

परिपक्व वर्गीकारक: सपोर्ट वेक्टर मशीन (SVM) एक शक्तिशाली और परिपक्व बाइनरी (या बहुभिन्नरूपी) वर्गीकरण एल्गोरिथम है। यह अनुमान लगाना कि शेयर में वृद्धि होगी या गिरावट, एक विशिष्ट बाइनरी वर्गीकरण समस्या है।
अरैखिक क्षमता: कर्नेल फ़ंक्शन (जैसे आरबीएफ कर्नेल) का उपयोग करके, एसवीएम इनपुट सुविधाओं के बीच जटिल अरैखिक संबंधों को पकड़ सकता है, जो वित्तीय बाजार डेटा के लिए महत्वपूर्ण है।
फ़ीचर-संचालित: मॉडल की प्रभावशीलता काफी हद तक आपके द्वारा उसमें डाली गई "फ़ीचर्स" पर निर्भर करती है। अभी गणना किया गया अल्फ़ा फ़ैक्टर एक अच्छी शुरुआत है, और हम पूर्वानुमान क्षमता को बेहतर बनाने के लिए ऐसे और फ़ीचर्स बना सकते हैं।
इस बार मैंने 3 फीचर रूपरेखाओं के साथ शुरुआत की:
1: उच्च आवृत्ति आदेश प्रवाह विशेषताएँ:
alpha_1min: पिछले मिनट में सभी टिक्स के आधार पर गणना की गई ऑर्डर प्रवाह असंतुलन कारक।
alpha_5min: पिछले 5 मिनट में सभी टिक्स के आधार पर ऑर्डर प्रवाह असंतुलन कारक की गणना की जाती है।
alpha_15min: पिछले 15 मिनट में सभी टिक्स के आधार पर ऑर्डर प्रवाह असंतुलन कारक की गणना की जाती है।
ofi_1min (ऑर्डर फ़्लो असंतुलन): 1 मिनट की अवधि में (खरीद मात्रा / बिक्री मात्रा) का अनुपात। यह अल्फ़ा से ज़्यादा प्रत्यक्ष है।
vol_per_trade_1min: 1 मिनट के भीतर प्रति ट्रेड औसत वॉल्यूम। बाज़ार पर बड़े ऑर्डर के प्रभाव का संकेत।
2: मूल्य और अस्थिरता विशेषताएँ:
log_return_5min: पिछले 5 मिनट में लघुगणकीय वापसी दर, log(P_t / P_{t-5min}).
अस्थिरता_15 मिनट: पिछले 15 मिनट के लॉग रिटर्न का मानक विचलन, अल्पकालिक अस्थिरता का एक माप।
atr_14 (औसत ट्रू रेंज): पिछले 14 1-मिनट कैंडलस्टिक्स पर आधारित एटीआर मूल्य, एक क्लासिक अस्थिरता संकेतक।
rsi_14 (सापेक्ष शक्ति सूचकांक): यह पिछले 14 1-मिनट कैंडलस्टिक्स के आरएसआई मूल्यों के आधार पर ओवरबॉट और ओवरसोल्ड स्थितियों का एक उपाय है।
3: समय विशेषताएँ:
दिन का घंटा: वर्तमान घंटा (0-23)। बाज़ार अलग-अलग समयावधियों (जैसे, एशियाई/यूरोपीय/अमेरिकी सत्र) में अलग-अलग व्यवहार करते हैं।
day_of_week: सप्ताह का दिन (0-6)। सप्ताहांत और कार्यदिवसों में उतार-चढ़ाव के अलग-अलग पैटर्न होते हैं।
