【Arbitrage statistique de couverture neutre New】(Pure-Alpha Version de rêve)

【Neutre de couverture statistique arbitrage New】(Pure-Alpha Rêve Édition)
-0 Stratégie d'arbitrage statistique de couverture neutre avec exposition zéro long-short
Bonjour à tous les traders, après plusieurs mois de réglage, d'optimisation et d'itérations, je suis ravi que cet arbitrage statistique neutre de couverture ait atteint un niveau relativement stable et puisse être présenté à tous. Il s'agit d'une stratégie neutre par rapport au marché basée sur la couverture long-short. Elle achète un panier de produits et vend un autre panier de produits dans le même compte, la valeur long étant égale à la valeur short. Tout en évitant le risque systématique bêta du marché, elle utilise des méthodes statistiques pour trouver diverses paires long-short et réaliser des bénéfices alpha stables à faible risque. Cette stratégie offre une bonne expérience de détention, une faible corrélation avec le marché global, une exposition neutre long-short et n'encourt absolument aucun risque lors de cygnes noirs extrêmes comme les événements 312/519. Au contraire, elle brille dans ces périodes de confusion totale des prix du marché. Vous trouverez ci-dessous une explication détaillée de cette stratégie.
Hello~Welcome come to my channel !
Bienvenue sur ma chaîne, chers traders. Je suis M. Trade, un développeur quantitatif (Quant Developer) spécialisé dans le développement de stratégies de trading CTA, HFT et d'arbitrage en full-stack.
Je remercie la plateforme FMZ. Je partagerai davantage de contenu lié au développement quantitatif sur ma chaîne de trading quantitatif, afin de contribuer à la prospérité de la communauté du trading quantitatif avec tous les traders.
Pour plus d'informations, rendez-vous sur ma chaîne ~ Je t'attends ici pour discuter 【La petite cabane quantique de M. Trade】
I. Introduction et explication de l'arbitrage statistique
L'arbitrage statistique est une stratégie qui exploite les relations de prix entre différents paniers de produits. Basée sur des principes statistiques, elle analyse les tendances historiques des prix et les corrélations entre plusieurs produits, identifie leurs écarts de prix et les utilise pour les transactions. Historiquement, l'arbitrage statistique a été largement utilisé sur les marchés boursiers, d'abord entre actions de sociétés pétrolières ou de télécommunications, par exemple. Ces stratégies reposaient souvent sur l'hypothèse de corrélations sectorielles : acheter les actions sous-évaluées et vendre les actions surévaluées pour réaliser un arbitrage.
Avec l'évolution des marchés, l'arbitrage statistique s'est étendu à d'autres marchés financiers, tels que les futures sur matières premières, le forex et les cryptomonnaies. Sur ces marchés, on peut trouver des paniers de produits corrélés et exploiter les écarts de prix pour des transactions d'arbitrage. La logique de cette stratégie repose sur le principe de retour à la moyenne. Lorsque les prix entre les paniers de produits construits s'écartent de leur plage statistique, il existe une tendance au retour. En suivant cette tendance, on peut vendre le panier surévalué et acheter le panier sous-évalué lorsque l'écart de prix devient important, afin de réaliser des transactions de couverture contre les erreurs de prix temporaires du marché. Ainsi, on obtient des gains basés sur la différence de prix entre les paires de paniers.
II. Avantages et inconvénients de l'arbitrage statistique
Avantages :
- Réduction du risque de marché : l'arbitrage statistique repose sur les différences entre les paniers de produits. Par rapport au trading d'un seul produit, il diversifie le risque et réduit l'impact des fluctuations du marché sur la stratégie, diminuant ainsi le risque systémique.
- Revenus stables : l'arbitrage statistique cible les erreurs de prix temporaires du marché pour un trading de retour à la moyenne. Comparé aux stratégies directionnelles, il présente des caractéristiques de revenus plus stables, avec un risque plus faible, une volatilité réduite et une stabilité accrue.
- Adaptabilité à différents environnements de marché : l'arbitrage statistique peut fonctionner dans divers environnements de marché car cette stratégie est peu corrélée à la direction du marché.
