

📢 레이어드 아머
이 기사는실용적인 거래를 위한 웨이블릿 변환에 대한 대중 과학 서적이 코드는 복잡한 단계(다단계 분해, 임계값 기반 잡음 제거, 표준 웨이블릿의 역변환 재구성 등)를 생략하고 핵심 개념만 남겨둔 간소화된 교육용 버전입니다.**웨이블릿 계수를 사용하여 가격에 다중 스케일 평활화를 수행함으로써 추세 정보를 추출합니다.**전략 개발 및 신속한 검증에는 적합하지만, 학술 연구나 논문 발표에는 적합하지 않습니다.
I. 서론: "지호 전문가"의 허위 주장 폭로
지후(Zhihu)에서 금융 및 양적 분석 관련 주제를 자주 검색하는 사람이라면 누구나 이러한 상황을 본 적이 있을 것입니다.
일부 "전문가"들은 계속해서 이렇게 말합니다:
- 웨이블릿 변환 잡음 제거
- 푸리에 변환 추출 기간
- 라플라스 평활화는 이상치를 제거합니다.
그는 마치 양적 거래라는 핵무기를 터득한 듯 모두를 놀라게 했다.
하지만 당신은 그가 코드를 보여주길 원하는 건가요?
"이것은 영업 비밀이므로 공개할 수 없습니다."
그에게 원리를 설명해달라고 하세요.
"이건... 고급 수학이 필요한 문제라서, 내가 설명해 줘도 당신은 이해하지 못할 거예요."
오늘은 "즈후 전문가"들이 자주 언급하는 주제들을 살펴보고, 금융 시장에서 웨이블릿 변환의 실제 적용 사례를 소개하여 여러분이 이 기술을 올바르게 이해할 수 있도록 돕겠습니다.
II. 웨이블릿 변환이란 정확히 무엇인가요?
간단한 설명
노래를 듣고 있는데 녹음에 배경 소음이 섞여 있다고 상상해 보세요.
원본 녹음 = 사람 목소리 + 배경 소음 + 잡음
웨이블릿 변환은 다음과 같습니다.스마트 필터:
- 목소리를 보존하세요
- 노이즈를 걸러냅니다
- 또한 어느 부분이 후렴이고 어느 부분이 절인지 알려줄 수 있습니다.
금융 시장으로 전환하세요:
원가 = 실제 추세 + 단기 변동 + 무작위 노이즈
웨이블릿 변환은 다음과 같은 도움을 줄 수 있습니다.
- 진정한 추세를 추출하다(장기적인 방향)
- 단기 변동 필터링(장중 변동)
- 주요 변곡점 파악(추세 반전)
핵심 개념: 기저 함수 분해
웨이블릿 변환의 핵심은 다음과 같습니다.특정 "기저 함수"(웨이블릿) 세트를 사용하여 원래 신호를 분해합니다.。
어떤 사람의 외모를 묘사하고 싶다고 상상해 보세요.
- 기존 방식: 픽셀 단위로 설명하는 것으로 매우 번거롭습니다.
- 웨이블릿 방법: 눈 크기, 코 높이, 얼굴 윤곽과 같은 요소를 활용합니다.특징설명을 결합하기 위해
금융 가격 기준으로:
원가격 시리즈 = 기본 함수 1 × 가중치 1 + 기본 함수 2 × 가중치 2 + ... + 노이즈
**기저 함수는 웨이블릿 계수에 해당하는 "템플릿"입니다.**다양한 웨이블릿 유형(Haar, Daubechies, Mexican Hat 등)은 가격을 분해하기 위해 다양한 "특징 추출기"를 사용하는 것과 마찬가지로 서로 다른 템플릿을 사용합니다.
필터: 주파수 영역에서의 체
웨이블릿 변환은 본질적으로...다중 스케일 필터 뱅크:
고주파 필터 → 급격한 변동(일상적인 노이즈, 틱 단위 변동)을 포착합니다.
중간 주파수 필터 → 중기 추세(수 시간에서 수 일 범위의 대역)를 포착합니다.
저주파 필터 → 장기적인 추세(주간 및 월간 추세)를 포착합니다.
왜 "웨이블릿"이라고 부르는 걸까요?
- 전통적인 푸리에 변환은 다음과 같습니다.무한히 긴 사인파마치 무한히 긴 자처럼
- 웨이블릿 변환이 사용됩니다.유한 길이의 "작은" 파동길이가 서로 다른 자 세트처럼
금융 시장 가격 분석에 사인파를 사용하는 것의 문제점은 다음과 같습니다. 사인파는 신호가 주기적으로 반복된다고 가정하지만, 금융 시장은 그렇지 않습니다! 비트코인은 오늘 10% 상승했다가 내일 8% 하락할 수도 있으며, 이러한 변동에는 주기성이 전혀 없습니다.
웨이블릿의 장점:현지화 분석이는 "전반적인 시장은 변동성을 보였다"와 같은 일반적인 결론 대신 "2025년 12월 20일 오후 3시부터 5시 사이에 가격 추세는 주로 상승세였다"와 같이 구체적인 정보를 제공할 수 있습니다.
재구성: 분해에서 재구성까지
웨이블릿 변환은거꾸로 할 수 있는이건 정말 중요해요!
원가 ---> 웨이블릿 분해 ---> 추세 성분 + 변동성 성분 + 노이즈 성분
추세 성분 + 변동성 성분 + 노이즈 성분 ---> 웨이블릿 재구성 ---> 원래 가격
리팩토링 프로세스개별 구성 요소를 분해하는 것입니다.선택적으로 다시 결합합니다:
- 추세 구성 요소 =[99800, 99850, 99900, 99950, ...] # 우리가 원하는 것
- 변동 성분 =[+200, -150, +180, -120, ...] # 유용할 수 있습니다
- 잡음 성분 =[±10, ±15, ±8, ±12, ...] # 버리세요!
재구성 시에는 추세 성분만 사용하십시오.
분해 후 다음과 같은 결과가 얻어졌습니다.
- 재구성된 가격 = 추세 요소 + 부분 변동성 요소
실제 거래에서는 보통 다음과 같은 방식으로 진행됩니다.저주파 부분만 재구성합니다.(트렌드) 고주파 성분(잡음)은 직접 제거됩니다. 이것이 웨이블릿 "잡음 제거"의 원리입니다.
수학의 원리 (간단한 버전)
복잡한 적분 공식은 생략하고 일반인이 이해하기 쉽게 설명해 보겠습니다.
웨이블릿 변환 = 일련의 "웨이블릿 계수"를 사용하여 가격 시계열의 가중 평균을 구하는 것
기본 공식:
가격 평활화[i] = Σ(원래 가격)[i-j] × 웨이블릿 계수[j]) / Σ(웨이블릿 계수)[j])
필터 관점:
원래 가격은 웨이블릿 필터를 거쳐 필터링됩니다 → 서로 다른 주파수 성분들이 "선택"됩니다.
핵심은웨이블릿 계수 선택:
- 서로 다른 웨이블릿은 서로 다른 필터 특성을 의미하며, 이는 결국 서로 다른 주파수 응답으로 이어집니다.
- 서로 다른 수준 = 서로 다른 시간 척도 = 서로 다른 추세 주기
예를 들어:
다우베시 4 웨이블릿을 사용한다고 가정하면 계수는 다음과 같습니다.[0.483, 0.837, 0.224, -0.129]:
이 계수 집합은 필터를 정의합니다.
- 양의 계수(0.483, 0.837, 0.224) → 해당 포지션에 대한 가격을 유지합니다.
- 음의 계수(-0.129) → 초기 가격 변동을 억제함
- 계수 가중치 → 각 가격의 기여도를 결정합니다.
웨이블릿 변환은 이 필터를 전체 가격 시계열에 걸쳐 "이동"시킬 때 완료됩니다. 각 이동마다 계산이 수행됩니다.현재 기간 내 가격의 가중 평균가중치는 웨이블릿 계수입니다.
신호를 "분해"할 수 있는 이유는 무엇일까요?
수학적으로 증명할 수 있기 때문입니다.**모든 신호는 웨이블릿 기저 함수의 선형 조합으로 표현될 수 있습니다.**RGB의 세 가지 기본색을 혼합하여 모든 색을 만들 수 있는 것처럼, 웨이블릿 기저 함수를 조합하여 모든 가격 시계열을 도출할 수 있습니다. 웨이블릿 유형마다 서로 다른 "기저 함수 라이브러리"를 제공하며, 이는 다양한 유형의 신호 분석에 적합합니다.
III. 본 시도: 7가지 웨이블릿 변환의 실제 적용
응용 접근법: 이론에서 실천으로의 단순화
신호 처리 교과서에서 웨이블릿 변환은 일반적으로 복소수를 포함합니다...다단계 분해, 재구성 및 임계값 잡음 제거단계:
완전한 웨이블릿 분석 워크플로우:
- 다중 스케일 분해 → 근사 계수와 상세 계수를 산출합니다.
- 임계값 설정 → 노이즈 감소를 위해 세부 계수에 소프트/하드 임계값 설정을 적용합니다.
- 역변환 재구성 → 처리된 계수를 신호에 복원
- 경계 확장 → 신호 경계 효과 처리
- 에너지 정규화 → 변환 전후의 에너지 보존을 보장합니다
하지만금융 거래의 실제 적용 사례중국에서는 그렇게 복잡할 필요가 없습니다. 이유는 다음과 같습니다.
1. 거래에는 추세 방향만 파악하면 되며, 완벽한 재구성은 필요하지 않습니다.
학술 연구에서는 재구성 오차가 0.01% 미만이어야 하지만, 거래에서는 가격이 오를지 내릴지만 예측하면 충분합니다. 재구성 오차가 5%에 달하더라도 추세 방향만 맞으면 전략은 여전히 수익을 낼 수 있습니다.
2. 실시간 요구 사항은 계산을 간소화합니다.
