
FMZ 플랫폼에 파이썬 크롤러를 적용한 예비 연구 - 바이낸스 공지사항 콘텐츠 크롤링
저는 최근 커뮤니티와 라이브러리를 살펴봤는데, QUANT의 포괄적인 개발 정신에 기초한 Python 크롤러에 대한 관련 정보가 전혀 없었습니다. 크롤러와 관련된 개념과 지식을 매우 간단하게 배웠습니다. 이에 대해 더 자세히 알게 된 후, 저는 "크롤러 기술"이 꽤 큰 "구덩이"라는 것을 알게 되었습니다. 이 글은 단지 "크롤러 기술"에 대한 예비적인 탐구일 뿐입니다. FMZ 양적 거래 플랫폼에서 크롤러 기술의 가장 간단한 연습을 해보겠습니다.
필요
새로운 코인에 투자하고 싶어 하는 트레이더들은 항상 거래소에 상장된 코인에 대한 정보를 가능한 한 빨리 얻기를 바랄 것입니다. 수동으로 거래소 웹사이트를 감시하는 것은 분명히 비현실적입니다. 그런 다음 크롤러 스크립트를 사용하여 거래소 공지 페이지를 모니터링하고 새로운 공지 사항을 감지하여 가능한 한 빨리 알림과 알림을 받아야 합니다.
초기 탐색
매우 간단한 프로그램으로 시작해 보겠습니다(진정으로 강력한 크롤러 스크립트는 훨씬 더 복잡하므로 시간을 들여 살펴보세요). 이 프로그램의 논리는 매우 간단합니다. 즉, 프로그램이 거래소의 공지 페이지에 지속적으로 접근하여 얻은 HTML 콘텐츠를 구문 분석하고 특정 태그의 콘텐츠가 업데이트되었는지 감지하도록 하는 것입니다.
구현 코드
몇 가지 유용한 크롤러 프레임워크를 사용할 수 있습니다. 하지만 요구 사항이 매우 간단하다는 점을 고려하면 직접 작성하는 것도 가능합니다.
Python 라이브러리가 필요합니다:
requests, 간단히 말하면 웹 페이지에 접근하는 데 사용되는 라이브러리라고 이해할 수 있습니다.
bs4이는 웹 페이지의 HTML 코드를 구문 분석하는 데 사용되는 라이브러리라고 간단히 이해할 수 있습니다.
암호:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
달리다
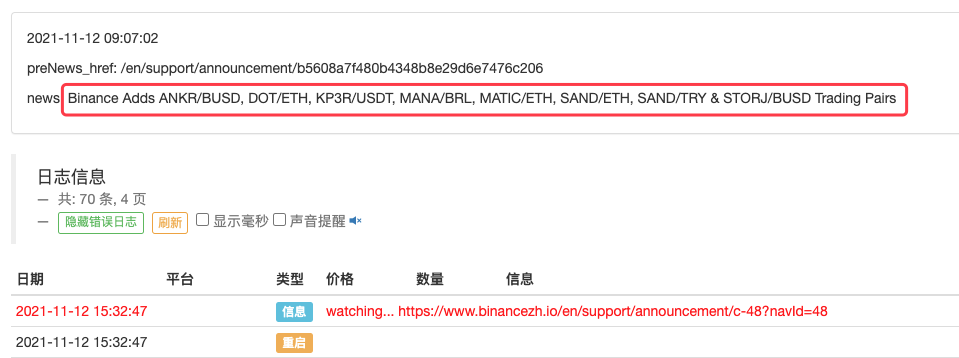
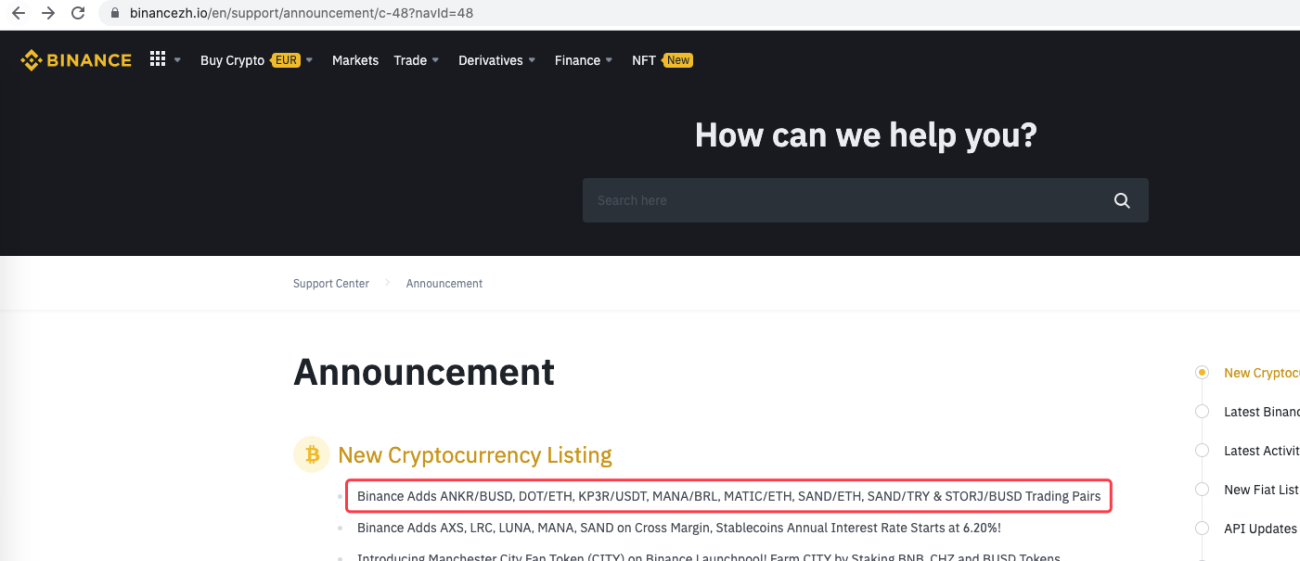
예를 들어, 새로운 공지가 나올 때 감지하도록 확장할 수도 있습니다. 공지사항에 나온 신규 통화를 분석하고 자동으로 새로운 거래에 대한 주문을 내립니다.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1