Inconvénients :
- Les données historiques ne reflètent que les relations passées et ne peuvent pas représenter complètement l'avenir, ce qui comporte un certain risque. La construction de l'arbitrage statistique utilise de nombreux tests statistiques, s'appuyant sur de grandes masses de données historiques pour identifier les combinaisons de paniers et les corrélations. Ces relations peuvent évoluer à l'avenir, entraînant un risque de queue.
- Il est difficile de juger précisément l'horizon temporel nécessaire pour que les prix erronés à court terme du marché reviennent à l'équilibre. Si la transaction prend trop de temps, le coût d'utilisation des capitaux peut devenir un défi important.
- Exigences élevées en matière d'analyse de données et de modélisation : l'arbitrage statistique nécessite une analyse approfondie et une modélisation des corrélations et de la cointégration entre les différents paniers de produits. Cela exige de solides compétences en analyse de données et en construction de modèles.
- Risques d'exécution et de liquidité : étant donné qu'il s'agit de transactions de couverture multiproduits, les prix d'exécution et les volumes peuvent être affectés par différents produits, ce qui entraîne des risques d'exécution. Une conception et une architecture de stratégie plus sophistiquées sont nécessaires.
III. Contenu principal de cet arbitrage statistique Alpha
1. Surveillance en temps réel des données de tous les produits, analyse big data et construction de paniers long-short.
Spécifiquement, on construit des paires de paniers : par exemple, avec 6 produits A, B, C, D, E, F, on peut les diviser en 2 groupes de 3 produits chacun pour former un panier. On construit également un arbitrage d'indice : diviser certains secteurs et certains produits en deux, créer deux nouveaux indices de marché, puis effectuer l'analyse statistique ultérieure sur ces deux indices.
2. Test de corrélation des paniers long-short.
La corrélation mesure le degré d'association entre deux ou plusieurs variables. Elle évalue la relation entre les variations d'une variable et celles d'une autre, aidant à déterminer s'il existe une correspondance ou à prédire l'impact d'une variable sur une autre. Le coefficient de corrélation est une méthode courante, avec notamment le coefficient de corrélation de Pearson et le coefficient de corrélation de rang de Spearman. Le coefficient de Pearson évalue la relation entre deux variables continues, tandis que celui de Spearman convient à deux variables ordinales. Le coefficient de corrélation varie de -1 à 1, où -1 indique une corrélation négative, 1 une corrélation positive, et 0 aucune corrélation. Plus il est proche de -1 ou 1, plus la corrélation est forte ; proche de 0, plus faible. La formule mathématique du coefficient de corrélation (exemple avec Pearson) est la suivante :
r = cov(X, Y) / (std(X) * std(Y))
où r est le coefficient de corrélation, cov la covariance, std l'écart-type, et X et Y les deux variables. Pour tester la corrélation, on utilise souvent la significativité statistique du coefficient. Un test d'hypothèse peut être employé pour déterminer si le coefficient est significatif. L'hypothèse nulle est qu'il n'y a pas de corrélation entre les variables, et on calcule la statistique du coefficient pour décider de rejeter ou non l'hypothèse nulle.
3. Test de cointégration des paniers long-short.
La cointégration fait référence à la relation à long terme entre deux ou plusieurs séries temporelles, où leur combinaison linéaire est stationnaire. Contrairement à la corrélation, la cointégration se concentre davantage sur la relation d'équilibre à long terme, et pas seulement sur l'association à court terme. Lorsqu'elles s'écartent de cette relation d'équilibre, un mécanisme de correction ramène l'écart dans une fourchette raisonnable. Le concept de cointégration a été introduit pour la première fois par S.G.Engle et C.W.J.Granger en 1987 pour résoudre le problème de régression fallacieuse dans l'analyse des séries temporelles. Ce problème survient en raison de la présence possible de racines unitaires dans les variables, rendant les régressions apparemment significatives à court terme mais sans véritable relation d'équilibre à long terme.