완전한 웨이블릿 분해는 여러 계층의 계수를 재귀적으로 계산해야 하므로 고빈도 거래에서 지연을 유발할 수 있습니다. 반면 직접 컨볼루션은 밀리초 단위로 완료될 수 있어 실시간 거래의 요구 사항을 충족합니다.
3. 금융 신호의 특성
금융 가격은 안정적인 신호가 아니며 엄격한 주기성을 보이지 않습니다. 복소 주파수 분해는 이러한 경우에 큰 의미가 없으며, 단순한 추세 추출이 더 실용적입니다.
이러한 단순화 전략
따라서 이 기사는웨이블릿 변환의 핵심을 추출하기금융 시장의 가장 실질적인 측면에 초점을 맞추어 보겠습니다.
핵심 간소화 1: 근사 계수(저주파 추세)만 사용
전통적인 웨이블릿 분해 → 근사 계수 + 상세 계수 (다층 구조)
이 응용 프로그램은 근사 계수만 유지하여 평활화된 추세를 직접 얻습니다.
핵심 간소화 2: 임계값 기반 노이즈 제거 없이 직접 컨볼루션
전통적인 웨이블릿 분해 → 세부 계수 임계값 처리 → 재구성
이 응용 프로그램: 직접 컨볼루션 → 평활화된 가격 얻기
핵심 단순화 3: 경계 처리 무시
기존 웨이블릿 변환은 신호 경계의 대칭 확장 및 주기적 확장과 같은 처리를 필요로 합니다.
이 애플리케이션은 중앙 부분에만 초점을 맞추고 있으며, 경계 부분의 오차는 허용됩니다.
구현 방법: 필터 컨볼루션
python
def convolve(src, coeffs, step):
"""
核心算法:用小波系数对价格序列做加权平均
src: 价格序列 [100000, 101000, 99000, ...]
coeffs: 小波系数 [0.483, 0.837, 0.224, -0.129]
step: 采样步长(用于多层级)
"""
sum_val = 0.0 # 加权和
sum_w = 0.0 # 权重和
for i, weight in enumerate(coeffs):
idx = i * step
if idx < len(src):
sum_val += src[idx] * weight
sum_w += weight
return sum_val / sum_w # 归一化
이 기능은...웨이블릿 필터의 핵심:
- 각 캔들스틱에 대해 N개의 캔들스틱 이전 데이터를 살펴봅니다(N은 웨이블릿 계수의 개수).
- 웨이블릿 계수를 가중치로 사용하여 가중 평균을 계산합니다.
- 조정함으로써
step매개변수를 통해 다단계 평활화(레벨 1/2/3...)를 활성화할 수 있습니다.
이러한 단순화가 타당한 이유는 무엇입니까?
거래의 필수 요건은 다음과 같기 때문입니다.소음 속에서 추세 찾기웨이블릿 변환의 근사 계수는 그 자체로 신호에 대한 "저역 통과 필터" 역할을 하여 저주파 추세 성분을 보존하는데, 이는 바로 우리가 필요로 하는 것입니다.
완전한 웨이블릿 분석이 더 정확하지만, 금융 거래에서는 다음과 같은 차이점이 있습니다.
- **수익은 추세 방향에서 발생합니다.**이는 복원의 정확성에서 비롯된 것이 아닙니다.
- **더 간단한 방법이 더 견고하다.**복잡한 모델은 과적합되기 쉽습니다.
- **계산 속도가 더 중요합니다.**실제 거래에서는 매 순간이 돈과 직결됩니다.
데이터 수집: FMZ 플랫폼의 편리함
사용Inventor Quantization(FMZ) 플랫폼의 로컬 백테스팅 엔진데이터를 얻기가 정말 편리해요!
python
'''backtest
start: 2025-12-17 00:00:00
end: 2025-12-23 08:00:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","fee":[0,0]}]
'''
from fmz import *
task = VCtx(__doc__)
def main():
exchange.SetCurrency("BTC_USDT")
exchange.SetContractType("swap")
records = exchange.GetRecords(PERIOD_H1, 500)
return records
records = main()
복잡한 API 통합이나 데이터 정제 과정이 필요하지 않습니다. 표준화된 캔들스틱 데이터를 직접 얻을 수 있으므로 데이터 처리 과정에 시간을 낭비하지 않고 7가지 웨이블릿 유형의 실제 효과를 신속하게 검증할 수 있습니다.
테스트 대상
7가지 일반적인 웨이블릿 유형(Haar, Daubechies 4, Symlet 4, Biorthogonal 3.3, Mexican Hat, Morlet 및 Discrete Meyer)의 암호화폐 가격 성능을 비교하여 다음과 같은 시각적 자료를 제공합니다.
- 서로 다른 웨이블릿 간의 평활화 강도 차이
- 동일한 웨이블릿의 서로 다른 레벨에서의 효과 변화
- 단기 거래에 적합한 웨이블릿과 추세 추종에 적합한 웨이블릿은 무엇일까요?
**수학적 유도의 엄밀성에 초점을 맞추는 것이 아니라, 실제 결과의 시각적 비교에 초점을 맞춥니다.**이를 통해 거래자들은 직관적인 이해를 바탕으로 자신의 전략에 맞는 웨이블릿 유형을 선택할 수 있습니다.
IV. 7가지 웨이블릿 유형에 대한 상세 설명
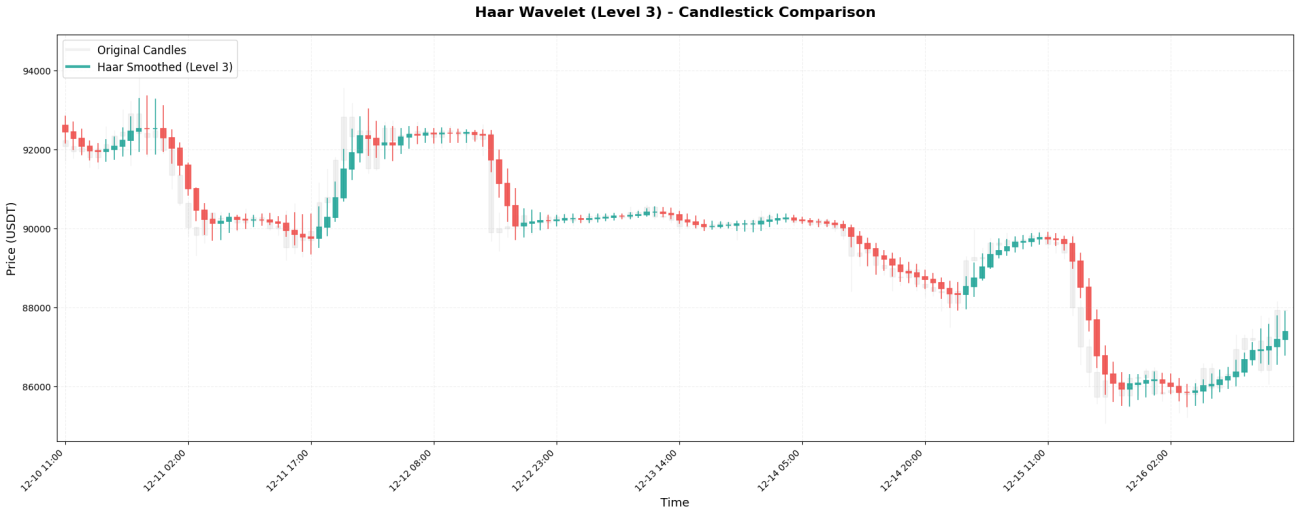
1. Haar 웨이블릿 - 가장 간단한 평균
하르 웨이블릿은 계수가 두 개뿐인 가장 기본적인 웨이블릿 유형입니다.[0.5, 0.5]기본적으로 이는 인접한 두 가격의 단순 평균입니다.
핵심 코드:
python
coeffs = [0.5, 0.5]
# 对价格序列 [100000, 101000, 99000, 102000, 98000] 处理
def smooth(prices, i):
return (prices[i] * 0.5 + prices[i-1] * 0.5) / 1.0
# 结果:[100000, 100500, 100000, 100500, 100000]
보시다시피, 원래 99,000에서 102,000까지 급격하게 변동하던 가격이 하르 웨이블릿 처리 후 상대적으로 안정됩니다. 이는 웨이블릿 "노이즈 제거" 효과로, 단기적인 급격한 변동을 완화하여 더욱 매끄러운 가격 추세를 보여주는 것입니다.
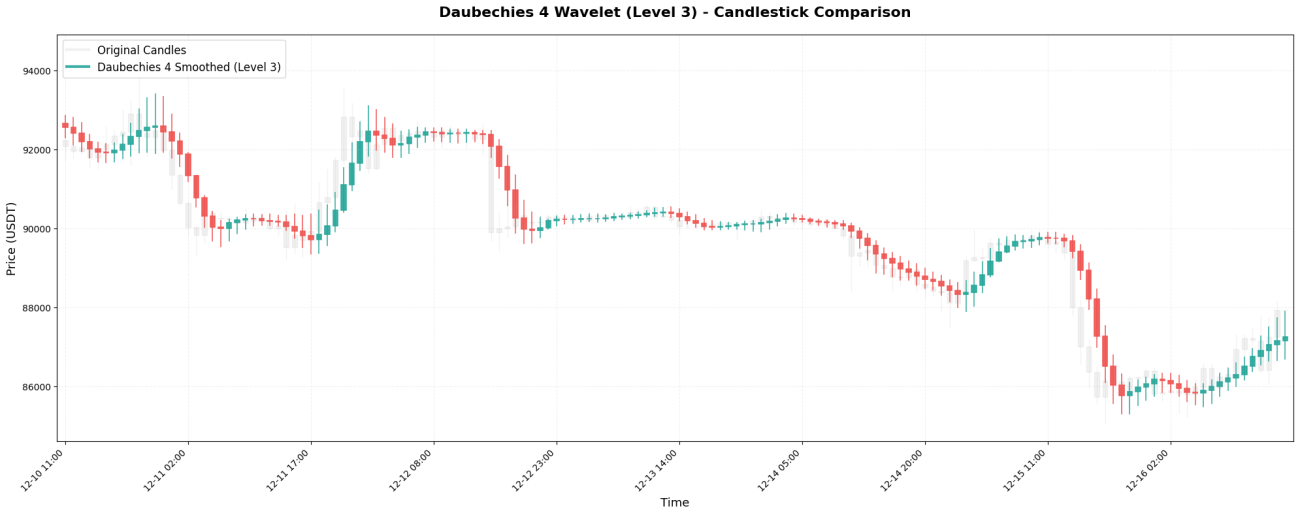
2. 도베시 4 - 엔지니어링 프로젝트에서 흔히 사용됨
다우베치 4(Daubechies 4, 줄여서 db4)는 공학에서 가장 일반적으로 사용되는 웨이블릿 중 하나입니다. 이 웨이블릿의 계수는 다음과 같습니다.[0.483, 0.837, 0.224, -0.129]마지막 계수는... 이라는 점에 유의하십시오.음수그것이 바로 이 제품을 독특하게 만드는 점입니다.