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
फिर तीन श्रेणियों का उपयोग करके बढ़ते, गिरते और बग़ल में अंतर करें।
फीचर स्क्रीनिंग का मुख्य विचार: "अच्छे साथियों" को खोजें और "बुरे साथियों" को हटाएँ
हमारा लक्ष्य ऐसी विशेषताओं का एक समूह खोजना है जो:
- उच्च प्रासंगिकता: प्रत्येक विशेषता का भविष्य के मूल्य परिवर्तनों (हमारा लक्ष्य लेबल) के साथ मजबूत संबंध है।
- कम अतिरेक: फ़ीचर में बहुत ज़्यादा दोहराई गई जानकारी नहीं होनी चाहिए। उदाहरण के लिए, "5-मिनट की गति" और "6-मिनट की गति" बहुत समान हैं। दोनों को शामिल करने से मॉडल में ज़्यादा सुधार नहीं होगा और शोर भी हो सकता है।
- स्थिरता: किसी सुविधा की वैधता समय के साथ बहुत तेज़ी से नहीं बदल सकती। जो सुविधा केवल एक ही दिन के लिए वैध हो, वह खतरनाक होती है।
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
प्रक्रिया इस प्रकार है:
डेटा एकत्र करना
विशेषता का महत्व

सुविधाओं और लेबलों के बीच पारस्परिक जानकारी और बैकटेस्ट जानकारी
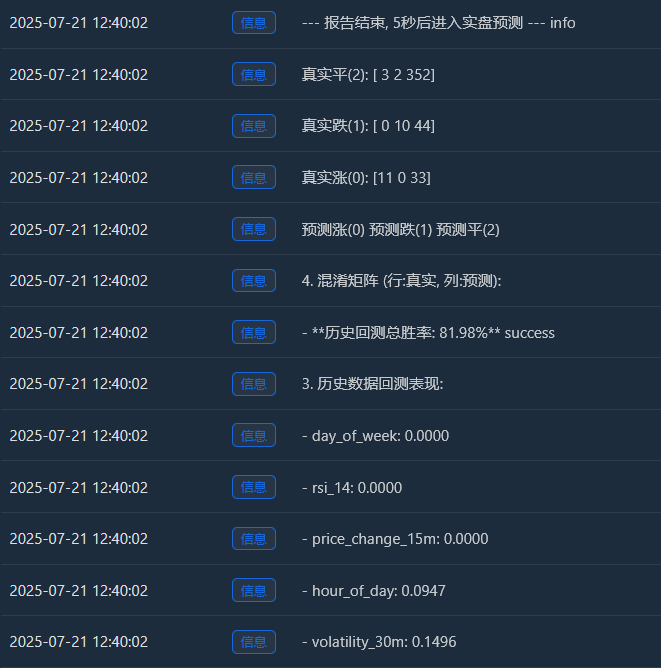
मैंने शुरू में सोचा था कि 65% जीत दर काफ़ी होगी, लेकिन मुझे उम्मीद नहीं थी कि यह 81.98% तक पहुँच जाएगी। मेरी पहली प्रतिक्रिया होनी चाहिए: "यह बहुत बढ़िया है, लेकिन यह सच होने के लिए बहुत अच्छा है। इसमें ज़रूर कुछ ऐसा होगा जिसकी खोज की जानी चाहिए।"
1विश्लेषण रिपोर्ट की गहन व्याख्या, रिपोर्ट की सामग्री की एक-एक करके व्याख्या:
- विशेषता महत्व एवं पारस्परिक जानकारी:
अस्थिरता_30m और मूल्य_परिवर्तन_15m सबसे महत्वपूर्ण विशेषताएँ हैं। यह तार्किक है, यह दर्शाता है कि हालिया बाज़ार रुझान और अस्थिरता भविष्य के सबसे मज़बूत भविष्यवक्ता हैं।
दिन का घंटा भी इसमें कुछ योगदान देता है, जो यह दर्शाता है कि मॉडल दिन के अलग-अलग समय पर ट्रेडिंग पैटर्न को पकड़ता है।
rsi_14 और day_of_week का योगदान लगभग शून्य है, जिससे पता चलता है कि ये दोनों फ़ीचर मौजूदा डेटासेट और फ़ीचर संयोजन के तहत "पिग टीममेट्स" हो सकते हैं। मॉडल को सरल बनाने और शोर को रोकने के लिए हम भविष्य में इन्हें हटाने पर विचार कर सकते हैं। - भ्रम मैट्रिक्स (यह बहुत सारी जानकारी है!)
