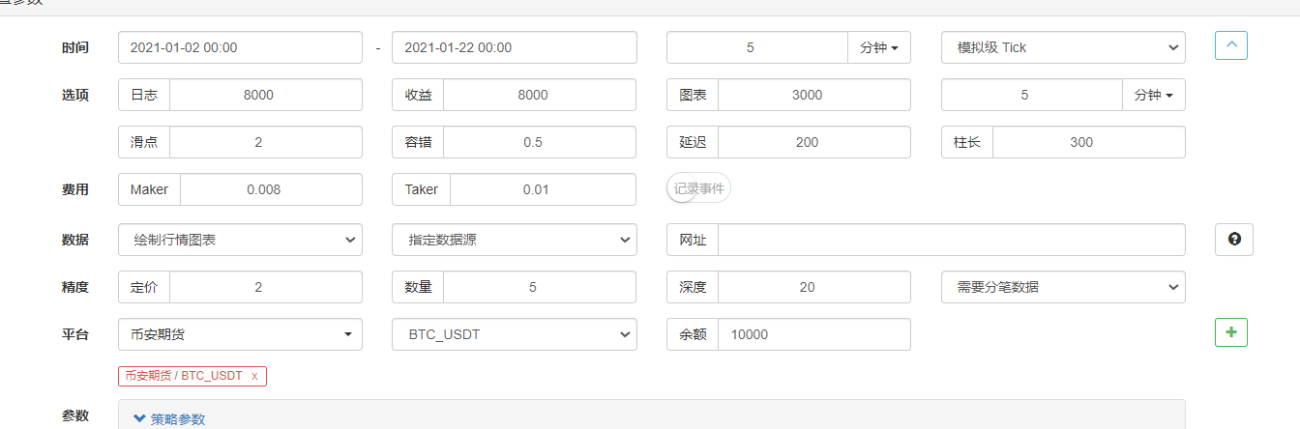
Configuration des paramètres :

Ensuite, nous créons une stratégie de test :
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
La stratégie est très simple, il suffit d'obtenir et d'imprimer trois données de ligne K.
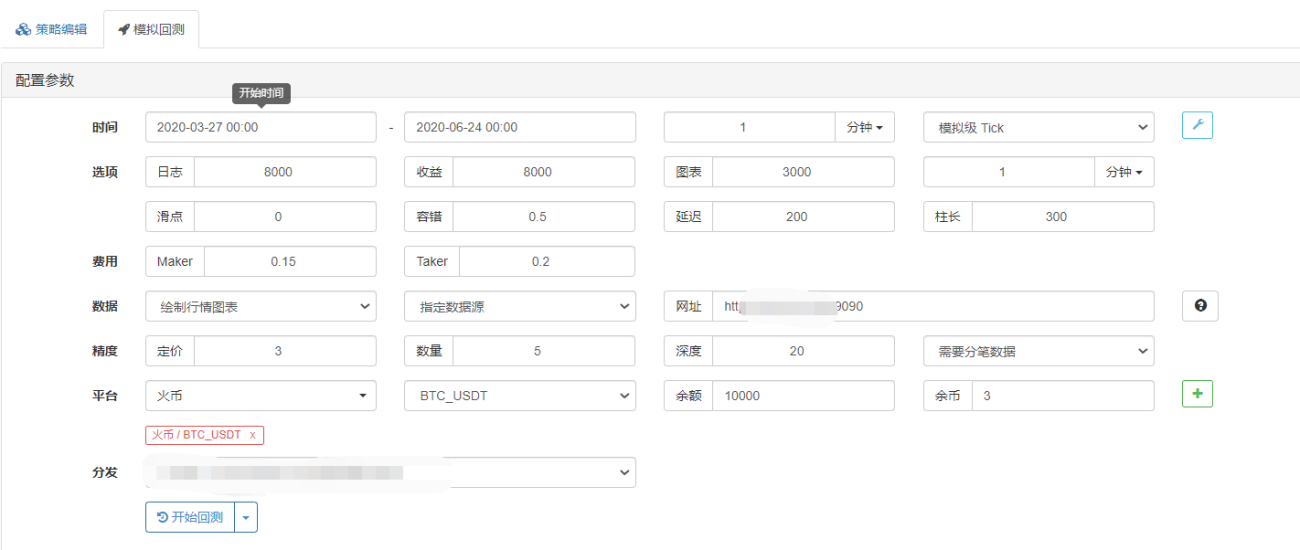
Sur la page de backtesting, définissez la source de données du système de backtesting sur une source de données personnalisée et renseignez l'adresse du serveur sur lequel s'exécute le robot collecteur de marché. Étant donné que les données de notre fichier CSV sont des lignes K d'une durée de 1 minute. Par conséquent, lors du backtesting, nous définissons la période de la ligne K à 1 minute.
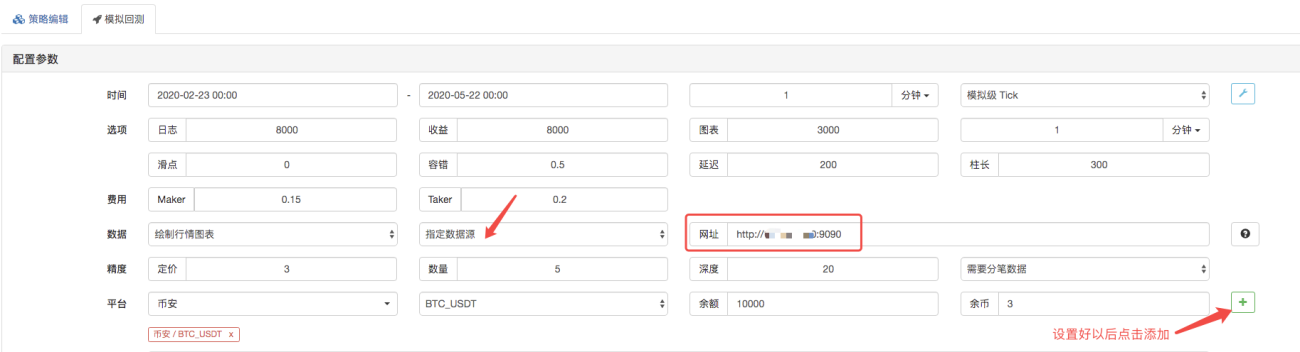
Cliquez sur Démarrer le backtesting et le robot collecteur de marché reçoit la demande de données :