La théorie de la cointégration part de l'analyse de la non-stationnarité des séries temporelles pour explorer les relations d'équilibre à long terme contenues dans les variables non stationnaires. Si les variables sont stationnaires après différenciation de premier ordre et qu'il existe une combinaison linéaire stationnaire de ces variables, on dit qu'elles sont cointégrées. La cointégration décrit la relation stationnaire entre deux ou plusieurs séries. Chaque série individuellement peut être non stationnaire, avec des moments (moyenne, variance, covariance) évoluant dans le temps, mais leur combinaison linéaire peut avoir des propriétés temporelles invariantes. Lorsque deux prix d'actifs suivent une relation de cointégration, leur combinaison linéaire présente un retour à la moyenne. La formule mathématique de la cointégration (exemple avec deux séries temporelles) est la suivante :
Y_t = β_0 + β_1 * X_t + ε_t
où Y_t et X_t sont les observations des deux séries, β_1 le coefficient de régression, et ε_t le terme d'erreur. Si Y_t et X_t sont cointégrés, la combinaison linéaire des deux variables sera stationnaire, c'est-à-dire que ε_t est stationnaire et suit une distribution normale de moyenne nulle. Pour tester la cointégration, on effectue généralement des tests de stationnarité, les plus courants étant le test de Johansen et le test d'Engle-Granger. Le test de Johansen, basé sur les valeurs propres, peut tester directement la cointégration entre plusieurs variables. La méthode en deux étapes d'Engle-Granger, basée sur une estimation OLS modifiée, convient pour tester la cointégration entre deux variables.
4. Cette stratégie effectue des tests de cointégration pour de nombreuses combinaisons de séries temporelles, avec les critères suivants :
- Les séries temporelles de prix des paniers individuels sont des vecteurs intégrés d'ordre un, c'est-à-dire qu'elles sont non stationnaires (avec une tendance évidente). Test de racine unitaire ADF pour vérifier la stationnarité de multiples séries temporelles de prix.
- Les séries après différenciation de premier ordre (dérivées) des paniers individuels sont stationnaires. Test de racine unitaire ADF pour les séries temporelles de prix des deux paniers. Test ADF pour la stationnarité des différences de premier ordre des deux séries de prix des paniers.
- Une combinaison linéaire des séries temporelles de prix des paires est stationnaire, c'est-à-dire que les résidus de l'équation linéaire construite à partir des deux séries sont stationnaires. Effectuer une régression OLS sur les deux séries de même ordre, puis tester la stationnarité des résidus.
- D'autres tests statistiques et analyses de données ne sont pas détaillés ici ; une analyse statistique complète et minutieuse à grande échelle est effectuée sur l'ensemble du marché et tous les produits.
5. Réalisation de nombreux tests de l'exposant de Hurst.
L'exposant de Hurst mesure la mémoire à long terme d'une série temporelle, afin de déterminer ses propriétés de retour à la moyenne. Il varie entre 0 et 1. Une valeur proche de 0,5 indique une marche aléatoire, proche de 1 indique une tendance persistante. Principe : l'exposant de Hurst estime le degré de mémoire à long terme en calculant la relation entre la plage de dispersion des sous-séquences qui se chevauchent et leur longueur. Formule mathématique : une méthode pour calculer l'exposant de Hurst consiste à établir une relation linéaire entre la plage de dispersion des sous-séquences qui se chevauchent et leur longueur, en s'appuyant sur une régression linéaire pour estimer l'exposant.
6. Estimation de la demi-vie de retour à la moyenne.
La demi-vie de retour à la moyenne est un indicateur permettant d'estimer le temps nécessaire pour que la série de prix revienne à sa moyenne. Plus la demi-vie est courte, plus la vitesse de retour à la moyenne est rapide. Principe : le calcul de la demi-vie de retour à la moyenne estime le modèle de moyenne mobile exponentielle (EMA) convergente. Lorsque l'écart de la série de prix par rapport à sa moyenne dépasse la demi-vie, on considère qu'il existe une opportunité de retour à la moyenne. Formule mathématique : la demi-vie de retour à la moyenne se calcule comme suit :
(H = -\frac{\ln(0,5)}{\ln(\frac{P_t}{P_t - P_{t-1}})})
Méthode de test : on peut calculer l'EMA de la série de prix, puis estimer la demi-vie à partir de celle-ci.