핵심 코드:
python
coeffs = [0.483, 0.837, 0.224, -0.129]
# 处理第i个价格点
def smooth(prices, i):
weighted_sum = (prices[i] * 0.483 + # 当前价格
prices[i-1] * 0.837 + # 前1根,权重最大!
prices[i-2] * 0.224 + # 前2根
prices[i-3] * (-0.129)) # 前3根,负权重
weight_sum = 0.483 + 0.837 + 0.224 + (-0.129) # = 1.415
return weighted_sum / weight_sum
# 示例:smooth([100000, 101000, 99000, 102000], 3) ≈ 100251
**주요 특징:**이전 캔들스틱의 가중치(0.837)가 현재 가격의 가중치(0.483)보다 큽니다! 이는 db4가 "방금 발생한 가격"에 더 큰 비중을 둔다는 것을 의미하며, 음의 가중치 계수는 이전 가격에 "상쇄" 효과를 주어 더욱 부드러운 차트 흐름을 만들어냅니다.
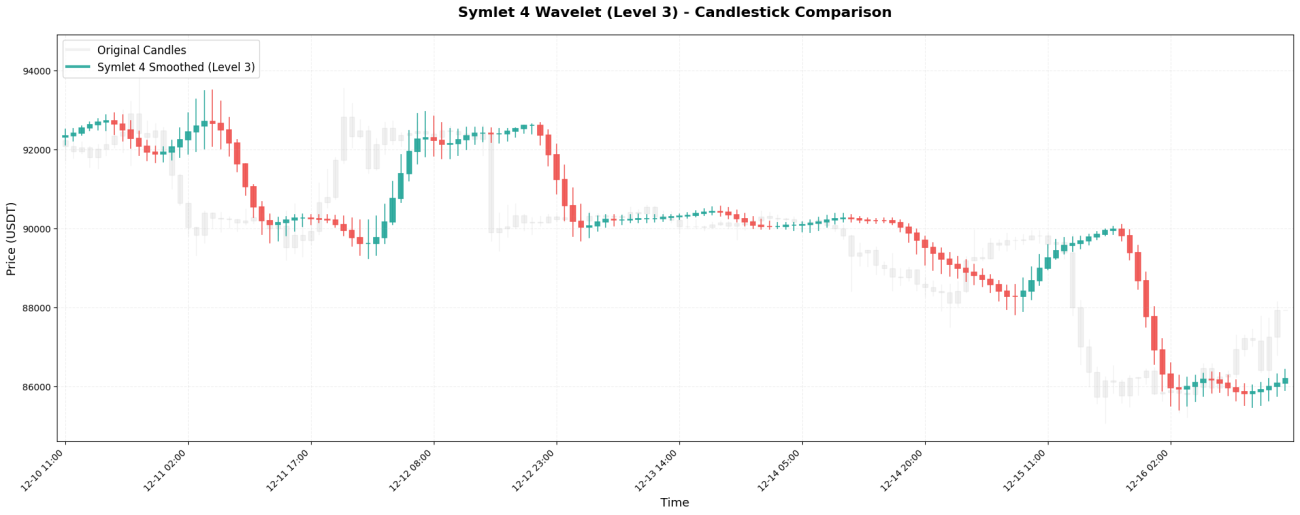
3. Symlet 4 - 대칭적으로 개선된 버전
Symlet 4는 더 나은 대칭성을 목표로 하는 Daubechies의 개선된 버전입니다. 계수:[-0.076, -0.030, 0.498, 0.804, 0.298, -0.099, -0.013, 0.032]。
핵심 코드:
python
coeffs = [-0.076, -0.030, 0.498, 0.804, 0.298, -0.099, -0.013, 0.032]
# 向前看8根K线
def smooth(prices, i):
weighted_sum = sum(prices[i-j] * coeffs[j] for j in range(8))
weight_sum = sum(coeffs)
return weighted_sum / weight_sum
# 平滑效果比Haar和db4都强,但反应速度更慢
**주요 특징:**8개의 캔들스틱으로 구성된 윈도우 길이는 가격 변동을 더 오래 기억할 수 있도록 해줍니다. 진정한 추세 반전은 8개의 캔들스틱이 지난 후에야 매끄러운 곡선에서 나타날 수 있습니다.
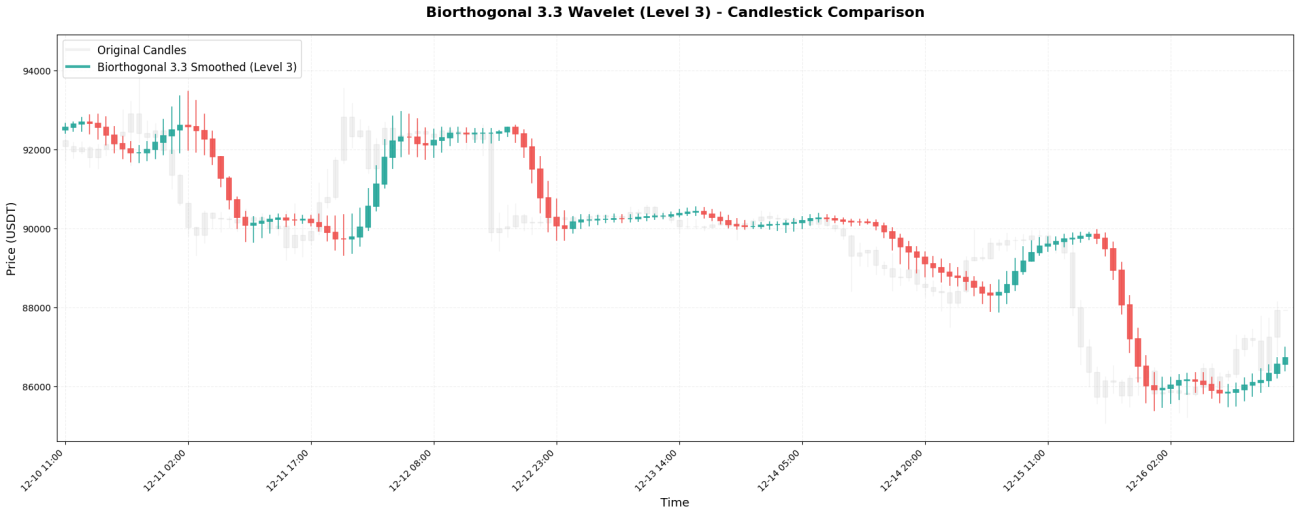
4. 쌍직교 3.3 - 완벽한 대칭
바이오직교 3.3(bior3.3으로 약칭)은 다음과 같은 계수를 갖는 완벽하게 대칭적인 웨이블릿입니다.[-0.066, 0.283, 0.637, 0.283, -0.066]。
핵심 코드:
python
coeffs = [-0.066, 0.283, 0.637, 0.283, -0.066]
# ↑ 中心↑ ↑
# 完全对称的两端
# 处理中间价格点
def smooth(prices, i):
# 实际应用:只向前看,不使用未来数据
weighted_sum = (prices[i-4] * (-0.066) + # 前4根
prices[i-3] * 0.283 + # 前3根
prices[i-2] * 0.637 + # 前2根,权重最大
prices[i-1] * 0.283 + # 前1根
prices[i] * (-0.066)) # 当前
weight_sum = sum(coeffs) # = 1.071
return weighted_sum / weight_sum
**주요 특징:**대칭성은 "위상 왜곡"이 발생하지 않도록 보장합니다. 즉, 평활화된 곡선이 설명할 수 없이 왼쪽이나 오른쪽으로 치우치지 않습니다.
5. 멕시칸 햇 - 터닝 포인트 헌터
멕시칸 햇(리커 웨이블릿이라고도 함) 계수:[-0.1, 0.0, 0.4, 0.8, 0.4, 0.0, -0.1]멕시코 모자처럼 생겼어요.
핵심 코드:
python
coeffs = [-0.1, 0.0, 0.4, 0.8, 0.4, 0.0, -0.1]
# 负值 零 正值 最大 正值 零 负值
# ↓ ↓
# "惩罚"两端,增强拐点检测能力
def smooth(prices, i):
weighted_sum = (prices[i-6] * (-0.1) + # 左3,负权重
prices[i-5] * 0.0 + # 左2
prices[i-4] * 0.4 + # 左1
prices[i-3] * 0.8 + # 中心,权重最大
prices[i-2] * 0.4 + # 右1
prices[i-1] * 0.0 + # 右2
prices[i] * (-0.1)) # 右3,负权重
weight_sum = sum(coeffs)
return weighted_sum / weight_sum
주요 특징:"중앙이 크고 양 끝이 음극인" 구조 덕분에 탐지 능력이 특히 뛰어납니다.변곡점- 가격이 상승 추세에서 하락 추세로 (또는 그 반대로) 전환되는 결정적인 순간. 음의 가중 계수는 먼 시점의 가격에 "불이익"을 주어 추세 변화를 빠르게 포착합니다.
