

Pengelas matang: Mesin Vektor Sokongan (SVM) ialah algoritma pengelasan binari (atau multivariat) yang berkuasa dan matang. Meramalkan sama ada saham akan naik atau turun adalah masalah klasifikasi binari biasa.
Keupayaan bukan linear: Dengan menggunakan fungsi kernel (seperti kernel RBF), SVM boleh menangkap hubungan bukan linear yang kompleks antara ciri input, yang penting untuk data pasaran kewangan.
Didorong ciri: Keberkesanan model bergantung pada "ciri" yang anda suapkan. Faktor alfa yang dikira sekarang ialah permulaan yang baik, dan kami boleh membina lebih banyak ciri sedemikian untuk meningkatkan kuasa ramalan.
Kali ini saya mulakan dengan 3 garis besar ciri:
1: Ciri aliran tertib frekuensi tinggi:
alpha_1min: Faktor ketidakseimbangan aliran pesanan dikira berdasarkan semua tanda pada minit yang lalu.
alpha_5min: Faktor ketidakseimbangan aliran pesanan dikira berdasarkan semua tanda dalam 5 minit yang lalu.
alpha_15min: Faktor ketidakseimbangan aliran pesanan dikira berdasarkan semua tanda dalam 15 minit yang lalu.
ofi_1min (Ketidakseimbangan Aliran Pesanan): Nisbah (volume beli / volum jual) dalam tempoh 1 minit. Ini lebih langsung daripada alpha.
vol_per_trade_1min: Purata volum setiap dagangan dalam masa 1 minit. Tanda pesanan besar memberi kesan kepada pasaran.
2: Harga dan ciri turun naik:
log_return_5min: Kadar pulangan logaritma sepanjang 5 minit yang lalu, log(P_t / P_{t-5min}).
volatiliti_15min: Sisihan piawai log kembali sepanjang 15 minit yang lalu, ukuran turun naik jangka pendek.
atr_14 (Julat Sebenar Purata): Nilai ATR berdasarkan 14 batang lilin 1 minit yang lalu, penunjuk turun naik klasik.
rsi_14 (Indeks Kekuatan Relatif): Ini ialah ukuran keadaan terlebih beli dan terlebih jual berdasarkan nilai RSI 14 batang lilin 1 minit yang lalu.
3: Ciri-ciri masa:
jam_hari: Jam semasa (0-23). Pasaran berkelakuan berbeza dalam tempoh masa yang berbeza (mis., sesi Asia/Eropah/Amerika).
day_of_week: Hari dalam seminggu (0-6). Hujung minggu dan hari bekerja mempunyai corak turun naik yang berbeza.
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
Kemudian gunakan tiga kategori untuk membezakan antara naik, turun dan sisi.
Idea teras penapisan ciri: Cari "rakan sepasukan yang baik" dan hapuskan "rakan sepasukan yang buruk"
Matlamat kami adalah untuk mencari satu set ciri yang:
- Perkaitan Tinggi: Setiap ciri mempunyai korelasi yang kuat dengan perubahan harga masa hadapan (label sasaran kami).
- Lebihan Rendah: Ciri tidak boleh mengandungi terlalu banyak maklumat pendua. Contohnya, "momentum 5 minit" dan "momentum 6 minit" adalah sangat serupa. Memasukkan kedua-duanya tidak akan menambah baik model malah boleh menimbulkan bunyi bising.
- Kestabilan: Kesahihan ciri tidak boleh berubah terlalu cepat dari semasa ke semasa. Ciri yang hanya sah sehari adalah berbahaya.
