
FMZ プラットフォームでの Python クローラーの適用に関する予備調査 - Binance の発表コンテンツのクロール
最近、コミュニティとライブラリを調べたところ、QUANT としての総合的な開発の精神に基づく Python クローラーに関する関連情報は見つかりませんでした。クローラーに関連する概念と知識を非常に簡単に学びました。さらに詳しく調べてみると、「クローラー技術」は実に大きな「落とし穴」であることが分かりました。この記事は、「クローラー技術」の予備的な調査にすぎません。 FMZ 定量取引プラットフォームでクローラー テクノロジーの最も簡単な実践をしてみましょう。
必要
新しいコインに投資したいトレーダーは、取引所でのコインの上場に関する情報をできるだけ早く入手したいと常に願っています。取引所のウェブサイトを手動で監視するのは明らかに非現実的です。次に、クローラー スクリプトを使用して取引所のお知らせページを監視し、新しいお知らせを検出して、できるだけ早く通知やリマインダーを受け取ることができるようにする必要があります。
初期調査
まずは、非常にシンプルなプログラムを使用しましょう (本当に強力なクローラー スクリプトははるかに複雑なので、時間をかけてください)。プログラムロジックは非常にシンプルで、プログラムが取引所のアナウンスページに継続的にアクセスし、取得した HTML コンテンツを解析し、特定のタグのコンテンツが更新されたかどうかを検出します。
実装コード
いくつかの便利なクローラー フレームワークを使用できます。ただし、要件が非常に単純であることを考慮すると、直接記述することも可能です。
Python ライブラリが必要です:
requestsこれは、Web ページにアクセスするために使用されるライブラリとして簡単に理解できます。
bs4これは、Web ページの HTML コードを解析するために使用されるライブラリとして簡単に理解できます。
コード:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
走る
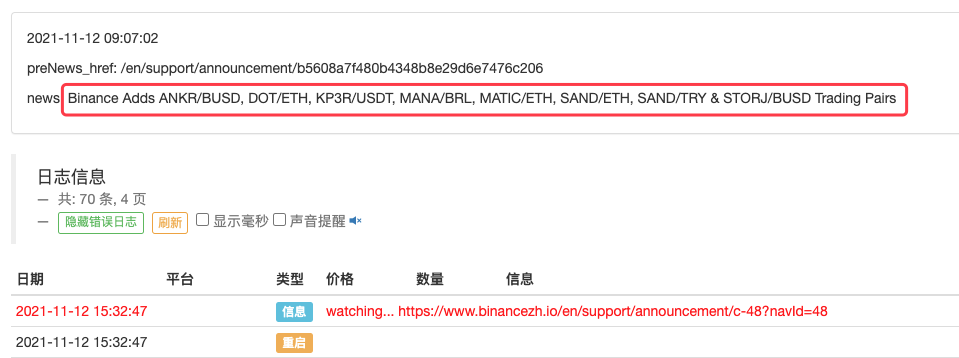
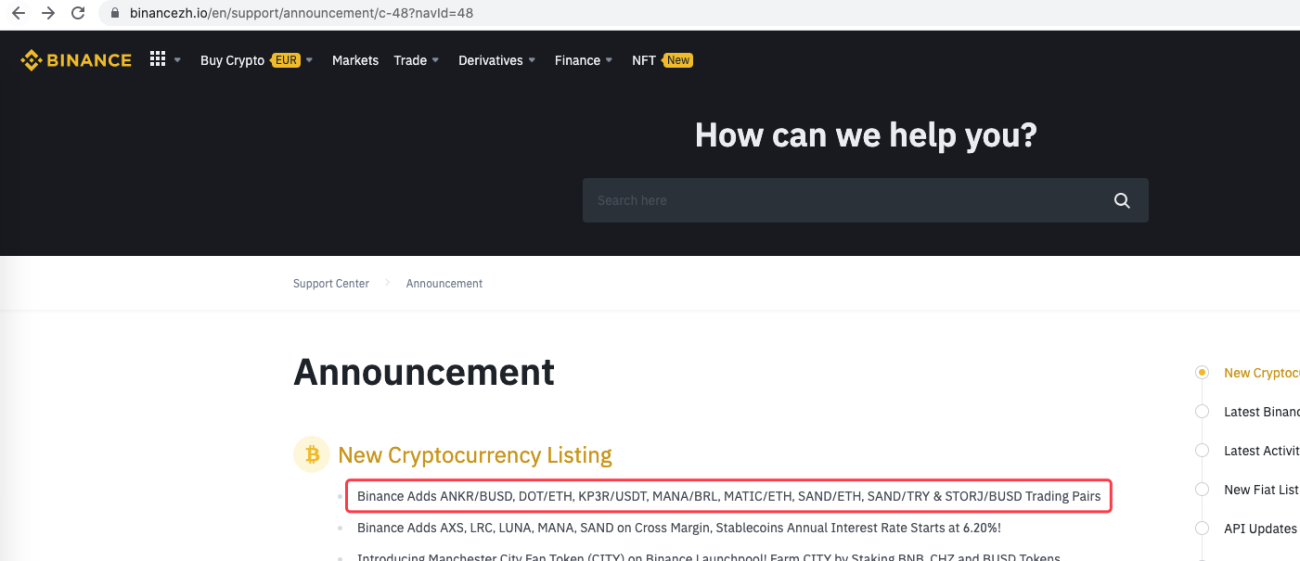
たとえば、新しいアナウンスが表示されたときにそれを検出するように拡張することもできます。発表された新しい通貨を分析し、新しい取引の注文を自動的に配置します。

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1