

Klasifikasi matang: Support Vector Machine (SVM) adalah algoritma klasifikasi biner (atau multivariat) yang andal dan matang. Memprediksi apakah saham akan naik atau turun merupakan masalah klasifikasi biner yang umum.
Kemampuan nonlinier: Dengan menggunakan fungsi kernel (seperti kernel RBF), SVM dapat menangkap hubungan nonlinier yang kompleks antara fitur masukan, yang sangat penting untuk data pasar keuangan.
Berbasis fitur: Efektivitas model sangat bergantung pada "fitur" yang Anda masukkan. Faktor alfa yang dihitung sekarang merupakan langkah awal yang baik, dan kita dapat membangun lebih banyak fitur serupa untuk meningkatkan daya prediktif.
Kali ini saya mulai dengan 3 garis besar fitur:
1: Karakteristik aliran orde frekuensi tinggi:
alpha_1min: Faktor ketidakseimbangan aliran pesanan dihitung berdasarkan semua tanda centang dalam menit terakhir.
alpha_5min: Faktor ketidakseimbangan arus pesanan dihitung berdasarkan semua tanda centang dalam 5 menit terakhir.
alpha_15min: Faktor ketidakseimbangan arus pesanan dihitung berdasarkan semua tanda centang dalam 15 menit terakhir.
ofi_1min (Ketidakseimbangan Arus Pesanan): Rasio (volume beli / volume jual) dalam periode 1 menit. Ini lebih langsung daripada alpha.
vol_per_trade_1min: Rata-rata volume per perdagangan dalam 1 menit. Tanda-tanda order besar memengaruhi pasar.
2: Karakteristik harga dan volatilitas:
log_return_5min: Tingkat pengembalian logaritmik selama 5 menit terakhir, log(P_t / P_{t-5min}).
volatilitas_15min: Deviasi standar log pengembalian selama 15 menit terakhir, ukuran volatilitas jangka pendek.
atr_14 (Average True Range): Nilai ATR berdasarkan 14 candlestick 1 menit terakhir, indikator volatilitas klasik.
rsi_14 (Indeks Kekuatan Relatif): Ini adalah ukuran kondisi jenuh beli dan jenuh jual berdasarkan nilai RSI dari 14 candlestick 1 menit terakhir.
3: Karakteristik waktu:
hour_of_day: Jam saat ini (0-23). Pasar berperilaku berbeda dalam periode waktu yang berbeda (misalnya, sesi Asia/Eropa/Amerika).
day_of_week: Hari dalam seminggu (0-6). Akhir pekan dan hari kerja memiliki pola fluktuasi yang berbeda.
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
Kemudian gunakan tiga kategori untuk membedakan antara naik, turun, dan samping.
Ide inti dari penyaringan fitur: Temukan "rekan tim yang baik" dan singkirkan "rekan tim yang buruk"
Tujuan kami adalah menemukan serangkaian fitur yang:
- Relevansi Tinggi: Setiap fitur memiliki korelasi kuat dengan perubahan harga di masa mendatang (label target kami).
- Redundansi Rendah: Fitur tidak boleh mengandung terlalu banyak informasi duplikat. Misalnya, "momentum 5 menit" dan "momentum 6 menit" sangat mirip. Memasukkan keduanya tidak akan banyak meningkatkan model dan bahkan dapat menimbulkan noise.
- Stabilitas: Validitas suatu fitur tidak dapat berubah terlalu cepat seiring waktu. Fitur yang hanya valid satu hari saja berbahaya.