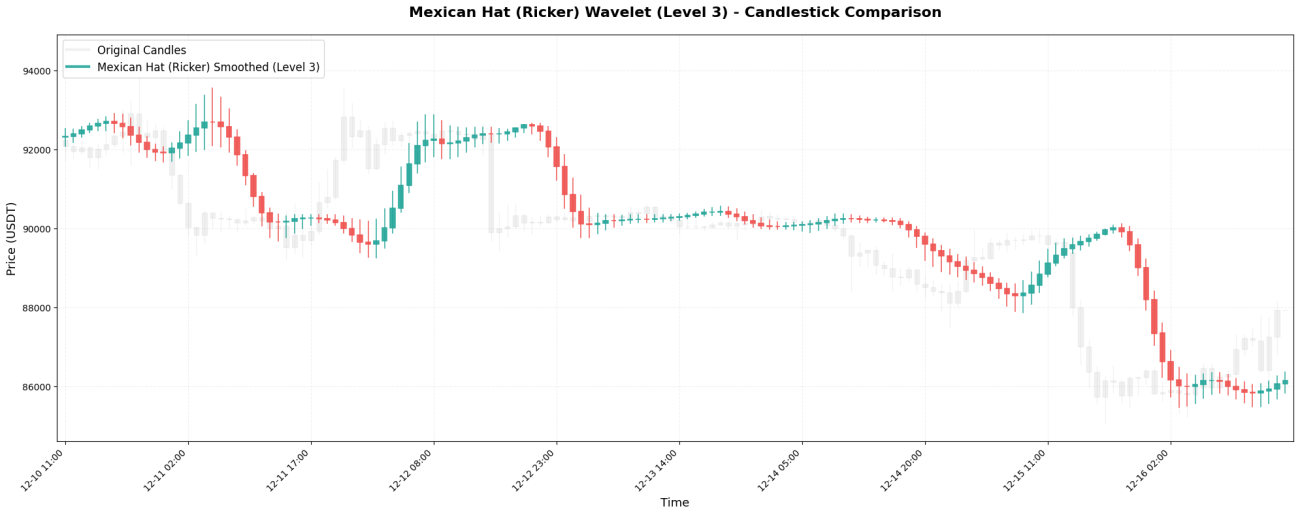
6. 모를레 - 가우스 평활화의 제왕
모를렛 웨이블릿은 가우시안(정규) 분포를 기반으로 하며, 계수는 다음과 같습니다.[0.0625, 0.25, 0.375, 0.25, 0.0625]。
핵심 코드:
python
coeffs = [0.0625, 0.25, 0.375, 0.25, 0.0625]
# ↓ ↓ ↓中心 ↓ ↓
# 远端 近端 最高 近端 远端
# 完美的高斯钟形曲线
def smooth(prices, i):
weighted_sum = (prices[i-4] * 0.0625 + # 左2,6.25%
prices[i-3] * 0.25 + # 左1,25%
prices[i-2] * 0.375 + # 中心,37.5%
prices[i-1] * 0.25 + # 右1,25%
prices[i] * 0.0625) # 右2,6.25%
# 权重和正好 = 1.0,无需除法
return weighted_sum
**주요 특징:**모든 웨이블릿 중에서 가장 "부드러운" 웨이블릿으로, 음수 가중치가 없으며 모든 가격이 계산에 부드럽게 반영됩니다. 결과적으로 곡선은 매우 매끄럽지만, 반응 속도가 느리다는 단점이 있습니다. 갑작스러운 가격 변동은 여러 캔들스틱이 지난 후에야 반영될 수 있습니다.
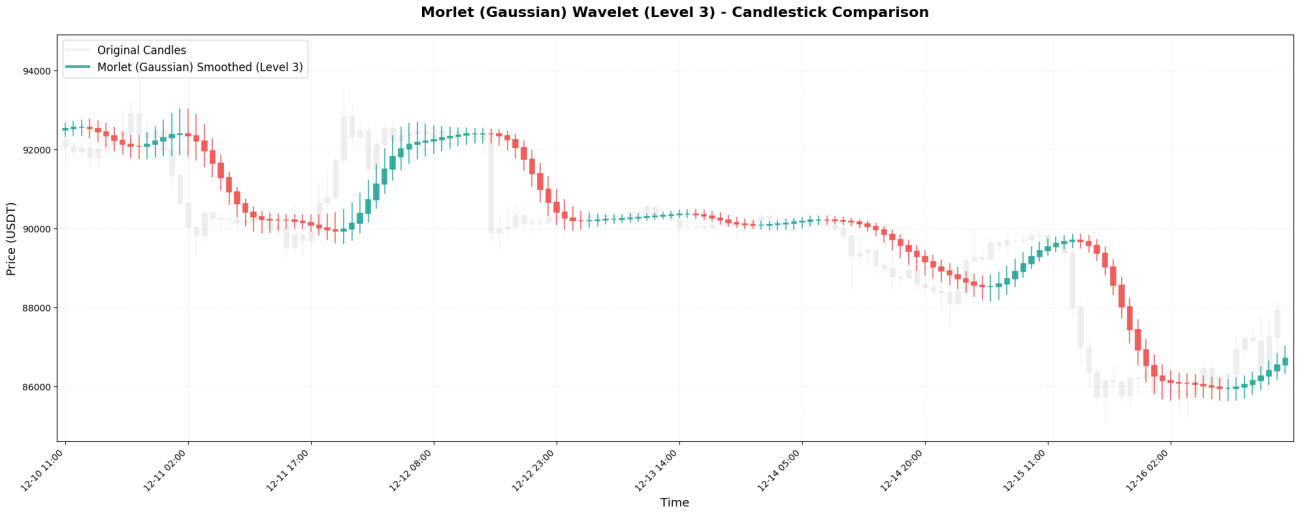
7. 이산 마이어 - 궁극의 평활화
이산 마이어 웨이블릿은 가장 복잡한 웨이블릿이며, 계수는 다음과 같습니다.[-0.015, -0.025, 0.0, 0.28, 0.52, 0.28, 0.0, -0.025, -0.015]。
핵심 코드:
python
coeffs = [-0.015, -0.025, 0.0, 0.28, 0.52, 0.28, 0.0, -0.025, -0.015]
# ↑ ↑ ↑ ↑中心↑ ↑ ↑ ↑
# 完全对称,中心权重超过50%
def smooth(prices, i):
# 向前看9根K线
weighted_sum = sum(prices[i-j] * coeffs[j] for j in range(9))
weight_sum = sum(coeffs) # = 1.0
return weighted_sum
# 注意:第4根之前的K线权重是0.52,超过50%!
# 实际上在告诉你"4根K线之前的中期趋势"
**주요 특징:**가장 많은 계수(9)와 가장 긴 과거 데이터, 가장 강력한 평활화 효과를 가지고 있습니다. "주간 추세"를 추출하는 데 적합하지만 지연이 매우 큽니다. 즉, 가격이 10% 하락한 경우에도 곡선에는 여전히 "계속 상승"하는 것처럼 보일 수 있습니다.
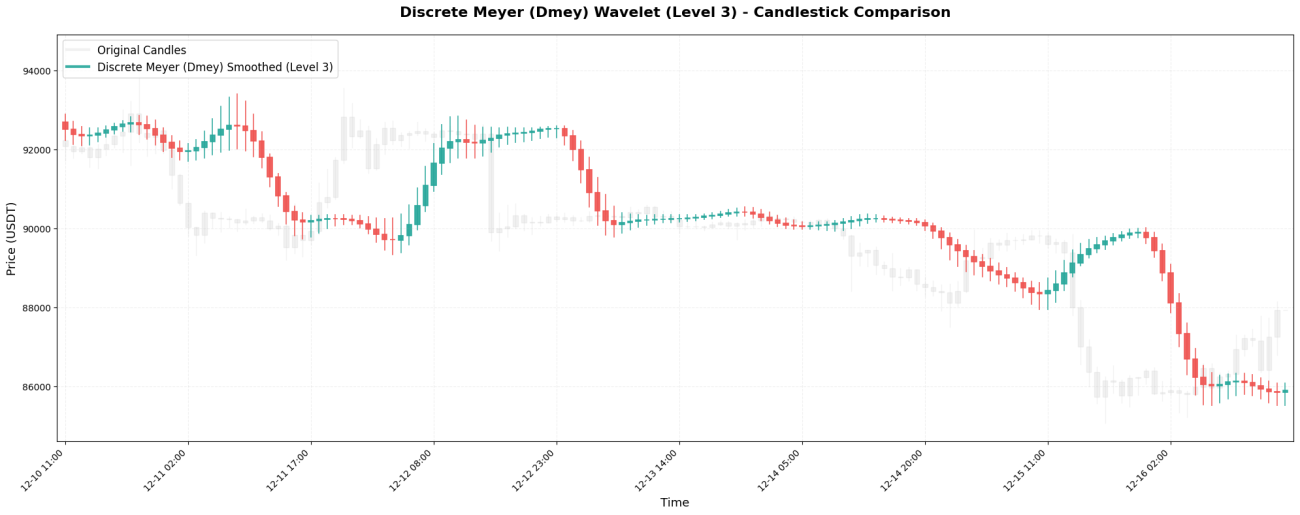
5. 평활화 효과에 차이가 나는 이유는 무엇입니까?
7가지 웨이블릿 유형을 검토하셨다면, 다음과 같은 패턴을 발견하셨을 것입니다.
계수가 많을수록 더 멀리 볼 수 있고, 평활화가 강해지며, 지연 시간이 길어집니다.
하르(계수 2개) → 막대 하나만 확인 → 거의 매끄럽지 않음
다우베시 4 (4개) → 앞의 3번 참조 → 약간 매끄러움
멕시칸 햇(7) → 6번 참조 → 중간 정도의 평활화
이산 마이어(9) → 8개 막대 보기 전 → 강한 평활화
음의 가중치를 사용하면 민감도가 향상되어 변화를 더 쉽게 감지할 수 있습니다.