वास्तविक वृद्धि (0):[11 0 33] -> 44 (11+0+33) वास्तविक रैलियों में से, मॉडल ने 11 की सही भविष्यवाणी की, लेकिन 33 बार इसे "समेकन" के रूप में गलत भविष्यवाणी की।
वास्तविक गिरावट (1):[0 10 44] -> 54 (0+10+44) वास्तविक गिरावटों में से, मॉडल ने 10 की सही भविष्यवाणी की, लेकिन 44 बार इसे "साइडवेज ट्रेंड" के रूप में गलत भविष्यवाणी की।
वास्तविक पिंग (2):[3 2 352] -> 357 (3+2+352) वास्तविक समेकनों में से, मॉडल ने उनमें से 352 की सही भविष्यवाणी की! - ऐतिहासिक बैकटेस्ट कुल जीत दर: 81.98%
इस उच्च जीत दर का मुख्य स्रोत "समेकन" की भविष्यवाणी करने में मॉडल की अत्यधिक उच्च सटीकता है! लगभग 455 नमूनों में से, 350 से ज़्यादा समेकन बाज़ार थे, और मॉडल ने उन्हें लगभग पूरी तरह से पहचान लिया।
यह अपने आप में एक बहुत ही मूल्यवान क्षमता है! एक ऐसा मॉडल जो आपको सटीक रूप से बता सके कि "अभी आगे बढ़ना बेहतर नहीं है", आपको बहुत सारे शुल्क और अमान्य लेनदेन से बचाने में मदद कर सकता है।
2वास्तविक जीत दर 81.98% से कम क्यों हो सकती है?
- "समेकन" की परिभाषा बहुत ढीली है: हमारा SPREAD_THRESHOLD 0.5% है। 15 मिनट की अवधि में 0.5% से ज़्यादा मूल्य में उतार-चढ़ाव होना आम बात है। नतीजतन, "समेकन" नमूने हमारे डेटासेट के विशाल बहुमत (लगभग 80%) के लिए ज़िम्मेदार हैं। मॉडल ने बड़ी चतुराई से सीखा है, "जब मुझे यकीन न हो, तो उच्च सटीकता के साथ 'समेकन' का अनुमान लगाएँ।" यह सांख्यिकीय रूप से सही है, लेकिन ट्रेडिंग में, हम मूल्य आंदोलनों की भविष्यवाणी करने में ज़्यादा रुचि रखते हैं।
- वृद्धि और गिरावट की भविष्यवाणी करने की क्षमता:
अपट्रेंड की भविष्यवाणी करने में जीत की दर: मॉडल ने 11 + 0 + 3 = 14 अपट्रेंड की भविष्यवाणी की, जिनमें से केवल 11 ही सही थे। जीत की दर 11/14 = 78.5% है। बहुत बढ़िया!
गिरावट की भविष्यवाणी करने में जीत की दर: मॉडल ने 0 + 10 + 2 = 12 गिरावट की भविष्यवाणी की, और उनमें से 10 सही साबित हुईं। जीत की दर 10/12 = 83.3% है। फिर से, बहुत प्रभावशाली! - इन-सैंपल ओवरफिटिंग: यह परीक्षण मॉडल के लिए "ज्ञात" डेटा (अर्थात, प्रशिक्षण और परीक्षण के लिए प्रयुक्त डेटा) पर किया जाता है। यह किसी छात्र से अभी-अभी पूरा किया गया कोई परीक्षण करने के लिए कहने जैसा है; स्कोर आमतौर पर उच्च होगा। नए, अनदेखे डेटा (लाइव ट्रेडिंग) पर मॉडल का प्रदर्शन लगभग हमेशा इस स्कोर से कम होगा।
अब हमारे पास एक प्रारंभिक, फिर भी संभावित रूप से विशाल, "अल्फ़ा मॉडल" है। हालाँकि हम 81.98% के आँकड़ों को भविष्य के लिए एक यथार्थवादी भविष्यवाणी के रूप में सीधे तौर पर नहीं समझ सकते, फिर भी यह एक मज़बूत सकारात्मक संकेत है, जो दर्शाता है कि आँकड़ों में पूर्वानुमान योग्य पैटर्न मौजूद हैं, और हमारे ढाँचे ने उन्हें सफलतापूर्वक पकड़ लिया है!
