
Studi pendahuluan tentang penerapan crawler Python pada platform FMZ - konten pengumuman Binance crawling
Saya baru-baru ini melihat komunitas dan pustaka dan tidak menemukan informasi relevan tentang perayap Python, berdasarkan semangat pengembangan komprehensif sebagai QUANT. Saya mempelajari konsep dan pengetahuan terkait crawler dengan cara yang sangat sederhana. Setelah mempelajarinya lebih lanjut, saya menemukan bahwa "teknologi perayap" merupakan "lubang" yang cukup besar. Artikel ini hanyalah eksplorasi awal tentang "teknologi perayap". Mari kita lakukan praktik teknologi perayapan yang paling sederhana pada platform perdagangan kuantitatif FMZ.
membutuhkan
Bagi para pedagang yang gemar berinvestasi pada koin-koin baru, mereka selalu berharap untuk memperoleh informasi tentang pencatatan koin di bursa sesegera mungkin. Jelas tidak realistis untuk mengawasi situs web bursa secara manual. Kemudian Anda perlu menggunakan skrip perayap untuk memantau halaman pengumuman bursa dan mendeteksi pengumuman baru sehingga Anda dapat diberi tahu dan diingatkan sesegera mungkin.
Eksplorasi awal
Mari kita gunakan program yang sangat sederhana sebagai permulaan (skrip perayap yang benar-benar kuat jauh lebih rumit, jadi luangkan waktu Anda). Logika programnya sangat sederhana, yaitu membiarkan program terus mengakses halaman pengumuman bursa, mengurai konten HTML yang diperoleh, dan mendeteksi apakah konten tag tertentu diperbarui.
Kode Implementasi
Anda dapat menggunakan beberapa kerangka kerja perayap yang berguna. Akan tetapi, mengingat persyaratannya sangat sederhana, maka dimungkinkan juga untuk menuliskannya secara langsung.
Pustaka Python yang dibutuhkan:
requests, yang secara sederhana dapat dipahami sebagai perpustakaan yang digunakan untuk mengakses halaman web.
bs4, yang secara sederhana dapat dipahami sebagai pustaka yang digunakan untuk mengurai kode HTML suatu halaman web.
Kode:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
berlari
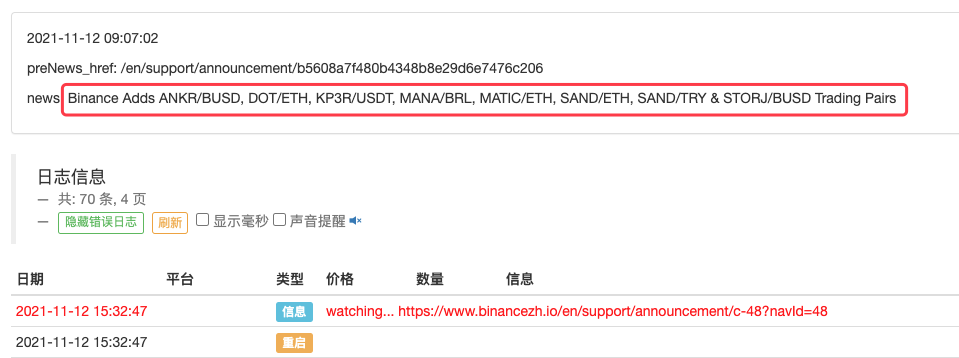
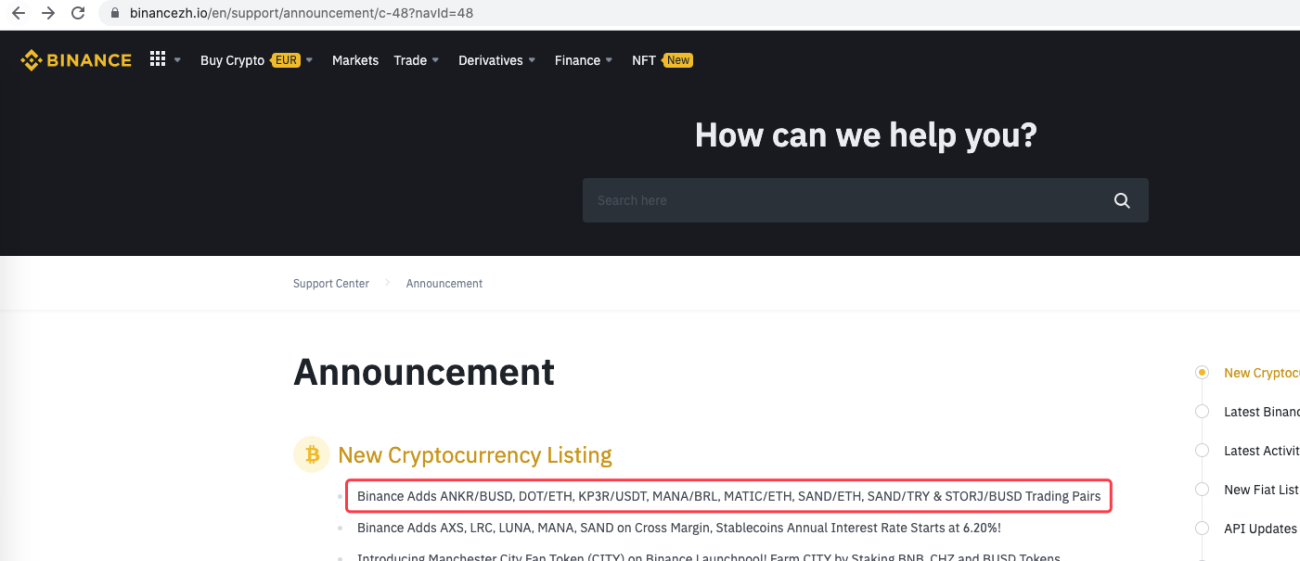
Bahkan dapat diperluas untuk mendeteksi saat pengumuman baru muncul, misalnya. Menganalisis mata uang baru dalam pengumuman dan secara otomatis menempatkan pesanan untuk transaksi baru.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1