하르/몰렛(음수 가중치 없음) → 온화하고 부드러우며 둔감함
멕시칸 햇(양쪽 끝이 음수) → 변곡점에 민감함
다우베치 4 (부정적) → 추세 변화에 민감함
대칭의 역할 = 왜곡 없음 = 원래 형태 유지
비대칭성(다우베시) → 좌우로 이동할 수 있음
대칭성(이중직교/마이어) → 중심 위치 유지
VI. 평활화 레벨의 영향
웨이블릿 변환은 마치 러시아 인형처럼 재귀적으로 적용할 수 있습니다. 첫 번째 적용을 레벨 1이라고 하고, 레벨 1의 결과에 다시 적용하는 것을 레벨 2라고 하며, 이런 식으로 계속 진행합니다.
서로 다른 수준에서 보이는 시간 척도:
비트코인 거래에 1시간 캔들스틱 차트를 사용한다고 가정해 보겠습니다.
레벨 1 → 2~4시간 동안 단기적인 변동을 관찰하세요
2단계 → 4~8시간 동안 추세를 관찰하세요
3단계 → 1~2일 동안 중장기 추세 관찰 (일반적으로 사용되는 전략)
4단계 → 2~4일간의 가격 변동폭을 관찰하세요
레벨 5 → 4~8일 동안 주요 추세를 관찰하세요
실제 결과 비교:
비트코인 최초 가격 (1시간 차트):99500, 99800, 99200, 100200, 99800, 100500, 100100, ...
레벨 1 처리: 99600, 99650, 99500, 99900, 99950, 100200, 100250, ...
(약간 매끄럽게 다듬어졌지만, 변동은 여전히 보입니다.)
레벨 3 처리: 99620, 99650, 99700, 99800, 99950, 100100, 100200, ...
(평활화된 그래프는 중기적인 추세를 나타냅니다.)
레벨 5 처리: 99630, 99640, 99660, 99700, 99760, 99840, 99930, ...
(매우 매끄러워서 대략적인 방향만 보여줍니다.)
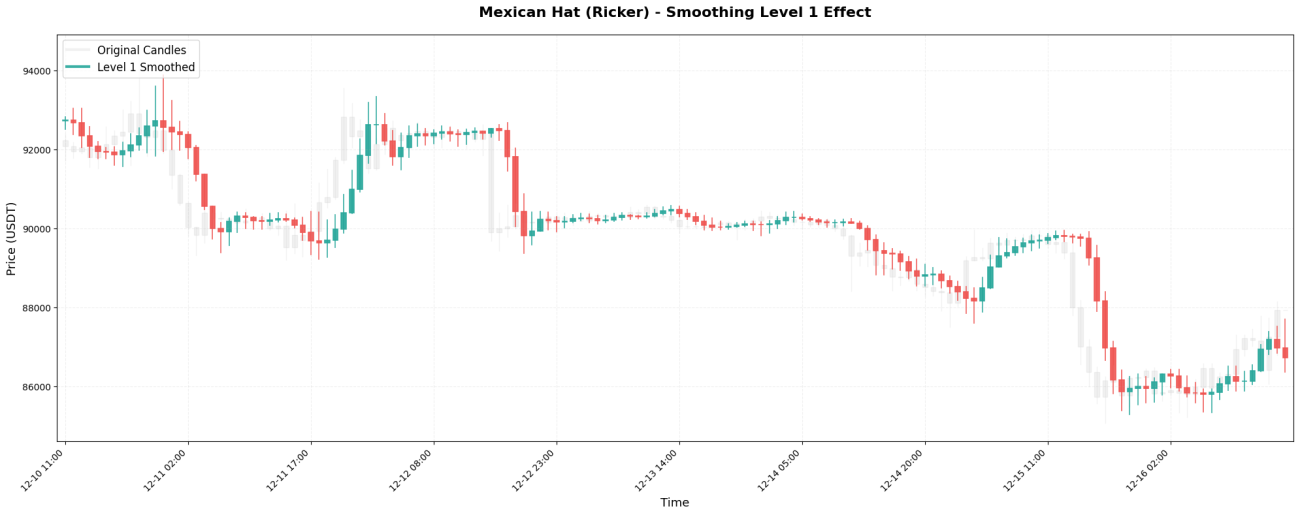
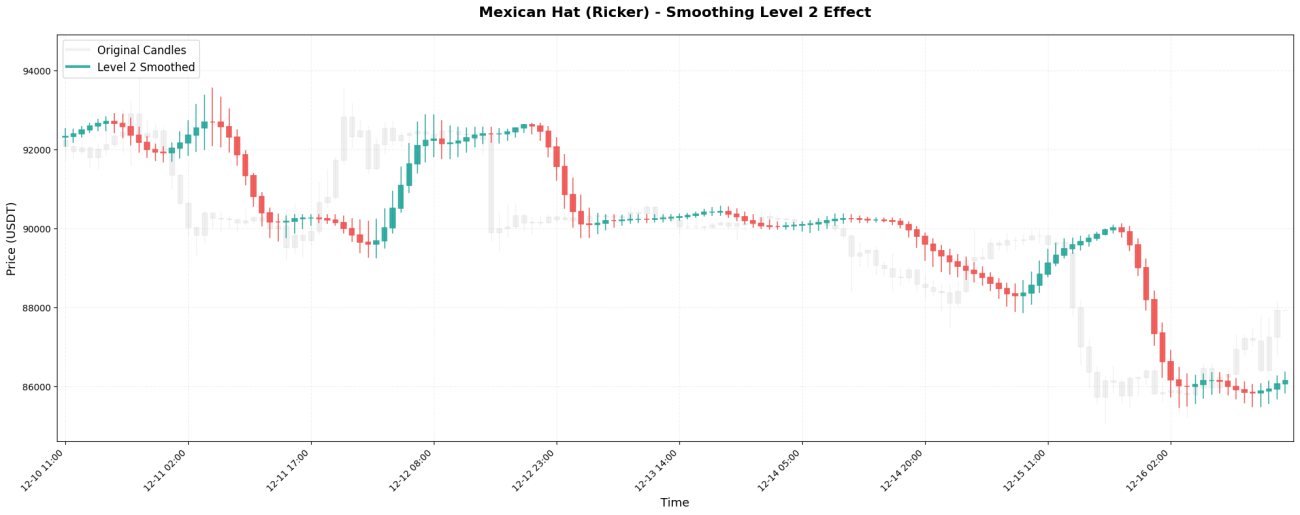
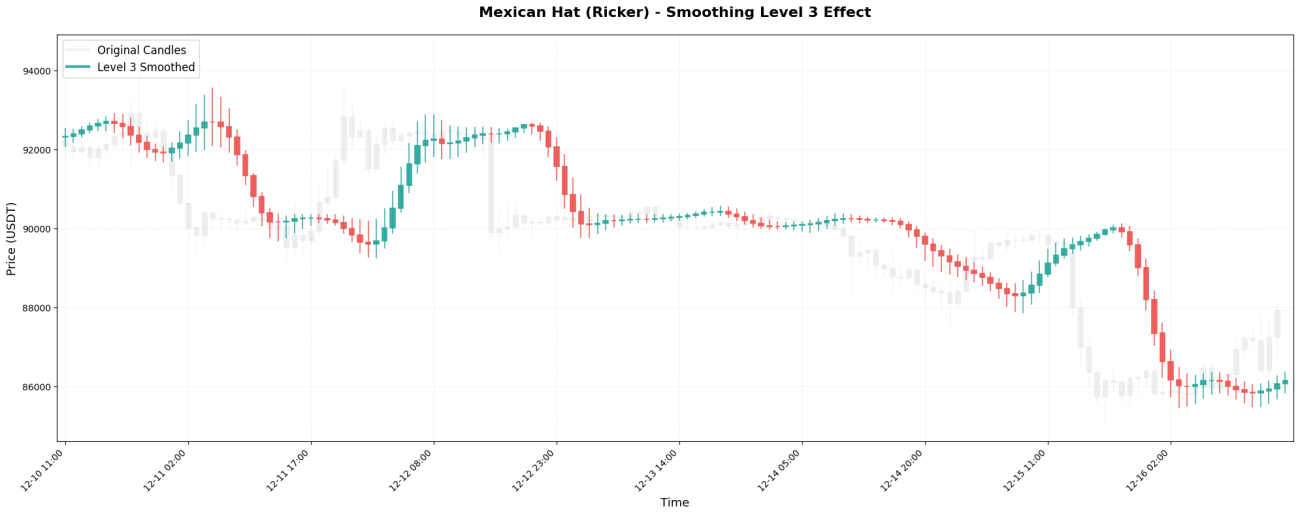
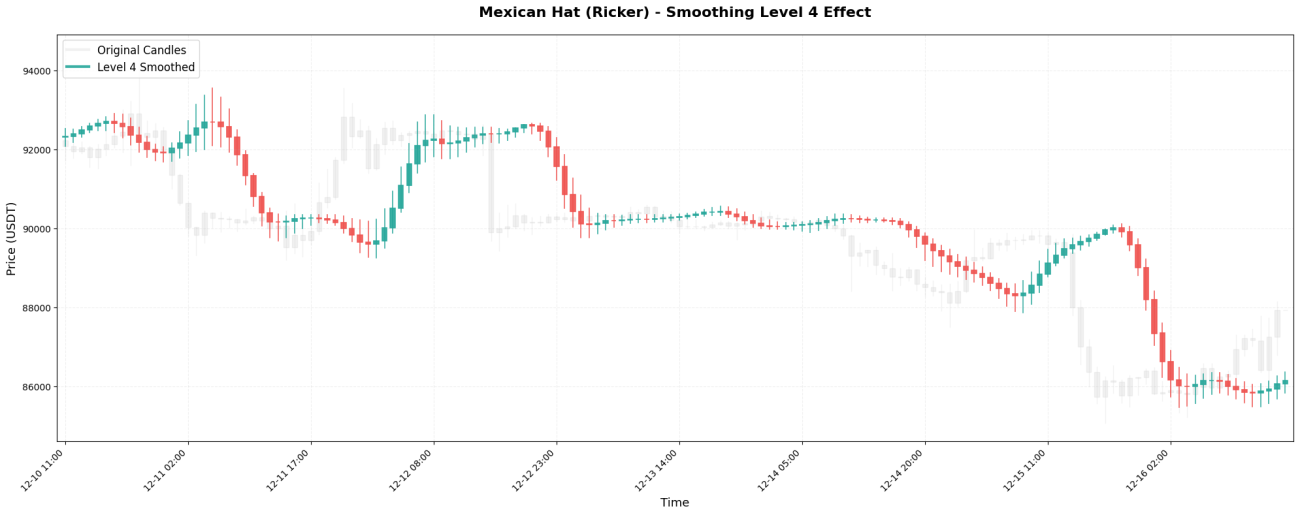
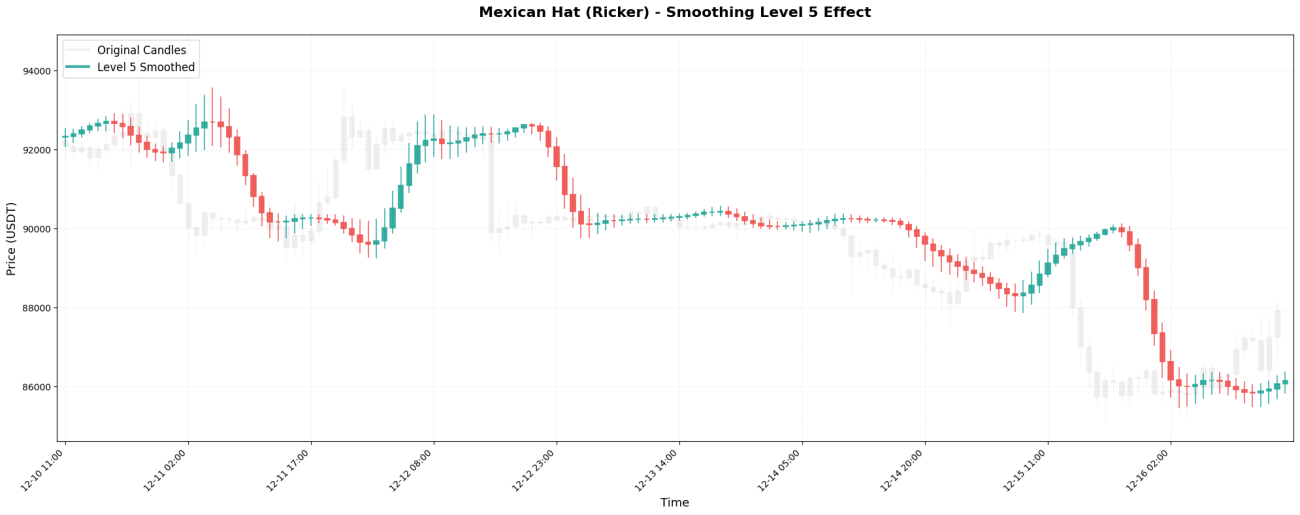
선택 원칙은 간단합니다. 보유 기간에 따라 적절한 레벨을 선택하십시오.
15분 스캘핑 → 1~2단계
단기 거래 → 레벨 2-3
스윙 댄스를 며칠 동안 춰보세요 → 레벨 3-4
장기 추세 분석 → 4~5단계
VII. 실제 적용 아이디어
웨이블릿 변환을 거래에 적용하는 방법은 매우 간단합니다. 웨이블릿 변환이 생성하는 평활화된 가격 곡선을 사용하여 추세 방향을 판단하고, 추세가 바뀔 때 거래하는 것입니다. 구체적으로, 평활화된 종가가 이전 종가보다 높으면 상승 추세를 나타내므로 매수 포지션을 취하고, 평활화된 종가가 이전 종가보다 낮으면 하락 추세를 나타내므로 포지션을 청산하거나 매도 포지션을 취합니다. 이러한 논리가 효과적인 이유는 웨이블릿이 단기적인 무작위 변동을 걸러내어 "상승" 또는 "하락"이라는 신호를 노이즈로 인한 잘못된 신호가 아닌, 실제 추세 변화를 나타낼 확률이 높은 신호로 남겨두기 때문입니다.
python
# 执行小波变换
transformed = transformer.transform_ohlc(df)
# 获取最近两根K线的平滑收盘价
w_close_current = transformed['w_close'].values[-1] # 当前平滑收盘价
w_close_prev = transformed['w_close'].values[-2] # 前一根平滑收盘价