अब हमें ऐसा लग रहा है जैसे हमें पहाड़ की तलहटी में उच्च-गुणवत्ता वाले सोने के अयस्क का पहला टुकड़ा मिल गया हो। हमारा अगला कदम इसे तुरंत बेचना नहीं है, बल्कि पूरे पहाड़ का अधिक कुशलतापूर्वक और स्थिर खनन करने के लिए अधिक विशिष्ट उपकरणों और तकनीकों (विशेषताओं का अनुकूलन और मापदंडों का समायोजन) का उपयोग करना है।
अब आइए युद्ध के कोहरे को “सूक्ष्म जगत” में पेश करें - ऑर्डर प्रवाह और ऑर्डर बुक विशेषताएँ
चरण 1: डेटा संग्रहण को उन्नत करें - गहन चैनलों की सदस्यता लें
ऑर्डर बुक डेटा प्राप्त करने के लिए, WebSocket कनेक्शन विधि को केवल aggTrade (सौदों) की सदस्यता लेने से aggTrade और depth दोनों की सदस्यता लेने में संशोधित किया जाना चाहिए।
इसके लिए हमें अधिक सामान्य मल्टी-स्ट्रीम सदस्यता URL का उपयोग करना होगा।
चरण 2: फ़ीचर इंजीनियरिंग को उन्नत करें - "समुद्र, भूमि और वायु" के लिए एक त्रिमूर्ति फ़ीचर मैट्रिक्स बनाएँ
हम calculate_features_and_labels फ़ंक्शन में निम्नलिखित नई सुविधाएँ जोड़ेंगे:
- ऑर्डर फ्लो विशेषताएँ (अल्फा - लघु):
alpha_15m: 15 मिनट का ऑर्डर फ़्लो असंतुलन कारक। यह मुख्य ऑर्डर फ़्लो मीट्रिक है जिसकी हमने पहले चर्चा की थी। - ऑर्डर बुक विशेषताएँ (पुस्तक - सेना):
wobi_10s: पिछले 10 सेकंड में भारित ऑर्डर बुक असंतुलन। यह एक बहुत ही उच्च-आवृत्ति संकेतक है जो बाज़ार पर खरीद और बिक्री के दबाव को मापता है।
spread_10s: पिछले 10 सेकंड का औसत बोली-माँग का अंतर। अल्पकालिक तरलता दर्शाता है। - मूल विशेषताएँ (कीमत - नौसेना):
हम पिछले संस्करण की सर्वश्रेष्ठ प्रदर्शन करने वाली विशेषताओं को बरकरार रखेंगे और उन्हें अनुकूलित करेंगे।
यह नया फीचर मैट्रिक्स एक संयुक्त लड़ाकू कमान की तरह है, जो एक साथ "समुद्र (मूल्य प्रवृत्ति)", "भूमि (बाजार की स्थिति)" और "वायु (लेनदेन प्रभाव)" से वास्तविक समय की खुफिया जानकारी प्राप्त करता है, और इसकी निर्णय लेने की क्षमता पहले से कहीं अधिक बेहतर होगी।
कोड इस प्रकार है:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
इस कोड के लिए बहुत सारी K-लाइन गणनाओं की आवश्यकता होती है