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
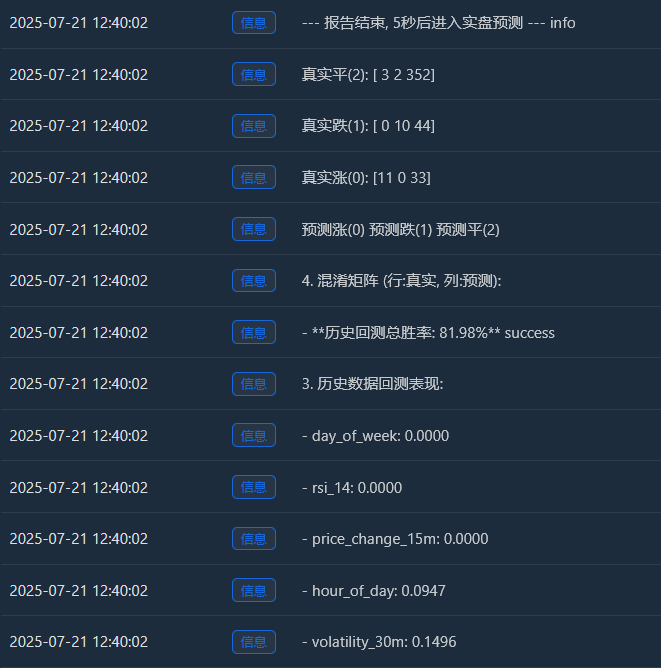
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
Prosesnya ialah:
Mengumpul data
Kepentingan Ciri

Maklumat bersama antara ciri dan label dan maklumat ujian belakang
Pada asalnya saya fikir kadar kemenangan 65% sudah memadai, tetapi saya tidak menjangka ia mencapai 81.98%. Reaksi pertama saya sepatutnya: "Itu bagus, tetapi ia terlalu bagus untuk menjadi kenyataan. Pasti ada sesuatu yang patut diterokai di sini."
1. Tafsiran mendalam laporan analisis, mentafsir kandungan laporan satu demi satu:
- Kepentingan Ciri & Maklumat Bersama:
Volatiliti_30m dan price_change_15m ialah ciri yang paling penting. Ini adalah logik, menunjukkan bahawa trend pasaran baru-baru ini dan turun naik adalah peramal masa depan yang paling kuat.
The hour_of_day juga menyumbang sedikit, menunjukkan bahawa model itu menangkap corak dagangan pada masa yang berbeza dalam sehari.
Sumbangan rsi_14 dan day_of_week hampir 0, yang menunjukkan bahawa kedua-dua ciri ini mungkin "rakan sepasukan babi" di bawah set data semasa dan gabungan ciri. Kami boleh mempertimbangkan untuk mengalih keluarnya pada masa hadapan untuk memudahkan model dan mengelakkan bunyi bising. - Matriks Kekeliruan (ini adalah banyak maklumat!)
Peningkatan sebenar (0):[11 0 33] -> Daripada 44 (11+0+33) rali sebenar, model itu telah meramalkan 11 dengan betul, tetapi salah meramalkannya sebagai "penyatuan" sebanyak 33 kali.
Penurunan sebenar (1):[0 10 44] -> Daripada 54 (0+10+44) kemerosotan sebenar, model itu telah meramalkan 10 dengan betul, tetapi tersilap meramalkannya sebagai "aliran sisi" sebanyak 44 kali.
Ping Sebenar (2):[3 2 352] -> Daripada 357 (3+2+352) penyatuan sebenar, model itu meramalkan 352 daripadanya dengan betul! - Kadar kemenangan jumlah ujian belakang sejarah: 81.98%
Sumber teras kadar kemenangan yang tinggi ini ialah ketepatan model yang sangat tinggi dalam meramalkan "penggabungan"! Di antara sejumlah kira-kira 455 sampel, lebih daripada 350 adalah pasaran penyatuan, dan model itu mengenal pastinya dengan hampir sempurna.
Ini adalah kebolehan yang sangat berharga itu sendiri! Model yang boleh memberitahu anda dengan tepat "lebih baik jangan bergerak sekarang" boleh membantu anda menjimatkan banyak yuran dan transaksi tidak sah.
2Mengapakah kadar kemenangan sebenar mungkin lebih rendah daripada 81.98%?
- Takrifan "penyatuan" terlalu longgar: SPREAD_THRESHOLD kami ialah 0.5%. Turun naik harga tidak lebih daripada 0.5% dalam tempoh 15 minit adalah perkara biasa. Akibatnya, sampel "penyatuan" menyumbang sebahagian besar (kira-kira 80%) set data kami. Model itu telah belajar dengan bijak, "Apabila saya tidak pasti, teka 'penyatuan' dengan ketepatan yang tinggi." Ini betul secara statistik, tetapi dalam perdagangan, kami lebih prihatin dengan meramalkan pergerakan harga.
- Keupayaan untuk meramal naik dan turun:
Kadar kemenangan meramalkan aliran menaik: Model meramalkan 11 + 0 + 3 = 14 aliran menaik, yang mana hanya 11 yang betul. Kadar kemenangan ialah 11 / 14 = 78.5%. Cemerlang!