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
Prosesnya adalah:
Mengumpulkan data
Pentingnya Fitur

Informasi timbal balik antara fitur dan label serta informasi backtest
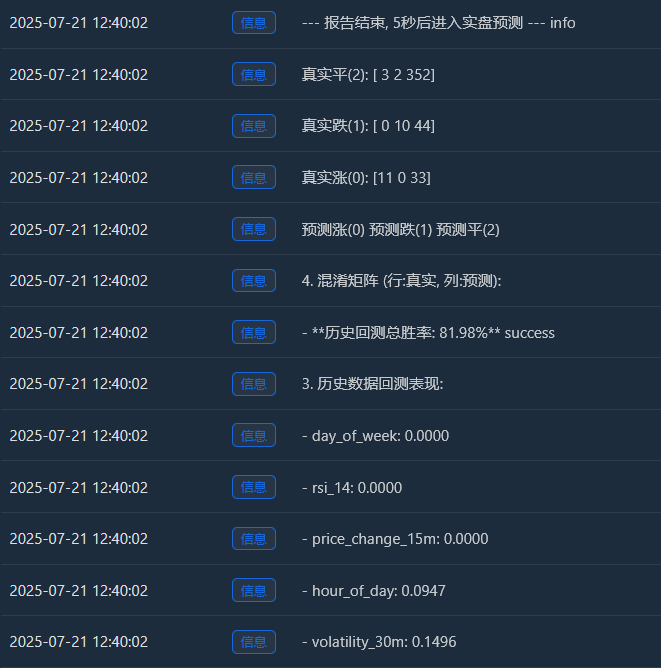
Awalnya saya pikir tingkat keberhasilan 65% sudah cukup, tapi saya tidak menyangka akan mencapai 81,98%. Reaksi pertama saya seharusnya: "Bagus, tapi terlalu bagus untuk menjadi kenyataan. Pasti ada sesuatu yang layak dieksplorasi di sini."
1Interpretasi mendalam atas laporan analisis, menafsirkan isi laporan satu per satu:
- Pentingnya Fitur & Informasi Saling:
Volatilitas_30 juta dan perubahan_harga_15 juta adalah fitur terpenting. Hal ini logis, menunjukkan bahwa tren pasar terkini dan volatilitas merupakan prediktor terkuat untuk masa depan.
Hour_of_day juga memberikan kontribusi sedikit, yang menunjukkan bahwa model tersebut menangkap pola perdagangan di waktu yang berbeda dalam sehari.
Kontribusi rsi_14 dan day_of_week hampir 0, yang menunjukkan bahwa kedua fitur ini mungkin merupakan "rekan satu tim" dalam kumpulan data dan kombinasi fitur saat ini. Kita dapat mempertimbangkan untuk menghapusnya di masa mendatang untuk menyederhanakan model dan mencegah gangguan. - Matriks Kebingungan (ini banyak sekali informasinya!)
Peningkatan riil (0):[11 0 33] -> Dari 44 (11+0+33) reli riil, model tersebut memprediksi 11 dengan tepat, namun salah memprediksi sebagai “konsolidasi” sebanyak 33 kali.
Penurunan nyata (1):[0 10 44] -> Dari 54 (0+10+44) penurunan riil, model tersebut memprediksi dengan tepat 10, tetapi salah memprediksinya sebagai "tren samping" sebanyak 44 kali.
Ping Nyata (2):[3 2 352] -> Dari 357 (3+2+352) konsolidasi nyata, model tersebut dengan tepat memprediksi 352 di antaranya! - Total tingkat kemenangan backtest historis: 81,98%
Sumber utama tingkat keberhasilan yang tinggi ini adalah akurasi model yang sangat tinggi dalam memprediksi "konsolidasi"! Di antara sekitar 455 sampel, lebih dari 350 merupakan pasar konsolidasi, dan model mengidentifikasinya dengan hampir sempurna.
Ini merupakan kemampuan yang sangat berharga! Model yang dapat secara akurat memberi tahu Anda "sebaiknya tidak pindah sekarang" dapat membantu Anda menghemat banyak biaya dan transaksi tidak valid.
2Mengapa tingkat kemenangan sesungguhnya mungkin lebih rendah dari 81,98%?
- Definisi "konsolidasi" terlalu longgar: SPREAD_THRESHOLD kami adalah 0,5%. Fluktuasi harga tidak lebih dari 0,5% dalam periode 15 menit cukup umum. Akibatnya, sampel "konsolidasi" mencakup sebagian besar (sekitar 80%) dari kumpulan data kami. Model ini dengan cerdik mempelajari, "Ketika saya tidak yakin, tebak 'konsolidasi' dengan akurasi tinggi." Ini benar secara statistik, tetapi dalam perdagangan, kita lebih fokus pada prediksi pergerakan harga.
- Kemampuan untuk memprediksi naik dan turun:
Tingkat keberhasilan prediksi tren naik: Model memprediksi 11 + 0 + 3 = 14 tren naik, dan hanya 11 yang benar. Tingkat keberhasilannya adalah 11 / 14 = 78,5%. Luar biasa!