यह रिपोर्ट बहुत मूल्यवान है, क्योंकि यह हमें मॉडल के "विचार" और "चरित्र" के बारे में बताती है।
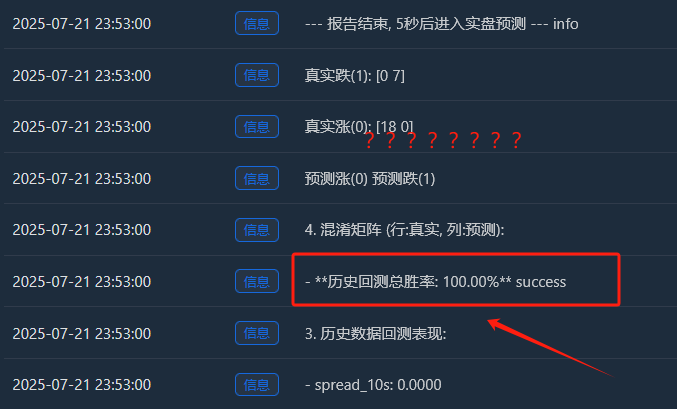
- ऐतिहासिक बैकटेस्टिंग कुल जीत दर: 93.33%
यह एक बेहद प्रभावशाली संख्या है! हालाँकि हमें इसे वस्तुनिष्ठ रूप से देखने की ज़रूरत है (यह एक इन-सैंपल परीक्षण है), यह हमारे नए जोड़े गए ऑर्डर फ़्लो और ऑर्डर बुक फ़ीचर्स की अपार भविष्यसूचक क्षमता को स्पष्ट रूप से दर्शाता है! मॉडल ने ऐतिहासिक डेटा में बहुत मज़बूत पैटर्न खोजे हैं। - विशेषता महत्व और पारस्परिक जानकारी
राजा का जन्म हुआ: volatility_15m (अस्थिरता) और price_change_5m (मूल्य परिवर्तन) अभी भी पूरी तरह से कोर हैं, जो कि उम्मीद के मुताबिक है।
राइजिंग स्टार: rsi_14 की महत्ता में उल्लेखनीय वृद्धि हुई है! यह दर्शाता है कि 5 मिनट की छोटी समयावधि में, RSI का "ओवरबॉट/ओवरसोल्ड" सेंटीमेंट इंडिकेटर ज़्यादा सार्थक हो गया है।
संभावित रूप से, wobi_10s (ऑर्डर बुक असंतुलन) और spread_10s (स्प्रेड) भी कुछ योगदान दिखाते हैं। यह बहुत उत्साहजनक है और यह दर्शाता है कि हमारी सूक्ष्म संरचना विशेषताएँ काम करना शुरू कर रही हैं!
प्रतिबिंब: अल्फा_5m (ऑर्डर फ्लो) का योगदान लगभग शून्य है। यह हमारी अल्फा गणना पद्धति के अति-सरलीकरण के कारण हो सकता है, या 5-मिनट के अल्फा और 5-मिनट के मूल्य परिवर्तनों में स्वयं बहुत अधिक ओवरलैपिंग जानकारी हो सकती है। यह भविष्य में हमारे लिए एक महत्वपूर्ण अनुकूलन बिंदु है। - भ्रम मैट्रिक्स (सफलता का प्रमुख प्रमाण!)
वास्तविक वृद्धि (0):[22 0] -> सभी 22 वास्तविक रैलियों में, मॉडल ने बिना किसी गलती के 100% सही भविष्यवाणी की!
वास्तविक गिरावट (1):[2 6] -> 8 वास्तविक गिरावटों में से, मॉडल ने 6 का सही अनुमान लगाया और 2 को गलत बताया (उन्हें वृद्धि समझकर)।
व्याख्या: यह मॉडल एक बहुत ही दिलचस्प विशेषता प्रदर्शित करता है: यह एक अत्यंत शक्तिशाली तेजी डिटेक्टर है, जो तेजी के संकेतों को लगभग पूरी तरह से पकड़ लेता है। यह मंदी के रुझानों की पहचान करने में भी अच्छा प्रदर्शन करता है (6/8 = 75% सटीकता), लेकिन कभी-कभी मंदी के रुझान को तेजी का रुझान समझने की गलती भी कर देता है।
फिर आगे क्या होगा?