Kadar kemenangan meramalkan penurunan: Model meramalkan 0 + 10 + 2 = 12 penurunan, dan betul 10 daripadanya. Kadar kemenangan ialah 10 / 12 = 83.3%. Sekali lagi, sangat mengagumkan! - In-Sample Overfitting: Ujian ini dilakukan pada data yang "dikenali" oleh model (iaitu, data yang digunakan untuk latihan dan ujian). Ini seperti meminta pelajar membuat ujian yang baru sahaja mereka selesaikan; markah biasanya akan tinggi. Prestasi model pada data baharu yang tidak kelihatan (dagangan langsung) hampir sentiasa lebih rendah daripada skor ini.
Kami kini mempunyai "Model Alpha" awal, namun berpotensi besar. Walaupun kami tidak dapat mentafsir angka 81.98% secara langsung sebagai ramalan realistik untuk masa hadapan, ia merupakan isyarat positif yang kuat, menunjukkan bahawa corak boleh diramal memang wujud dalam data dan rangka kerja kami telah berjaya menangkapnya!
Kami kini berasa seperti baru menjumpai bijih emas berkualiti tinggi pertama di kaki gunung. Langkah seterusnya kami bukanlah menjualnya serta-merta, tetapi menggunakan alat dan teknik yang lebih khusus (mengoptimumkan ciri dan melaraskan parameter) untuk melombong seluruh gunung dengan lebih cekap dan stabil.
Sekarang mari kita perkenalkan kabus perang dalam "mikrokosmos" — aliran pesanan dan ciri buku pesanan
Langkah 1: Tingkatkan pengumpulan data - langgan saluran yang lebih mendalam
Untuk mendapatkan data buku pesanan, kaedah sambungan WebSocket mesti diubah suai daripada hanya melanggan aggTrade (urusan) kepada melanggan kedua-dua aggTrade dan depth (depth).
Ini memerlukan kami menggunakan URL langganan berbilang strim yang lebih umum.
Langkah 2: Tingkatkan kejuruteraan ciri - bina matriks ciri triniti untuk "laut, darat dan udara"
Kami akan menambah ciri baharu berikut pada fungsi calculate_features_and_labels:
- Ciri Aliran Pesanan (Alfa - Pendek):
alpha_15m: Faktor ketidakseimbangan aliran pesanan 15 minit. Ini ialah metrik aliran pesanan teras yang kami bincangkan sebelum ini. - Ciri-ciri Buku Pesanan (Buku - Tentera):
wobi_10s: Ketidakseimbangan Buku Pesanan Berwajaran sepanjang 10 saat yang lalu. Ini adalah penunjuk frekuensi sangat tinggi yang mengukur tekanan belian dan jualan di pasaran.
spread_10s: Purata tebaran bida-tanya sepanjang 10 saat yang lalu. Mencerminkan kecairan jangka pendek. - Ciri asal (Harga - Tentera Laut):
Kami akan mengekalkan ciri berprestasi terbaik daripada versi sebelumnya dan mengoptimumkannya.
Matriks ciri baharu ini adalah seperti arahan tempur bersama, yang pada masa yang sama menangkap risikan masa nyata daripada "laut (trend harga)", "darat (kedudukan pasaran)" dan "udara (kesan urus niaga)", dan keupayaan membuat keputusannya akan jauh lebih baik daripada sebelumnya.
Kodnya adalah seperti berikut:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
Kod ini memerlukan banyak pengiraan K-line
Laporan ini bernilai banyak, kerana ia memberitahu kita "pemikiran" dan "watak" model.
- Kadar kemenangan ujian belakang sejarah: 93.33%
Ini adalah angka yang sangat mengagumkan! Walaupun kita perlu melihatnya secara objektif (ini adalah ujian dalam sampel), ia jelas menunjukkan kuasa ramalan yang besar bagi ciri aliran pesanan dan buku pesanan kami yang baru ditambah! Model ini telah menemui corak yang sangat kuat dalam data sejarah. - Kepentingan Ciri & Maklumat Bersama
Raja dilahirkan: volatiliti_15m (volatiliti) dan price_change_5m (perubahan harga) masih menjadi teras sepenuhnya, seperti yang dijangkakan.
Bintang Terbit: rsi_14 telah menyaksikan peningkatan ketara dalam kepentingan! Ini menunjukkan bahawa pada jangka masa 5 minit yang lebih pendek, penunjuk sentimen "terlebih beli/terlebih jual" RSI telah menjadi lebih bermakna.