Tingkat keberhasilan prediksi penurunan: Model memprediksi 0 + 10 + 2 = 12 penurunan, dan 10 di antaranya benar. Tingkat keberhasilannya adalah 10 / 12 = 83,3%. Sekali lagi, sangat mengesankan! - Overfitting dalam Sampel: Pengujian ini dilakukan pada data yang "diketahui" oleh model (yaitu, data yang digunakan untuk pelatihan dan pengujian). Hal ini seperti meminta siswa untuk mengerjakan tes yang baru saja mereka selesaikan; skornya biasanya akan tinggi. Performa model pada data baru yang belum pernah dilihat sebelumnya (perdagangan langsung) hampir selalu lebih rendah dari skor ini.
Kini kami memiliki "Model Alfa" awal, yang berpotensi sangat besar. Meskipun kami tidak dapat secara langsung menafsirkan angka 81,98% sebagai prediksi realistis untuk masa depan, ini merupakan sinyal positif yang kuat, menunjukkan bahwa pola yang dapat diprediksi memang ada dalam data, dan kerangka kerja kami telah berhasil menangkapnya!
Kini kami merasa seperti baru saja menemukan bijih emas berkualitas tinggi pertama di kaki gunung. Langkah kami selanjutnya bukanlah menjualnya langsung, melainkan menggunakan alat dan teknik yang lebih terspesialisasi (mengoptimalkan fitur dan menyesuaikan parameter) untuk menambang seluruh gunung secara lebih efisien dan stabil.
Sekarang mari kita perkenalkan kabut perang dalam “mikrokosmos” — aliran pesanan dan karakteristik buku pesanan
Langkah 1: Tingkatkan pengumpulan data - berlangganan saluran yang lebih dalam
Untuk memperoleh data buku pesanan, metode koneksi WebSocket harus dimodifikasi dari hanya berlangganan aggTrade (transaksi) menjadi berlangganan aggTrade dan depth (kedalaman).
Hal ini mengharuskan kami menggunakan URL langganan multi-aliran yang lebih umum.
Langkah 2: Tingkatkan rekayasa fitur - bangun matriks fitur trinitas untuk "laut, darat, dan udara"
Kami akan menambahkan fitur baru berikut ke fungsi calculate_features_and_labels:
- Karakteristik Aliran Pesanan (Alfa - Pendek):
alpha_15m: Faktor ketidakseimbangan arus pesanan 15 menit. Ini adalah metrik inti arus pesanan yang telah kita bahas sebelumnya. - Karakteristik Buku Pesanan (Buku - Angkatan Darat):
wobi_10s: Ketidakseimbangan Buku Pesanan Tertimbang selama 10 detik terakhir. Ini adalah indikator frekuensi sangat tinggi yang mengukur tekanan beli dan jual di pasar.
spread_10s: Rata-rata spread bid-ask selama 10 detik terakhir. Mencerminkan likuiditas jangka pendek. - Karakteristik asli (Harga - Angkatan Laut):
Kami akan mempertahankan fitur berkinerja terbaik dari versi sebelumnya dan mengoptimalkannya.
Matriks fitur baru ini seperti komando tempur gabungan, yang secara bersamaan menangkap intelijen waktu nyata dari "laut (tren harga)", "darat (posisi pasar)", dan "udara (dampak transaksi)", dan kemampuan pengambilan keputusannya akan jauh lebih unggul dari sebelumnya.
Kodenya adalah sebagai berikut:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
Kode ini membutuhkan banyak perhitungan K-line
Laporan ini sangat berharga, karena memberi tahu kita "pemikiran" dan "karakter" model tersebut.
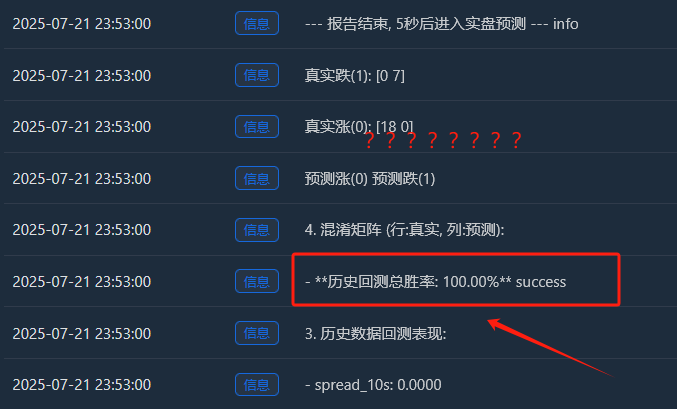
- Total tingkat kemenangan backtest historis: 93,33%
Ini angka yang sangat mengesankan! Meskipun kita perlu melihatnya secara objektif (ini adalah uji coba sampel), angka ini dengan jelas menunjukkan kekuatan prediktif yang luar biasa dari fitur alur pesanan dan buku pesanan yang baru kami tambahkan! Model ini telah menemukan pola yang sangat kuat dalam data historis. - Pentingnya Fitur & Informasi Saling
Raja telah lahir: volatilitas_15m (volatilitas) dan harga_perubahan_5m (perubahan harga) masih benar-benar inti, seperti yang diharapkan.