# 判断趋势方向
signal = 0
if w_close_current > w_close_prev:
signal = 1 # 平滑价格向上 → 做多
elif w_close_current < w_close_prev:
signal = -1 # 平滑价格向下 → 做空
# 获取账户信息
account = exchange.GetAccount()
ticker = exchange.GetTicker()
if not account or not ticker:
Log("[Warning] Failed to get account/ticker info")
Sleep(5000)
continue
current_price = ticker['Last']
Log(f"[Price] 原始: {df['Close'].values[-1]:.2f}, "
f"平滑当前: {w_close_current:.2f}, 平滑前值: {w_close_prev:.2f}")
Log(f"[Trend] {'↑ 向上' if signal == 1 else '↓ 向下' if signal == -1 else '→ 横盘'}")
# 执行交易逻辑
if signal == 1 and position != 1:
# 平滑价格向上 → 做多
Log(f"[信号] 趋势向上,开多 @ {current_price:.2f}")
if position == -1:
# 先平空仓
exchange.SetDirection("closesell")
exchange.Buy(current_price, 1)
Log(f"[平仓] 平空仓")
# 开多仓
exchange.SetDirection("buy")
exchange.Buy(current_price, 1)
Log(f"[开仓] 开多仓")
position = 1
elif signal == -1 and position != -1:
# 平滑价格向下 → 做空
Log(f"[信号] 趋势向下,开空 @ {current_price:.2f}")
if position == 1:
# 先平多仓
exchange.SetDirection("closebuy")
exchange.Sell(current_price, 1)
Log(f"[平仓] 平多仓")
# 开空仓
exchange.SetDirection("sell")
exchange.Sell(current_price, 1)
Log(f"[开仓] 开空仓")
position = -1
else:
Log(f"[持仓] 当前{'多头' if position == 1 else '空头' if position == -1 else '空仓'},无需操作")
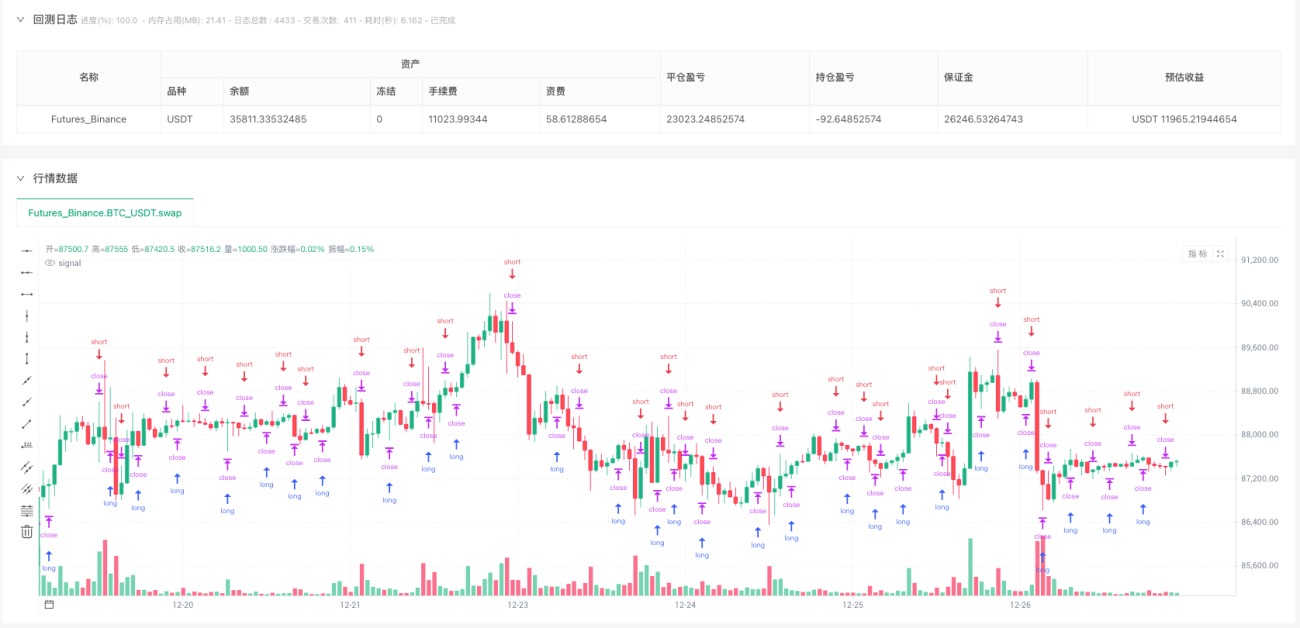
물론 실제로는 그렇게 간단하지 않습니다. 단기 추세를 보여주는 레벨 2 웨이블릿과 장기 추세를 보여주는 레벨 4 웨이블릿처럼 여러 레벨의 웨이블릿을 동시에 사용할 수 있습니다. 두 웨이블릿이 같은 방향으로 움직일 때만 포지션을 개설하면 잘못된 신호를 크게 줄일 수 있습니다. 거래량 증가, 충분히 높은 변동성, 주요 레벨 돌파와 같은 추가 필터링 조건을 적용하여 승률을 높일 수도 있습니다. 손절매 주문은 웨이블릿으로 평활화된 가격 변동 범위를 이용하여 동적으로 설정할 수 있습니다. 예를 들어, 가격이 평활화된 가격에서 평균 변동률(ATR)의 2배를 뺀 값 아래로 떨어지면 손절매되도록 설정할 수 있습니다. 포지션 관리에서는 추세가 명확할수록(평활화된 가격의 기울기가 가파를수록) 포지션 규모를 키우고, 추세가 불분명할 경우에는 작은 포지션을 유지하거나 관망하는 것이 좋습니다.