Berkemungkinan, wobi_10s (order book imbalance) dan spread_10s (spread) juga menunjukkan sedikit sumbangan. Ini sangat menggalakkan dan mencadangkan ciri struktur mikro kami mula berfungsi!
Refleksi: Sumbangan alpha_5m (aliran pesanan) hampir sifar. Ini mungkin disebabkan oleh terlalu memudahkan kaedah pengiraan alfa kami, atau alfa 5 minit dan perubahan harga 5 minit itu sendiri mengandungi terlalu banyak maklumat bertindih. Ini adalah titik pengoptimuman yang penting untuk kami pada masa hadapan. - Matriks Kekeliruan (bukti utama kejayaan!)
Peningkatan sebenar (0):[22 0] -> Dalam kesemua 22 perhimpunan sebenar, model itu meramalkannya 100% betul, tanpa sebarang kesilapan!
Penurunan sebenar (1):[2 6] -> Daripada 8 penurunan sebenar, model meramalkan 6 dengan betul dan terlepas 2 (tersalah anggap sebagai peningkatan).
Tafsiran: Model ini mempamerkan personaliti yang sangat menarik: ia merupakan pengesan kenaikkan harga yang sangat kuat, menangkap isyarat kenaikkan harga hampir sempurna. Ia juga menunjukkan prestasi yang baik dalam mengenal pasti arah aliran menurun (6/8 = 75% ketepatan), tetapi kadangkala membuat kesilapan dengan tersilap arah aliran menurun untuk aliran menaik.
Kemudian apa yang seterusnya
Memperkenalkan "Mesin Keadaan Isyarat Dagangan"
Ini adalah bahagian teras dan paling bijak dalam peningkatan ini. Kami akan memperkenalkan pembolehubah keadaan global, seperti g_active_signal, untuk mengurus status "kedudukan" semasa strategi (perhatikan bahawa ini hanya status kedudukan maya dan tidak melibatkan dagangan sebenar).
Logik kerja mesin keadaan ini adalah seperti berikut:
- Keadaan awal: Terbiar
- Apabila strategi berada dalam keadaan ini, ia akan membuat ramalan untuk setiap K-line baharu, sama seperti sekarang.
- Peralihan Rejim: Setelah model meramalkan isyarat yang jelas (cth., “Naik”), strategi akan:
- Mencetak isyarat kemasukan tunggal yang menarik perhatian ke jurnal, sebagai contoh, 🎯 Isyarat dagangan baharu: Ramalan meningkat! Tempoh pemerhatian 15 minit.
- Menukar status strategi daripada Idle kepada In-Signal.
Catatkan masa dan arah pencetus isyarat semasa.
- Status Kedudukan: Dalam Isyarat
- Apabila strategi berada dalam keadaan ini, ia akan berhenti sepenuhnya meramal garis K baharu. Ia tidak lagi mengambil berat tentang turun naik setiap minit dan memasuki mod "let the bullet fly".
- Satu-satunya perkara yang dilakukan ialah menyemak masa: sama ada 15 minit (panjang PREDICT_HORIZON) telah berlalu sejak isyarat dicetuskan.
- Peralihan Negeri: Selepas tempoh pemerhatian selama 15 minit, polisi akan:
- Cetak isyarat keluar yang jelas ke log, seperti penghujung tempoh isyarat 🏁. Tetapkan semula strategi dan cari peluang baharu...
- Menukar status strategi daripada menahan kepada melahu.
- Pada ketika ini, strategi akan mula meramalkan K-line baharu dan mencari peluang dagangan seterusnya.
Dengan mesin keadaan ringkas ini, kami telah mencapai keperluan dengan sempurna: satu isyarat, satu kitaran pemerhatian lengkap, dan tiada maklumat gangguan dalam tempoh tersebut.
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
Kemudian saya menjalankan kod ini
Analisis mendalam: Mengapakah kadar kemenangan 100% "sempurna" wujud?
Keputusan "sempurna" ini mendedahkan beberapa cerapan penting dan mendalam tentang pembelajaran mesin dan pasaran kewangan. Ia bukan pepijat, sebaliknya fenomena biasa yang dikenali sebagai "overfitting," yang boleh berlaku dalam keadaan tertentu.
Apakah maksud "overfitting"?