Bintang Baru: rsi_14 telah mengalami peningkatan signifikan dalam hal kepentingan! Ini menunjukkan bahwa pada jangka waktu 5 menit yang lebih pendek, indikator sentimen "overbought/oversold" RSI menjadi lebih bermakna.
Secara potensial, wobi_10s (ketidakseimbangan buku pesanan) dan spread_10s (spread) juga menunjukkan kontribusi. Hal ini sangat menggembirakan dan menunjukkan bahwa fitur mikrostruktur kami mulai berfungsi!
Refleksi: Kontribusi alpha_5m (aliran pesanan) hampir nol. Hal ini mungkin disebabkan oleh penyederhanaan metode perhitungan alpha kami yang berlebihan, atau alpha 5 menit dan perubahan harga 5 menit itu sendiri mengandung terlalu banyak informasi yang tumpang tindih. Ini merupakan poin optimasi penting bagi kami di masa mendatang. - Matriks Kebingungan (bukti utama keberhasilan!)
Peningkatan riil (0):[22 0] -> Dalam semua 22 reli nyata, model memprediksinya 100% benar, tanpa kesalahan sedikit pun!
Penurunan nyata (1):[2 6] -> Dari 8 penurunan aktual, model tersebut memprediksi dengan tepat 6 dan melewatkan 2 (salah mengiranya sebagai peningkatan).
Interpretasi: Model ini menunjukkan karakteristik yang sangat menarik: ia merupakan detektor bullish yang sangat kuat, menangkap sinyal bullish dengan hampir sempurna. Model ini juga berkinerja baik dalam mengidentifikasi tren bearish (akurasi 6/8 = 75%), tetapi terkadang membuat kesalahan dengan salah mengira tren bearish sebagai tren naik.
Lalu apa yang terjadi selanjutnya?
Memperkenalkan "Mesin Sinyal Perdagangan"
Inilah inti dan bagian paling inovatif dari peningkatan ini. Kami akan memperkenalkan variabel status global, seperti g_active_signal, untuk mengelola status "posisi" strategi saat ini (perlu diketahui bahwa ini hanyalah status posisi virtual dan tidak melibatkan perdagangan aktual).
Logika kerja mesin keadaan ini adalah sebagai berikut:
- Keadaan awal: Diam
- Ketika strategi berada dalam kondisi ini, ia akan membuat prediksi untuk setiap garis K baru, sama seperti yang dilakukannya sekarang.
- Transisi Rezim: Setelah model memprediksi sinyal yang jelas (misalnya, “Naik”), strategi akan:
- Mencetak satu sinyal entri yang menarik ke jurnal, misalnya, 🎯 Sinyal perdagangan baru: Prakiraan naik! Periode observasi 15 menit.
- Mengubah status strategi dari Diam ke Dalam Sinyal.
Catat waktu pemicu dan arah sinyal saat ini.
- Status Posisi: Dalam Sinyal
- Ketika strategi berada dalam kondisi ini, ia akan sepenuhnya berhenti memprediksi garis K baru. Ia tidak lagi peduli dengan fluktuasi setiap menit dan memasuki mode "biarkan peluru terbang".
- Satu-satunya hal yang dilakukannya adalah memeriksa waktu: apakah 15 menit (durasi PREDICT_HORIZON) telah berlalu sejak sinyal dipicu.
- Transisi Negara: Setelah periode observasi 15 menit, kebijakan akan:
- Cetak sinyal keluar yang jelas ke log, seperti akhir periode sinyal 🏁. Atur ulang strategi dan cari peluang baru...
- Mengubah status strategi dari ditahan menjadi diam.
