
Une étude préliminaire sur l'application du crawler Python sur la plateforme FMZ - crawling Binance annonce content
J'ai récemment examiné la communauté et la bibliothèque et je n'ai trouvé aucune information pertinente sur les robots Python, basée sur l'esprit de développement complet en tant que QUANT. J'ai appris les concepts et les connaissances liés aux crawlers très simplement. Après en avoir appris davantage sur le sujet, j'ai découvert que la « technologie des robots d'exploration » était un « gouffre » assez vaste. Cet article n'est qu'une exploration préliminaire de la « technologie des robots d'exploration ». Faisons la pratique la plus simple de la technologie du crawler sur la plateforme de trading quantitative FMZ.
besoin
Pour les traders qui aiment investir dans de nouvelles pièces, ils espèrent toujours obtenir des informations sur la cotation des pièces en bourse le plus rapidement possible. Il n’est évidemment pas réaliste de surveiller manuellement le site Web de l’échange. Vous devez ensuite utiliser un script d'exploration pour surveiller la page d'annonce d'échange et détecter les nouvelles annonces afin que vous puissiez être averti et rappelé dès que possible.
Exploration initiale
Commençons par un programme très simple (un script de crawler vraiment puissant est beaucoup plus compliqué, alors prenez votre temps). La logique du programme est très simple, elle consiste à permettre au programme d'accéder en continu à la page d'annonce de l'échange, d'analyser le contenu HTML obtenu et de détecter si le contenu d'une balise spécifique est mis à jour.
Code de mise en œuvre
Vous pouvez utiliser certains frameworks d'exploration utiles. Cependant, étant donné que l’exigence est très simple, il est également possible de l’écrire directement.
Des bibliothèques Python sont nécessaires :
requests, qui peut être simplement compris comme une bibliothèque utilisée pour accéder aux pages Web.
bs4, qui peut être simplement compris comme une bibliothèque utilisée pour analyser le code HTML d'une page Web.
Code:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
courir
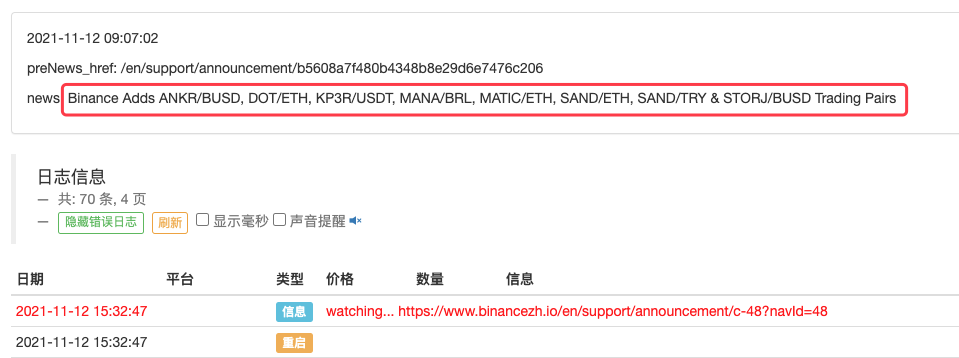
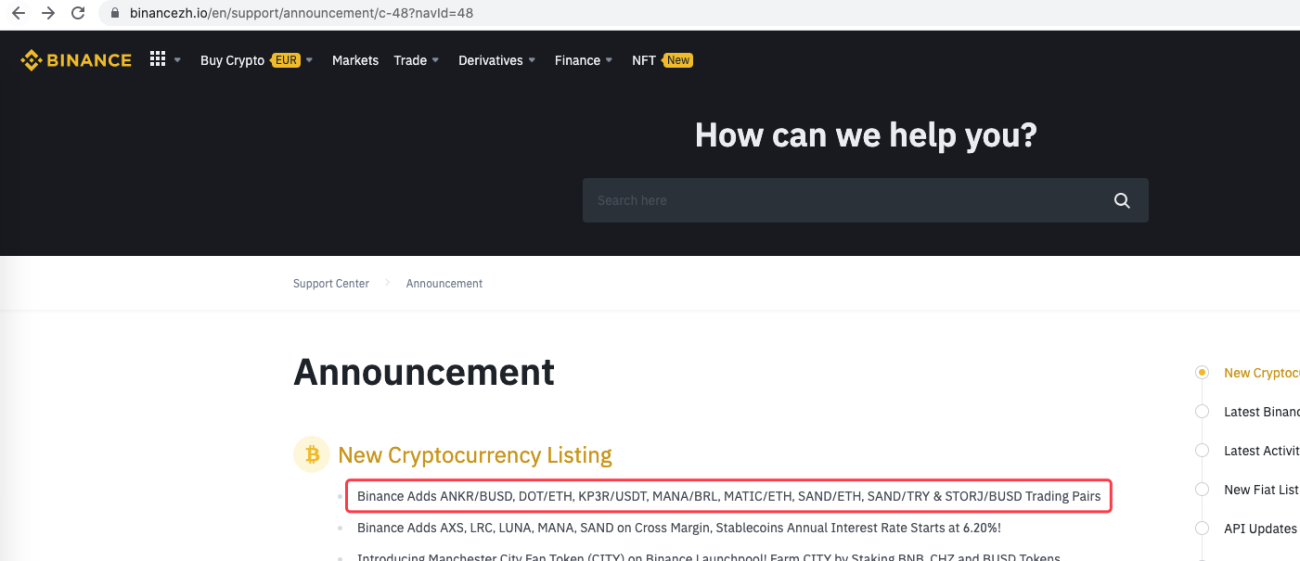
Il peut même être étendu pour détecter quand une nouvelle annonce apparaît, par exemple. Analysez les nouvelles devises dans l'annonce et passez automatiquement des commandes pour de nouvelles transactions.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1