-
Berikut ialah analogi yang jelas: Bayangkan kami mempunyai seorang pelajar (model SVM kami) melakukan satu set latihan yang sangat singkat dan sangat mudah (200 titik data candlestick yang kami kumpulkan). Pelajar ini sangat pintar, dan bukannya mempelajari kaedah penyelesaian masalah umum, mereka hanya menghafal jawapan kepada beberapa masalah ini.
-
Keputusan: Apabila kami mengujinya dengan set soalan latihan yang sama (ini adalah "ujian belakang sejarah"), dia pastinya boleh mendapat skor sempurna 100. Walau bagaimanapun, sebaik sahaja kami memberinya satu set soalan yang benar-benar baru yang tidak pernah dilihatnya sebelum ini (pasaran masa depan sebenar), dia mungkin tidak dapat menjawab mana-mana soalan itu.
- Mengapa model kami "terlebih"?
-
Sampel latihan adalah "terlalu sedikit" dan "terlalu istimewa":
-
Walaupun kami mengumpul 200 K-lines (kira-kira 3.3 jam), mengikut log, bilangan akhir sampel "kenaikan dan penurunan berkesan" yang memenuhi definisi kami hanyalah 18 + 7 = 25.
-
Untuk model SVM yang kompleks, 25 sampel adalah seperti beberapa gelombang di lautan, yang terlalu kecil.
-
Lebih penting lagi, 25 sampel ini semuanya datang daripada situasi pasaran yang sangat berkorelasi pada petang yang sama. Mereka berkemungkinan mempunyai "rutin" yang hampir sama.
- Keupayaan model "terlalu kuat":
- SVM ialah pengelas tak linear yang sangat berkuasa. Keupayaannya seperti otak yang mempunyai memori super.
- Apabila model yang berkuasa belajar daripada set data yang terlalu mudah dan berulang, model itu cenderung untuk "menghafal" semua butiran dan bunyi data daripada mempelajari undang-undang makro yang lebih universal di belakangnya.
- Bukti dari matriks kekeliruan:
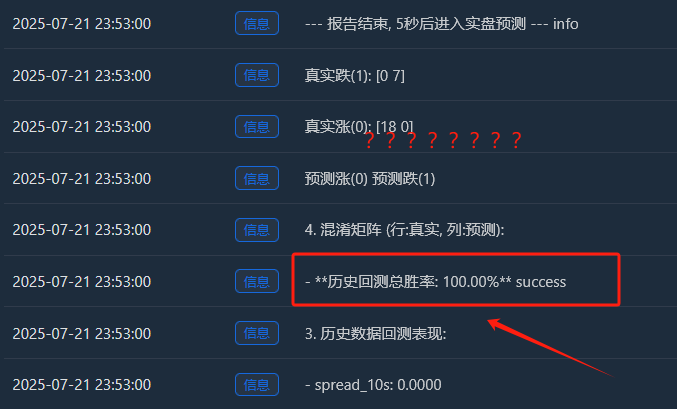
- Peningkatan sebenar (0):[18 0] -> 18 sampel yang semakin meningkat, semuanya dihafal dengan sempurna.
- Penurunan sebenar (1):[0 7] -> 7 sampel jatuh, semuanya diingati dengan sempurna.
- Sempurna ini[ [18, 0], [Matriks [0, 7] ialah bukti yang tidak dapat dinafikan tentang kelengkapan model yang berlebihan. Ia hampir tidak membuat kesilapan, yang sememangnya tidak normal dalam pasaran kewangan yang penuh dengan rawak.
Oleh itu, kita harus mentafsirkan kadar kemenangan 100% ini seperti berikut:
"Model ini telah mempelajari dan menghafal semua corak keadaan pasaran tertentu secara luar biasa sepanjang tiga jam yang lalu. Ini menunjukkan keberkesanan rangka kerja kejuruteraan ciri dan model kami. Walau bagaimanapun, kami sama sekali tidak boleh mengharapkan ia mengekalkan kadar kemenangan yang tinggi dalam pasaran sebenar pada masa hadapan. Ini lebih seperti 'kuiz pop' yang sempurna daripada keputusan akhir 'peperiksaan kemasukan kolej'."

Pembelajaran mesin juga merupakan sesuatu yang saya terokai baru-baru ini, kita akan membincangkannya dalam keluaran seterusnya!
Kita perlu melakukan "transformasi pemikiran" yang menyeluruh terhadap "pelajar berat sebelah ini." Matlamat kami adalah untuk memecahkan berat sebelahnya dan membenarkan dia melihat "naik turun" secara adil dan objektif.