"ट्रेडिंग सिग्नल स्टेट मशीन" का परिचय
यह इस अपग्रेड का मुख्य और सबसे चतुर हिस्सा है। हम रणनीति की वर्तमान "पोज़िशन" स्थिति को प्रबंधित करने के लिए एक वैश्विक स्टेट वैरिएबल, जैसे g_active_signal, पेश करेंगे (ध्यान दें कि यह केवल एक वर्चुअल पोज़िशन स्थिति है और इसमें वास्तविक ट्रेडिंग शामिल नहीं है)।
इस स्टेट मशीन का कार्य तर्क इस प्रकार है:
- प्रारंभिक अवस्था: निष्क्रिय
- जब रणनीति इस अवस्था में होगी, तो यह प्रत्येक नई K-लाइन के लिए पूर्वानुमान लगाएगी, जैसा कि यह अभी करती है।
- व्यवस्था परिवर्तन: एक बार जब मॉडल एक स्पष्ट संकेत (जैसे, "ऊपर") की भविष्यवाणी करता है, तो रणनीति:
- जर्नल में एक एकल, आकर्षक प्रवेश संकेत प्रिंट करता है, उदाहरण के लिए, 🎯 नया ट्रेडिंग संकेत: पूर्वानुमान ऊपर! अवलोकन अवधि 15 मिनट।
- रणनीति की स्थिति को निष्क्रिय से इन-सिग्नल में बदलता है।
वर्तमान सिग्नल का ट्रिगर समय और दिशा रिकॉर्ड करें।
- स्थिति स्थिति: इन-सिग्नल
- जब रणनीति इस अवस्था में होती है, तो यह नई K रेखाओं की भविष्यवाणी करना पूरी तरह से बंद कर देती है। यह अब हर मिनट के उतार-चढ़ाव की परवाह नहीं करती और "गोली को उड़ने दो" मोड में प्रवेश कर जाती है।
- यह केवल समय की जांच करता है: क्या सिग्नल ट्रिगर होने के बाद से 15 मिनट (PREDICT_HORIZON की लंबाई) बीत चुके हैं।
- राज्य परिवर्तन: 15 मिनट की अवलोकन अवधि के बाद, नीति:
- लॉग में एक स्पष्ट निकास संकेत प्रिंट करें, जैसे कि 🏁 सिग्नल अवधि का अंत। रणनीति रीसेट करें और नए अवसरों की तलाश करें...
- रणनीति की स्थिति को होल्ड से निष्क्रिय में बदलता है।
- इस बिंदु पर, रणनीति फिर से नई K-लाइन की भविष्यवाणी करना शुरू कर देगी और अगले ट्रेडिंग अवसर की तलाश करेगी।
इस सरल स्टेट मशीन के साथ, हमने आवश्यकताओं को पूरी तरह से पूरा कर लिया है: एक संकेत, एक पूर्ण अवलोकन चक्र, और इस अवधि के दौरान कोई हस्तक्षेप जानकारी नहीं।
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
फिर मैं यह कोड चलाता हूँ
गहन विश्लेषण: 100% जीत की दर “पूर्ण” क्यों होती है?
यह "परफेक्ट" परिणाम मशीन लर्निंग और वित्तीय बाज़ारों के बारे में कई महत्वपूर्ण और गहन जानकारियाँ उजागर करता है। यह कोई बग नहीं है, बल्कि एक विशिष्ट घटना है जिसे "ओवरफिटिंग" कहा जाता है, जो कुछ परिस्थितियों में हो सकती है।
"ओवरफिटिंग" का क्या अर्थ है?
-
यहाँ एक ज्वलंत उदाहरण है: कल्पना कीजिए कि हमारा एक छात्र (हमारा SVM मॉडल) बहुत ही छोटे, बहुत ही सरल अभ्यासों (हमारे द्वारा एकत्रित 200 कैंडलस्टिक डेटा पॉइंट्स) का एक सेट करता है। यह छात्र बहुत होशियार है, और सामान्य समस्या-समाधान विधियों को सीखने के बजाय, वह बस इन कुछ समस्याओं के उत्तर रट लेता है।
-
परिणाम: जब हम उसे अभ्यास प्रश्नों के उसी सेट के साथ परीक्षण करते हैं (यह हमारा "ऐतिहासिक बैकटेस्ट" है), तो वह निश्चित रूप से 100 का पूर्ण स्कोर प्राप्त कर सकता है। हालांकि, जब हम उसे प्रश्नों का एक बिल्कुल नया सेट देते हैं जिसे उसने पहले कभी नहीं देखा है (वास्तविक भविष्य के बाजार), तो वह उनमें से किसी का भी उत्तर देने में असमर्थ हो सकता है।
- हमारा मॉडल "ओवरफिट" क्यों है?