- Pada titik ini, strategi akan mulai memprediksi garis K baru lagi dan mencari peluang perdagangan berikutnya.
Dengan mesin keadaan sederhana ini, kami telah mencapai persyaratan dengan sempurna: satu sinyal, satu siklus pengamatan lengkap, dan tidak ada informasi interferensi selama periode tersebut.
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
Lalu saya jalankan kode ini
Analisis mendalam: Mengapa ada tingkat kemenangan 100% yang “sempurna”?
Hasil "sempurna" ini mengungkap beberapa wawasan penting dan mendalam tentang pembelajaran mesin dan pasar keuangan. Ini bukan bug, melainkan fenomena umum yang dikenal sebagai "overfitting", yang dapat terjadi dalam kondisi tertentu.
Apa arti “overfitting”?
-
Berikut analogi yang gamblang: Bayangkan seorang siswa (model SVM kita) mengerjakan serangkaian latihan yang sangat singkat dan sederhana (200 titik data candlestick yang kita kumpulkan). Siswa ini sangat cerdas, dan alih-alih mempelajari metode pemecahan masalah umum, ia hanya menghafal jawaban dari beberapa soal tersebut.
-
Hasil: Ketika kami mengujinya dengan rangkaian pertanyaan latihan yang sama (ini adalah "uji balik historis" kami), ia pasti bisa mendapatkan skor sempurna 100. Namun, begitu kami memberinya rangkaian pertanyaan yang benar-benar baru yang belum pernah ia lihat sebelumnya (pasar berjangka riil), ia kemungkinan besar tidak akan bisa menjawab satu pun pertanyaan tersebut.
- Mengapa model kita "overfit"?
-
Sampel pelatihannya "terlalu sedikit" dan "terlalu khusus":
-
Meskipun kami mengumpulkan 200 garis K (sekitar 3,3 jam), menurut log, jumlah akhir sampel "kenaikan dan penurunan efektif" yang memenuhi definisi kami hanya 18 + 7 = 25.
-
Untuk model SVM yang kompleks, 25 sampel seperti beberapa gelombang di lautan, yang terlalu kecil.
-
Lebih penting lagi, ke-25 sampel ini semuanya berasal dari situasi pasar yang sangat berkorelasi pada sore yang sama. Mereka kemungkinan besar memiliki "rutinitas" yang sangat mirip.
- Kemampuan model “terlalu kuat”:
- SVM adalah pengklasifikasi nonlinier yang sangat kuat. Kemampuannya seperti otak dengan memori super.
- Ketika sebuah model yang kuat belajar dari kumpulan data yang terlalu sederhana dan berulang, ia cenderung "menghafal" semua detail dan gangguan dalam data tersebut, alih-alih mempelajari hukum makro yang lebih universal di baliknya.
- Bukti dari matriks kebingungan:
- Peningkatan riil (0):[18 0] -> 18 sampel naik, semuanya dihafal dengan sempurna.
- Penurunan nyata (1):[0 7] -> 7 sampel jatuh, semuanya diingat dengan sempurna.
- Ini sempurna[ [18, 0], [Matriks [0, 7] merupakan bukti tak terbantahkan dari overfitting model. Matriks ini hampir tidak membuat kesalahan, yang secara inheren tidak normal dalam pasar keuangan yang penuh dengan keacakan.
Oleh karena itu, kita harus menafsirkan tingkat kemenangan 100% ini sebagai berikut:
Model ini telah mempelajari dan menghafal semua pola kondisi pasar spesifik secara luar biasa selama tiga jam terakhir. Ini menunjukkan efektivitas rekayasa fitur dan kerangka kerja model kami. Namun, kami sama sekali tidak dapat mengharapkannya untuk mempertahankan tingkat kemenangan yang begitu tinggi di pasar nyata di masa mendatang. Ini lebih seperti 'kuis dadakan' yang sempurna daripada hasil akhir 'ujian masuk perguruan tinggi'.

Pembelajaran mesin juga merupakan sesuatu yang telah saya jelajahi baru-baru ini, kita akan membicarakannya di edisi berikutnya!
Kita perlu melakukan "transformasi pemikiran" yang menyeluruh terhadap "siswa yang bias" ini. Tujuan kita adalah untuk mematahkan biasnya dan memungkinkannya untuk memandang "suka dan duka" secara adil dan objektif.