하지만 핵심 아이디어는 동일합니다. 웨이블릿을 사용하여 잡음이 섞인 가격 변동을 명확한 추세로 변환한 다음, 이러한 명확한 추세를 기반으로 판단을 내리는 것입니다. 이는 원래 캔들스틱 차트에서 직접 상승과 하락을 살펴보는 것보다 훨씬 더 신뢰할 수 있습니다. 왜냐하면 원래 캔들스틱 차트는 오늘 3% 상승하고 내일 2% 하락하고 그 다음 날 4% 상승할 수도 있기 때문입니다. 이러한 경우 추세인지 변동인지 구분하기 어렵습니다. 웨이블릿으로 처리된 곡선은 "이 기간 동안 전반적인 추세는 상승세이지만 중간에 변동이 있다"는 것을 알려줍니다.
VIII. 결론: "삼중 접근법"에 대한 합리적인 관점
실질적인 평활화 효과 측면에서 웨이블릿 변환은 금융 데이터 처리에서 중요한 역할을 할 수 있습니다. 단기적인 노이즈를 걸러내고 비교적 명확한 추세 정보를 추출하는 데 도움을 줄 수 있기 때문입니다. 그러나 이 기법에는 상당한 한계점도 존재합니다.**지연 현상은 완전히 피할 수 없습니다.**하지만 웨이블릿 변환은 과거 데이터만 처리할 수 있고 미래 추세를 예측할 수는 없습니다. 또한 웨이블릿 변환 단독 사용의 효과는 상대적으로 제한적이므로 완전한 거래 시스템을 구축하려면 다른 분석 방법 및 위험 관리 조치와 결합해야 합니다.
이러한 한계의 근본적인 원인은 금융 시장의 특수한 특성에 있습니다. 음성 인식이나 영상 처리와 같은 전통적인 신호 처리 분야에서는 잡음 특성이 비교적 안정적이고 신호 패턴이 반복되는 경향이 있어 웨이블릿 변환을 통해 신호를 잡음으로부터 효과적으로 분리할 수 있습니다. 그러나 금융 시장은 완전히 다릅니다. 오늘날 "잡음"으로 여겨지는 변동이 내일은 시장 변화를 반영하는 "신호"가 될 수 있고, 현재 효과적인 분석 모델이 미래에는 비효과적이 될 수도 있습니다.**시장 자체는 고정되어 있지 않고 역동적으로 변화합니다.**웨이블릿 변환에는 불변의 법칙이 없으므로 금융 분야에서 웨이블릿 변환을 적용할 때는 특정한 시장 환경에 따라 유연하게 조정해야 합니다.
누군가가 웨이블릿 변환과 푸리에 변환의 실제 효과를 과장하는 것을 보면 다음과 같은 질문을 해보세요. 어떤 웨이블릿 유형을 사용했나요? 다른 유형이 아닌 이 유형을 선택한 근거는 무엇인가요? 평활화 수준은 어떻게 설정했나요? 해당 백테스팅 결과와 파라미터 선택 절차가 있나요?진정한 전문 지식을 갖춘 사람들은 이러한 핵심적인 기술적 세부 사항을 명확하게 설명할 수 있을 것입니다.
우리가 가진 제한적인 지식을 바탕으로, 본 실증적 탐구를 수행했습니다.**핵심 아이디어는 웨이블릿 변환의 응용 개념을 간단하고 이해하기 쉬운 방식으로 공유하는 것입니다.**이 글은 독자들이 해당 기술에 대한 기본적인 이해를 돕는 것을 목표로 합니다. 저희는 이 분야에 깊이 몰두하는 양적 연구자들을 매우 존경하며, 해당 분야의 전문가이시라면 웨이블릿 파라미터 선택의 이론적 근거, 다중 스케일 조합 최적화 방법, 적응형 웨이블릿 선택 구현 방안 등 이 글의 부족한 부분을 지적해 주시면 감사하겠습니다. 여러분의 의견을 겸허히 수용하여 지속적으로 내용을 개선해 나가겠습니다.
그래프 작성 기능: 발명가의 로컬 백테스팅 엔진에 적용됨
python
'''backtest
start: 2025-12-17 00:00:00
end: 2025-12-23 08:00:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","fee":[0,0]}]
'''
from fmz import *
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
task = VCtx(__doc__)
# ==================== 小波系数库 ====================
class WaveletCoefficients:
"""Wavelet Coefficients Definition"""
@staticmethod
def get_coeffs(wavelet_name):
"""Get coefficients for different wavelet types"""
coeffs = {
"Haar": [0.5, 0.5],
"Daubechies 4": [
0.48296291314453414,
0.8365163037378079,
0.22414386804201339,
-0.12940952255126037
],
"Symlet 4": [
-0.05357, -0.02096, 0.35238,
0.56833, 0.21062, -0.07007,
-0.01941, 0.03268
],
"Biorthogonal 3.3": [
-0.06629, 0.28289, 0.63678,
0.28289, -0.06629
],
"Mexican Hat (Ricker)": [
-0.1, 0.0, 0.4, 0.8, 0.4, 0.0, -0.1
],
"Morlet (Gaussian)": [
0.0625, 0.25, 0.375, 0.25, 0.0625
],
"Discrete Meyer (Dmey)": [
-0.015, -0.025, 0.0,
0.28, 0.52, 0.28,
0.0, -0.025, -0.015
]
}
return coeffs.get(wavelet_name, coeffs["Mexican Hat (Ricker)"])
# ==================== 小波变换引擎 ====================
class WaveletTransform:
"""Wavelet Transform Engine"""
def __init__(self, wavelet_type="Mexican Hat (Ricker)", smoothing_level=3):
self.wavelet_type = wavelet_type
self.smoothing_level = smoothing_level
self.coeffs = WaveletCoefficients.get_coeffs(wavelet_type)
def convolve(self, src, coeffs, step):
"""
Convolution operation - Core algorithm
Args:
src: Source data sequence
coeffs: Wavelet coefficients
step: Sampling step
Returns:
Convolved value
"""
sum_val = 0.0
sum_w = 0.0
for i, weight in enumerate(coeffs):
idx = i * step
if idx < len(src):
val = src[idx]
sum_val += val * weight
sum_w += weight
# Normalization - Critical fix
return sum_val / sum_w if sum_w != 0 else sum_val
def calc_level(self, data, target_level):
"""
Calculate wavelet transform for specified level
Args:
data: Original data array
target_level: Target smoothing level
Returns:
Transformed data array
"""
result = []
coeffs = self.coeffs
for i in range(len(data)):
# Get data from current position backwards
src = data[max(0, i - 50):i + 1][::-1]
# Level 1
val = self.convolve(src, coeffs, 1)
# Level 2
if target_level >= 2:
src_temp = [val] + [self.convolve(data[max(0, j - 50):j + 1][::-1], coeffs, 1)
for j in range(max(0, i - 10), i)][::-1]
val = self.convolve(src_temp, coeffs, 2)
# Level 3
if target_level >= 3:
val = self.convolve([val] * len(coeffs), coeffs, 4)
# Level 4+
if target_level >= 4:
val = self.convolve([val] * len(coeffs), coeffs, 8)
result.append(val)
return np.array(result)
def transform_ohlc(self, df):
"""
Perform wavelet transform on OHLC data
Args:
df: DataFrame with Open/High/Low/Close
Returns:
Transformed DataFrame
"""
result_df = df.copy()
# Transform each price series
result_df['w_open'] = self.calc_level(df['Open'].values, self.smoothing_level)
result_df['w_high'] = self.calc_level(df['High'].values, self.smoothing_level)
result_df['w_low'] = self.calc_level(df['Low'].values, self.smoothing_level)
result_df['w_close'] = self.calc_level(df['Close'].values, self.smoothing_level)
# Reconstruct logically consistent candlesticks
result_df['real_high'] = result_df[['w_high', 'w_low', 'w_open', 'w_close']].max(axis=1)
result_df['real_low'] = result_df[['w_high', 'w_low', 'w_open', 'w_close']].min(axis=1)
return result_df
# ==================== K线图可视化工具 ====================
class WaveletCandlestickVisualizer:
"""Wavelet Candlestick Visualization"""
@staticmethod
def plot_single_wavelet(df, wavelet_type, smoothing_level=3, n_bars=200):
"""
Plot single wavelet type comparison
Args:
df: Original candlestick data
wavelet_type: Wavelet type
smoothing_level: Smoothing level
n_bars: Number of bars to display
"""
# Take only last n_bars
df_plot = df.iloc[-n_bars:].copy()
# Create figure
fig, ax = plt.subplots(figsize=(20, 8))
# Perform wavelet transform
transformer = WaveletTransform(wavelet_type, smoothing_level)
transformed = transformer.transform_ohlc(df)
transformed_plot = transformed.iloc[-n_bars:].copy()
# Draw original candlesticks (gray background)
WaveletCandlestickVisualizer._draw_candlesticks(
ax, df_plot,
color_up='lightgray',
color_down='lightgray',
alpha=0.3,
label='Original Candles'
)
# Draw wavelet smoothed candlesticks
WaveletCandlestickVisualizer._draw_candlesticks(
ax, transformed_plot,
use_wavelet=True,
color_up='#26A69A', # Green
color_down='#EF5350', # Red
alpha=0.9,
linewidth=1.2,
label=f'{wavelet_type} Smoothed (Level {smoothing_level})'
)
# Set title and labels
ax.set_title(f'{wavelet_type} Wavelet (Level {smoothing_level}) - Candlestick Comparison',
fontsize=16, fontweight='bold', pad=20)
ax.set_ylabel('Price (USDT)', fontsize=13)
ax.set_xlabel('Time', fontsize=13)
ax.grid(True, alpha=0.2, linestyle='--')
ax.legend(loc='upper left', fontsize=12)
# Format x-axis
ax.set_xlim(-1, len(df_plot))
ax.set_xticks(range(0, len(df_plot), max(1, len(df_plot) // 10)))
ax.set_xticklabels([df_plot.index[i].strftime('%m-%d %H:%M')
for i in range(0, len(df_plot), max(1, len(df_plot) // 10))],
rotation=45, ha='right')
plt.tight_layout()
plt.show()
return fig
@staticmethod
def plot_single_level(df, wavelet_type, level, n_bars=200):
"""
Plot single smoothing level
Args:
df: Original candlestick data
wavelet_type: Wavelet type
level: Smoothing level
n_bars: Number of bars to display
"""
# Take only last n_bars
df_plot = df.iloc[-n_bars:].copy()
# Create figure
fig, ax = plt.subplots(figsize=(20, 8))
# Perform wavelet transform
transformer = WaveletTransform(wavelet_type, level)