7. Construction de la stratégie de trading basée sur de nombreuses données statistiques.
Description simplifiée : filtrer les combinaisons de paniers en fonction du classement de l'exposant de Hurst, estimer les paramètres statistiques pertinents à l'aide de la demi-vie de retour à la moyenne, et construire la stratégie de trading basée sur la cointégration. Les détails supplémentaires ne sont pas décrits.
Soient \(x\) et \(y\) les séries temporelles de prix des paniers d'actifs X et Y respectivement. Leur relation de cointégration peut s'exprimer comme suit : \(\ln y = a + b \ln x + c\), où \(c\) est le terme résiduel, stationnaire, suivant une distribution normale de moyenne nulle.
Après un test de cointégration, les séries de prix des actifs X et Y présentent une relation de cointégration, l'écart-type du terme résiduel \(c\) est \(\sigma\), et une constante \(\lambda\) est choisie comme seuil.
- Lorsque \(\ln y - (a + b \ln x) > \lambda\sigma\), le panier Y est relativement surévalué et le panier X est relativement sous-évalué : acheter le panier X, vendre le panier Y.
- Lorsque \(\ln y - (a + b \ln x) < -\lambda\sigma\), le panier X est relativement surévalué et le panier Y est relativement sous-évalué : acheter le panier Y, vendre le panier X.
- Lorsque l'écart \(\ln y - (a + b \ln x)\) revient dans une certaine plage, par exemple \([-0.5\lambda\sigma, 0.5\lambda\sigma]\), on procède à la liquidation.
8, Quelques caractéristiques.
La version actuelle est déjà assez complète, incluant une capacité de trading quasi universelle sur l'ensemble du marché, une estimation des tendances haute fréquence du carnet d'ordres et des tâches de trading pour réaliser des avantages en combinant Maker et Taker en haute fréquence, une protection de queue par couverture unidirectionnelle validée par des probabilités à long terme, un enregistrement local extrêmement détaillé de chaque ordre pouvant fonctionner en couverture mixte avec d'autres stratégies, etc., sans en dire plus.
IV, Quelques performances historiques (statistiques par tranches de minutes, coût de 0,05% en prenant les ordres après estimation des prix réels)
【Neutral Hedging Statistical Arbitrage New】- Supernova
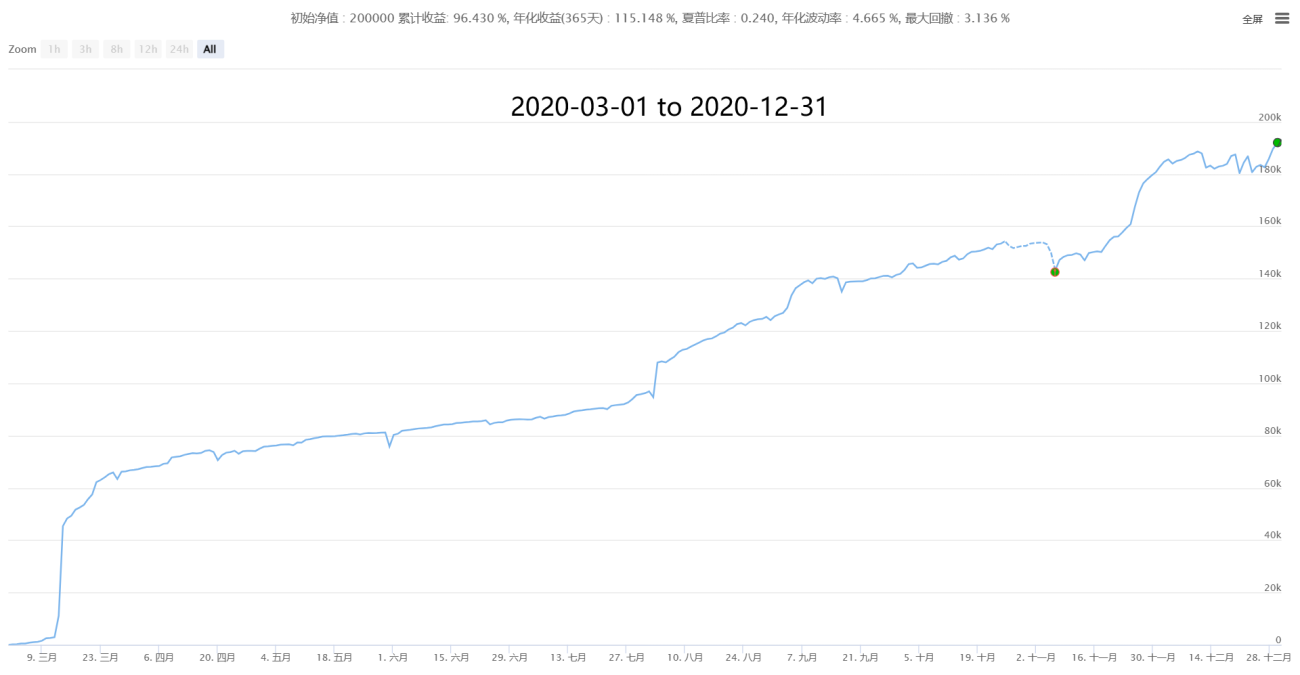
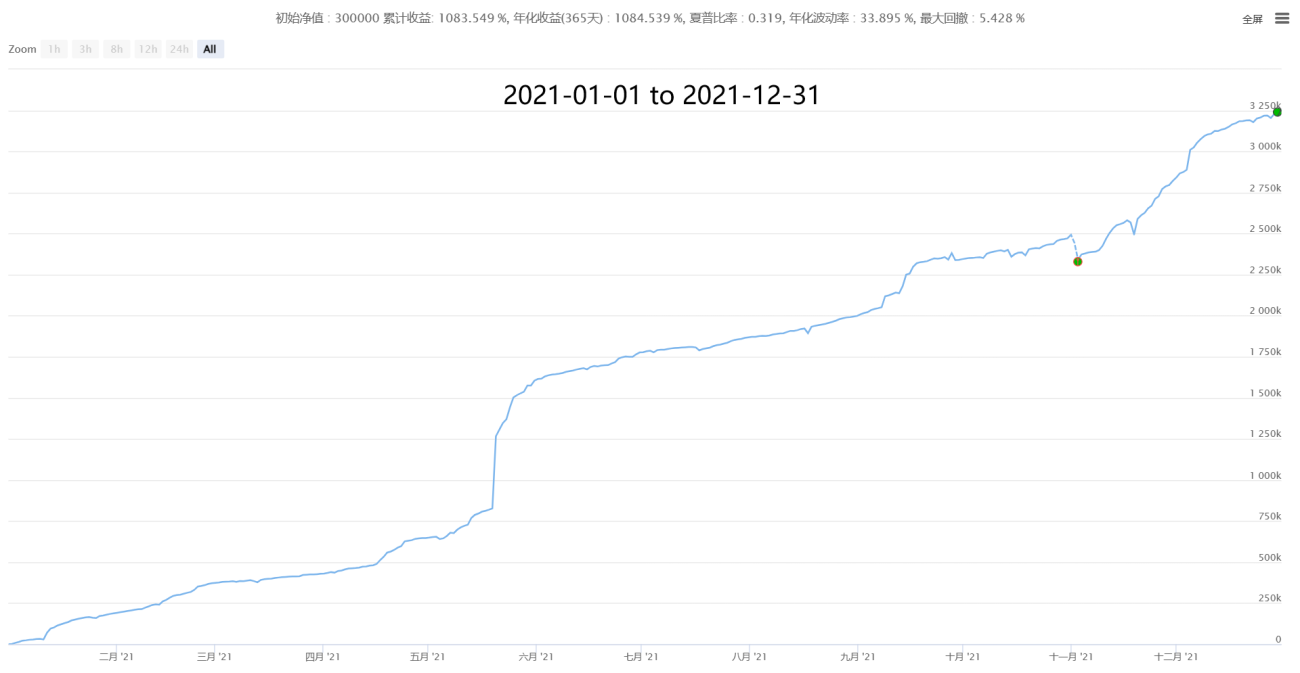