-
प्रशिक्षण नमूने "बहुत कम" और "बहुत विशेष" हैं:
-
यद्यपि हमने 200 K-लाइनें (लगभग 3.3 घंटे) एकत्रित कीं, लॉग के अनुसार, हमारी परिभाषा को पूरा करने वाले "प्रभावी वृद्धि और गिरावट" नमूनों की अंतिम संख्या केवल 18 + 7 = 25 थी।
-
एक जटिल एसवीएम मॉडल के लिए, 25 नमूने समुद्र में कुछ लहरों के समान हैं, जो बहुत छोटा है।
-
इससे भी महत्वपूर्ण बात यह है कि ये सभी 25 नमूने एक ही दोपहर में एक ही तरह की बाज़ार स्थिति से लिए गए हैं। इनकी "दिनचर्या" बहुत समान होने की संभावना है।
- मॉडल की क्षमताएं “बहुत मजबूत” हैं:
- एसवीएम एक बहुत ही शक्तिशाली, अरैखिक वर्गीकारक है। इसकी क्षमता सुपर मेमोरी वाले मस्तिष्क जैसी है।
- जब एक शक्तिशाली मॉडल किसी ऐसे डेटासेट से सीखता है जो बहुत सरल और दोहराव वाला होता है, तो वह डेटा के पीछे के अधिक सार्वभौमिक मैक्रो नियमों को सीखने के बजाय, डेटा के सभी विवरणों और शोर को "याद" करने लगता है।
- भ्रम मैट्रिक्स से साक्ष्य:
- वास्तविक वृद्धि (0):[18 0] -> 18 बढ़ते नमूने, सभी पूरी तरह से याद किए गए।
- वास्तविक गिरावट (1):[0 7] -> 7 गिरते नमूने, सभी पूरी तरह से याद हैं।
- यह उत्तम[ [18, 0], [[0, 7] मैट्रिक्स मॉडल के ओवरफिटिंग का अकाट्य प्रमाण है। यह लगभग कोई गलती नहीं करता, जो कि यादृच्छिकता से भरे वित्तीय बाज़ार में स्वाभाविक रूप से असामान्य है।
इसलिए, हमें इस 100% जीत दर की व्याख्या इस प्रकार करनी चाहिए:
"पिछले तीन घंटों में मॉडल ने विशिष्ट बाज़ार स्थितियों के सभी पैटर्न को उल्लेखनीय रूप से सीखा और याद किया है। यह हमारी फ़ीचर इंजीनियरिंग और मॉडल फ्रेमवर्क की प्रभावशीलता को दर्शाता है। हालाँकि, हम भविष्य में वास्तविक बाज़ार में इससे इतनी उच्च जीत दर बनाए रखने की उम्मीद बिल्कुल नहीं कर सकते। यह 'कॉलेज प्रवेश परीक्षा' के अंतिम परिणाम से कहीं ज़्यादा एक आदर्श 'पॉप क्विज़' जैसा है।"

मशीन लर्निंग भी एक ऐसी चीज है जिस पर मैं हाल ही में खोज कर रहा हूं, हम अगले अंक में इसके बारे में बात करेंगे!
हमें इस "पक्षपाती छात्र" पर गहन "विचार परिवर्तन" करने की ज़रूरत है। हमारा लक्ष्य उसके पूर्वाग्रहों को तोड़ना और उसे "उतार-चढ़ाव" को निष्पक्ष और वस्तुनिष्ठ रूप से देखने की अनुमति देना है।