transformed = transformer.transform_ohlc(df)
transformed_plot = transformed.iloc[-n_bars:].copy()
# Draw original candlesticks
WaveletCandlestickVisualizer._draw_candlesticks(
ax, df_plot,
color_up='lightgray',
color_down='lightgray',
alpha=0.3,
label='Original Candles'
)
# Draw wavelet smoothed candlesticks
WaveletCandlestickVisualizer._draw_candlesticks(
ax, transformed_plot,
use_wavelet=True,
color_up='#26A69A',
color_down='#EF5350',
alpha=0.9,
linewidth=1.2,
label=f'Level {level} Smoothed'
)
# Set title and labels
ax.set_title(f'{wavelet_type} - Smoothing Level {level} Effect',
fontsize=16, fontweight='bold', pad=20)
ax.set_ylabel('Price (USDT)', fontsize=13)
ax.set_xlabel('Time', fontsize=13)
ax.grid(True, alpha=0.2, linestyle='--')
ax.legend(loc='upper left', fontsize=12)
# Format x-axis
ax.set_xlim(-1, len(df_plot))
ax.set_xticks(range(0, len(df_plot), max(1, len(df_plot) // 10)))
ax.set_xticklabels([df_plot.index[i].strftime('%m-%d %H:%M')
for i in range(0, len(df_plot), max(1, len(df_plot) // 10))],
rotation=45, ha='right')
plt.tight_layout()
plt.show()
return fig
@staticmethod
def _draw_candlesticks(ax, df, use_wavelet=False, color_up='green',
color_down='red', alpha=1.0, linewidth=1.0, label=''):
"""
Draw candlestick chart
Args:
ax: Matplotlib axis
df: Data DataFrame
use_wavelet: Whether to use wavelet data
color_up: Up color
color_down: Down color
alpha: Transparency
linewidth: Line width
label: Legend label
"""
if use_wavelet:
opens = df['w_open'].values
highs = df['real_high'].values
lows = df['real_low'].values
closes = df['w_close'].values
else:
opens = df['Open'].values
highs = df['High'].values
lows = df['Low'].values
closes = df['Close'].values
for i in range(len(df)):
x = i
open_price = opens[i]
high_price = highs[i]
low_price = lows[i]
close_price = closes[i]
color = color_up if close_price >= open_price else color_down
# Draw wick
ax.plot([x, x], [low_price, high_price],
color=color, linewidth=linewidth, alpha=alpha)
# Draw body
height = abs(close_price - open_price)
bottom = min(open_price, close_price)
rect = Rectangle((x - 0.3, bottom), 0.6, height,
facecolor=color, edgecolor=color,
alpha=alpha, linewidth=linewidth)
ax.add_patch(rect)
# Add legend (only once)
if label:
ax.plot([], [], color=color_up, linewidth=3, alpha=alpha, label=label)
# ==================== 主函数 ====================
def main():
"""Main execution flow"""
exchange.SetCurrency("BTC_USDT")
exchange.SetContractType("swap")
# Get candlestick data
records = exchange.GetRecords(PERIOD_H1, 500)
# Convert to DataFrame
df = pd.DataFrame(records, columns=['Time', 'Open', 'High', 'Low', 'Close', 'Volume'])
df['Time'] = pd.to_datetime(df['Time'], unit='ms')
df.set_index('Time', inplace=True)
print(f"Data loaded: {len(df)} bars")
print(f"Time range: {df.index[0]} to {df.index[-1]}")
print(f"Price range: ${df['Low'].min():.2f} - ${df['High'].max():.2f}")
return df
# ==================== 执行绘图 ====================
try:
# Get candlestick data
kline = main()
print("\n" + "="*70)
print("Generating Wavelet Candlestick Charts (Each in Separate Window)...")
print("="*70)
# ========== Chart Series 1: Different Wavelet Types ==========
print("\n[Series 1] Comparing Different Wavelet Types")
print("-" * 70)
wavelet_types = [
"Haar",
"Daubechies 4",
"Symlet 4",
"Biorthogonal 3.3",
"Mexican Hat (Ricker)",
"Morlet (Gaussian)",
"Discrete Meyer (Dmey)" # ✅ 添加了 Discrete Meyer
]
for i, wavelet_type in enumerate(wavelet_types, 1):
print(f" Chart {i}/{len(wavelet_types)}: {wavelet_type}")
fig = WaveletCandlestickVisualizer.plot_single_wavelet(
kline,
wavelet_type=wavelet_type,
smoothing_level=3,
n_bars=150
)
# ========== Chart Series 2: Different Smoothing Levels ==========
print("\n[Series 2] Comparing Different Smoothing Levels")
print("-" * 70)
levels = [1, 2, 3, 4, 5]
for i, level in enumerate(levels, 1):
print(f" Chart {i}/5: Level {level}")
fig = WaveletCandlestickVisualizer.plot_single_level(
kline,
wavelet_type="Mexican Hat (Ricker)",
level=level,
n_bars=150
)
print("\n" + "="*70)
print("All charts generated successfully!")
print(f"Total charts: {len(wavelet_types) + len(levels)} ({len(wavelet_types)} wavelets + {len(levels)} levels)")
print("="*70)
except Exception as e:
print(f"Error: {str(e)}")
import traceback
print(traceback.format_exc())
finally:
print("\nStrategy testing completed.")
거래 기능: Inventors 플랫폼에서 적용됨
python
'''backtest
start: 2025-01-17 00:00:00
end: 2025-12-23 08:00:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","fee":[0,0]}]
'''
import numpy as np
import pandas as pd
# ==================== 小波系数库 ====================
class WaveletCoefficients:
"""与上部分函数一致"""
# ==================== 小波变换引擎 ====================
class WaveletTransform:
"""与上部分函数一致"""
def main():
"""小波交易主函数 - 基于平滑价格趋势"""
# ========== 配置参数 ==========
WAVELET_TYPE = "Mexican Hat (Ricker)" # 小波类型
SMOOTHING_LEVEL = 1 # 平滑阶数
# 初始化
exchange.SetCurrency("BTC_USDT")
exchange.SetContractType("swap")
Log(f"=" * 70)
Log(f"Wavelet Trend Following Strategy")
Log(f"Wavelet: {WAVELET_TYPE}, Level: {SMOOTHING_LEVEL}")
Log(f"Logic: 平滑收盘价向上→做多, 平滑收盘价向下→做空")
Log(f"=" * 70)
# 初始化小波变换器
transformer = WaveletTransform(WAVELET_TYPE, SMOOTHING_LEVEL)
# 持仓状态
position = 0 # 0: 无持仓, 1: 多头, -1: 空头
while True:
# 获取K线数据
records = exchange.GetRecords(PERIOD_H1, 500)
if not records:
Log("[Warning] Failed to get kline data")
Sleep(5000)
continue
df = pd.DataFrame(records, columns=['Time', 'Open', 'High', 'Low', 'Close', 'Volume'])
df['Time'] = pd.to_datetime(df['Time'], unit='ms')
df.set_index('Time', inplace=True)
# 执行小波变换
transformed = transformer.transform_ohlc(df)
# 获取最近两根K线的平滑收盘价
w_close_current = transformed['w_close'].values[-1] # 当前平滑收盘价
w_close_prev = transformed['w_close'].values[-2] # 前一根平滑收盘价
# 判断趋势方向
signal = 0
if w_close_current > w_close_prev:
signal = 1 # 平滑价格向上 → 做多
elif w_close_current < w_close_prev:
signal = -1 # 平滑价格向下 → 做空
# 获取账户信息
account = exchange.GetAccount()
ticker = exchange.GetTicker()
if not account or not ticker:
Log("[Warning] Failed to get account/ticker info")
Sleep(5000)
continue
current_price = ticker['Last']
Log(f"[Price] 原始: {df['Close'].values[-1]:.2f}, "
f"平滑当前: {w_close_current:.2f}, 平滑前值: {w_close_prev:.2f}")
Log(f"[Trend] {'↑ 向上' if signal == 1 else '↓ 向下' if signal == -1 else '→ 横盘'}")
# 执行交易逻辑
if signal == 1 and position != 1:
# 平滑价格向上 → 做多
Log(f"[信号] 趋势向上,开多 @ {current_price:.2f}")
if position == -1:
# 先平空仓
exchange.SetDirection("closesell")
exchange.Buy(current_price, 1)
Log(f"[平仓] 平空仓")
# 开多仓
exchange.SetDirection("buy")
exchange.Buy(current_price, 1)
Log(f"[开仓] 开多仓")
position = 1
elif signal == -1 and position != -1:
# 平滑价格向下 → 做空
Log(f"[信号] 趋势向下,开空 @ {current_price:.2f}")
if position == 1:
# 先平多仓
exchange.SetDirection("closebuy")
exchange.Sell(current_price, 1)
Log(f"[平仓] 平多仓")
# 开空仓
exchange.SetDirection("sell")
exchange.Sell(current_price, 1)
Log(f"[开仓] 开空仓")
position = -1
else:
Log(f"[持仓] 当前{'多头' if position == 1 else '空头' if position == -1 else '空仓'},无需操作")
Log(f"[账户] 余额: {account['Balance']:.2f}, 权益: {account['Equity']:.2f}")
Log("-" * 70)
Sleep(60000 * 60)
- 1