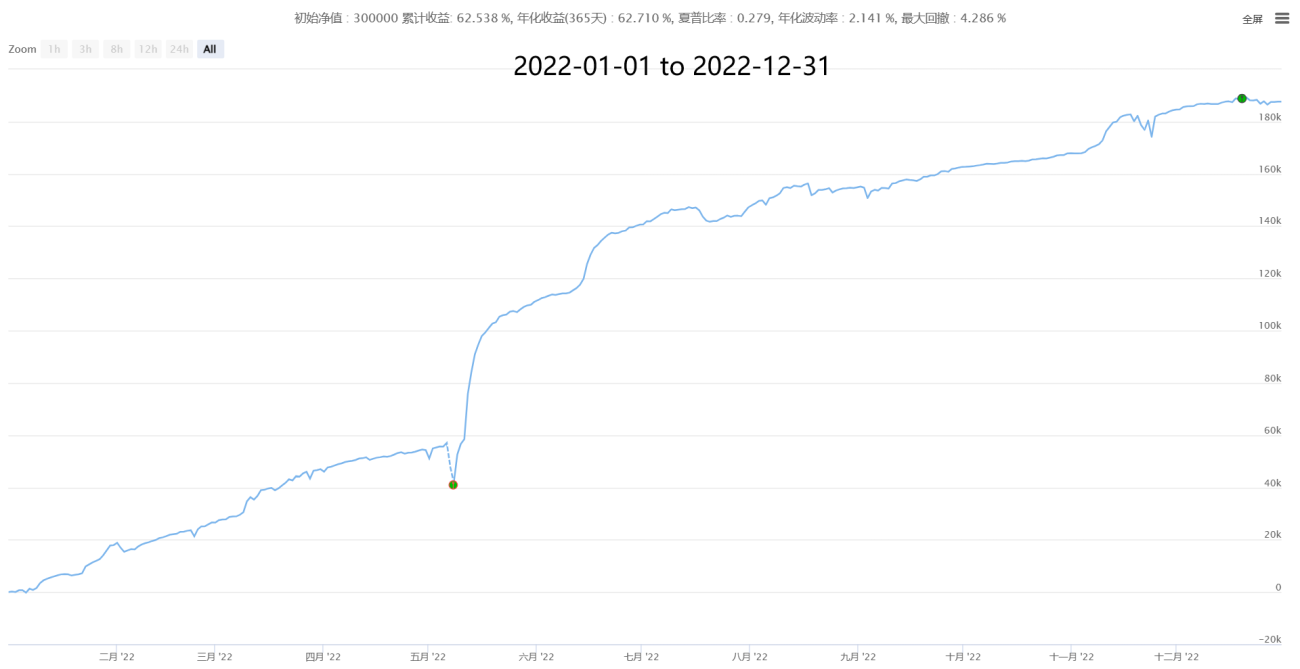
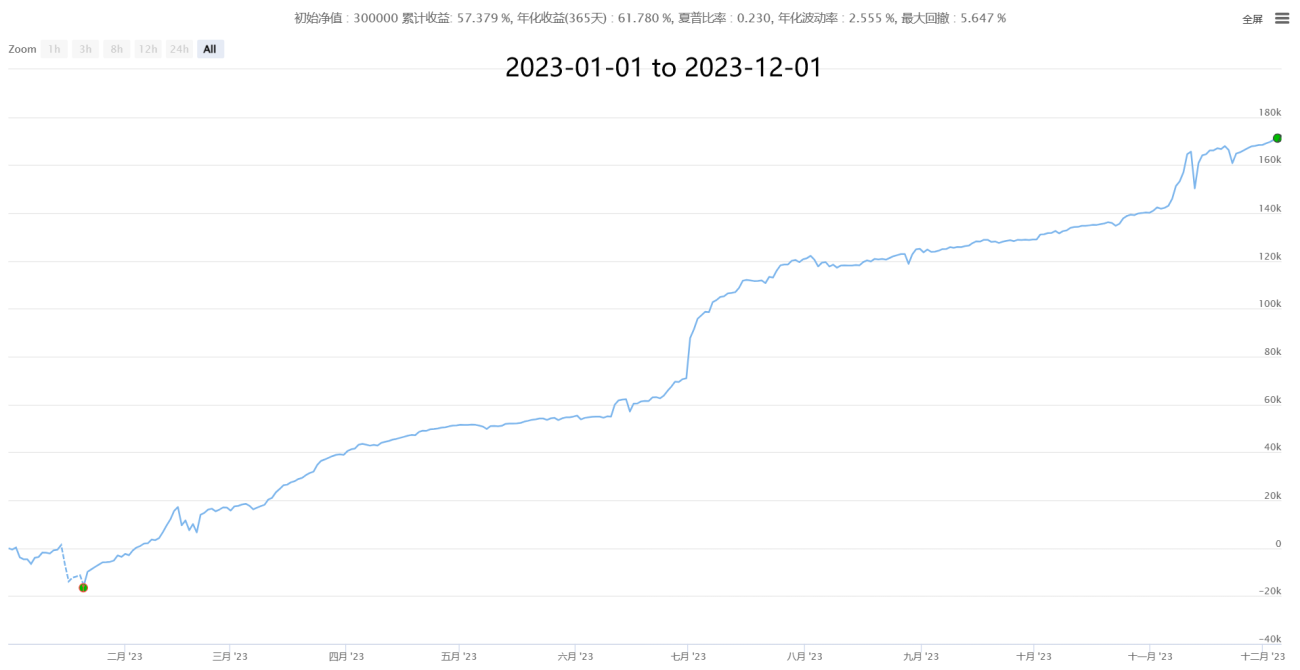
V, En attente de collaboration et d'échanges, apprendre et progresser ensemble
【Neutral Hedging Statistical Arbitrage New】- Supernova
Données tierces de Coin
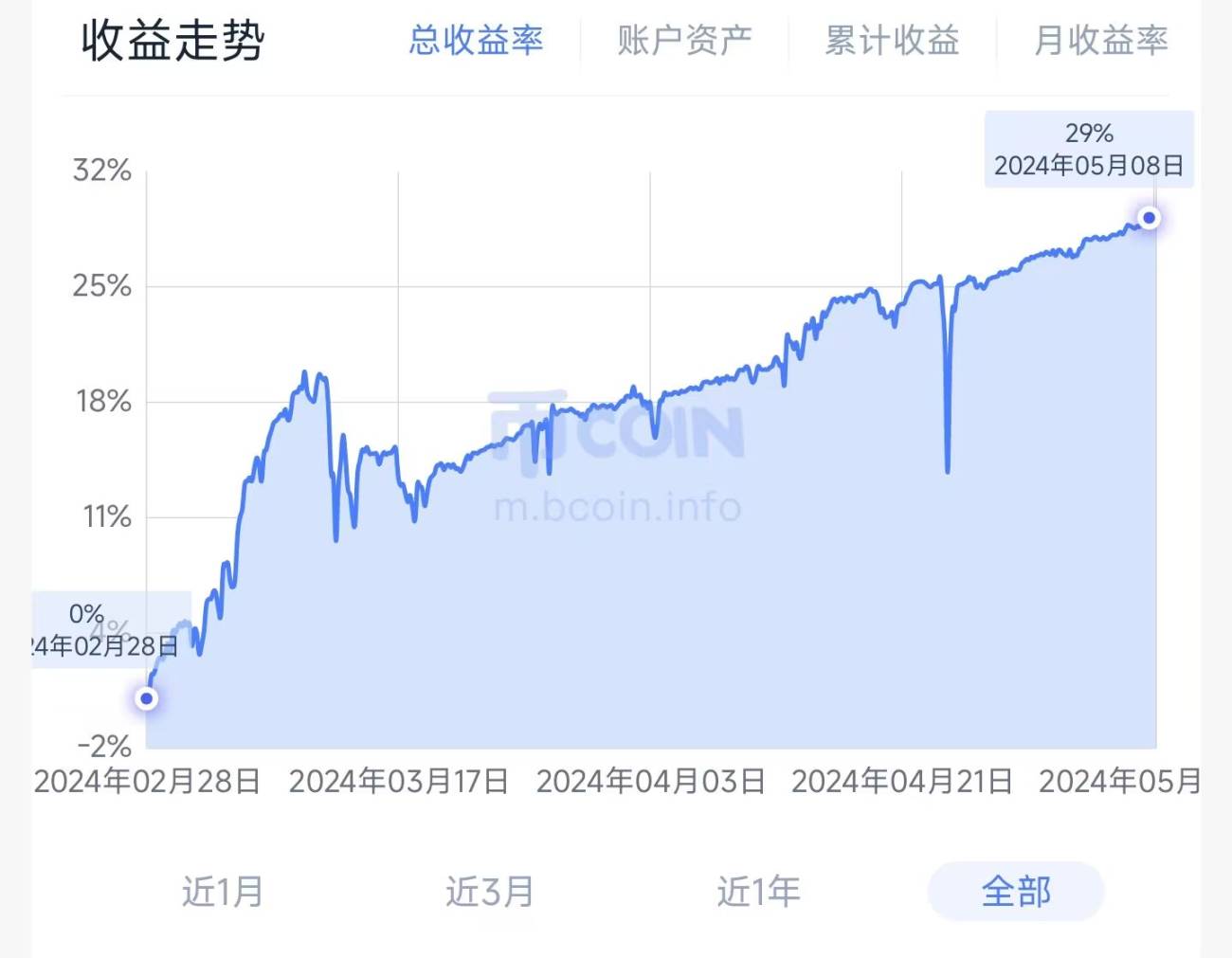
Chaque stratégie a sa propre méthodologie et des conditions de marché auxquelles elle s'adapte ou non. Par exemple, les stratégies de retour à la moyenne reposent sur la théorie de la marche aléatoire des marchés, tandis que les stratégies de momentum et de tendance s'appuient sur diverses théories de la finance comportementale et des marchés présentant des fluctuations à queue épaisse. Il est essentiel d'en comprendre les principes, d'en maîtriser les caractéristiques et de s'adapter à leurs volatilités. En même temps, l'utilisateur de la stratégie doit garder à l'esprit que les gains et les pertes sont liés : des rendements plus élevés s'accompagnent nécessairement de risques plus élevés. Une stratégie mature a ses avantages et ses inconvénients ; il faut l'utiliser de manière raisonnable, en maximisant ses forces et en minimisant ses faiblesses, en connaissant ses performances complètes dans les conditions de marché favorables ou défavorables, afin d'être confiant et imperturbable.