Une fois que le système de backtesting a terminé l'exécution de la stratégie, il génère un graphique K-line basé sur les données K-line de la source de données.
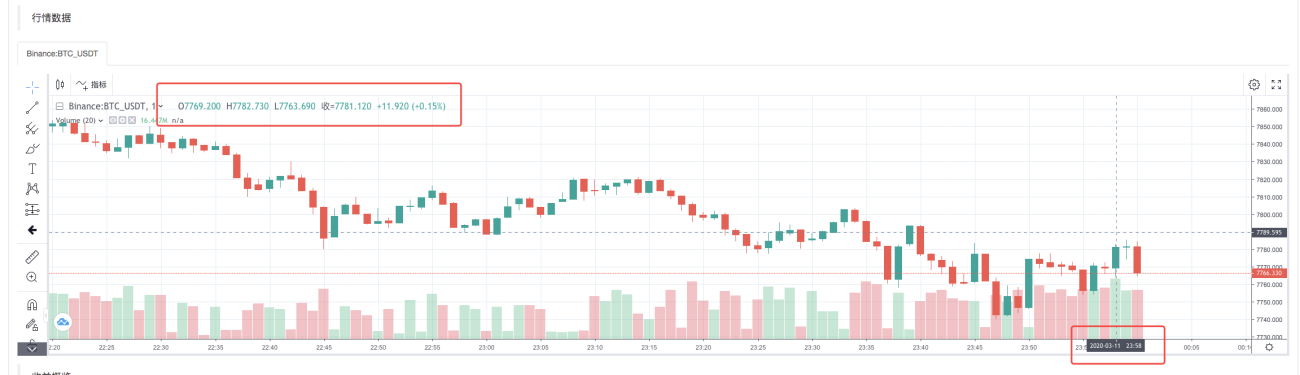
Comparez les données du fichier :

Ceci n'est qu'un point de départ, n'hésitez pas à laisser un message.




请问一下,为什么我在托管服务器上面设置好了自定义CSV数据源,用页面请求有数据的返回,然后在回测中没有数据的返回,当把数据直接设置为只有俩个数据的时候httpserver服务端可以接收请求中, 




你在浏览器端可以是因为 你指定写的查询参数, 回测系统 触发不了 机器人 应答,说明机器人没接受到请求, 说明回测时那个地方配置错了, 检查下,调试下就能找到问题。
请问一下 怎么可以在本地起http服务端 本地回测数据, 是不是本地回测不支持回测自定义数据源?我在本地回测添加exchanges: [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"}]这种参数,以及改成机器人的IP也是没有请求到服务端



- 1