Le trading quantitatif n'est pas une machine à mouvement perpétuel, ni une panacée, mais il est certainement l'avenir du trading, et mérite que chaque trader l'apprenne et l'utilise ! Bienvenue à tous les traders pour signaler les lacunes, discuter ensemble, apprendre et progresser ensemble, pour naviguer avec succès dans les marchés tumultueux et avancer avec détermination.
● Cette stratégie a des caractéristiques spécifiques, très différentes des stratégies traditionnelles de grille, de tendance, de haute fréquence, d'arbitrage, etc. Sa capacité est limitée, principalement utilisée pour le trading propre. Bienvenue aux grands utilisateurs et investisseurs institutionnels pour échanger et apprendre.
● Plus de solutions de collaboration : Nous adoptons une attitude de collaboration ouverte et gagnant-gagnant envers toute personne ou institution ayant des besoins. Nous attendons avec impatience vos discussions pour une collaboration personnalisée selon vos besoins, votre appétit pour le risque, etc.
Si vous avez un appétit pour le risque élevé, que vous aimez les gains à court terme et avez besoin de trading à court terme, vous pouvez consulter une autre stratégie de haute fréquence stable avec un rendement mensuel de 3% à 50%, sans risque de liquidation :
【High Frequency Hedging Market Making Grid New】(HFT Market-Making version Miner)
Si vous disposez d'un capital important, vous pouvez également observer un autre système de trading CTA composite à moyenne/basse fréquence et grande capacité, qui a été utilisé en trading réel pendant 1000 jours sans interruption. C'est le système de combinaison de stratégies CTA le plus long, le plus stable et le plus largement applicable jamais publié, visant à une croissance stable à long terme :
【Composite CTA Trading System New】(Version publique multi-facteurs + multi-instruments + multi-stratégies)
✱ Coordonnées (Bienvenue pour échanger, discuter et apprendre ensemble)
WECHAT : haiyanyydss
Telegram : https://t.me/JadeRabbitcm
Plus de contenu → Le petit coin quantitatif de l'auteur https://www.fmz.com/market-offer/512
✱ Système de trading entièrement automatique CTA & HFT & Arbitrage @2018 - 2024
- 1